") 利用NVIDIA RAPIDS加速DolphinDB Shark平臺提升計算性能
利用NVIDIA RAPIDS加速DolphinDB Shark平臺提升計算性能
DolphinDB 是一家高性能數據庫研發(fā)企業(yè),也是 NVIDIA 初創(chuàng)加速計劃成員,其開發(fā)的產品基于高性能分布式時序數據庫,是支持復雜計算和流數據分析的實時計算平臺,適用于金融、電力、物聯網和零售等行業(yè)。
DolphinDB 公司推出的 CPU-GPU 異構計算平臺 Shark,將 DolphinDB 上的復雜指標計算能力無縫切換到 GPU 算力平臺,從而大幅提升了計算性能。
DolphinDB 開發(fā)團隊與 NVIDIA 團隊合作,通過利用NVIDIA RAPIDS加速 Shark 異構計算平臺的因子挖掘算法運行效率,幫助 Shark 將因子挖掘的效率提升 2 - 10 倍,并基于NVIDIA cuDF實現 Shark 因子高效計算,大幅減少開發(fā)成本,縮短開發(fā)周期。
RAPIDS 的 RMM 是一套開源的內存/顯存管理庫,提供 C++ 和 Python 接口,相比 cuMalloc、cuFree 等操作來講,具有更好的性能和靈活性;RAPIDS libcudf 是基于 GPU 的 C++ DataFrame 庫,提供了基礎數據結構,并且內置了基礎的函數算子。
Shark 的因子挖掘功能,能通過利用遺傳算法從數據中挖掘出有效的因子。在這一場景中,遺傳算法會隨機生成大量因子并進行計算。這一過程會頻繁地創(chuàng)建和釋放臨時空間來存儲中間結果,直接使用原生的 CUDA C 顯存分配和釋放接口,會嚴重降低執(zhí)行效率。
Shark 的因子計算功能,針對金融領域的數據分析與處理,提供了豐富的函數庫。如果從零開始將 CPU 的函數遷移至 GPU,需要為 GPU 重新實現一套底層數據結構以及基礎計算函數,會導致開發(fā)周期的延長以及開發(fā)成本的增加。
基于以上挑戰(zhàn),DolphinDB 開發(fā)團隊與 NVIDIA 團隊及 RAPIDS 開發(fā)團隊合作,通過利用 RAPIDS RMM,解決因子挖掘過程中頻繁申請和釋放顯存導致的性能問題;通過基于 RAPIDS libcudf 進行二次開發(fā),實現因子計算,從而縮短開發(fā)周期,降低開發(fā)成本。
Shark 進行因子挖掘時,會通過遺傳算法隨機生成海量的因子計算公式。這些公式長度不等,接受的參數數量也不盡相同。因此在計算時,需要頻繁地申請和釋放臨時空間用于存儲中間結果。DolphinDB 開發(fā)團隊通過使用 RMM 對顯存進行池化,從而對中間結果所使用的顯存進行高效地分配、釋放和重用。
Shark 支持用戶輸入自定義的公式,自動將自定義公式轉換為計算圖,并在 GPU 完成計算,從而加快數據分析和處理的效率。如果從零開始將 DolphinDB 的計算函數遷移至 Shark,則需要在 GPU 構建 array、table 等底層數據結構,并實現大量基礎計算函數。經過調研后,DolphinDB 開發(fā)團隊決定基于 RAPIDS libcudf 進行二次開發(fā),復用 cuDF 的 column、table 等底層數據結構,并借助 cuDF 的 groupby 和 rolling 框架,只需要完成算子的核心計算邏輯,即可完成 DolphinDB 時序算子和橫截面算子的遷移,這樣不僅極大提升了開發(fā)效率,還降低了開發(fā)成本。
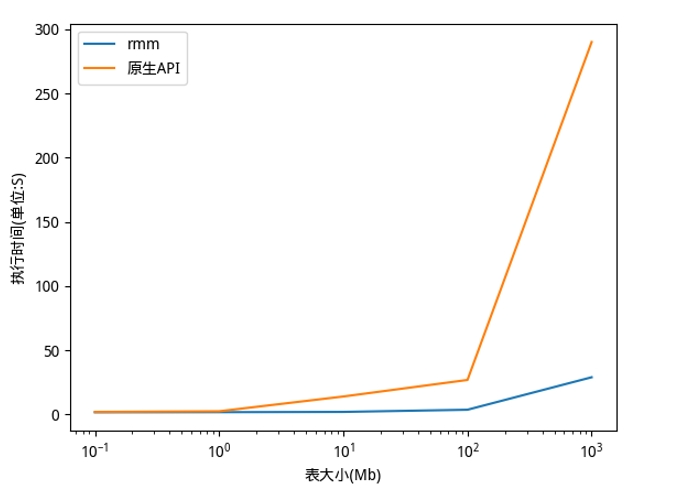
下圖展示了在不同規(guī)模數據下,使用 RAPIDS 的 RMM 顯存管理庫相對于原生的 CUDA 顯存分配 API,Shark 因子挖掘效率的對比。可以清楚地看到,使用 RMM 可以顯著提升 Shark 因子挖掘效率,最高可達到 10 倍的加速比。
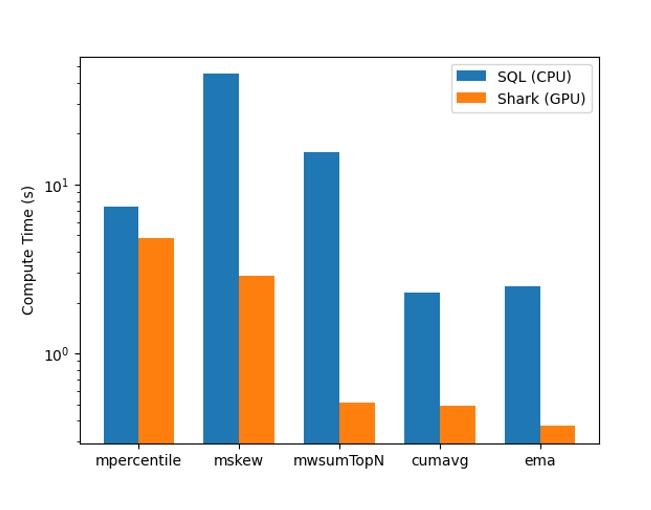
除此之外,Shark 通過使用 RAPIDS libcudf,大大提升了因子的計算效率。下圖中對比了 1000 個 group,每個 group 有 10 萬行的數據,采用分組方式計算下面的算子。可以看到與 CPU 相比,利用 GPU 總體耗時(包含拷貝時間),基本達到了一個數量級的加速比。
借助 RAPIDS ,Shark 的因子挖掘效率提升了 10 倍。除此之外,基于 cuDF 進行二次開發(fā),只需要實現算子的核心邏輯,就可以達到一個數量級的加速,并極大降低了算子遷移成本。
-
NVIDIA
+關注
關注
14文章
5246瀏覽量
105774 -
gpu
+關注
關注
28文章
4912瀏覽量
130661 -
數據庫
+關注
關注
7文章
3901瀏覽量
65778
原文標題:NVIDIA RAPIDS 助力 Shark 平臺實現高效數據挖掘和計算
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
英偉達GTC2025亮點:NVIDIA Blackwell加速計算機輔助工程軟件,實現實時數字孿生性能數量級提升
GPU加速計算平臺的優(yōu)勢
利用NVIDIA DPF引領DPU加速云計算的未來
NVIDIA助力FinCatch開發(fā)智能投資輔助系統
借助NVIDIA GPU提升魯班系統CAE軟件計算效率
《CST Studio Suite 2024 GPU加速計算指南》
將NVIDIA加速計算引入Polars

使用NVIDIA TensorRT提升Llama 3.2性能
RAPIDS cuDF將pandas提速近150倍

NVIDIA加速計算如何推動醫(yī)療健康
NVIDIA向開放計算項目捐贈Blackwell平臺設計
AI高性能計算平臺是什么
“跨越數據邊界:企業(yè)級實時計算平臺構想——2024 DolphinDB 年度峰會

以實時,見未來——DolphinDB 2024 年度峰會圓滿舉辦






 工商網監(jiān)
工商網監(jiān)
評論