") Groq推出大模型推理芯片 超越了傳統(tǒng)GPU和谷歌TPU
Groq推出大模型推理芯片 超越了傳統(tǒng)GPU和谷歌TPU
Groq推出了大模型推理芯片,以每秒500tokens的速度引起轟動(dòng),超越了傳統(tǒng)GPU和谷歌TPU。該芯片采用了全球首個(gè)LPU方案,解決了計(jì)算密度和內(nèi)存帶寬的瓶頸,推理速度提高了10倍,成本降低十分之一,性價(jià)比提高了100倍。芯片搭載了230MB大SRAM,內(nèi)存帶寬高達(dá)80TB/s,算力強(qiáng)大,支持多種機(jī)器學(xué)習(xí)框架進(jìn)行推理。 Groq在演示中展示了多種模型的強(qiáng)大性能,并宣稱在三年內(nèi)將超越英偉達(dá)。產(chǎn)品特色包括API訪問(wèn)速度快、支持多種開源LLM模型、價(jià)格優(yōu)勢(shì)等,成為大模型推理領(lǐng)域的新興力量。
Groq 公司的創(chuàng)始于2016年,旗艦產(chǎn)品是 Groq Tensor Streaming Processor Chip(TSP)和相應(yīng)的軟件,主要應(yīng)用于人工智能、機(jī)器學(xué)習(xí)、深度學(xué)習(xí)等領(lǐng)域。目標(biāo)市場(chǎng)包括人工智能和機(jī)器學(xué)習(xí)超大規(guī)模應(yīng)用、政府部門、高性能計(jì)算集群、自動(dòng)駕駛車輛以及高性能邊緣設(shè)備。
Groq產(chǎn)品以其出色的推理性能、對(duì)多種開源LLM模型的支持以及具有競(jìng)爭(zhēng)力的價(jià)格政策等特色,成為一個(gè)引人注目的選擇。這個(gè)芯片到底是怎么做的呢?

Part 1
Groq的做法
隨著人工智能(AI)和高性能計(jì)算(HPC)的融合發(fā)展,對(duì)于同時(shí)處理AI和HPC工作負(fù)載的需求日益增加。在這一背景下,Groq公司推出了其最新的AI推理加速器,旨在簡(jiǎn)化計(jì)算、提高效率,并實(shí)現(xiàn)更高的可擴(kuò)展性,軟件定義張量流多處理器(TSP),采用了一種全新的硬件軟件結(jié)合的方法,為人工智能、機(jī)器學(xué)習(xí)和深度學(xué)習(xí)應(yīng)用提供更高效的計(jì)算支持。
Groq AI推理加速器的設(shè)計(jì)思想是結(jié)合了HPC與AI的工作負(fù)載需求,提供了一種創(chuàng)新的可擴(kuò)展計(jì)算架構(gòu)。
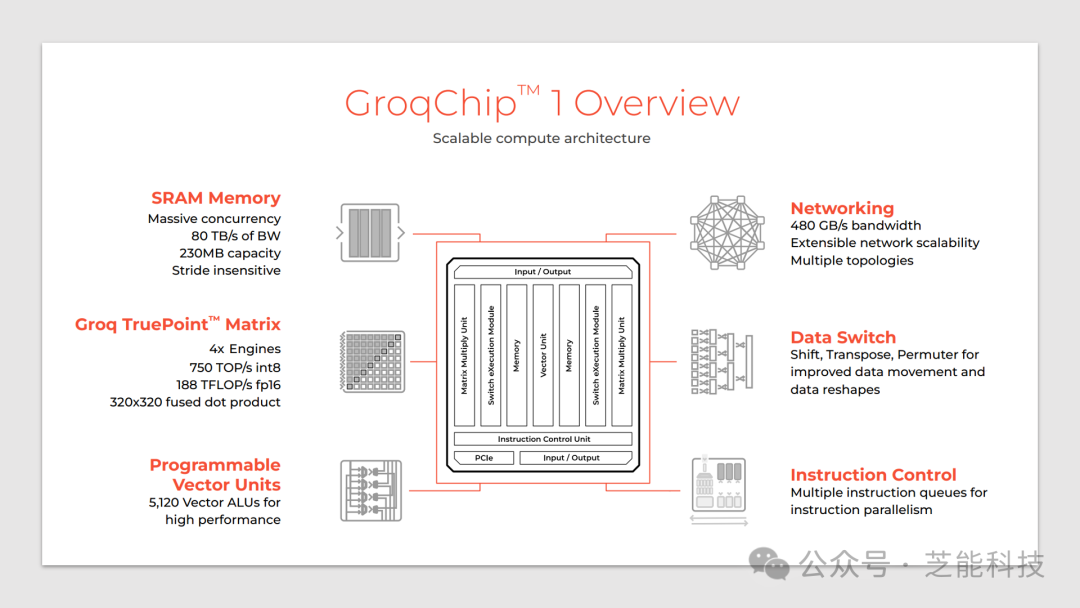
相比傳統(tǒng)的GPU,GroqChip 1具有更簡(jiǎn)化的編程模型,更高的響應(yīng)速度以及更可靠的執(zhí)行。該芯片擁有多個(gè)特色組件,包括高速網(wǎng)絡(luò)、數(shù)據(jù)交換器、指令控制、SRAM內(nèi)存以及Groq TruePoint矩陣,使其具備了強(qiáng)大的計(jì)算能力和靈活性。
傳統(tǒng)的 CPU 架構(gòu)在控制邏輯方面隱藏了大量復(fù)雜性,如緩存、預(yù)取、亂序執(zhí)行和分支預(yù)測(cè),但這些控制邏輯會(huì)減少可用于原始計(jì)算的面積。
與此相反,Groq 公司重新審視了硬件軟件的合約,創(chuàng)造出了更加可預(yù)測(cè)和基于流的硬件,并將更多的控制權(quán)交給了軟件。
硬件(CPU)定義了軟件,但隨著數(shù)據(jù)流型計(jì)算需求的增長(zhǎng)以及摩爾定律和 Dennard 縮放的減速,CPU“抽象”不再是軟件開發(fā)的唯一基礎(chǔ)。因此,Hennessy 和 Patterson 提出了“計(jì)算機(jī)體系結(jié)構(gòu)的新黃金時(shí)代”的觀點(diǎn),Lattner 提出了“編譯器的新黃金時(shí)代”的觀點(diǎn),Karpathy 則提出了“軟件 2.0”的概念,這都預(yù)示著硬件與軟件的抽象合約已經(jīng)重新開啟,實(shí)現(xiàn)了“軟件定義硬件”的機(jī)會(huì)。
GroqChip 的可擴(kuò)展架構(gòu)以簡(jiǎn)化計(jì)算,通過(guò)使用大量單級(jí)劃分 SRAM 和顯式分配張量,實(shí)現(xiàn)了可預(yù)測(cè)的性能。
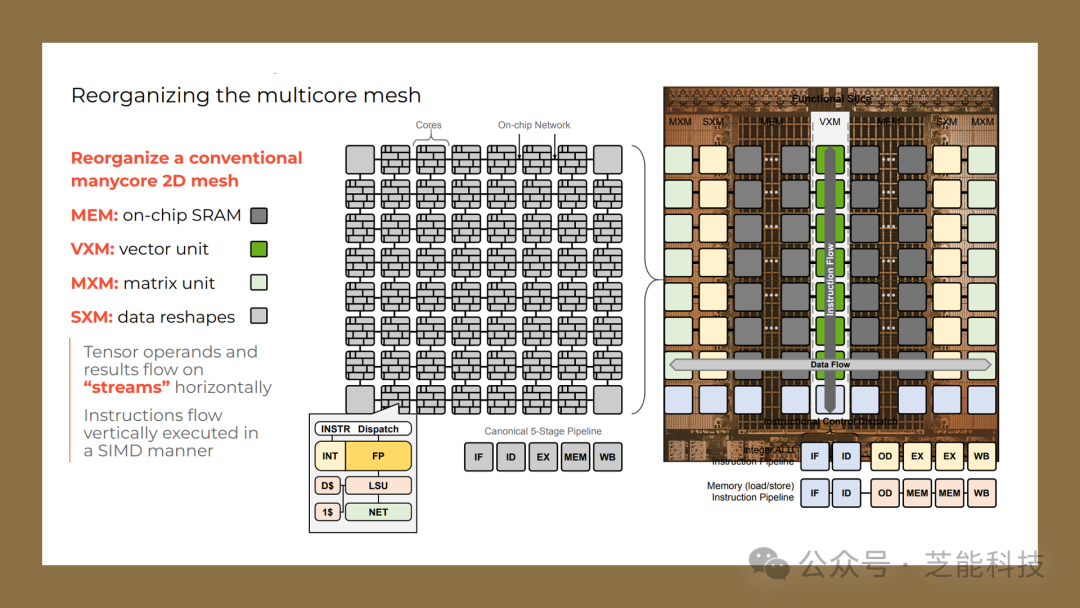
此外,Groq 公司設(shè)計(jì)了功能劃分的微體系結(jié)構(gòu),重新組織了多核網(wǎng)格,使得編譯器可以對(duì)程序執(zhí)行進(jìn)行精確控制,從而提高了執(zhí)行效率。
Groq AI推理加速器支持各種規(guī)模的計(jì)算節(jié)點(diǎn),從單個(gè)卡片到整個(gè)機(jī)架,都能實(shí)現(xiàn)高效的并行計(jì)算。

通過(guò)GroqRack和GroqNode等組件的組合,用戶可以根據(jù)實(shí)際需求靈活搭建計(jì)算集群,實(shí)現(xiàn)對(duì)不同規(guī)模工作負(fù)載的處理。
Groq 公司提供了強(qiáng)大的編譯器支持,通過(guò)在編譯時(shí)和運(yùn)行時(shí)之間建立靜態(tài)-動(dòng)態(tài)接口和硬件-軟件接口,賦予了軟件更多的數(shù)據(jù)編排權(quán)力。該編譯器能夠?qū)崿F(xiàn) SOTA(State of the Art)級(jí)別的性能,對(duì)于一些重要的矩陣操作如通用矩陣乘法(GEMM),Cholesky 分解等,取得了令人矚目的成果。
在系統(tǒng)拓?fù)浣Y(jié)構(gòu)方面,Groq 公司采用了低直徑網(wǎng)絡(luò) Dragonfly,以最小化網(wǎng)絡(luò)中的跳數(shù),提高了數(shù)據(jù)傳輸效率。
同時(shí),通過(guò) Chip-to-Chip(C2C)鏈接和流量控制,實(shí)現(xiàn)了多芯片間的通信。此外,Groq 公司還提出了一種多芯片間的分區(qū)和流水線并行執(zhí)行的方法,以進(jìn)一步提高多芯片系統(tǒng)的性能。

Part 2
實(shí)際案例
除了傳統(tǒng)的計(jì)算流體動(dòng)力學(xué)(CFD)應(yīng)用外,Groq AI推理加速器還可應(yīng)用于圖神經(jīng)網(wǎng)絡(luò)(GNN)等領(lǐng)域。GNN廣泛應(yīng)用于非歐幾里得數(shù)據(jù)的建模和預(yù)測(cè),例如化學(xué)分子結(jié)構(gòu)、社交媒體推薦系統(tǒng)等。Groq芯片在處理這類非結(jié)構(gòu)化數(shù)據(jù)時(shí)表現(xiàn)出色,通過(guò)深度學(xué)習(xí)算法的加速,能夠大幅提升模型訓(xùn)練和推理的效率。軟件定義張量流多處理器提供了一種全新的硬件軟件結(jié)合的方法,通過(guò)重新審視硬件軟件合約,將更多的控制權(quán)交給了軟件,從而實(shí)現(xiàn)了更高效的計(jì)算性能。隨著人工智能和深度學(xué)習(xí)應(yīng)用的不斷發(fā)展,這種方法將有望在未來(lái)的計(jì)算領(lǐng)域發(fā)揮重要作用。
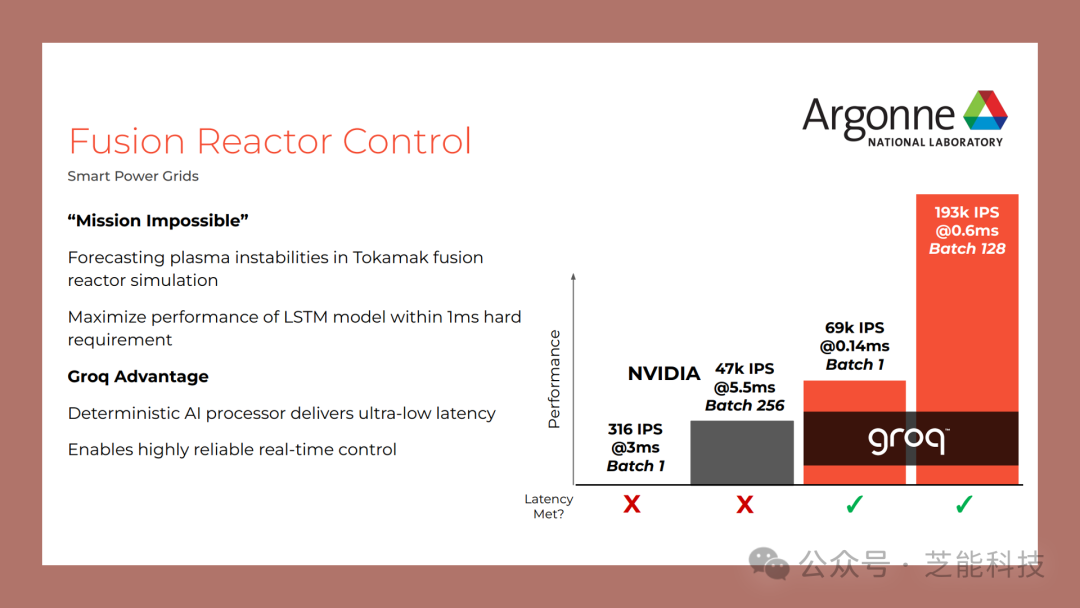
在實(shí)際應(yīng)用中,Groq AI推理加速器已經(jīng)在化學(xué)分子屬性預(yù)測(cè)、藥物發(fā)現(xiàn)等領(lǐng)域取得了顯著的成果。

借助其高性能和可擴(kuò)展性,Groq芯片在處理大規(guī)模數(shù)據(jù)集時(shí)能夠?qū)崿F(xiàn)極大的加速,從而提升了科學(xué)研究和工程實(shí)踐的效率。
小結(jié)
總的來(lái)說(shuō),Groq AI推理加速器以其創(chuàng)新的設(shè)計(jì)思想和強(qiáng)大的性能,在處理融合HPC與AI工作負(fù)載的應(yīng)用中展現(xiàn)出了巨大的潛力。隨著對(duì)于高性能計(jì)算和人工智能技術(shù)的不斷發(fā)展,相信Groq芯片將在各個(gè)領(lǐng)域展現(xiàn)出更廣泛的應(yīng)用前景。
?
審核編輯:劉清
-
人工智能
+關(guān)注
關(guān)注
1804文章
48677瀏覽量
246337 -
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8490瀏覽量
134062 -
TSP
+關(guān)注
關(guān)注
1文章
25瀏覽量
17109 -
大模型
+關(guān)注
關(guān)注
2文章
3020瀏覽量
3808 -
Groq
+關(guān)注
關(guān)注
0文章
9瀏覽量
123
原文標(biāo)題:Groq AI推理加速器: 三年內(nèi)超越英偉達(dá)?
文章出處:【微信號(hào):QCDZSJ,微信公眾號(hào):汽車電子設(shè)計(jì)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Google推出第七代TPU芯片Ironwood
谷歌第七代TPU Ironwood深度解讀:AI推理時(shí)代的硬件革命

谷歌新一代 TPU 芯片 Ironwood:助力大規(guī)模思考與推理的 AI 模型新引擎?
無(wú)法在GPU上運(yùn)行ONNX模型的Benchmark_app怎么解決?
無(wú)法調(diào)用GPU插件推理的遠(yuǎn)程張量API怎么解決?
AI變革正在推動(dòng)終端側(cè)推理創(chuàng)新
OpenAI即將推出o3 mini推理AI模型
阿里云開源推理大模型QwQ
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
高效大模型的推理綜述

FPGA和ASIC在大模型推理加速中的應(yīng)用

澎峰科技高性能大模型推理引擎PerfXLM解析

沙特阿美攜手Groq打造全球最大推理數(shù)據(jù)中心
從TPU v1到Trillium TPU,蘋果等科技公司使用谷歌TPU進(jìn)行AI計(jì)算
采用創(chuàng)新的FPGA 器件來(lái)實(shí)現(xiàn)更經(jīng)濟(jì)且更高能效的大模型推理解決方案





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論