") 對(duì)2017年深度學(xué)習(xí)所取得的成就進(jìn)行盤(pán)點(diǎn)
對(duì)2017年深度學(xué)習(xí)所取得的成就進(jìn)行盤(pán)點(diǎn)
機(jī)器學(xué)習(xí)將成為基本技能,學(xué)習(xí)機(jī)器學(xué)習(xí)永遠(yuǎn)不會(huì)遲編者按:人工智能正在日益滲透到所有的技術(shù)領(lǐng)域。而機(jī)器學(xué)習(xí)(ML)是目前最活躍的分支。最近幾年,ML取得了許多重要進(jìn)展。其中一些因?yàn)槭录蟊婈P(guān)系密切而引人矚目,而有的雖然低調(diào)但意義重大。Statsbot一直在持續(xù)評(píng)估深度學(xué)習(xí)的各項(xiàng)成就。值此年終之際,他們的團(tuán)隊(duì)決定對(duì)過(guò)去一年深度學(xué)習(xí)所取得的成就進(jìn)行盤(pán)點(diǎn)。
1. 文字
1.1. Google自然機(jī)器翻譯
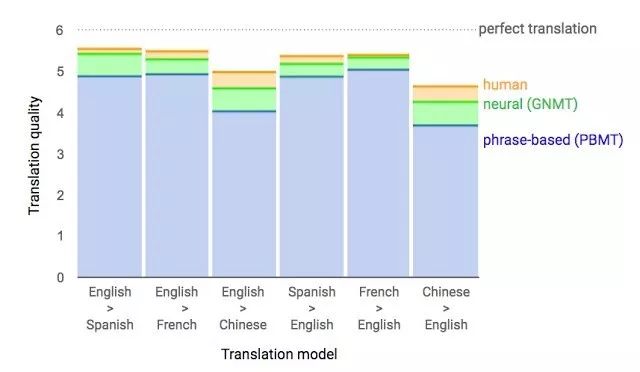
將近1年前,Google發(fā)布了新一代的Google Translate。這家公司還介紹了其網(wǎng)絡(luò)架構(gòu)遞歸神經(jīng)網(wǎng)絡(luò)(RNN)的細(xì)節(jié)情況。
其關(guān)鍵成果是:將跟人類翻譯準(zhǔn)確率的差距縮小了55%—85%(由人按照6個(gè)等級(jí)進(jìn)行評(píng)估)。如果沒(méi)有像Google手里的那么大規(guī)模的數(shù)據(jù)集的話,是很難用這一模型再生出好結(jié)果的。
1.2. 談判。能否成交?
你大概已經(jīng)聽(tīng)說(shuō)過(guò)Facebook把它的聊天機(jī)器人關(guān)閉這則愚蠢的新聞了,因?yàn)槟菣C(jī)器人失去了控制并且發(fā)明了自己的語(yǔ)言。Facebook做這個(gè)聊天機(jī)器人的目的是為了協(xié)商談判,跟另一個(gè)代理進(jìn)行文字上的談判,以期達(dá)成交易:比如怎么分?jǐn)偽锲罚〞?shū)、帽等)。每一個(gè)代理在談判時(shí)都有自己的目標(biāo),但是對(duì)方并不知道自己的目標(biāo)。不能達(dá)成交易就不能推出談判。
出于訓(xùn)練的目的,他們收集了人類談判協(xié)商的數(shù)據(jù)集然后做一個(gè)有監(jiān)督的遞歸渦輪里面對(duì)它進(jìn)行訓(xùn)練。接著,他們用強(qiáng)化學(xué)習(xí)訓(xùn)練代理,讓它自己跟自己講話,條件限制是語(yǔ)言跟人類類似。
機(jī)器人學(xué)會(huì)了一條真正的談判策略——假裝對(duì)交易的某個(gè)方面展現(xiàn)出興趣,然后隨后放棄這方面的訴求從而讓自己的真正目標(biāo)受益。這是創(chuàng)建此類交互式機(jī)器人的第一次嘗試,結(jié)果還是相當(dāng)成功的。
當(dāng)然,說(shuō)這個(gè)機(jī)器人發(fā)明了自己的語(yǔ)言完全就是牽強(qiáng)附會(huì)了。在訓(xùn)練(跟同一個(gè)代理進(jìn)行協(xié)商談判)的時(shí)候,他們?nèi)∠藢?duì)文字與人類相似性的限制,然后算法就修改了交互的語(yǔ)言。沒(méi)什么特別。
過(guò)去幾年,遞歸網(wǎng)絡(luò)的發(fā)展一直都很活躍,并且應(yīng)用到了很多的任務(wù)和應(yīng)用中。RNN的架構(gòu)已經(jīng)變得復(fù)雜許多,但在一些領(lǐng)域,簡(jiǎn)單的前向網(wǎng)絡(luò)——DSSM也能取得類似的結(jié)果。比方說(shuō),此前Google用LSTM在郵件功能Smart Reply上也已經(jīng)達(dá)到了相同的質(zhì)量。此外,Yandex還基于此類網(wǎng)絡(luò)推出了一個(gè)新的搜索引擎。
2. 語(yǔ)音
2.1. WaveNet:裸音頻的生成式模型
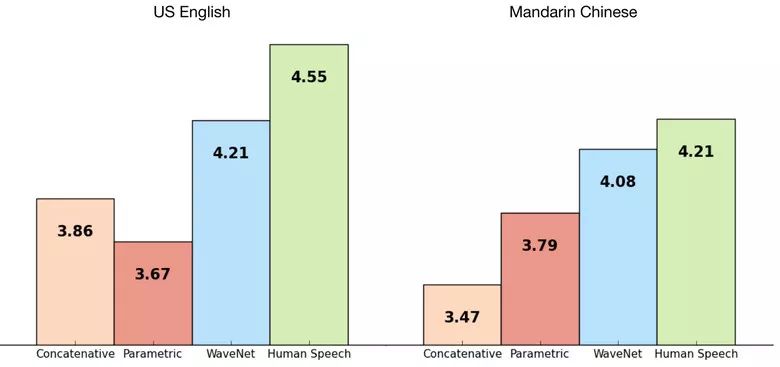
DeepMind的員工在文章中介紹了音頻的生成。簡(jiǎn)單來(lái)說(shuō),研究人員在之前圖像生成(PixelRNN和PixelCNN)的基礎(chǔ)上做出了一個(gè)自回歸的完全卷積WaveNet模型。
該網(wǎng)絡(luò)經(jīng)過(guò)了端到端的訓(xùn)練:文本作為輸入,音頻做出輸出。研究取得了出色的結(jié)果,因?yàn)楦祟惖牟町悳p少了50%。
這種網(wǎng)絡(luò)的主要劣勢(shì)是生產(chǎn)力低,由于自回歸的關(guān)系,聲音是串行生產(chǎn)的,所以一秒鐘的音頻要1到2分鐘才能生成。
我們來(lái)看看……哦對(duì)不起,是聽(tīng)聽(tīng)這個(gè)例子。
如果你撤銷網(wǎng)絡(luò)對(duì)輸入文字的依賴,只留下對(duì)之前生成音素的依賴,則網(wǎng)絡(luò)就能生成類似人類語(yǔ)言的音素,但這樣的音頻是沒(méi)有意義的。
聽(tīng)聽(tīng)這個(gè)生成語(yǔ)音的例子。
同一個(gè)模型不僅可以應(yīng)用到語(yǔ)音上,而且也可以應(yīng)用在創(chuàng)作音樂(lè)等事情上。想象一下用這個(gè)模型(用某個(gè)鋼琴游戲的數(shù)據(jù)集訓(xùn)練,也是沒(méi)有依賴輸入數(shù)據(jù)的)生成音頻。
2.2. 理解唇語(yǔ)
唇語(yǔ)理解是另一個(gè)深度學(xué)習(xí)超越人類的成就和勝利。
Google Deepmind跟牛津大學(xué)合作在《唇語(yǔ)自然理解》這篇文章中介紹了他們的模型(通過(guò)電視數(shù)據(jù)集訓(xùn)練)是如何超越職業(yè)唇語(yǔ)解讀師的。
這個(gè)數(shù)據(jù)集總共有包含100000個(gè)句子的音視頻。模型:音頻用LSTM,視頻用CNN+LSTM。這兩個(gè)狀態(tài)向量提供給最后的LSTM,然后再生成結(jié)果(字符)。
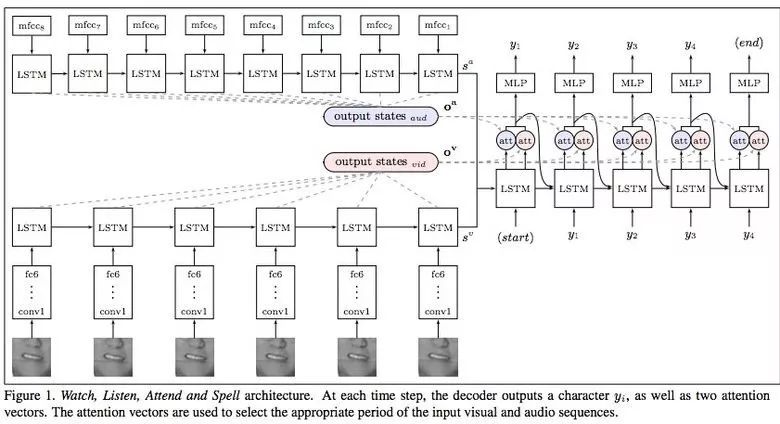
訓(xùn)練過(guò)程中用到了不同類型的輸入數(shù)據(jù):音頻、視頻以及音視頻。換句話說(shuō),這是一種“多渠道”模型。
2.3. 合成奧巴馬:從音頻中合成嘴唇動(dòng)作
華盛頓大學(xué)干了一件嚴(yán)肅的工作,他們生成了奧巴馬總統(tǒng)的唇語(yǔ)動(dòng)作。之所以要選擇他是因?yàn)樗v話的網(wǎng)上視頻很多(17小時(shí)的高清視頻)。
光靠網(wǎng)絡(luò)他們是沒(méi)有辦法取得進(jìn)展的,因?yàn)槿斯さ臇|西太多。因此,文章作者構(gòu)思了一些支撐物(或者花招,你要是喜歡這么說(shuō)的話)來(lái)改進(jìn)紋理和時(shí)間控制。
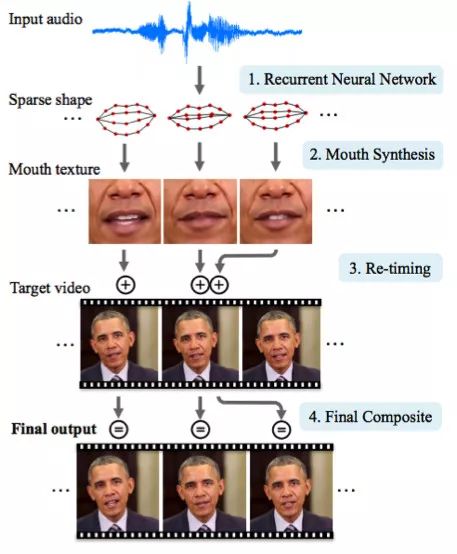
你可以看到,結(jié)果是很驚艷的。很快,你就沒(méi)法相信這位總統(tǒng)的視頻了。
3.1. OCR:Google Maps和StreetView(街景)
Google Brain Team在博客和文章中報(bào)告了他們是如何引入一種新的OCR(光學(xué)字符識(shí)別)引擎給Maps,然后用來(lái)識(shí)別街道名牌和商店標(biāo)志。
在技術(shù)開(kāi)發(fā)的過(guò)程中,該公司編譯了一種新的FSNS(法國(guó)街道名牌),里面包含有很多復(fù)雜的情況。
為了識(shí)別每一塊名牌,該網(wǎng)絡(luò)利用了名牌多至4張的照片。特征由CNN來(lái)析取,在空間注意(考慮了像素坐標(biāo))的幫助下進(jìn)行擴(kuò)充,然后再把結(jié)果送給LSTM。
同樣的方法被應(yīng)用到識(shí)別廣告牌上的商店名上面(里面會(huì)有大量的“噪聲”數(shù)據(jù),網(wǎng)絡(luò)本身必須“關(guān)注”合適的位置)。這一算法應(yīng)用到了800億張圖片上。
3.2. 視覺(jué)推理
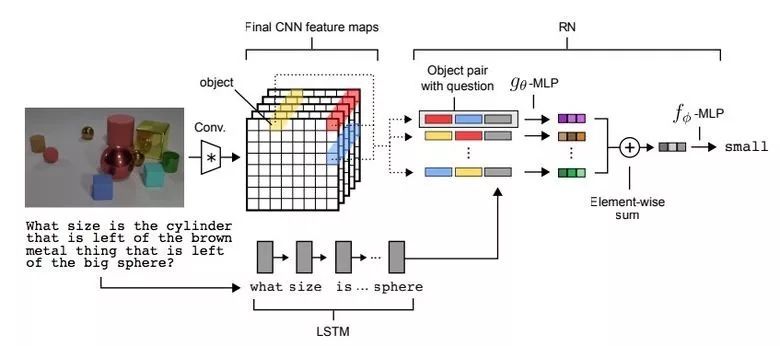
有一種任務(wù)類型叫做視覺(jué)推理,神經(jīng)網(wǎng)絡(luò)被要求根據(jù)一張照片來(lái)回答問(wèn)題。比方說(shuō):“圖中橡皮材料的物品跟黃色金屬圓柱體的數(shù)量是不是一樣的?”這個(gè)問(wèn)題可不是小問(wèn)題,直到最近,解決的準(zhǔn)確率也只有68.5%。

不過(guò)Deepind團(tuán)隊(duì)再次取得了突破:在CLEVR數(shù)據(jù)集上他們達(dá)到了95.5%的準(zhǔn)確率,甚至超過(guò)了人類。
這個(gè)網(wǎng)絡(luò)的架構(gòu)非常有趣:
把預(yù)訓(xùn)練好的LSTM用到文本問(wèn)題上,我們就得到了問(wèn)題的嵌入。
利用CNN(只有4層)到圖片上,就得到了特征地圖(歸納圖片特點(diǎn)的特征)
接下來(lái),我們對(duì)特征地圖的左邊片段進(jìn)行兩兩配對(duì)(下圖的黃色、藍(lán)色、紅色),給每一個(gè)增加坐標(biāo)與文本嵌入。
我們通過(guò)另一個(gè)網(wǎng)絡(luò)來(lái)跑所有這些三元組然后匯總起來(lái)。
結(jié)果呈現(xiàn)再到一個(gè)前向反饋網(wǎng)絡(luò)里面跑,然后提供softmax答案。
3.3. Pix2Code應(yīng)用
Uizard公司創(chuàng)建了一個(gè)有趣的神經(jīng)網(wǎng)絡(luò)應(yīng)用:根據(jù)界面設(shè)計(jì)器的截屏生成布局代碼:
這是極其有用的一種神經(jīng)網(wǎng)絡(luò)應(yīng)用,可以幫助軟件開(kāi)發(fā)變得容易一些。作者聲稱他們?nèi)〉昧?7%的準(zhǔn)確率。然而,這仍然在研究中,還沒(méi)有討論過(guò)真正的使用情況。
他們還沒(méi)有開(kāi)源代碼或者數(shù)據(jù)集,但是承諾會(huì)上傳。
3.4. SketchRNN:教機(jī)器畫(huà)畫(huà)
你大概已經(jīng)看過(guò)Google的Quick, Draw!了,其目標(biāo)是在20秒之內(nèi)畫(huà)出各種對(duì)象的草圖。這家公司收集了這個(gè)數(shù)據(jù)集以便來(lái)教神經(jīng)網(wǎng)絡(luò)畫(huà)畫(huà),就像Google在他們的博客和文章中所說(shuō)那樣。
這份數(shù)據(jù)集包含了7萬(wàn)張素描,Google現(xiàn)在已經(jīng)開(kāi)放給公眾了。素描不是圖片,而是畫(huà)畫(huà)詳細(xì)的向量表示(用戶按下“鉛筆”畫(huà)畫(huà),畫(huà)完時(shí)釋放所記錄的東西)。
研究人員已經(jīng)把RNN作為編碼/解碼機(jī)制來(lái)訓(xùn)練該序列到序列的變自編碼器(Sequence-to-Sequence Variational Autoencoder)。

最終,作為自編碼器應(yīng)有之義,該模型將得到一個(gè)歸納原始圖片特點(diǎn)的特征向量。
鑒于該解碼器可以從這一向量析取出一幅圖畫(huà),你可以改變它并且得到新的素描。
甚至進(jìn)行向量運(yùn)算來(lái)創(chuàng)作一只貓豬:
3.5. GAN(生成對(duì)抗網(wǎng)絡(luò))
生成對(duì)抗網(wǎng)絡(luò)(GAN)是深度學(xué)習(xí)最熱門(mén)的話題之一。很多時(shí)候,這個(gè)想法都是用于圖像方面,所以我會(huì)用圖像來(lái)解釋這一概念。
其想法體現(xiàn)在兩個(gè)網(wǎng)絡(luò)——生成器與鑒別器的博弈上。第一個(gè)網(wǎng)絡(luò)創(chuàng)作圖像,然后對(duì)二個(gè)網(wǎng)絡(luò)試圖理解該圖像是真實(shí)的還是生成的。
用圖示來(lái)解釋大概是這樣的:
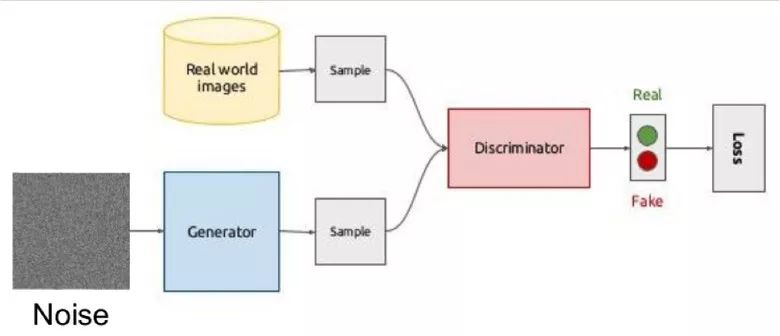
在訓(xùn)練期間,生成器通過(guò)隨機(jī)向量(噪聲)生成一幅圖像然后交給鑒別器的輸入,由后者說(shuō)出這是真的還是假的。鑒別器還會(huì)接收來(lái)自數(shù)據(jù)集的真實(shí)圖像。
訓(xùn)練這樣的結(jié)構(gòu)是很難的,因?yàn)檎业絻蓚€(gè)網(wǎng)絡(luò)的平衡點(diǎn)很難。通常情況下鑒別器會(huì)獲勝,然后訓(xùn)練就停滯不前了。然而,該系統(tǒng)的優(yōu)勢(shì)在于我們可以解決對(duì)我們來(lái)說(shuō)很難設(shè)置損失函數(shù)的問(wèn)題(比方說(shuō)改進(jìn)圖片質(zhì)量)——這種問(wèn)題交給鑒別器最合適。
GAN訓(xùn)練結(jié)果的典型例子是宿舍或者人的圖片
此前,我們討論過(guò)將原始數(shù)據(jù)編碼為特征表示的自編碼(Sketch-RNN)。同樣的事情也發(fā)生在生成器上。
利用向量生成圖像的想法在這個(gè)以人臉為例的項(xiàng)目http://carpedm20.github.io/faces/中得到了清晰展示。你可以改變向量來(lái)看看人臉是如何變化的。
相同的算法也可用于潛在空間:“一個(gè)戴眼鏡的人”減去“一個(gè)人”加上一個(gè)“女人”相當(dāng)于“一個(gè)戴眼鏡的女人”。
3.6. 用GAN改變臉部年齡
如果在訓(xùn)練過(guò)程中你把控制參數(shù)交給潛在向量,那么在生成潛在向量時(shí),你就可以更改它從而在在圖片中管理必要的圖像。這種方法被稱為有條件GAN。
《用有條件生成對(duì)抗網(wǎng)絡(luò)進(jìn)行面部老化》這篇文章的作者就是這么干的。在用IMDB數(shù)據(jù)集中已知年齡的演員對(duì)引擎進(jìn)行過(guò)訓(xùn)練之后,研究人員就有機(jī)會(huì)來(lái)改變此人的面部年齡。
3.7. 專業(yè)照片
Google已經(jīng)為GAN找到了另一種有趣的應(yīng)用——選擇和改善照片。他們用專業(yè)照片數(shù)據(jù)集來(lái)訓(xùn)練GAN:生成器試圖改進(jìn)糟糕的照片(經(jīng)過(guò)專業(yè)拍攝然后用特殊過(guò)濾器劣化),而鑒別器則要區(qū)分“改進(jìn)過(guò)”的照片與真正的專業(yè)照片。
經(jīng)過(guò)訓(xùn)練的算法會(huì)篩查Google Street View的全景照片,選出其中最好的作品,并會(huì)收到一些專業(yè)和半專業(yè)品質(zhì)的照片(經(jīng)過(guò)攝影師評(píng)級(jí))。
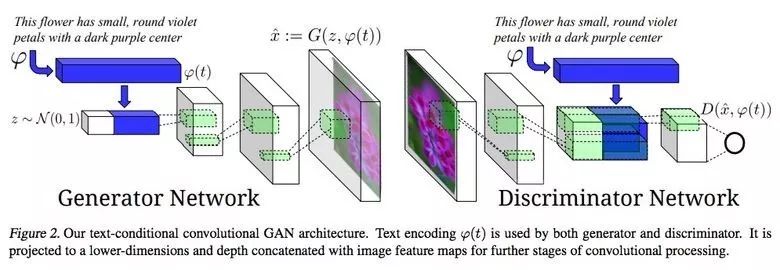
3.8. 通過(guò)文字描述合成圖像
GAN的一個(gè)令人印象深刻的例子是用文字生成圖像。
這項(xiàng)研究的作者提出不僅把文字嵌入到生成器(有條件GAN)的輸入,同時(shí)也嵌入到鑒別器的輸入,這樣就可以驗(yàn)證文字與圖像的相關(guān)性。為了確保鑒別器學(xué)會(huì)運(yùn)行他的函數(shù),除了訓(xùn)練以外,他們還給真實(shí)圖像添加了不正確的文字。
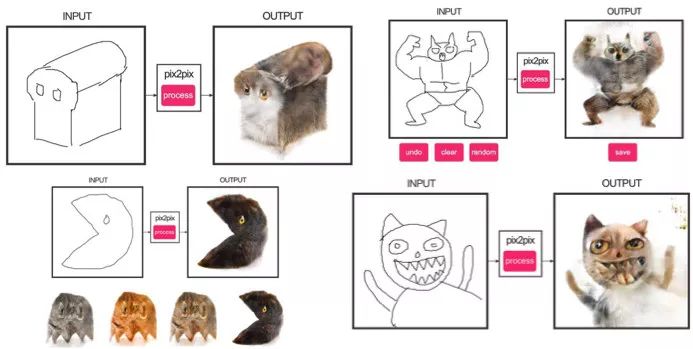
3.9. Pix2pix應(yīng)用
2016年引人矚目的文章之一是Berkeley AI Research (BAIR)的《用有條件對(duì)抗網(wǎng)絡(luò)進(jìn)行圖像到圖像的翻譯》。研究人員解決了圖像到圖像生成的問(wèn)題,比方說(shuō)在要求它用一幅衛(wèi)星圖像創(chuàng)造一幅地圖時(shí),或者根據(jù)素描做出物體的真實(shí)紋理。

這里還有一個(gè)有條件GAN成功表現(xiàn)的例子。這種情況下,條件擴(kuò)大到整張圖片。在圖像分割中很流行的UNet被用作生成器的架構(gòu),一個(gè)新的PatchGAN分類器用作鑒別器來(lái)對(duì)抗模糊圖像(圖片被分成N塊,每一塊都分別進(jìn)行真?zhèn)蔚念A(yù)測(cè))。
Christopher Hesse創(chuàng)作了可怕的貓形象,引起了用戶極大的興趣。
你可以在這里找到源代碼。
3.10. CycleGAN圖像處理工具
要想應(yīng)用Pix2Pix,你需要一個(gè)包含來(lái)自不同領(lǐng)域圖片匹配對(duì)的數(shù)據(jù)集。比方說(shuō)在卡片的情況下,收集此類數(shù)據(jù)集并不是問(wèn)題。然而,如果你希望做點(diǎn)更復(fù)雜的東西,比如對(duì)對(duì)象進(jìn)行“變形”或者風(fēng)格化,一般而言就找不到對(duì)象匹配対了。
因此,Pix2Pix的作者決定完善自己的想法,他們想出了CycleGAN,在沒(méi)有特定配對(duì)的情況來(lái)對(duì)不同領(lǐng)域的圖像進(jìn)行轉(zhuǎn)換——《不配對(duì)的圖像到圖像翻譯》
其想法是教兩對(duì)生成器—鑒別器將圖像從一個(gè)領(lǐng)域轉(zhuǎn)換為另一個(gè)領(lǐng)域,然后再反過(guò)來(lái),由于我們需要一種循環(huán)的一致性——經(jīng)過(guò)一系列的生成器應(yīng)用之后,我們應(yīng)該得到類似原先L1層損失的圖像。為了確保生成器不會(huì)將一個(gè)領(lǐng)域的圖像轉(zhuǎn)換成另一個(gè)跟原先圖像毫無(wú)關(guān)系的領(lǐng)域的圖像,需要有一個(gè)循環(huán)損失。
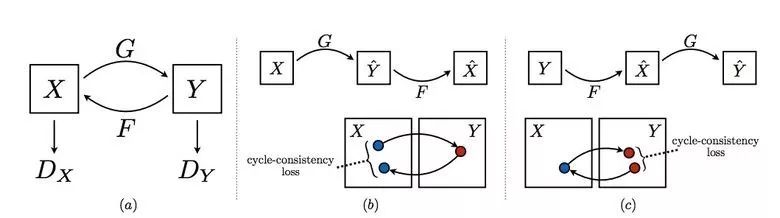
這種辦法讓你可以學(xué)習(xí)馬—>斑馬的映射。
此類轉(zhuǎn)換不太穩(wěn)定,往往會(huì)創(chuàng)造出不成功的選項(xiàng):
源碼可以到這里找。
3.11. 腫瘤分子學(xué)的進(jìn)展
機(jī)器學(xué)習(xí)現(xiàn)在已經(jīng)走進(jìn)了醫(yī)療業(yè)。除了識(shí)別超聲波、MRI以及進(jìn)行診斷以外,它還可以用來(lái)發(fā)現(xiàn)對(duì)抗癌癥的藥物。
我們已經(jīng)報(bào)道過(guò)這一研究的細(xì)節(jié)。簡(jiǎn)單來(lái)說(shuō),在對(duì)抗自編碼器(AAE)的幫助下,你可以學(xué)習(xí)分子的潛在表征然后用它來(lái)尋找新的分子。通過(guò)這種方式已經(jīng)找到了69種分子,其中一半是用于對(duì)抗癌癥的,其他的也有著重大潛能。
3.12. 對(duì)抗攻擊
對(duì)抗攻擊方面的話題探討得很熱烈。什么是對(duì)抗攻擊?比方說(shuō),基于ImageNet訓(xùn)練的標(biāo)準(zhǔn)網(wǎng)絡(luò),在添加特殊噪聲給已分類的圖片之后完全是不穩(wěn)定的。在下面這個(gè)例子中,我們看到給人類眼睛加入噪聲的圖片基本上是不變的,但是模型完全發(fā)瘋了,預(yù)測(cè)成了完全不同的類別。
Fast Gradient Sign Method(FGSM,快速梯度符號(hào)方法)就實(shí)現(xiàn)了穩(wěn)定性:在利用了該模型的參數(shù)之后,你可以朝著想要的類別前進(jìn)一到幾個(gè)梯度步然后改變?cè)紙D片。
Kaggle的任務(wù)之一與此有關(guān):參與者被鼓勵(lì)去建立通用的攻防體系,最終會(huì)相互對(duì)抗以確定最好的。
為什么我們要研究這些攻擊?首先,如果我們希望保護(hù)自己的產(chǎn)品的話,我們可以添加噪聲給captcha來(lái)防止spammer(垃圾群發(fā)者)的自動(dòng)識(shí)別。其次,算法正日益滲透到我們的生活當(dāng)中——比如面部識(shí)別系統(tǒng)和自動(dòng)駕駛汽車(chē)就是例子。這種情況下,攻擊者會(huì)利用這些算法的缺陷。
這里就有一個(gè)例子,通過(guò)特殊玻璃你可以欺騙面部識(shí)別系統(tǒng),然后“把自己扮成另一個(gè)人而獲得通過(guò)”。因此,在訓(xùn)練模型的時(shí)候我們需要考慮可能的攻擊。
此類對(duì)標(biāo)識(shí)的操縱也妨礙了對(duì)其的正確識(shí)別。
這里有來(lái)自競(jìng)賽組織者的一組文章。
已經(jīng)寫(xiě)好的用于攻擊的庫(kù):cleverhans和foolbox。
4. 強(qiáng)化學(xué)習(xí)
強(qiáng)化學(xué)習(xí)(RL)也是機(jī)器學(xué)習(xí)最有趣發(fā)展最活躍的分支之一。
這種辦法的精髓是在一個(gè)通過(guò)體驗(yàn)給予獎(jiǎng)勵(lì)的環(huán)境中學(xué)習(xí)代理的成功行為——就像人一生的學(xué)習(xí)一樣。
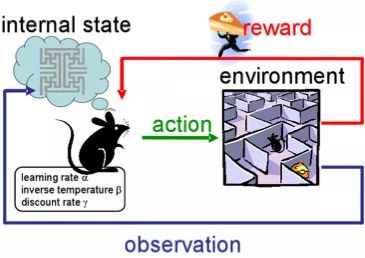
RL在游戲、機(jī)器人以及系統(tǒng)管理(比如交通)中使用活躍。
當(dāng)然,每個(gè)人都聽(tīng)說(shuō)過(guò)Alphago在與人類最好圍棋選手的比賽中取得的勝利。研究人員在訓(xùn)練中使用了RL:機(jī)器人個(gè)你自己下棋來(lái)改進(jìn)策略。
4.1. 不受控輔助任務(wù)的強(qiáng)化訓(xùn)練
前幾年DeepMind已經(jīng)學(xué)會(huì)了用DQN來(lái)玩大型電玩,表現(xiàn)已經(jīng)超過(guò)了人類。目前,他們正在教算法玩類似Doom這樣更復(fù)雜的游戲。
大量關(guān)注被放到了學(xué)習(xí)加速上面,因?yàn)榇砀h(huán)境的交互經(jīng)驗(yàn)需要現(xiàn)代GPU很多小時(shí)的訓(xùn)練。
4.2. 學(xué)習(xí)機(jī)器人
在OpenAi,他們一直在積極研究人類在虛擬環(huán)境下對(duì)代理的訓(xùn)練,這要比在現(xiàn)實(shí)生活中進(jìn)行實(shí)驗(yàn)更安全。
他們的團(tuán)隊(duì)在其中一項(xiàng)研究中顯示出一次性的學(xué)習(xí)是有可能的:一個(gè)人在VR中演示如何執(zhí)行特定任務(wù),結(jié)果表明,一次演示就足以供算法學(xué)會(huì)然后在真實(shí)條件下再現(xiàn)。

如果教會(huì)人也這么簡(jiǎn)單就好了。
4.3. 基于人類偏好的學(xué)習(xí)
這里是OpenAi和DeepMind聯(lián)合對(duì)該主題展開(kāi)的工作。基本上就是代理有個(gè)任務(wù),算法提供了兩種可能的解決方案給人然后指出哪一個(gè)更好。這個(gè)過(guò)程會(huì)不斷反復(fù),然后獲取人類900的字位反饋(二進(jìn)制標(biāo)記)的算法就學(xué)會(huì)了如何解決這個(gè)問(wèn)題。
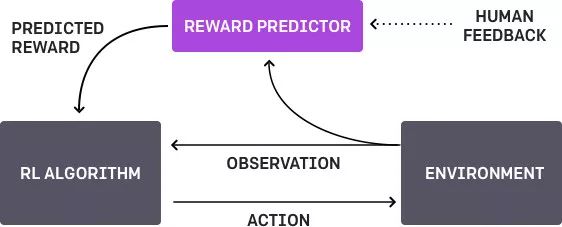
像以往一樣,人類必須小心,要考慮清楚他教給機(jī)器的是什么。比方說(shuō),鑒別器確定算法真的想要拿那個(gè)東西,但其實(shí)他只是模仿了這個(gè)動(dòng)作。
4.4. 復(fù)雜環(huán)境下的運(yùn)動(dòng)
這是另一項(xiàng)來(lái)自DeepMind的研究。為了教機(jī)器人復(fù)雜的行為(走路、跳躍等),甚至做類似人的動(dòng)作,你得大量參與到損失函數(shù)的選擇上,這會(huì)鼓勵(lì)想要的行為。然而,算法學(xué)習(xí)通過(guò)簡(jiǎn)單獎(jiǎng)勵(lì)學(xué)習(xí)復(fù)雜行為會(huì)更好一些。
研究人員設(shè)法實(shí)現(xiàn)了這一點(diǎn):他們通過(guò)搭建一個(gè)有障礙的復(fù)雜環(huán)境并且提供一個(gè)簡(jiǎn)單的回報(bào)機(jī)制用于運(yùn)動(dòng)中的處理來(lái)教代理(軀體模擬器)執(zhí)行復(fù)雜動(dòng)作。
你可以觀看這段視頻,結(jié)果令人印象深刻。然而,用疊加聲音觀看會(huì)有趣得多!
最后,我再提供一個(gè)最近發(fā)布的算法鏈接,這是OpenAI開(kāi)發(fā)用于學(xué)習(xí)RL的。現(xiàn)在你可以使用比標(biāo)準(zhǔn)的DQN更先進(jìn)的解決方案了。
5. 其他
5.1. 冷卻數(shù)據(jù)中心
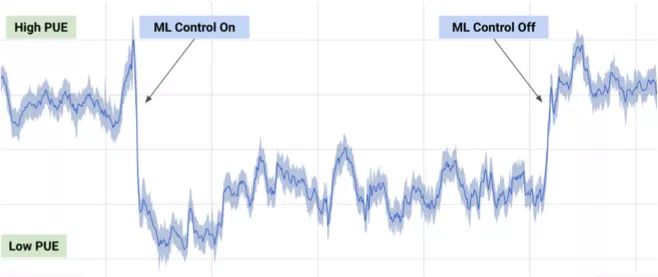
2017年7月,Google報(bào)告稱它利用了DeepMind在機(jī)器學(xué)習(xí)方面的成果來(lái)減少數(shù)據(jù)中心的能耗。
基于數(shù)據(jù)中心數(shù)千個(gè)傳感器的信息,Google開(kāi)發(fā)者訓(xùn)練了一個(gè)神經(jīng)網(wǎng)絡(luò),一方面預(yù)測(cè)數(shù)據(jù)中心的PUE(能源使用效率),同時(shí)進(jìn)行更高效的數(shù)據(jù)中心管理。這是ML實(shí)際應(yīng)用的一個(gè)令人印象深刻的重要例子。
5.2. 適用所有任務(wù)的模型
就像你知道的那樣,訓(xùn)練過(guò)的模型是非常專門(mén)化的,每一個(gè)任務(wù)都必須針對(duì)特殊模型訓(xùn)練,很難從一個(gè)任務(wù)轉(zhuǎn)化到執(zhí)行另一個(gè)任務(wù)。不過(guò)Google Brain在模型的普適性方面邁出了一小步,《學(xué)習(xí)一切的單一模型》
研究人員已經(jīng)訓(xùn)練了一個(gè)模型來(lái)執(zhí)行8種不同領(lǐng)域(文本、語(yǔ)音、圖像)的任務(wù)。比方說(shuō),翻譯不同的語(yǔ)言,文本解析,以及圖像與聲音識(shí)別。
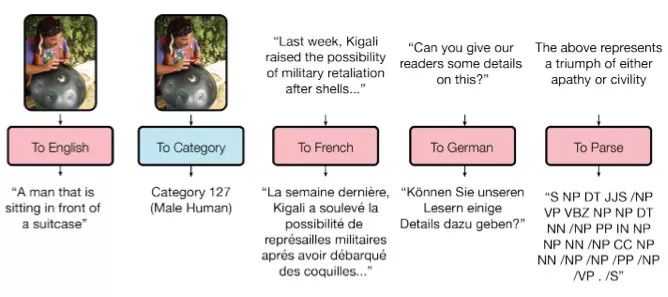
為了實(shí)現(xiàn)這一點(diǎn),他們開(kāi)發(fā)了一個(gè)復(fù)雜的網(wǎng)絡(luò)架構(gòu),里面有不同的塊處理不同的輸入數(shù)據(jù)然后產(chǎn)生出結(jié)果。用于編碼/解碼的這些塊分成了3種類型:卷積、注意力以及門(mén)控專家混合(MoE)。
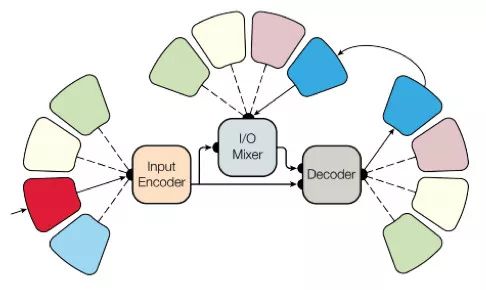
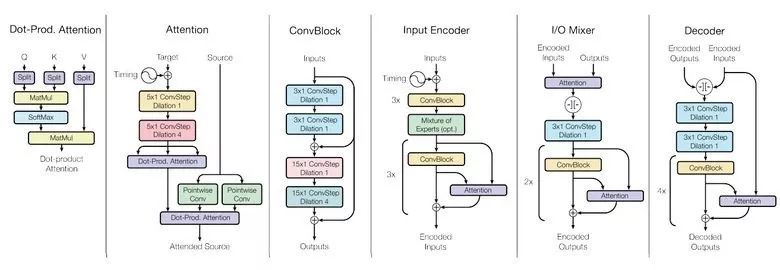
學(xué)習(xí)的主要結(jié)果:
得到了幾乎完美的模型(作者并未對(duì)超參數(shù)進(jìn)行調(diào)優(yōu))。
不同領(lǐng)域間的知識(shí)發(fā)生了轉(zhuǎn)化,也就是說(shuō),對(duì)于需要大量數(shù)據(jù)的任務(wù),表現(xiàn)幾乎是一樣的。而且在小問(wèn)題上表現(xiàn)更好(比方說(shuō)解析)。
不同任務(wù)需要的塊并不會(huì)相互干擾甚至有時(shí)候還有所幫助,比如,MoE——對(duì)Imagenet任務(wù)就有幫助。
順便說(shuō)一下,這個(gè)模型放到了tensor2tensor里面。
5.3. 一小時(shí)弄懂Imagenet
Facebook的員工在一篇文章中告訴我們,他們的工程師是如何在僅僅一個(gè)小時(shí)之內(nèi)教會(huì)Resnet-50模型弄懂Imagenet的。要說(shuō)清楚的是,他們用來(lái)256個(gè)GPU(Tesla P100)。
他們利用了Gloo和Caffe2進(jìn)行分布式學(xué)習(xí)。為了讓這個(gè)過(guò)程高效,采用大批量(8192個(gè)要素)的學(xué)習(xí)策略是必要的:梯度平均、熱身階段、特殊學(xué)習(xí)率等。
因此,從8個(gè)GPU擴(kuò)展到256個(gè)GPU時(shí),實(shí)現(xiàn)90%的效率是有可能的。不想沒(méi)有這種集群的普通人,現(xiàn)在Facebook的研究人員實(shí)驗(yàn)甚至可以更快。
6. 新聞
6.1. 無(wú)人車(chē)
無(wú)人車(chē)的研發(fā)正熱火朝天,各種車(chē)都在積極地進(jìn)行測(cè)試。最近幾年,我們留意到了英特爾收購(gòu)了Mobileye,Uber與Google之間發(fā)生的前員工竊取技術(shù)的丑聞,以及采用自動(dòng)導(dǎo)航導(dǎo)致的第一起死亡事件等等。
我想強(qiáng)調(diào)一件事情:Google Waymo正在推出一個(gè)beta計(jì)劃。Google是該領(lǐng)域的先驅(qū),它認(rèn)為自己的技術(shù)是非常好的,因?yàn)樗能?chē)已經(jīng)行駛了300多萬(wàn)英里。
最近無(wú)人車(chē)還被允許在美國(guó)全境行駛了。
6.2. 醫(yī)療保健
就像我說(shuō)過(guò)那樣,現(xiàn)代ML正開(kāi)始引入到醫(yī)療行業(yè)當(dāng)中。比方說(shuō),Google跟一個(gè)醫(yī)療中心合作來(lái)幫助后者進(jìn)行診斷。
Deepmind甚至還設(shè)立了一個(gè)獨(dú)立的部門(mén)。
今年Kaggle推出了Data Science Bowl計(jì)劃,這是一項(xiàng)預(yù)測(cè)一年肺癌情況的競(jìng)賽,選手們的依據(jù)是一堆詳細(xì)的圖片,獎(jiǎng)金池高達(dá)100萬(wàn)美元。
6.3 投資
目前,ML方面的投資非常大,就像之前在大數(shù)據(jù)方面的投資一樣。
中國(guó)在AI方面的投入高達(dá)1500億美元,意在成為這個(gè)行業(yè)的領(lǐng)袖。
公司方面,百度研究院雇用了1300人,相比之下FAIR的是80人。在最近的KDD上,阿里的員工介紹了他們的參數(shù)服務(wù)器鯤鵬(KunPeng),上面跑的樣本達(dá)1000億,有1萬(wàn)億個(gè)參數(shù),這些都是“普通任務(wù)”。
你可以得出自己的結(jié)論,學(xué)習(xí)機(jī)器學(xué)習(xí)永遠(yuǎn)不會(huì)遲。無(wú)路如何,隨著時(shí)間轉(zhuǎn)移,所有開(kāi)發(fā)者都會(huì)使用機(jī)器學(xué)習(xí),使得后者變成普通技能之一,就像今天對(duì)數(shù)據(jù)庫(kù)的使用能力一樣。
-
翻譯
+關(guān)注
關(guān)注
0文章
47瀏覽量
10961 -
計(jì)算機(jī)視覺(jué)
+關(guān)注
關(guān)注
9文章
1706瀏覽量
46573 -
無(wú)人車(chē)
+關(guān)注
關(guān)注
1文章
307瀏覽量
36816 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5554瀏覽量
122482
原文標(biāo)題:深度 | 2017 年,深度學(xué)習(xí)領(lǐng)域有哪些成就?
文章出處:【微信號(hào):melux_net,微信公眾號(hào):人工智能大趨勢(shì)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
拿高薪必備的深度學(xué)習(xí)nlp技術(shù),這篇文章講得很透徹
2017全國(guó)深度學(xué)習(xí)技術(shù)應(yīng)用大會(huì)
【盤(pán)點(diǎn)】2017元器件交期年終盤(pán)點(diǎn),2018年最新預(yù)測(cè)!
Nanopi深度學(xué)習(xí)之路(1)深度學(xué)習(xí)框架分析
什么是深度學(xué)習(xí)?使用FPGA進(jìn)行深度學(xué)習(xí)的好處?
2017年18款雙攝機(jī)型盤(pán)點(diǎn) 誰(shuí)在受益?
2017年Apple、大疆、聯(lián)想、google的智能硬件盤(pán)點(diǎn)
對(duì)2017年NLP領(lǐng)域中深度學(xué)習(xí)技術(shù)應(yīng)用的總結(jié)
深度學(xué)習(xí)領(lǐng)域Facebook等巨頭在2017都做了什么
深度神經(jīng)網(wǎng)絡(luò)加速和壓縮方面所取得的進(jìn)展報(bào)告
你知道機(jī)器深度學(xué)習(xí) 那你知道全新的進(jìn)化算法嗎





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論