") 一文詳解機(jī)器學(xué)習(xí)工程師必知的10大算法
一文詳解機(jī)器學(xué)習(xí)工程師必知的10大算法
毫無疑問,機(jī)器學(xué)習(xí)/人工智能的子領(lǐng)域在過去幾年越來越受歡迎。目前大數(shù)據(jù)在科技行業(yè)已經(jīng)炙手可熱,而基于大量數(shù)據(jù)來進(jìn)行預(yù)測(cè)或者得出建議的機(jī)器學(xué)習(xí)無疑是非常強(qiáng)大的。一些最常見的機(jī)器學(xué)習(xí)例子,比如Netflix的算法可以根據(jù)你以前看過的電影來進(jìn)行電影推薦,而Amazon的算法則可以根據(jù)你以前買過的書來推薦書籍。
所以如果你想了解更多有關(guān)機(jī)器學(xué)習(xí)的內(nèi)容,那么你該如何入門?對(duì)于我來說,我的入門課程是我在哥本哈根出國(guó)留學(xué)時(shí)參加的人工智能課。當(dāng)時(shí)我的講師是丹麥技術(shù)大學(xué)(Technical University of Denmark)的應(yīng)用數(shù)學(xué)和計(jì)算機(jī)科學(xué)的全職教授,他的研究方向是邏輯與人工智能,側(cè)重于使用邏輯學(xué)來對(duì)人性化的規(guī)劃、推理和解決問題進(jìn)行建模。這個(gè)課程包括對(duì)理論/核心概念的討論和自己動(dòng)手解決問題。我們使用的教材是AI經(jīng)典之一:Peter Norvig的Artificial Intelligence—A Modern Approach(中文譯本:《人工智能:一種現(xiàn)代的方法》),這本書主要講了智能體、搜索解決問題、對(duì)抗搜索、概率論、多智能體系統(tǒng)、社會(huì)AI和AI的哲學(xué)/倫理/未來等等。在課程結(jié)束時(shí),我們?nèi)齻€(gè)人的團(tuán)隊(duì)實(shí)現(xiàn)了一個(gè)簡(jiǎn)單的編程項(xiàng)目,也就是基于搜索的智能體解決虛擬環(huán)境中的運(yùn)輸任務(wù)問題。
在那門課程上我已經(jīng)學(xué)到了很多知識(shí),并決定繼續(xù)學(xué)習(xí)相關(guān)的課題。在過去的幾個(gè)星期里,我在舊金山參加了多次相關(guān)的技術(shù)講座,涉及到深度學(xué)習(xí)、神經(jīng)網(wǎng)絡(luò)和數(shù)據(jù)結(jié)構(gòu),并且參加了一個(gè)有很多該領(lǐng)域的知名專家學(xué)者參加的機(jī)器學(xué)習(xí)會(huì)議。最重要的是,我在6月初參加了Udacity上的Intro to Machine Learning(機(jī)器學(xué)習(xí)入門)在線課程,前幾天才完成。在這篇文章中,我想分享一下我從課程中學(xué)到的一些最常用的機(jī)器學(xué)習(xí)算法。
機(jī)器學(xué)習(xí)算法可以分為三大類:監(jiān)督學(xué)習(xí)、無監(jiān)督學(xué)習(xí)和強(qiáng)化學(xué)習(xí)。監(jiān)督學(xué)習(xí)可用于一個(gè)特定的數(shù)據(jù)集(訓(xùn)練集)具有某一屬性(標(biāo)簽),但是其他數(shù)據(jù)沒有標(biāo)簽或者需要預(yù)測(cè)標(biāo)簽的情況。無監(jiān)督學(xué)習(xí)可用于給定的沒有標(biāo)簽的數(shù)據(jù)集(數(shù)據(jù)不是預(yù)分配好的),目的就是要找出數(shù)據(jù)間的潛在關(guān)系。強(qiáng)化學(xué)習(xí)位于這兩者之間,每次預(yù)測(cè)都有一定形式的反饋,但是沒有精確的標(biāo)簽或者錯(cuò)誤信息。因?yàn)檫@是一個(gè)介紹課程,我沒有學(xué)習(xí)過強(qiáng)化學(xué)習(xí)的相關(guān)內(nèi)容,但是我希望以下10個(gè)關(guān)于監(jiān)督學(xué)習(xí)和無監(jiān)督學(xué)習(xí)的算法足以讓你感興趣。
監(jiān)督學(xué)習(xí)
1.決策樹(Decision Trees)
決策樹是一個(gè)決策支持工具,它使用樹形圖或者決策模型以及可能性序列,包括偶然事件的結(jié)果、資源成本和效用。下圖是其基本原理:

從業(yè)務(wù)決策的角度來看,決策樹是人們必須了解的最少的是/否問題,這樣才能評(píng)估大多數(shù)時(shí)候做出正確決策的概率。作為一種方法,它允許你以結(jié)構(gòu)化和系統(tǒng)化的方式來解決問題,從而得出合乎邏輯的結(jié)論。
2.樸素貝葉斯分類(Naive Bayesian classification)
樸素貝葉斯分類器是一類簡(jiǎn)單的概率分類器,它基于貝葉斯定理和特征間的強(qiáng)大的(樸素的)獨(dú)立假設(shè)。圖中是貝葉斯公式,其中P(A|B)是后驗(yàn)概率,P(B|A)是似然,P(A)是類先驗(yàn)概率,P(B)是預(yù)測(cè)先驗(yàn)概率。
一些應(yīng)用例子:
判斷垃圾郵件
對(duì)新聞的類別進(jìn)行分類,比如科技、政治、運(yùn)動(dòng)
判斷文本表達(dá)的感情是積極的還是消極的
人臉識(shí)別
3.最小二乘法(Ordinary Least Squares Regression)
如果你懂統(tǒng)計(jì)學(xué)的話,你可能以前聽說過線性回歸。最小二乘法是一種計(jì)算線性回歸的方法。你可以將線性回歸看做通過一組點(diǎn)來擬合一條直線。實(shí)現(xiàn)這個(gè)有很多種方法,“最小二乘法”就像這樣:你可以畫一條直線,然后對(duì)于每一個(gè)數(shù)據(jù)點(diǎn),計(jì)算每個(gè)點(diǎn)到直線的垂直距離,然后把它們加起來,那么最后得到的擬合直線就是距離和盡可能小的直線。
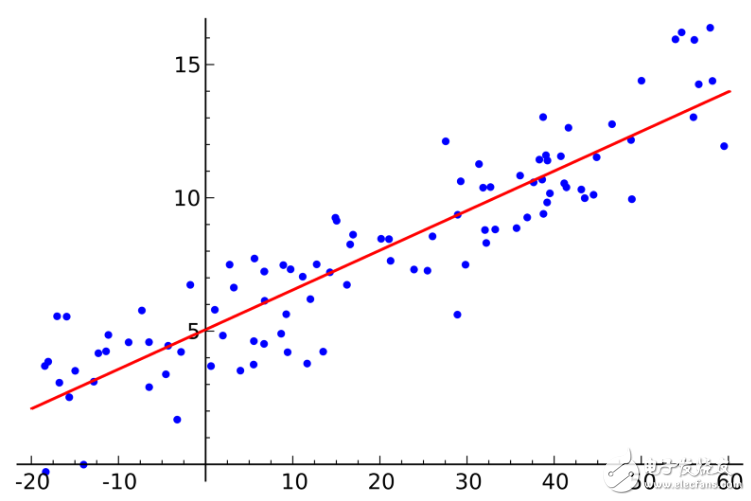
線性指的是你用來擬合數(shù)據(jù)的模型,而最小二乘法指的是你最小化的誤差度量。
4.邏輯回歸(Logistic Regression)
邏輯回歸是一個(gè)強(qiáng)大的統(tǒng)計(jì)學(xué)方法,它可以用一個(gè)或多個(gè)解釋變量來表示一個(gè)二項(xiàng)式結(jié)果。它通過使用邏輯函數(shù)來估計(jì)概率,從而衡量類別依賴變量和一個(gè)或多個(gè)獨(dú)立變量之間的關(guān)系,后者服從累計(jì)邏輯分布。
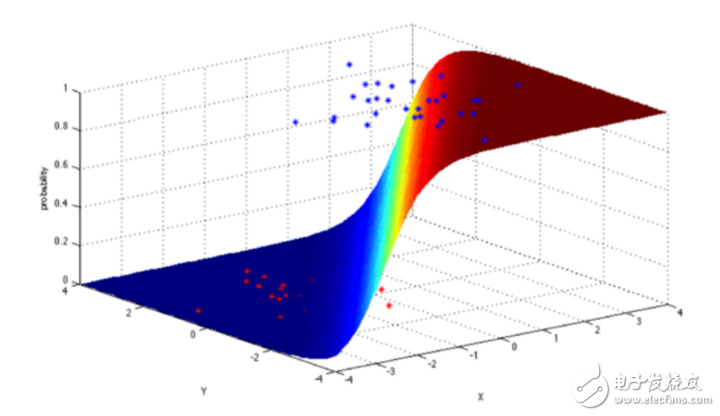
總的來說,邏輯回歸可以用于以下幾個(gè)真實(shí)應(yīng)用場(chǎng)景:
信用評(píng)分
計(jì)算營(yíng)銷活動(dòng)的成功率
預(yù)測(cè)某個(gè)產(chǎn)品的收入
特定的某一天是否會(huì)發(fā)生地震
5.支持向量機(jī)(Support Vector Machine,SVM)
SVM是二進(jìn)制分類算法。給定N維坐標(biāo)下兩種類型的點(diǎn),SVM生成(N-1)維的超平面來將這些點(diǎn)分成兩組。假設(shè)你在平面上有兩種類型的可以線性分離的點(diǎn),SVM將找到一條直線,將這些點(diǎn)分成兩種類型,并且這條直線盡可能遠(yuǎn)離所有這些點(diǎn)。
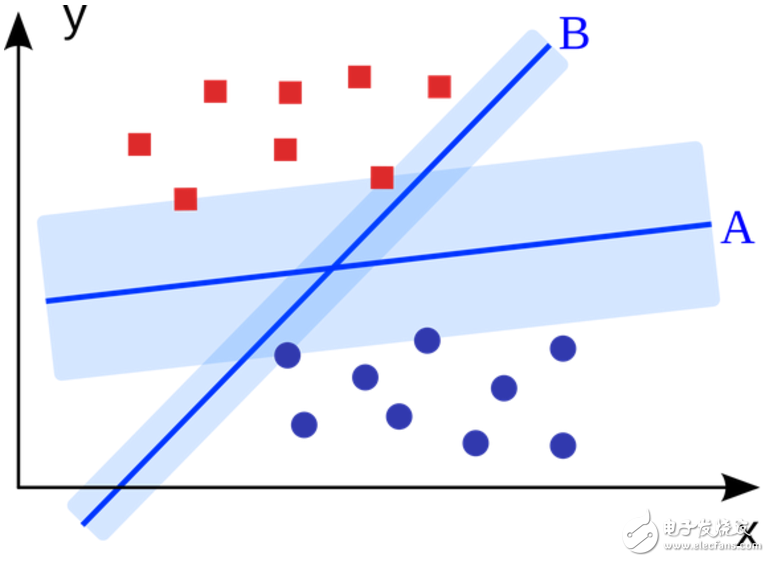
從規(guī)模上看,使用SVM(經(jīng)過適當(dāng)?shù)男薷模┙鉀Q的一些最大的問題包括顯示廣告、人類剪切位點(diǎn)識(shí)別(human splice site recognition)、基于圖像的性別檢測(cè),大規(guī)模圖像分類……
6.集成方法(Ensemble methods)
集成方法是學(xué)習(xí)算法,它通過構(gòu)建一組分類器,然后通過它們的預(yù)測(cè)結(jié)果進(jìn)行加權(quán)投票來對(duì)新的數(shù)據(jù)點(diǎn)進(jìn)行分類。原始的集成方法是貝葉斯平均,但是最近的算法包括糾錯(cuò)輸出編碼、Bagging和Boosting。
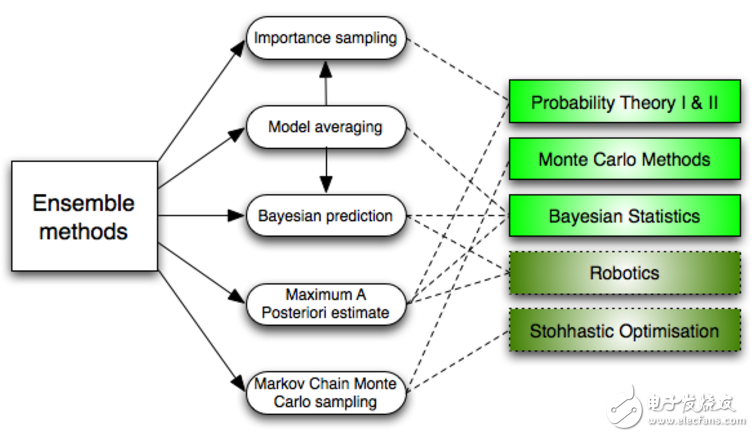
那么集成方法如何工作?并且為什么它們要優(yōu)于單個(gè)模型?
它們平均了單個(gè)模型的偏差:如果你將民主黨的民意調(diào)查和共和黨的民意調(diào)查在一起平均化,那么你將得到一個(gè)均衡的結(jié)果,不偏向任何一方。
它們減少了方差:一組模型的總體意見比其中任何一個(gè)模型的單一意見更加統(tǒng)一。在金融領(lǐng)域,這就是所謂的多元化,有許多股票的組合比一個(gè)單獨(dú)的股票的不確定性更少,這也為什么你的模型在數(shù)據(jù)多的情況下會(huì)更好的原因。
它們不太可能過擬合:如果你有單個(gè)的模型沒有過擬合,那么把這些模型的預(yù)測(cè)簡(jiǎn)單結(jié)合起來(平均、加權(quán)平均、邏輯回歸),那么最后得到的模型也不會(huì)過擬合。
無監(jiān)督學(xué)習(xí)
7.聚類算法(Clustering Algorithms)
聚類是將一系列對(duì)象分組的任務(wù),目標(biāo)是使相同組(集群)中的對(duì)象之間比其他組的對(duì)象更相似。
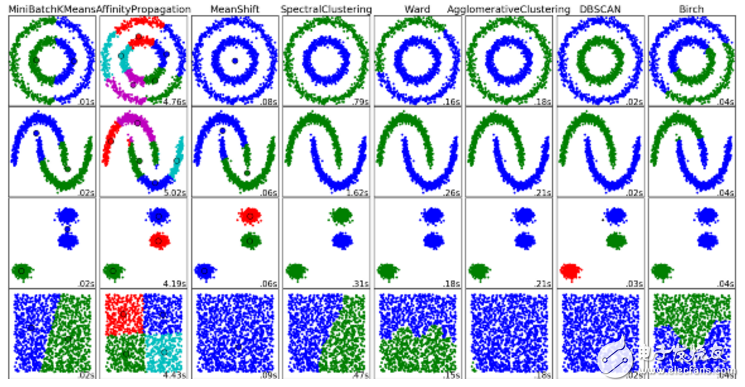
每一種聚類算法都不相同,下面是一些例子:
基于質(zhì)心的算法
基于連接的算法
基于密度的算法
概率
降維
神經(jīng)網(wǎng)絡(luò)/深度學(xué)習(xí)
8.主成分分析(Principal Component Analysis,PCA)
PCA是一個(gè)統(tǒng)計(jì)學(xué)過程,它通過使用正交變換將一組可能存在相關(guān)性的變量的觀測(cè)值轉(zhuǎn)換為一組線性不相關(guān)的變量的值,轉(zhuǎn)換后的變量就是所謂的主分量。
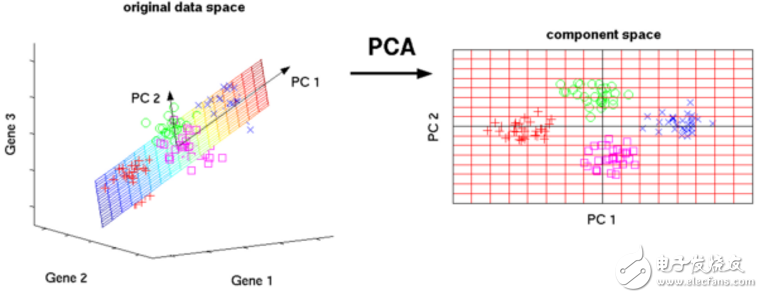
PCA的一些應(yīng)用包括壓縮、簡(jiǎn)化數(shù)據(jù)便于學(xué)習(xí)、可視化等。請(qǐng)注意,領(lǐng)域知識(shí)在選擇是否繼續(xù)使用PCA時(shí)非常重要。 數(shù)據(jù)嘈雜的情況(PCA的所有成分具有很高的方差)并不適用。
9.奇異值分解(Singular Value Decomposition,SVD)
在線性代數(shù)中,SVD是復(fù)雜矩陣的因式分解。對(duì)于給定的m * n矩陣M,存在分解使得M=UΣV,其中U和V是酉矩陣,Σ是對(duì)角矩陣。
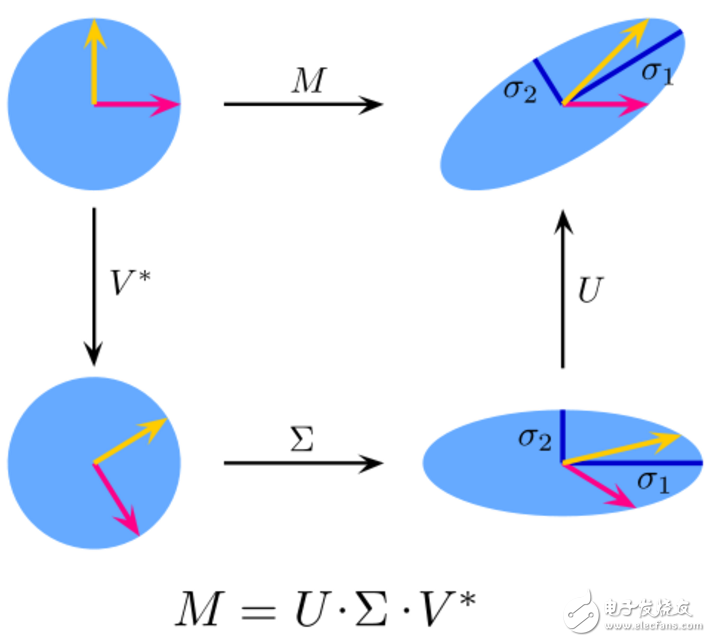
實(shí)際上,PCA是SVD的一個(gè)簡(jiǎn)單應(yīng)用。在計(jì)算機(jī)視覺中,第一個(gè)人臉識(shí)別算法使用PCA和SVD來將面部表示為“特征面”的線性組合,進(jìn)行降維,然后通過簡(jiǎn)單的方法將面部匹配到身份,雖然現(xiàn)代方法更復(fù)雜,但很多方面仍然依賴于類似的技術(shù)。
10.獨(dú)立成分分析(Independent Component Analysis,ICA)
ICA是一種統(tǒng)計(jì)技術(shù),主要用于揭示隨機(jī)變量、測(cè)量值或信號(hào)集中的隱藏因素。ICA對(duì)觀測(cè)到的多變量數(shù)據(jù)定義了一個(gè)生成模型,這通常是作為樣本的一個(gè)大的數(shù)據(jù)庫。在模型中,假設(shè)數(shù)據(jù)變量由一些未知的潛在變量線性混合,混合方式也是未知的。潛在變量被假定為非高斯分布并且相互獨(dú)立,它們被稱為觀測(cè)數(shù)據(jù)的獨(dú)立分量。
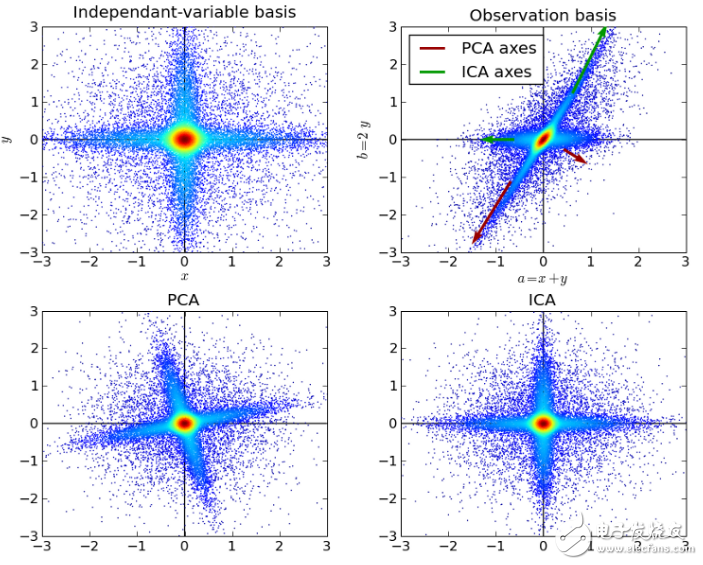
ICA與PCA有關(guān),但是當(dāng)這些經(jīng)典方法完全失效時(shí),它是一種更強(qiáng)大的技術(shù),能夠找出源的潛在因素。 其應(yīng)用包括數(shù)字圖像、文檔數(shù)據(jù)庫、經(jīng)濟(jì)指標(biāo)和心理測(cè)量。
現(xiàn)在運(yùn)用你對(duì)這些算法的理解去創(chuàng)造機(jī)器學(xué)習(xí)應(yīng)用,為世界各地的人們帶來更好的體驗(yàn)吧。
-
人工智能
+關(guān)注
關(guān)注
1804文章
48691瀏覽量
246418 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8490瀏覽量
134077
發(fā)布評(píng)論請(qǐng)先 登錄
電子電氣工程師必知必會(huì)(第2版)【好書】
[妖精的分享] 電子電氣工程師必知必會(huì)_第2版
機(jī)器學(xué)習(xí)工程師必知的10大算法
電子電氣工程師必知必會(huì)知識(shí)點(diǎn)分享!
本文作者YY碩,來自大疆工程師《機(jī)器人工程師學(xué)習(xí)計(jì)劃》精選資料分享
電子電氣工程師必知必會(huì)(第二版)
詳解嵌入式工程師必知必會(huì)(高清完整中文版)
電子電氣工程師必知必會(huì)_第二版.PDF版
這10個(gè)程序員必知的基礎(chǔ)算法,你都了解嗎?我們一起來學(xué)習(xí)下資料下載






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論