") 集成32GB HBM2e內(nèi)存,AMD Alveo V80加速卡助力傳感器處理、存儲壓縮等
集成32GB HBM2e內(nèi)存,AMD Alveo V80加速卡助力傳感器處理、存儲壓縮等
電子發(fā)燒友網(wǎng)報道(文/黃晶晶)日前,AMD推出Alveo V80加速卡,Versal FPGA自適應(yīng)SoC搭配HBM,可處理計算以及內(nèi)存密集型的工作負載,用于高性能計算、數(shù)據(jù)分析、金融科技、存儲壓縮等等。

突破網(wǎng)絡(luò)訪問和內(nèi)存的瓶頸
此次Alveo V80為何采用HBM高速內(nèi)存,AMD 自適應(yīng)和嵌入式計算事業(yè)部( AECG )高級產(chǎn)品線經(jīng)理Shyam Chander分析,在傳統(tǒng)的處理器架構(gòu)中,無論是存儲器還是網(wǎng)絡(luò)訪問都容易形成瓶頸。網(wǎng)絡(luò)接口只支持25G、100G,內(nèi)存采用DDR而FPGA的帶寬遠高于內(nèi)存提供的帶寬。
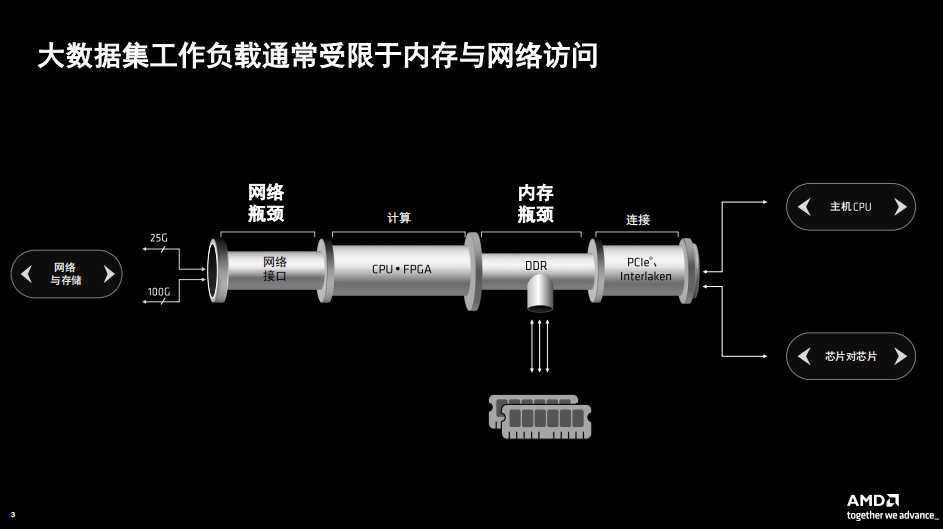
那么Alveo V80針對于這兩個問題進行了優(yōu)化,帶來顯著的性能提升。內(nèi)存采用高帶寬存儲器HBM2e,提供820 GB/s 的存儲器帶寬,容量達32GB。網(wǎng)絡(luò)訪問上采用QSFP56光纖模塊可以支持從10G到800G的帶寬,支持4X200G,以及4X10G/25G/40G/50G等不同工作模式。

這款加速卡采用全高、3/4 長( FH?L )尺寸規(guī)格,由 AMD Versal HBM 自適應(yīng) SoC 提供支持,具備 2,600,000 個 LUT 邏輯單元的 FPGA 架構(gòu)、10,848 個 DSP 計算邏輯片以及 820 GB/s 的存儲器帶寬。

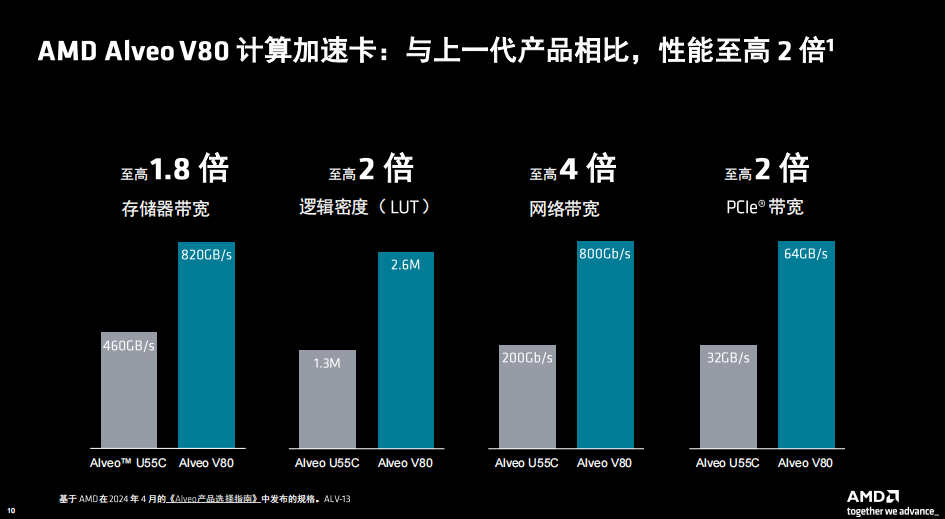
與前代產(chǎn)品 AMD Alveo U55C 計算加速卡相比,Alveo V80 的邏輯密度至高翻倍、存儲器帶寬至高翻倍且網(wǎng)絡(luò)帶寬可高至 4 倍,可以實現(xiàn)強大的計算集群,同時還能優(yōu)化卡、服務(wù)器數(shù)量以及機架空間。
Alveo V80還配有32GB DDR DIMM擴展插槽,MCIO擴展端口可直連NVMe驅(qū)動器,實現(xiàn)存儲卡的連接。系統(tǒng)連接總線支持PCIe 5.0接口,可達64GB/秒傳輸速率。整卡功率300W,采用被動散熱,總熱設(shè)計功耗TDP則取決于器件和服務(wù)器。
V80集成高帶寬網(wǎng)絡(luò)核心600G以太網(wǎng)和400G加密引擎,硬化基礎(chǔ)設(shè)施連接包括DDR控制器、支持DMA的PCIe 5.0、可編程片上網(wǎng)絡(luò)。Shyam Chander表示,基于這些硬化的功能,用戶沒有必要使用軟性的IP進行部署。

通常來說,傳統(tǒng)的加速卡(如GPU)要與CPU進行連接,這會限制能夠使用的加速卡的數(shù)量。但是V80能夠避開CPU到加速卡的PCle瓶頸、低時延處理傳入的網(wǎng)絡(luò)數(shù)據(jù),消除分立式網(wǎng)絡(luò)接口卡、實現(xiàn)每服務(wù)器的卡數(shù)和計算密度最大化。同時,按照需求以網(wǎng)絡(luò)限速的方式管理傳入的數(shù)據(jù),包括在線加密、數(shù)據(jù)包監(jiān)控、傳感器處理等等。
傳統(tǒng)架構(gòu)是固定的緩存層次用于數(shù)據(jù)的讀取和寫入,不規(guī)則的訪問模式會降低效率。而V80的自適應(yīng)計算,擁有靈活的架構(gòu),在計算附近分配內(nèi)存,從而降低延遲和低功耗,并可以靈活適應(yīng)自定義的數(shù)據(jù)類型和數(shù)據(jù)遷移。
AMD同時提供設(shè)計示例AVED,可在GitHub上獲取,以及用戶可繼續(xù)使用 Vivado設(shè)計套件,從而硬件開發(fā)者能夠更快地上手,助其縮短開發(fā)上市時間。
大規(guī)模加速內(nèi)存密集型工作負載
Alveo V80加速卡可以應(yīng)對很多大數(shù)據(jù)工作負載,包括高性能計算,包括基因組學(xué)和傳感器處理、數(shù)據(jù)分析(像欺詐檢測);金融科技,包括風(fēng)險分析和算法交易;還有網(wǎng)絡(luò)安全,像數(shù)據(jù)包監(jiān)控;存儲壓縮,這是一個非常關(guān)鍵的工作負載。另外在AI計算領(lǐng)域,包括推薦引擎和大語言模型等等。因此可以幫助客戶大規(guī)模加速以上工作負載,可以加快數(shù)據(jù)處理的速度,同時還能夠進行實時的洞見和分析。

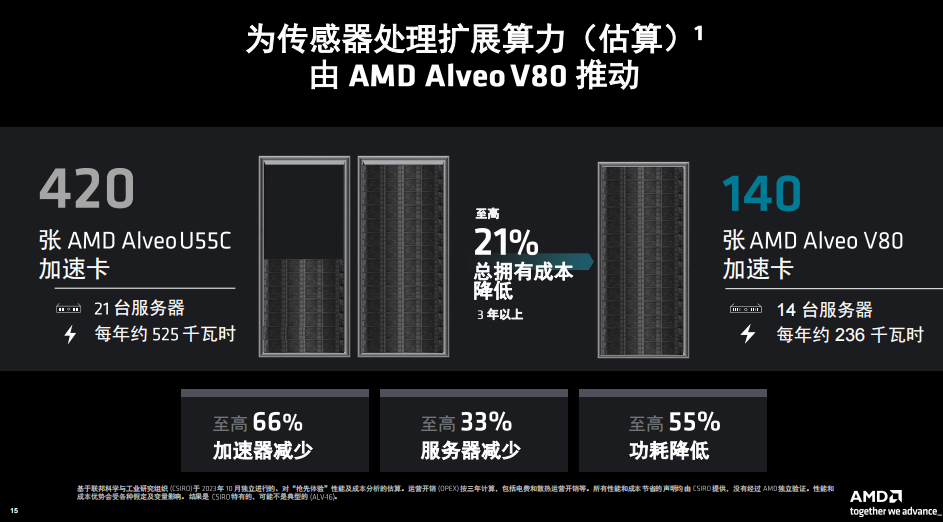
以傳感器處理為例,聯(lián)邦科學(xué)與工業(yè)研究組織( CSIRO )是澳大利亞的國立研究組織,其參與建造了世界上最大的射電天文學(xué)天線陣列,該天線陣列目前包含 420 張 Alveo U55C 加速器卡用于處理無線電波,以研究早期宇宙并探索星系演化。
CSIRO計劃借助 Alveo V80 加速卡縮減占板面積與成本,并將所需加速卡的數(shù)量精簡多達 66%,同時應(yīng)對來自望遠鏡 131,000 個天線的新信號處理任務(wù)。考慮到卡、服務(wù)器、機架空間和功耗的潛在減少,每卡算力的躍升預(yù)計可帶來至高 20% 總擁有成本( TCO )下降。
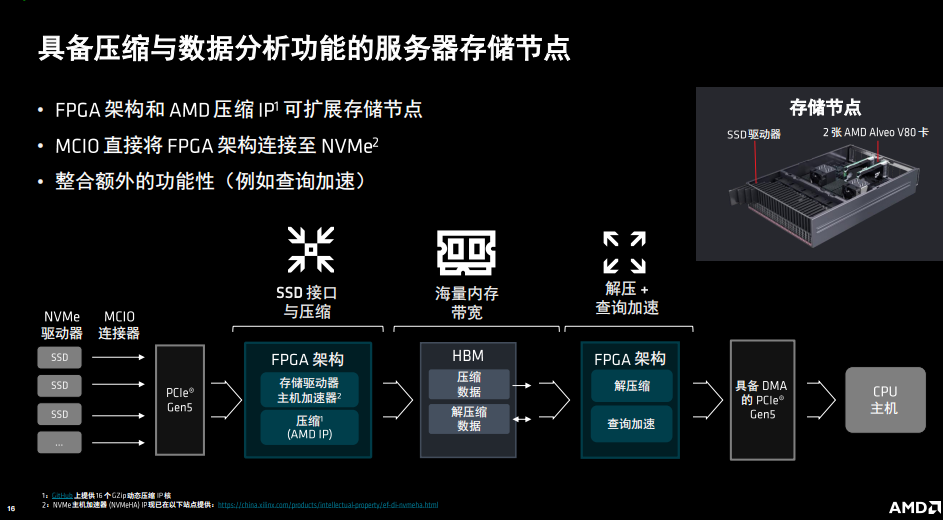
還有具備壓縮與數(shù)據(jù)分析功能的服務(wù)器存儲節(jié)點的例子,通過Alveo V80進行壓縮,利用FPGA架構(gòu)和AMD壓縮IP可擴展存儲節(jié)點,并可解壓縮,查詢加速等。
從總擁有成本的角度來分析,比如10Pb數(shù)據(jù)存儲,沒有壓縮時需要55臺服務(wù)器,1303個SSD驅(qū)動器,每年約427千瓦時的功耗。如果進行壓縮,同樣10Pb數(shù)據(jù),只需要21臺服務(wù)器,504個SSD驅(qū)動器,每年約233千瓦時,使用42張AMD Alveo V80卡進行壓縮,總擁有成本三年以上至高可以達到56%的降低,而且服務(wù)器的數(shù)量、服務(wù)器成本以及功耗也都有非常顯著的降低。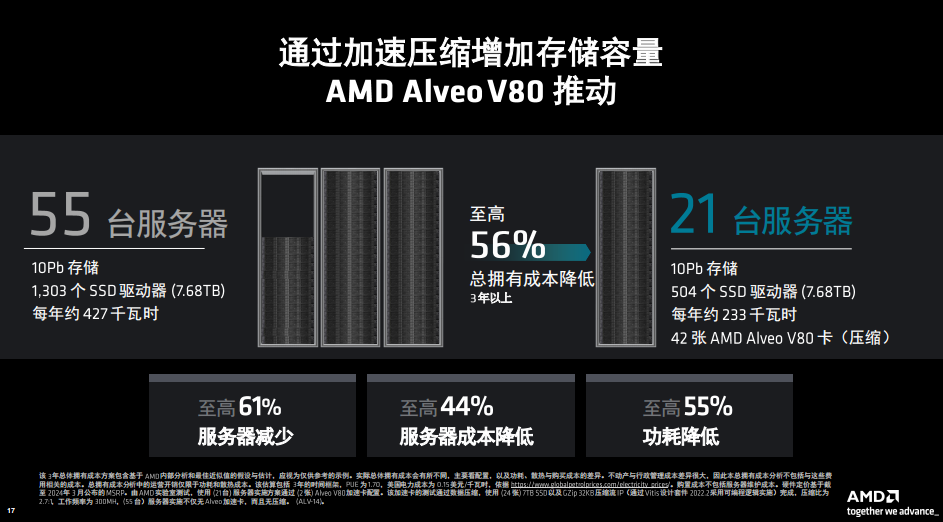
小結(jié):
市面上加速卡也有GPU、ASIC等,但這些加速卡各有所長。Shyam Chander表示,相較而言GPU擅長浮點、并聯(lián)、定點,F(xiàn)PGA擅長線上訪問的實時處理,而且低時延、靈活應(yīng)變,有非常豐富的存儲器架構(gòu)資源。AMD Alveo系列產(chǎn)品主要針對內(nèi)聯(lián)網(wǎng)絡(luò)、實時處理比如傳感器的實時處理、金融科技的需求,他們的訴求點在于低時延和靈活應(yīng)變,F(xiàn)PGA的自適應(yīng)SoC就是極好的解決方案。
另外,HBM的價格雖然高于DDR,但是如果能夠正確地配置FPGA資源,最終就能實現(xiàn)高性價比的競爭優(yōu)勢。在產(chǎn)品路線上,全面看待工作負載方面的要求,也在考慮引入HBM3等存儲。
-
FPGA
+關(guān)注
關(guān)注
1643文章
21968瀏覽量
614296 -
amd
+關(guān)注
關(guān)注
25文章
5566瀏覽量
135916 -
AI
+關(guān)注
關(guān)注
87文章
34294瀏覽量
275476 -
HBM
+關(guān)注
關(guān)注
1文章
408瀏覽量
15121
發(fā)布評論請先 登錄
華強北TF卡回收 內(nèi)存卡回收
AMD Alveo媒體加速產(chǎn)品組合SDK 1.2.1發(fā)布
特斯拉欲將HBM4用于自動駕駛,內(nèi)存大廠加速HBM4進程
基于Xilinx XCKU115的半高PCIe x8 硬件加速卡

2.34納秒超低時延,滿足金融市場高頻交易,AMD發(fā)布新一代金融加速卡

AMD Alveo V80計算加速器網(wǎng)絡(luò)研討會
AMD 以全球極快的纖薄尺寸電子交易加速卡擴展 Alveo 產(chǎn)品組合,助力廣泛且具性價比的服務(wù)器部署






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論