 基于雙級優化(BLO)的消除過擬合的微調方法
基于雙級優化(BLO)的消除過擬合的微調方法
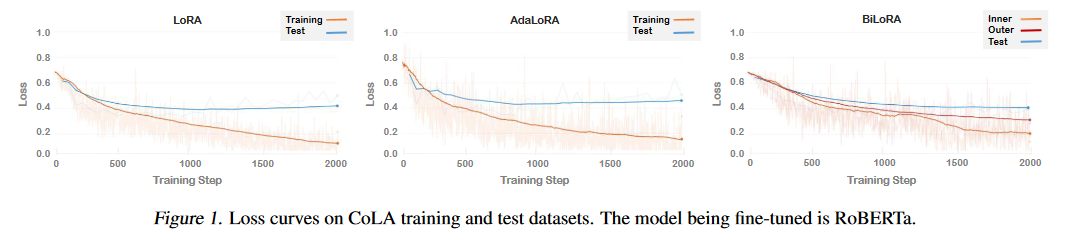
摘要:低秩適應(LoRA)是在下游任務中通過學習低秩增量矩陣對大規模預訓練模型進行微調的一種流行方法。雖然與完全微調方法相比,LoRA 及其變體能有效減少可訓練參數的數量,但它們經常會對訓練數據進行過擬合,導致測試數據的泛化效果不理想。為了解決這個問題,我們引入了 BiLoRA,這是一種基于雙級優化(BLO)的消除過擬合的微調方法。BiLoRA 采用偽奇異值分解來參數化低秩增量矩陣,并將偽奇異向量和偽奇異值的訓練分成兩個不同的訓練數據子集。這種分割嵌入了 BLO 框架的不同層次,降低了對單一數據集過度擬合的風險。BiLoRA 在涵蓋自然語言理解和生成任務的十個數據集上進行了測試,并應用于各種著名的大型預訓練模型,在可訓練參數數量相似的情況下,BiLoRA 明顯優于 LoRA 方法和其他微調方法。

https://arxiv.org/abs/2403.13037
Q1: 這篇論文試圖解決什么問題?
A:這篇論文試圖解決的問題是大型預訓練模型在下游任務中進行微調時出現的過擬合問題。盡管低秩適應(LoRA)及其變體通過學習低秩增量矩陣有效地減少了與完全微調方法相比的可訓練參數數量,但這些方法往往容易過擬合訓練數據,導致在測試數據上泛化性能不佳。為了解決這個問題,論文引入了基于雙層優化(BLO)的BiLoRA方法,通過在不同的訓練數據子集上分別訓練偽奇異向量和奇異值來減輕過擬合的風險。
Q2: 有哪些相關研究?
A:這篇論文提到了幾項與BiLoRA相關的研究領域,具體包括:
低秩適應(Low-Rank Adaptation, LoRA):
Li et al. (2018) 和 Aghajanyan et al. (2020) 展示了預訓練模型具有很低的內在維度,并且可以通過使用低秩參數化來實現與全參數微調相當的性能。
Hu et al. (2021) 提出了LoRA,通過將低秩更新矩陣引入到預訓練的權重矩陣中來實現。
其他方法如DyLoRA (Valipour et al., 2022),QLoRA (Dettmers et al., 2023),和LoraHub (Huang et al., 2023) 旨在提高LoRA的效率和性能。
雙層優化(Bi-level Optimization, BLO):
BLO在元學習(Finn et al., 2017; Rajeswaran et al., 2019),超參數優化(Franceschi et al., 2017; Lorraine et al., 2020),神經架構搜索(Liu et al., 2018; Zhang et al., 2021),強化學習(Rajeswaran et al., 2020)等領域得到了廣泛應用。
提出了多種算法來解決這種特定形式的優化問題,包括零階方法如貝葉斯優化(Cui & Bai, 2019),一階算法基于超梯度(Pearlmutter & Siskind, 2008; Lorraine et al., 2020)等。
其他微調方法:
Full Fine-Tuning (FT) 是一種常用的適應方法,涉及對所有模型參數進行梯度更新。
Bias-only 或 BitFit (Zaken et al., 2021) 只訓練偏置向量,而保持預訓練模型中的其他參數不變。
Prefix-embedding tuning 和 Prefix-layer tuning 是在輸入嵌入或Transformer層之間插入可訓練的特定參數。
Adapter tuning (Houlsby et al., 2019) 通過在神經模塊之間插入適配器來適應模型。
這些相關研究為BiLoRA的開發提供了理論基礎和技術背景。BiLoRA通過結合LoRA的低秩更新和BLO的雙層優化策略,旨在提高大型預訓練模型在特定下游任務中的泛化能力和微調效率。
Q3: 論文如何解決這個問題?
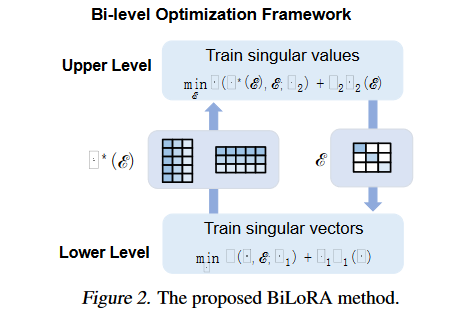
A:為了解決大型預訓練模型在下游任務微調時的過擬合問題,論文提出了BiLoRA(Bi-level Optimization Framework for Overfitting-Resilient Low-Rank Adaptation)方法,具體解決方案如下:
雙層優化(Bi-level Optimization, BLO):
BiLoRA采用雙層優化框架,將參數學習分為兩個層次。在較低層次,優化偽奇異向量(P和Q),在較高層次,優化偽奇異值(Λ)。
參數化低秩增量矩陣:
類似于奇異值分解(SVD),每個低秩增量矩陣?W被參數化為?W = PΛQ,其中P和Q是偽左/右奇異向量矩陣,Λ是偽奇異值對角矩陣。
通過正則化項(R1)鼓勵P和Q的近似正交性。
分離訓練過程:
在較低層次,固定Λ,僅在訓練數據集D1的一個子集上訓練P和Q。
在較高層次,使用從較低層次得到的最優P和Q(記為V*(Λ)),在剩余的數據集D2上訓練Λ。
迭代優化:
通過迭代方式交替解決兩個層次的優化問題,直到收斂。
正則化偽奇異值:
提供了三種偽奇異值的參數化形式:實值(Real-Value)、Softmax和近似二值(Approximately Binary),以控制不同奇異向量對最終模型的貢獻。
高效的訓練框架:
利用基于梯度的優化算法,特別是針對高維問題和大量可訓練參數的情況。

通過這種方法,BiLoRA能夠在不同的數據子集上分別學習模型的架構(Λ)和候選操作(P和Q),從而有效地減少了對單一數據集的過擬合風險,并提高了模型在測試數據上的泛化性能。論文通過在多個自然語言理解和生成任務的數據集上進行實驗,證明了BiLoRA與其他微調方法相比,在保持相似數量的可訓練參數的同時,能夠取得更好的性能。
Q4: 論文做了哪些實驗?
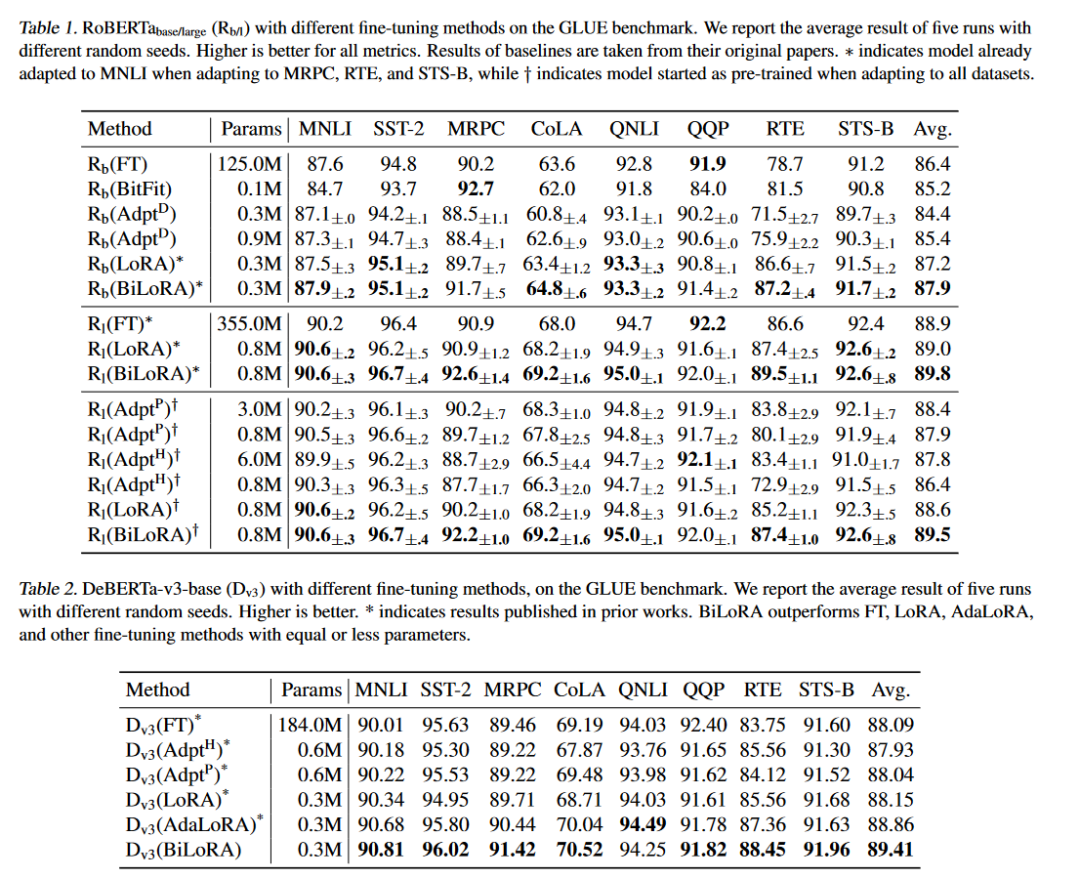
A:論文中進行了一系列的實驗來驗證BiLoRA方法的有效性和性能,具體包括:
自然語言理解(NLU)任務:
在GLUE基準測試上評估了RoBERTa和DeBERTa模型。GLUE包含多種NLU任務,包括情感分析、語義相似性評估、自然語言推理等。
使用開發集作為測試數據,因為GLUE的測試集不公開。
將訓練集分為兩個子集,分別作為雙層優化中的下層(D1)和上層(D2)數據集。
自然語言生成(NLG)任務:
在E2E NLG挑戰賽上評估了GPT-2中大型模型。這個數據集用于評估端到端、數據驅動的自然語言生成系統。
遵循Prefix-Tuning和LoRA的設置,并與LoRA和其他微調方法進行直接比較。
不同參數化形式的實驗:
對偽奇異值的三種參數化形式(Real Value、Softmax和Approximately Binary)進行了實驗,以評估它們對模型性能的影響。
超參數γ1的影響分析:
分析了正交性促進正則化項中超參數γ1的不同取值對RoBERTa-base性能的影響。
計算成本比較:
比較了LoRA和BiLoRA在訓練時間上的差異,以評估BiLoRA在減少總訓練時間方面的效率。
與其他過擬合緩解方法的比較:
對比了增加權重衰減和采用更激進的秩修剪設置這兩種常見的過擬合緩解方法在AdaLoRA上的效果。
擴展到大型模型的性能評估:
使用DeBERTa-v2xxlarge(1.5億參數)模型評估了BiLoRA在非常大型模型上的擴展性能。
這些實驗覆蓋了從模型微調、正則化策略分析、不同參數化形式的比較,到計算效率和大規模模型適應性的全面評估,充分證明了BiLoRA方法在減少過擬合、提高泛化能力和計算效率方面的優勢。
Q5: 有什么可以進一步探索的點?
A:論文中提到了幾個可以進一步探索的研究方向和潛在的改進點:
偽奇異值的參數化形式:
論文中提出了三種偽奇異值的參數化形式:實值、Softmax和近似二值。未來的研究可以探索更多種類的參數化方法,特別是支持自動秩選擇的參數化形式。
理論分析:
BiLoRA的雙層優化框架提高了微調模型的泛化能力。未來的工作可以對這種優化策略的理論和實際效果進行更深入的分析,以更好地理解其工作原理。
超參數調整:
盡管BiLoRA的超參數調整相對簡單,但進一步的研究可以探索自動化超參數優化技術,例如貝葉斯優化或進化算法,以提高BiLoRA的性能和效率。
不同模型架構的適應性:
論文中的實驗主要針對RoBERTa、DeBERTa和GPT-2模型。BiLoRA方法在其他類型的模型架構上的效果和適用性值得進一步研究。
更廣泛的任務和數據集:
盡管BiLoRA在多個NLU和NLG任務上表現出色,但在更多種類的任務和更大規模的數據集上的性能尚未得到驗證。未來的研究可以在這些方面進行擴展。
計算效率:
盡管BiLoRA已經顯示出比LoRA更少的訓練時間,但仍有進一步提高計算效率的空間,例如通過優化迭代優化步驟或并行化技術。
模型解釋性:
BiLoRA通過分開訓練偽奇異向量和值來減少過擬合。研究這種訓練策略如何影響模型的可解釋性和決策過程可能是一個有趣的方向。
長期影響和適應性:
研究BiLoRA在長期部署和適應新任務或數據時的表現,以及如何整合新知識以最小化性能下降。
這些潛在的研究方向可以進一步推動BiLoRA方法的發展,并擴展其在自然語言處理和其他機器學習領域的應用。
Q6: 總結一下論文的主要內容?
A:這篇論文的主要內容可以總結如下:
標題: BiLoRA: A Bi-level Optimization Framework for Overfitting-Resilient Low-Rank Adaptation of Large Pre-trained Models
問題陳述: 大型預訓練模型在下游任務中的微調經常面臨過擬合問題,導致模型在訓練數據上表現良好,但在測試數據上泛化能力不足。
方法: 為了解決這個問題,論文提出了BiLoRA,一個基于雙層優化(BLO)的微調方法。BiLoRA通過偽奇異值分解(pseudo SVD)的形式參數化低秩增量矩陣,并在兩個不同的訓練數據子集上分別訓練偽奇異向量和偽奇異值。
關鍵創新:
引入雙層優化框架,將參數學習分為兩個層次,分別優化偽奇異向量和偽奇異值。
在不同的數據子集上訓練參數,減少了對單一數據集的過擬合風險。
提出了三種偽奇異值的參數化形式:實值、Softmax和近似二值。
實驗:
在GLUE基準測試上對RoBERTa和DeBERTa模型進行了評估。
在E2E NLG挑戰賽上對GPT-2模型進行了評估。
對比了BiLoRA與LoRA、AdaLoRA和其他微調方法的性能。
分析了不同參數化形式和超參數設置對模型性能的影響。
結果: BiLoRA在多個自然語言理解和生成任務上顯著優于LoRA方法和其他微調方法,同時保持了相似數量的可訓練參數。
結論: BiLoRA是一個有效的微調方法,可以減少大型預訓練模型的過擬合問題,并提高模型在測試數據上的泛化性能。論文還提出了未來研究的潛在方向,包括改進參數化形式、理論分析和計算效率等。
這篇論文為大型預訓練模型的微調提供了一個新的視角,并通過實驗驗證了其有效性。BiLoRA方法的提出,為NLP社區提供了一個有價值的工具,以提高模型在各種下游任務中的性能。
審核編輯:黃飛
-
數據集
+關注
關注
4文章
1223瀏覽量
25283 -
LoRa
+關注
關注
351文章
1763瀏覽量
234316 -
自然語言
+關注
關注
1文章
291瀏覽量
13608 -
大模型
+關注
關注
2文章
3033瀏覽量
3837
原文標題:每日論文速遞 | BiLoRA: 基于雙極優化消除LoRA過擬合
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
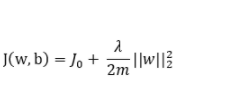
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
基于SLM的樣條擬合優化工具箱
封裝級微調與其它失調校正法的比較
曲線擬合的判定方法
基于G 的ANFIS在函數擬合中的應用
GPS高程擬合方法研究

萊特準則的橢圓擬合優化算法
PCB設計:消除過孔至過孔耦合噪聲的技巧
基于DFP優化的大規模數據點擬合方法

基于LSPIA的NURBS曲線擬合優化算法

四種微調大模型的方法介紹





 工商網監
工商網監
評論