") 奇異摩爾專用DSA加速解決方案重塑人工智能與高性能計算
奇異摩爾專用DSA加速解決方案重塑人工智能與高性能計算
寫在開頭,奇異摩爾的 NDSA 互聯(lián)系列產(chǎn)品基于高性能RoCEv2 RDMA引擎,是面向智算網(wǎng)絡(luò)通信加速及無損數(shù)據(jù)傳輸?shù)膶S肈SA加速解決方案。
本文部分內(nèi)容來源于麥肯錫白皮書
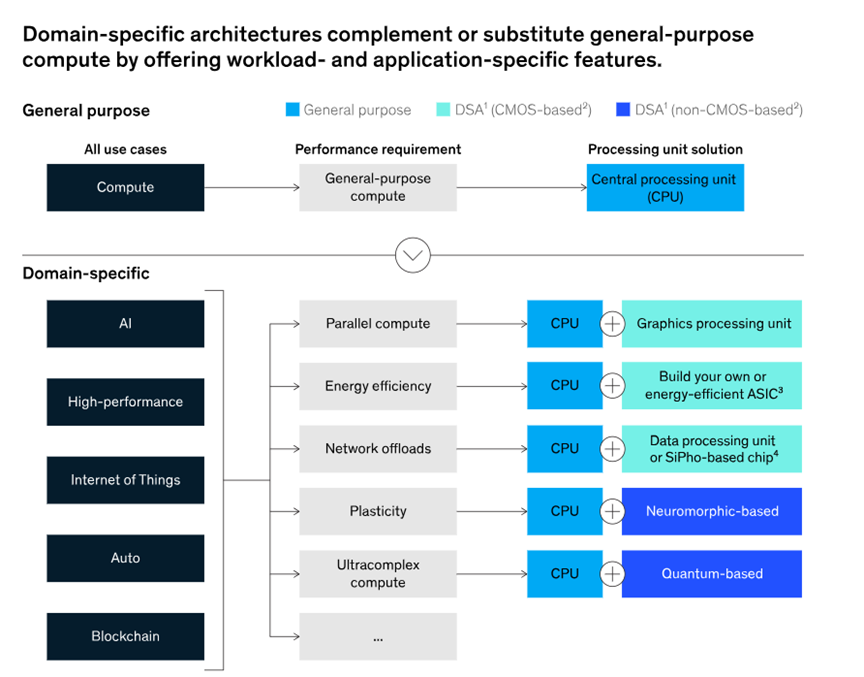
隨著摩爾定律下的晶體管縮放速度放緩,單純依靠增加晶體管密度的通用計算的邊際效益不斷遞減,促使專用計算日益多樣化,于是,針對特定計算任務(wù)的專用架構(gòu)成為計算創(chuàng)新的焦點。
在過去的幾十年的時間里,半導體晶圓上的晶體管密度幾乎每兩年翻一番,這一趨勢令人矚目。但在過去幾年中,晶體管縮放的速度顯著放緩,比摩爾定律預測的速度落后了大約十倍。
2018年,著名計算機架構(gòu)師約翰·亨尼斯西(John Hennessy)和大衛(wèi)·帕特森(David Patterson)在圖靈講座中指出,半導體工藝創(chuàng)新的放緩將逐漸增加對架構(gòu)創(chuàng)新的激勵——即集成電路的設(shè)計方式,以執(zhí)行計算任務(wù)。
“他們認為,通用計算架構(gòu)(如CPU)固有的低效性將開始被專門針對特定計算任務(wù)的架構(gòu)(也稱為領(lǐng)域?qū)S眉軜?gòu),DSAs)的計算能力和成本效益所取代 。”
與此同時,隨著計算和數(shù)字化在云計算(人工智能和高性能計算)、網(wǎng)絡(luò)、邊緣、物聯(lián)網(wǎng)(IoT)和自動駕駛等眾多應(yīng)用領(lǐng)域中普及,高度領(lǐng)域?qū)S玫挠嬎愎ぷ髫撦d正在為DSAs提供有意義的性能優(yōu)勢。大型語言模型(生成式AI的核心引擎),例如ChatGPT,在高容量的AI工作負載中提供了進一步的專業(yè)化,這促進了進一步的硬件專業(yè)化。 DSA(domain-specific architecture)為特定應(yīng)用領(lǐng)域開發(fā)的硬件和軟件的商業(yè)潛力是巨大的。專用的圖形處理單元 (GPU) 和張量處理單元 (TPU) 已經(jīng)在數(shù)據(jù)中心獲得了重要的市場份額,它們在 AI 工作負載學習和推理方面的表現(xiàn)優(yōu)于 CPU。使用GPU和TPU對某些應(yīng)用的性能提升是非常顯著的,特定工作負載的可以實現(xiàn)15 到 50 倍的加速。此外,在汽車領(lǐng)域,來自領(lǐng)先供應(yīng)商的定制的專用于某些計算場景的DSA硬件也提供了安全支持日益提高的自動駕駛水平所需的低延遲、高性能推理。
隨著 DSA 擴展到其他應(yīng)用領(lǐng)域,麥肯錫咨詢估計到 2026 年,DSA 將占約 900 億美元的收入(約占全球半導體市場的 10% 至 15%),高于 2022 年的約 400 億美元。因此,我們看到在這個方向的硬件類的風險投資顯著增加也就不足為奇了。
01 算力革命下的高性能網(wǎng)絡(luò)DSA
隨著人工智能及高性能計算的高速發(fā)展,服務(wù)器集群的瓶頸逐漸從單CPU、GPU、APU的算力轉(zhuǎn)換到硬件間的互聯(lián)能力。傳統(tǒng)的數(shù)據(jù)中心架構(gòu)中包含CPU、內(nèi)存、存儲和網(wǎng)絡(luò)等組件,但CPU目前已經(jīng)公認不再是運行基礎(chǔ)設(shè)施功能的最佳位置了。對于下一代數(shù)據(jù)中心而言,面向網(wǎng)絡(luò)加速的DSA將扮演重要的角色,根據(jù)不同應(yīng)用場景的需求,加速數(shù)據(jù)傳輸。同時,以太網(wǎng)速度從25G增加到100G、200G、400G,再到800G,甚至還有持續(xù)增長的趨勢,超大規(guī)模數(shù)據(jù)中心的硬件架構(gòu)在逐漸轉(zhuǎn)變。
據(jù)估計,對于超大規(guī)模數(shù)據(jù)中心來說,大約有一半的CPU被用在了非創(chuàng)收型任務(wù)上。網(wǎng)絡(luò)DSA可以承擔大部分繁重的工作,將CPU解放出來,專注于創(chuàng)收的應(yīng)用處理上。同時,由于功能和作用不同,北向網(wǎng)絡(luò)和高帶寬域在設(shè)計時側(cè)重點不同。北向網(wǎng)絡(luò)側(cè)重于網(wǎng)絡(luò)控制與管理,主要是網(wǎng)絡(luò)控制器與上層應(yīng)用之間的接口和通信。高帶寬域網(wǎng)絡(luò)側(cè)重于數(shù)據(jù)傳輸性能,旨在提供高速度、低延遲的網(wǎng)絡(luò)連接。基于RoCE的RDMA技術(shù),兼容現(xiàn)有的以太網(wǎng)基礎(chǔ)設(shè)施,擁抱開放生態(tài),是業(yè)界解決高帶寬域網(wǎng)絡(luò)與北向網(wǎng)絡(luò)數(shù)據(jù)傳輸?shù)闹匾鉀Q方案。
02 Chiplet設(shè)計方法與DSA的完美結(jié)合
結(jié)合Chiplet設(shè)計方法學與DSA的設(shè)計,可以構(gòu)建出高效、靈活且高度定制化的計算平臺。Chiplet設(shè)計方法學通過將處理器設(shè)計拆分為多個獨立的Chiplet,每個Chiplet可以針對特定功能進行優(yōu)化。這樣可以在設(shè)計、制造和測試中提高靈活性。同時,不同的Chiplet分工明確,可以專門處理不同的任務(wù),例如CPU核心、內(nèi)存控制器、I/O接口等。而DSA針對特定計算任務(wù)進行優(yōu)化,例如生成式人工智能、圖形處理、網(wǎng)絡(luò)處理等,相比于通用處理器,DSA在其特定領(lǐng)域內(nèi)具有更高的性能和能效比。
通過Chiplet方法學,可以將多個DSA集成到一個系統(tǒng)中,創(chuàng)建一個高度定制化的平臺。比如,一個系統(tǒng)可以包含CPU、GPU、TPU、DPU等Chiplet,根據(jù)應(yīng)用需求靈活組合。在這一背景下,組件之間的高速可連接對于確保順利快速的數(shù)據(jù)傳輸至關(guān)重要。互聯(lián)標準、帶寬、延遲和低延遲是關(guān)鍵指標。
03奇異摩爾NDSA網(wǎng)絡(luò)加速與無損數(shù)據(jù)傳輸解決方案
在智算中心領(lǐng)域,奇異摩爾 的NDSA互聯(lián)系列產(chǎn)品復用以太網(wǎng)基礎(chǔ)設(shè)施,基于高性能RoCEv2 RDMA引擎,面向智算網(wǎng)絡(luò)通信加速及無損數(shù)據(jù)傳輸?shù)膶S肈SA加速解決方案。
AI原生智能網(wǎng)卡
奇異摩爾的Kiwi NDSA-SNIC AI原生智能網(wǎng)卡針對網(wǎng)絡(luò)數(shù)據(jù)傳輸,基于RoCE V2 RDMA技術(shù),自適應(yīng)網(wǎng)絡(luò)調(diào)度算法,搭載可編程加速核心SDPU,高達800G傳輸帶寬,實現(xiàn)Tb級萬卡集群無損數(shù)據(jù)傳輸。
高性能網(wǎng)絡(luò)加速芯粒
奇異摩爾的高性能網(wǎng)絡(luò)加速芯粒 – Kiwi NDSA互聯(lián)芯粒針對高帶寬域數(shù)據(jù)傳輸,基于RoCEv2 RDMA技術(shù),單芯粒傳輸帶寬高達800G,攜帶UCIe-D2D芯粒可擴展互聯(lián)接口,實現(xiàn)集群內(nèi)TB級的高速通信。
寫在最后,無論是在高性能計算領(lǐng)域還是在人工智能領(lǐng)域,我們會預見更多加速數(shù)據(jù)傳輸?shù)腄SA問世。它們通過提供高吞吐量效率,計算節(jié)點之間的超快速互連,或提升人工智能訓練的效率,為半導體價值鏈的參與者及其客戶帶來更多的革新和挑戰(zhàn)。
-
芯片
+關(guān)注
關(guān)注
459文章
52169瀏覽量
436100 -
人工智能
+關(guān)注
關(guān)注
1804文章
48701瀏覽量
246448 -
奇異摩爾
+關(guān)注
關(guān)注
0文章
54瀏覽量
3659
原文標題:Kiwi Talks | DSA專用領(lǐng)域芯片正在重塑人工智能與高性能計算
文章出處:【微信號:奇異摩爾,微信公眾號:奇異摩爾】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
開售RK3576 高性能人工智能主板
Cognizant將與NVIDIA合作部署神經(jīng)人工智能平臺,加速企業(yè)人工智能應(yīng)用

FPGA+AI王炸組合如何重塑未來世界:看看DeepSeek東方神秘力量如何預測......
GIGABYTE CES 2025全方位展示人工智能計算解決方案
鴻蒙原生頁面高性能解決方案上線OpenHarmony社區(qū) 助力打造高性能原生應(yīng)用
Banana Pi 攜手 ArmSoM 推出人工智能加速 RK3576 CM5 計算模塊
德晟達推出高性能醫(yī)療專用AI一體機
機智云入選廣州市“人工智能+”優(yōu)秀解決方案冊
嵌入式和人工智能究竟是什么關(guān)系?
《AI for Science:人工智能驅(qū)動科學創(chuàng)新》第一章人工智能驅(qū)動的科學創(chuàng)新學習心得
risc-v在人工智能圖像處理應(yīng)用前景分析
FPGA在人工智能中的應(yīng)用有哪些?
人工智能與大模型的關(guān)系與區(qū)別
奇異摩爾上海總部進駐上海浦東科海大樓

人工智能數(shù)據(jù)中心的新型連接解決方案






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論