") 從TPU v1到Trillium TPU,蘋果等科技公司使用谷歌TPU進(jìn)行AI計(jì)算
從TPU v1到Trillium TPU,蘋果等科技公司使用谷歌TPU進(jìn)行AI計(jì)算
電子發(fā)燒友網(wǎng)報(bào)道(文/李彎彎)7月30日消息,蘋果公司周一在一篇技術(shù)論文中表示,支撐其人工智能系統(tǒng)Apple Intelligence的兩個(gè)人工智能模型是在谷歌設(shè)計(jì)的云端芯片上進(jìn)行預(yù)訓(xùn)練的。這表明,在訓(xùn)練尖端人工智能方面,大型科技公司正在尋找英偉達(dá)以外的替代品。
不斷迭代的谷歌TPU芯片
隨著機(jī)器學(xué)習(xí)算法,特別是深度學(xué)習(xí)算法在各個(gè)領(lǐng)域的廣泛應(yīng)用,對(duì)于高效、低功耗的AI計(jì)算硬件需求日益增長(zhǎng)。傳統(tǒng)的CPU和GPU在處理這些算法時(shí)存在效率較低的問題,促使谷歌等科技巨頭開始探索專用AI加速芯片的研發(fā)。
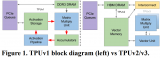
谷歌在2015年左右開始規(guī)劃開發(fā)新的專用架構(gòu)處理器,旨在優(yōu)化機(jī)器學(xué)習(xí)算法中的張量運(yùn)算執(zhí)行過(guò)程。經(jīng)過(guò)快速迭代和研發(fā),谷歌于2016年發(fā)布了首個(gè)TPU版本(TPU v1),專門用于大規(guī)模機(jī)器學(xué)習(xí)加速。
TPU v1部署于數(shù)據(jù)中心,用于加速神經(jīng)網(wǎng)絡(luò)的推理階段。擁有65536個(gè)8-bit MAC(矩陣乘單元),峰值性能為92 TOPS(每秒萬(wàn)億次操作),以及28 MiB的片上內(nèi)存空間。相比于CPU和GPU,TPU v1在響應(yīng)時(shí)間和能效比上表現(xiàn)出色,能夠顯著提升神經(jīng)網(wǎng)絡(luò)的推理速度。
隨著技術(shù)的不斷進(jìn)步,谷歌相繼推出了多個(gè)TPU版本,不斷提升性能和功能。例如,TPU v2和TPU v3被設(shè)計(jì)為服務(wù)端AI推理和訓(xùn)練芯片,支持更復(fù)雜的AI任務(wù)。TPU v4則進(jìn)一步增強(qiáng)了擴(kuò)展性和靈活性,支持大規(guī)模AI計(jì)算集群的構(gòu)建。
在面對(duì)爭(zhēng)議和質(zhì)疑后,谷歌推出了TPU v5e版本。TPU v5e在架構(gòu)上進(jìn)行了調(diào)整,采用單TensorCore架構(gòu),并在INT8峰值算力上有所提升。盡管在BF16峰值算力上略低于前代版本,但TPU v5e更適用于推理任務(wù),并體現(xiàn)了谷歌在AI算力服務(wù)市場(chǎng)的戰(zhàn)略選擇。
在今年5月的I/O開發(fā)者大會(huì)上,谷歌又發(fā)布了第六代張量處理單元 (TPU) ,稱為Trillium。Trillium TPU 可以更快地訓(xùn)練下一波基礎(chǔ)模型,并以更少的延遲和更低的成本為這些模型提供服務(wù)。至關(guān)重要的是,Trillium TPU 的能效比 TPU v5e 高出 67% 以上。
值得一提的是,Trillium 可以在單個(gè)高帶寬、低延遲 Pod 中擴(kuò)展到多達(dá) 256 個(gè) TPU。除了這種 Pod 級(jí)可擴(kuò)展性之外,借助多切片技術(shù)和Titanium 智能處理單元 (IPU ),Trillium TPU 還可以擴(kuò)展到數(shù)百個(gè) Pod,從而連接建筑物級(jí)超級(jí)計(jì)算機(jī)中的數(shù)萬(wàn)個(gè)芯片,這些芯片通過(guò)每秒數(shù) PB 的速度互連數(shù)據(jù)中心網(wǎng)絡(luò)。
谷歌表示,Trillium TPU 將為下一波 AI 模型和代理提供動(dòng)力,包括自動(dòng)駕駛汽車公司Nuro、藥物發(fā)現(xiàn)公司Deep Genomics、德勤等企業(yè)也采用其TPU產(chǎn)品進(jìn)行應(yīng)用。
越來(lái)越多企業(yè)使用谷歌TPU芯片滿足AI計(jì)算
據(jù)谷歌官方信息,其最新TPU的運(yùn)行成本每小時(shí)不足2美元,但客戶需提前三年預(yù)訂以確保使用。自2015年專為內(nèi)部工作負(fù)載設(shè)計(jì)的TPU問世以來(lái),谷歌于2017年將其向公眾開放,如今,TPU已成為人工智能領(lǐng)域最為成熟和先進(jìn)的定制芯片之一。
谷歌在其多個(gè)設(shè)施中使用了自研的TPU(Tensor Processing Unit)芯片。谷歌云平臺(tái)廣泛使用了TPU芯片來(lái)支持其AI基礎(chǔ)設(shè)施。這些芯片被用于加速機(jī)器學(xué)習(xí)模型的訓(xùn)練和推理過(guò)程,提供高性能和高效的計(jì)算能力。通過(guò)谷歌云平臺(tái),用戶可以訪問到基于TPU芯片的虛擬機(jī)實(shí)例(VM),用于訓(xùn)練和部署自己的機(jī)器學(xué)習(xí)模型。
除此之外,已經(jīng)有多家公司使用谷歌的TPU芯片,如蘋果,蘋果在最新發(fā)表的技術(shù)論文中承認(rèn),公司采用了谷歌張量處理單元(TPU)訓(xùn)練其人工智能模型。
在周一發(fā)布的技術(shù)論文中,蘋果詳細(xì)介紹為支持蘋果個(gè)人智能化系統(tǒng)Apple Intelligence而開發(fā)了一些基礎(chǔ)語(yǔ)言模型,包括一個(gè)用于在設(shè)備上高效運(yùn)行的約30億參數(shù)模型——端側(cè)“蘋果基礎(chǔ)模型”(AFM),以及一個(gè)為蘋果云端AI架構(gòu)“私有云計(jì)算”(Private Cloud Compute)而設(shè)計(jì)的大型服務(wù)器語(yǔ)言模型——服務(wù)器AFM。
蘋果披露,訓(xùn)練模型采用了谷歌研發(fā)的第四代AI ASIC芯片TPUv4和更新一代的芯片TPUv5。蘋果在8192塊TPUv4 芯片上從無(wú)到有訓(xùn)練服務(wù)器AFM,使用4096的序列長(zhǎng)度和4096個(gè)序列的批量大小,進(jìn)行6.3萬(wàn)億token訓(xùn)練。端側(cè)AFM在2048塊TPUv5p芯片上進(jìn)行訓(xùn)練。
此外,Anthropic這家被譽(yù)為“OpenAI勁敵”的人工智能初創(chuàng)公司,據(jù)悉是谷歌TPU芯片的早期用戶之一。Anthropic使用谷歌Cloud TPU v5e芯片為其大語(yǔ)言模型(LLM)Claude提供硬件支持,以加速模型的訓(xùn)練和推理過(guò)程。Hugging Face和AssemblyAI這兩家同樣在人工智能領(lǐng)域備受矚目的初創(chuàng)公司也在大規(guī)模使用谷歌TPU芯片來(lái)支持其AI應(yīng)用。
另外,許多科研機(jī)構(gòu)也在使用谷歌TPU芯片來(lái)支持其AI相關(guān)的研究項(xiàng)目。這些機(jī)構(gòu)可以利用TPU芯片的高性能計(jì)算能力來(lái)加速實(shí)驗(yàn)過(guò)程,推動(dòng)科研進(jìn)展。一些教育機(jī)構(gòu)也將谷歌TPU芯片用于教學(xué)和培訓(xùn)目的,幫助學(xué)生和研究人員學(xué)習(xí)和掌握機(jī)器學(xué)習(xí)技術(shù)。
寫在最后
長(zhǎng)期以來(lái),英偉達(dá)的高性能GPU在高端人工智能模型訓(xùn)練市場(chǎng)占據(jù)主導(dǎo)地位,包括OpenAI、微軟、Anthropic在內(nèi)的多家科技公司紛紛采用其GPU來(lái)加速模型訓(xùn)練。但在過(guò)去幾年里,英偉達(dá)GPU始終供不應(yīng)求,為此谷歌、Meta、甲骨文及特斯拉等企業(yè)都在自研芯片,以滿足各自人工智能系統(tǒng)與產(chǎn)品開發(fā)的需求。
不僅如此,如谷歌,雖然TPU最初是為內(nèi)部工作負(fù)載而創(chuàng)建,而其憑借著諸多優(yōu)勢(shì),現(xiàn)在正得到更廣泛的應(yīng)用。隨著人工智能技術(shù)的不斷發(fā)展和市場(chǎng)的不斷擴(kuò)大,未來(lái)可能會(huì)有更多的企業(yè)選擇使用谷歌TPU芯片來(lái)滿足其AI計(jì)算需求。
-
谷歌
+關(guān)注
關(guān)注
27文章
6222瀏覽量
107432 -
蘋果
+關(guān)注
關(guān)注
61文章
24526瀏覽量
202960 -
TPU
+關(guān)注
關(guān)注
0文章
151瀏覽量
21067
發(fā)布評(píng)論請(qǐng)先 登錄
OpenAI與博通洽談合作!定制化ASIC芯片走向臺(tái)前,英偉達(dá)GPU迎來(lái)“勁敵”?

TPU處理器的特性和工作原理
Google推出第七代TPU芯片Ironwood
谷歌第七代TPU Ironwood深度解讀:AI推理時(shí)代的硬件革命

谷歌新一代 TPU 芯片 Ironwood:助力大規(guī)模思考與推理的 AI 模型新引擎?
TPU編程競(jìng)賽|第二十屆研電賽算能杯賽啟動(dòng) -- 智算賦能,創(chuàng)見未來(lái)!

為什么無(wú)法使用OpenVINO?模型優(yōu)化器轉(zhuǎn)換TensorFlow 2.4模型?
TPU編程競(jìng)賽系列|第九屆集創(chuàng)賽“算能杯”火熱報(bào)名中!
光纜用tpu外護(hù)套用在哪些型號(hào)光纜上
TPU編程競(jìng)賽|2024 CCF BDCI大賽圓滿結(jié)束!算能賽道“常務(wù)副SOTA”團(tuán)隊(duì)榮獲最佳算法能力獎(jiǎng)
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
蘋果轉(zhuǎn)向谷歌芯片訓(xùn)練AI,或成棄用英偉達(dá)GPU首例
【算能RADXA微服務(wù)器試用體驗(yàn)】+ GPT語(yǔ)音與視覺交互:4,文字轉(zhuǎn)語(yǔ)音
【算能RADXA微服務(wù)器試用體驗(yàn)】+ GPT語(yǔ)音與視覺交互:2,圖像識(shí)別
TPU編程競(jìng)賽系列|2024中國(guó)國(guó)際大學(xué)生創(chuàng)新大賽產(chǎn)業(yè)命題賽道,算能11項(xiàng)命題入選!





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論