") SegRefiner:通過(guò)擴(kuò)散模型實(shí)現(xiàn)高精度圖像分割
SegRefiner:通過(guò)擴(kuò)散模型實(shí)現(xiàn)高精度圖像分割
背景介紹
盡管圖像分割在過(guò)去得到了廣泛研究和快速發(fā)展,但獲得細(xì)節(jié)上非常準(zhǔn)確的分割 mask 始終十分具有挑戰(zhàn)性。因?yàn)檫_(dá)成高精度的分割既需要高級(jí)語(yǔ)義信息,也需要細(xì)粒度的紋理信息,這將導(dǎo)致較大的計(jì)算復(fù)雜性和內(nèi)存使用。而對(duì)于分辨率達(dá)到2K甚至更高的圖像,這一挑戰(zhàn)尤為突出。
由于直接預(yù)測(cè)高質(zhì)量分割 mask 具有挑戰(zhàn)性,因此一些研究開(kāi)始集中于 refine 已有分割模型輸出的粗糙 mask。為了實(shí)現(xiàn)高精度的圖像分割,來(lái)自北京交大、南洋理工、字節(jié)跳動(dòng)等的研究者們引入了一種基于擴(kuò)散模型Diffusion去逐步提高mask質(zhì)量的方法。
現(xiàn)有方法
Model-Specific
一類(lèi)常見(jiàn)的 Refinement 方法是 Model-Specific 的,其通過(guò)在已有分割模型中引入一些新模塊,從而為預(yù)測(cè) Mask 補(bǔ)充了更多額外信息,從而增強(qiáng)了已有模型對(duì)于細(xì)節(jié)的感知能力。這一類(lèi)方法中代表性的工作有 PointRend,RefineMask,MaskTransfiner等。然而,這些方法是基于特定模型的改進(jìn),因此不能直接用于 refine 其他分割模型輸出的粗糙 mask。
Model-Agnostic
另一類(lèi) Refinement 方法是 Model-Agnostic 的,其只使用原始圖像和粗糙mask作為輸入信息,如 BPR,SegFix,CascadePSP,CRM 等。由于這類(lèi)方法在 Refinement 過(guò)程中未使用已有模型的中間特征,因此不依賴于特定分割模型,可以用于不同分割模型的 Refinement。然而,盡管這類(lèi)方法能夠有效地提升分割準(zhǔn)確度,但由于粗糙 mask 中存在多種多樣的錯(cuò)誤預(yù)測(cè)(如下圖所示),導(dǎo)致模型無(wú)法穩(wěn)定地修正粗糙 mask 中的全部預(yù)測(cè)錯(cuò)誤。

實(shí)現(xiàn)目標(biāo)
相比于 Model-Specific 的方法,Model-Agnostic 的方法能夠直接應(yīng)用于不同分割模型的 Refinement,從而有著更高的實(shí)用價(jià)值。更進(jìn)一步地,由于不同分割任務(wù)(語(yǔ)義分割,實(shí)例分割等)的結(jié)果都可以被表示為一系列 binary mask,具有相同的表征形式,在同一個(gè)模型中統(tǒng)一實(shí)現(xiàn)不同分割任務(wù)的 Refinement 同樣是可能的。因此,我們希望實(shí)現(xiàn)能夠應(yīng)用于不同分割模型和分割任務(wù)的通用 Refinement 模型。
如前所述,已有分割模型產(chǎn)生的錯(cuò)誤預(yù)測(cè)是多種多樣的,而想要通過(guò)一個(gè)通用模型一次性地更正這些多樣性的錯(cuò)誤十分困難。面對(duì)這一問(wèn)題,在圖像生成任務(wù)中取得巨大成功的擴(kuò)散概率模型給予了我們啟發(fā):擴(kuò)散概率模型的迭代策略使得模型可以在每一個(gè)時(shí)間步中僅僅消除一部分噪聲,并通過(guò)多步迭代來(lái)不斷接近真實(shí)圖像的分布。這大大降低了一次性擬合出目標(biāo)數(shù)據(jù)分布的難度,從而賦予了擴(kuò)散模型生成高質(zhì)量圖像的能力。
直觀地,如果將擴(kuò)散概率模型的策略遷移到 Refinement 任務(wù)中,可以使得模型在進(jìn)行 Refinement 時(shí)每一步僅關(guān)注一些“最明顯的錯(cuò)誤”,這將降低一次性修正所有錯(cuò)誤預(yù)測(cè)的難度,并可以通過(guò)不斷迭代來(lái)逐漸接近精細(xì)分割結(jié)果,從而使得模型能夠應(yīng)對(duì)更具挑戰(zhàn)性的實(shí)例并持續(xù)糾正錯(cuò)誤,產(chǎn)生精確分割結(jié)果。
在這一想法下,我們提出了一個(gè)新的視角:將粗糙 mask 視作 ground truth 的帶噪版本,并通過(guò)一個(gè)去噪擴(kuò)散過(guò)程來(lái)實(shí)現(xiàn)粗糙 mask 的 Refinement,從而將 Refinement 任務(wù)表示為一個(gè)以圖像為條件,目標(biāo)為精細(xì) mask 的數(shù)據(jù)生成過(guò)程。
算法方案
擴(kuò)散概率模型是一種由前向和反向過(guò)程表示的生成模型,其中前向過(guò)程通過(guò)不斷加入高斯噪聲得到不同程度的帶噪圖像,并訓(xùn)練模型預(yù)測(cè)噪聲;而反向過(guò)程則從純高斯噪聲開(kāi)始逐步迭代去噪,最終采樣出圖像。而將擴(kuò)散概率模型遷移到 Refinement 任務(wù)中,數(shù)據(jù)形式的不同帶來(lái)了以下兩個(gè)問(wèn)題:
(1) 由于自然圖像往往被視作高維高斯變量,將圖像生成的過(guò)程建模為一系列高斯過(guò)程是十分自然的,因此已有的擴(kuò)散概率模型大多基于高斯假設(shè)建立;而我們的目標(biāo)數(shù)據(jù)是 binary mask,通過(guò)高斯過(guò)程擬合這樣一個(gè)離散變量的分布并不合理。
(2) 作為一種分割 Refinement 方法,我們的核心思想是將粗糙 mask 視為帶有噪聲的 ground truth,并通過(guò)消除這種噪聲來(lái)恢復(fù)高質(zhì)量的分割結(jié)果。這意味著我們擴(kuò)散過(guò)程的結(jié)尾應(yīng)當(dāng)收斂到確定性的粗糙 mask(而非純?cè)肼暎@也與已有的擴(kuò)散概率模型不同。
針對(duì)上述問(wèn)題,我們建立了如下圖所示的基于“隨機(jī)狀態(tài)轉(zhuǎn)移”的離散擴(kuò)散過(guò)程。其中,前向過(guò)程將 ground truth 轉(zhuǎn)換為“不同粗糙程度”的 mask,并用于訓(xùn)練;而反向過(guò)程用于模型推理,SegRefiner 從給出的粗糙 mask 開(kāi)始,通過(guò)逐步迭代修正粗糙 mask 中的錯(cuò)誤預(yù)測(cè)區(qū)域。以下將詳細(xì)介紹前向和反向過(guò)程。
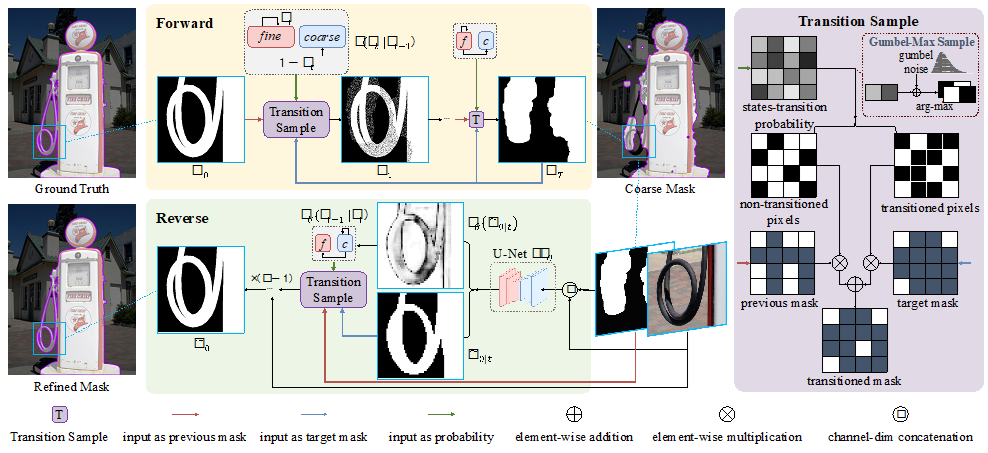
前向過(guò)程
前向過(guò)程的目標(biāo)是將 ground truth 提供的精細(xì) mask 逐步消融為粗糙的 mask,記前向過(guò)程每一步的變量為  ,則前向過(guò)程應(yīng)當(dāng)滿足:
,則前向過(guò)程應(yīng)當(dāng)滿足:
(1)  為 ground truth
為 ground truth
(2)  為粗糙 mask
為粗糙 mask
(3)  介于和之間,隨 t 增大逐漸向粗糙 mask 演變 ? ?
介于和之間,隨 t 增大逐漸向粗糙 mask 演變 ? ?
基于這些限制條件,我們用隨機(jī)狀態(tài)轉(zhuǎn)移來(lái)表述前向過(guò)程:假設(shè)變量中的每一個(gè)像素都有兩種可能的狀態(tài):精細(xì)和粗糙,處于精細(xì)狀態(tài)的像素值與保持一致,處于粗糙狀態(tài)的像素則取 的值(即使二者一致)。我們提出了一個(gè)“轉(zhuǎn)移采樣”模塊來(lái)進(jìn)行這一過(guò)程,如上圖右側(cè)所示。在每一個(gè)時(shí)間步,其以當(dāng)前 mask ,粗糙 mask 以及狀態(tài)轉(zhuǎn)移概率作為輸入。
在前向過(guò)程中,狀態(tài)轉(zhuǎn)移概率描述了當(dāng)前 mask 中每個(gè)像素轉(zhuǎn)移到中的狀態(tài)的概率。根據(jù)狀態(tài)轉(zhuǎn)移概率進(jìn)行采樣,可以得到后一個(gè)時(shí)間步 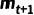 每個(gè)像素的狀態(tài),從而確定其取值。這一模塊確定了一個(gè)“單向”過(guò)程,即只會(huì)發(fā)生“轉(zhuǎn)移到目標(biāo)狀態(tài)”的情況。這一單向性質(zhì)確保了前向過(guò)程會(huì)收斂到(盡管每一步都是完全隨機(jī)的),從而滿足了上述限制 條件(2),(3)。
每個(gè)像素的狀態(tài),從而確定其取值。這一模塊確定了一個(gè)“單向”過(guò)程,即只會(huì)發(fā)生“轉(zhuǎn)移到目標(biāo)狀態(tài)”的情況。這一單向性質(zhì)確保了前向過(guò)程會(huì)收斂到(盡管每一步都是完全隨機(jī)的),從而滿足了上述限制 條件(2),(3)。
通過(guò)重參數(shù)技巧,我們引入了一個(gè)二元隨機(jī)變量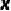 來(lái)描述上述過(guò)程:我們將
來(lái)描述上述過(guò)程:我們將 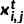 表示為一個(gè) one-hot 向量,用來(lái)表示中間掩模 中像素
表示為一個(gè) one-hot 向量,用來(lái)表示中間掩模 中像素 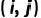 的狀態(tài),同時(shí)設(shè)置
的狀態(tài),同時(shí)設(shè)置 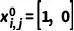 和
和 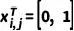 來(lái)表示精細(xì)狀態(tài)和粗糙狀態(tài)。因此,前向過(guò)程可以被表示為:
來(lái)表示精細(xì)狀態(tài)和粗糙狀態(tài)。因此,前向過(guò)程可以被表示為:
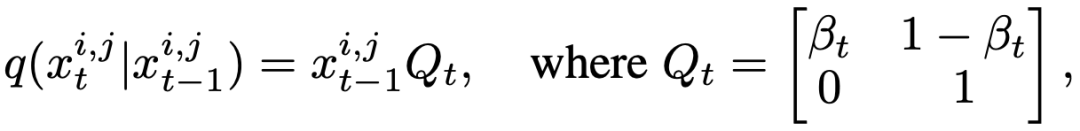
其中 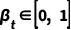 為超參數(shù),而
為超參數(shù),而 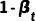 對(duì)應(yīng)了上述的狀態(tài)轉(zhuǎn)移概率,
對(duì)應(yīng)了上述的狀態(tài)轉(zhuǎn)移概率,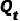 是狀態(tài)轉(zhuǎn)移矩陣。則前向過(guò)程的邊緣分布可以表示為:
是狀態(tài)轉(zhuǎn)移矩陣。則前向過(guò)程的邊緣分布可以表示為:
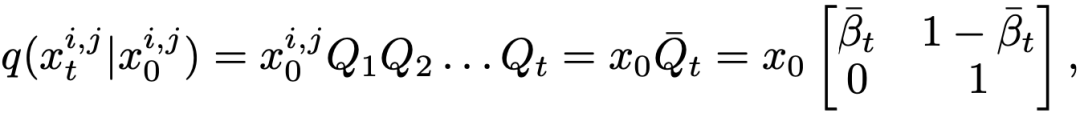
其中  。從而我們可以直接獲取任何中間時(shí)間步
。從而我們可以直接獲取任何中間時(shí)間步 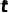 的 mask 并用于訓(xùn)練,而無(wú)需逐步采樣
的 mask 并用于訓(xùn)練,而無(wú)需逐步采樣 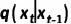 。
。
反向過(guò)程
反向擴(kuò)散過(guò)程用于模型推理,目標(biāo)是將粗糙 mask 逐漸修正為精細(xì) mask 。由于此時(shí)精細(xì) mask 和狀態(tài)轉(zhuǎn)移概率未知,類(lèi)似 DDPM 的做法,我們訓(xùn)練一個(gè)神經(jīng)網(wǎng)絡(luò) 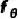 ,來(lái)預(yù)測(cè)精細(xì) mask
,來(lái)預(yù)測(cè)精細(xì) mask 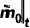 ,表示為:
,表示為:
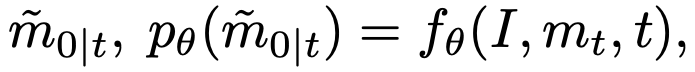
其中  是相應(yīng)的圖像。
是相應(yīng)的圖像。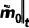 和
和 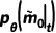 分別表示預(yù)測(cè)的精細(xì) mask 和其置信度分?jǐn)?shù)。這里表示了網(wǎng)絡(luò)對(duì)于預(yù)測(cè)準(zhǔn)確與否的置信度,故同樣可以被視作中每個(gè)像素處于“精細(xì)狀態(tài)”的概率。為了獲得反向狀態(tài)轉(zhuǎn)移概率,根據(jù)前向過(guò)程的設(shè)定和貝葉斯定理,延續(xù) DDPM 的做法,我們可以由前向過(guò)程的后驗(yàn)概率和預(yù)測(cè)的得到反向過(guò)程的概率分布,為:? ?
分別表示預(yù)測(cè)的精細(xì) mask 和其置信度分?jǐn)?shù)。這里表示了網(wǎng)絡(luò)對(duì)于預(yù)測(cè)準(zhǔn)確與否的置信度,故同樣可以被視作中每個(gè)像素處于“精細(xì)狀態(tài)”的概率。為了獲得反向狀態(tài)轉(zhuǎn)移概率,根據(jù)前向過(guò)程的設(shè)定和貝葉斯定理,延續(xù) DDPM 的做法,我們可以由前向過(guò)程的后驗(yàn)概率和預(yù)測(cè)的得到反向過(guò)程的概率分布,為:? ?
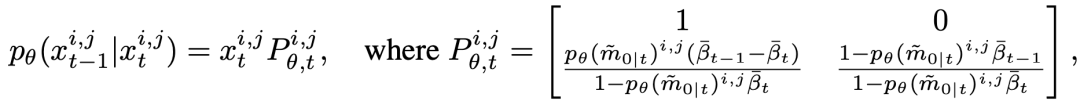
其中 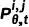 為反向過(guò)程的狀態(tài)轉(zhuǎn)移概率。給定粗糙 mask 以及相應(yīng)的圖像,我們首先將所有像素初始化為粗糙狀態(tài)
為反向過(guò)程的狀態(tài)轉(zhuǎn)移概率。給定粗糙 mask 以及相應(yīng)的圖像,我們首先將所有像素初始化為粗糙狀態(tài) 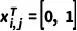 ,然后通過(guò)不斷迭代地狀態(tài)轉(zhuǎn)移,逐漸修正 中預(yù)測(cè)值。下圖為一個(gè)推理過(guò)程的可視化展示。
,然后通過(guò)不斷迭代地狀態(tài)轉(zhuǎn)移,逐漸修正 中預(yù)測(cè)值。下圖為一個(gè)推理過(guò)程的可視化展示。

模型結(jié)構(gòu)
任意滿足  形式的網(wǎng)絡(luò)均可滿足我們的要求,這里我們延續(xù)了之前工作的做法,采用 U-Net 作為我們的去噪網(wǎng)絡(luò),將其輸入通道數(shù)修改為4(圖像和 在通道維度上串聯(lián)),并輸出1通道的改進(jìn)掩模。
形式的網(wǎng)絡(luò)均可滿足我們的要求,這里我們延續(xù)了之前工作的做法,采用 U-Net 作為我們的去噪網(wǎng)絡(luò),將其輸入通道數(shù)修改為4(圖像和 在通道維度上串聯(lián)),并輸出1通道的改進(jìn)掩模。
算法評(píng)估
由于 Refinement 任務(wù)的核心是獲取細(xì)節(jié)精確的分割結(jié)果,在實(shí)驗(yàn)中我們選取了三個(gè)代表性的高質(zhì)量分割數(shù)據(jù)集,分別對(duì)應(yīng)Semantic Segmentation,Instance Segmentation 和 Dichotomous Image Segmentation。
Semantic Segmentation
如表1所示,我們?cè)?BIG 數(shù)據(jù)集上將提出的 SegRefiner 與四種已有方法:SegFix,CascadePSP,CRM 以及 MGMatting 進(jìn)行了對(duì)比。其中前三個(gè)為語(yǔ)義分割的 Refinement 方法,而 MGMatting 使用圖像和 mask 進(jìn)行 Matting 任務(wù),也可以用于 Refinement 任務(wù)。結(jié)果表明,我們提出的 SegRefiner 在 refine 四個(gè)不同語(yǔ)義分割模型的粗糙 mask 時(shí),都在 IoU 和 mBA 兩項(xiàng)指標(biāo)上獲得了明顯提升,且超越了之前的方法。
 ? ?
? ?
Instance Segmentation
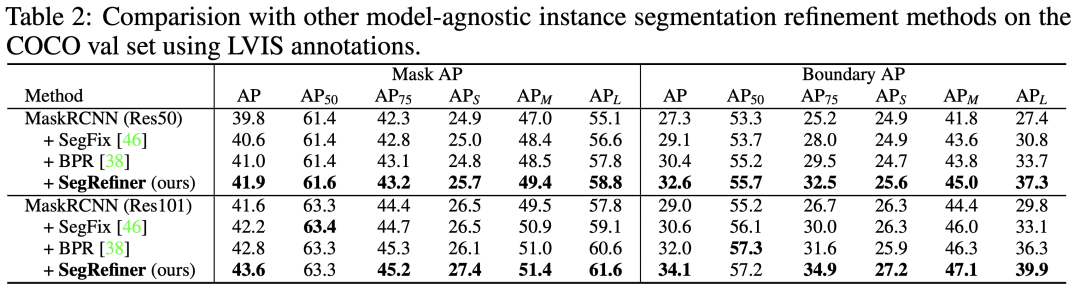
實(shí)例分割中,我們選擇了之前的工作廣泛使用的 COCO 數(shù)據(jù)集進(jìn)行測(cè)試,并使用了 LVIS 數(shù)據(jù)集的標(biāo)注。與原始 COCO 標(biāo)注相比,LVIS 標(biāo)注提供了更高質(zhì)量和更詳細(xì)的結(jié)構(gòu),這使得 LVIS 標(biāo)注更適合評(píng)估改進(jìn)模型的性能。
首先,在表2中,我們將提出的SegRefiner與兩種 Model-Agnostic 的實(shí)例分割 Refinement 方法 BPR 和 SegFix 進(jìn)行了比較。結(jié)果表明我們的 SegRefiner 在性能上明顯優(yōu)于這兩種方法。
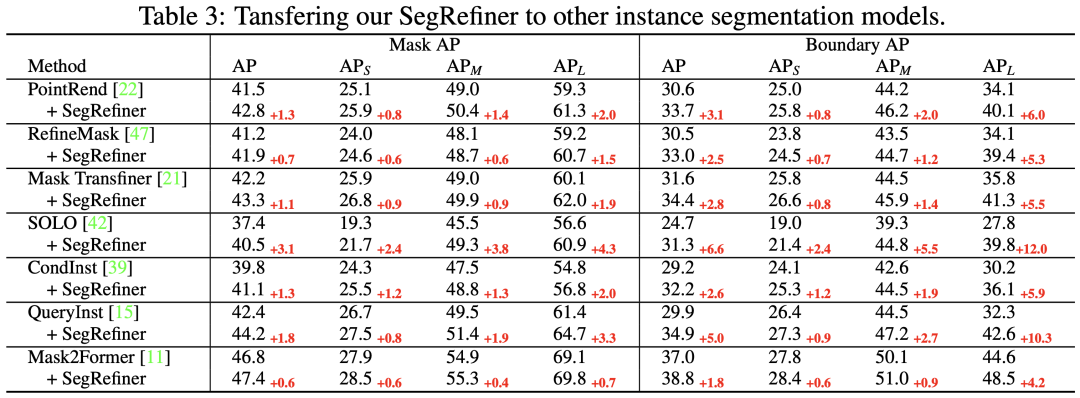
然后在表3中,我們將 SegRefiner 應(yīng)用于其他7種實(shí)例分割模型。我們的方法在不同準(zhǔn)確度水平的模型上都取得了顯著的增強(qiáng)效果。值得注意的是,當(dāng)應(yīng)用于三種 Model-Specific 的實(shí)例分割 Refinement 模型(包括PointRend、RefineMask 和 Mask TransFiner)時(shí),SegRefiner 依然能穩(wěn)定提升它們的性能,這說(shuō)明 SegRefiner 具有更強(qiáng)大的細(xì)節(jié)感知能力。
Dichotomous Image Segmentation
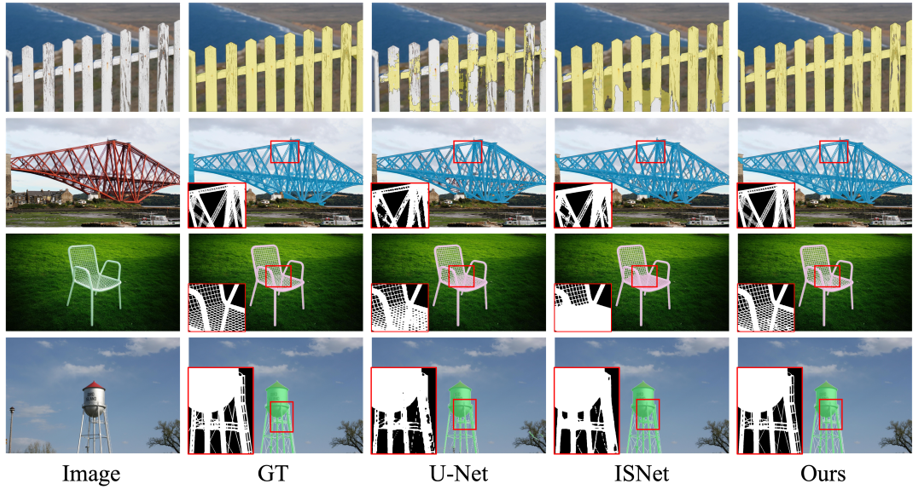
Dichotomous Image Segmentation 是一個(gè)較新提出的任務(wù),如下圖所示,其數(shù)據(jù)集包含大量具有復(fù)雜細(xì)節(jié)結(jié)構(gòu)的對(duì)象,因此十分適合評(píng)估我們 SegRefiner 對(duì)細(xì)節(jié)的感知能力。

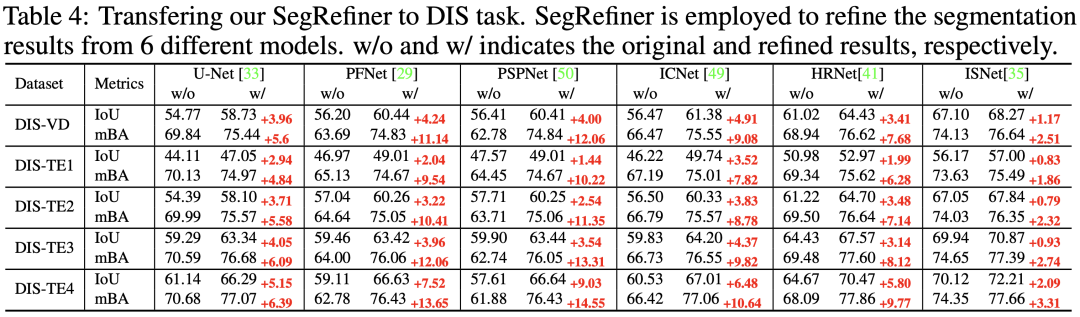
在本實(shí)驗(yàn)中,我們將 SegRefiner 應(yīng)用于6種分割模型,結(jié)果如表4所示。可以看到,我們的SegRefiner在 IoU 和 mBA 兩項(xiàng)指標(biāo)上都明顯提升了每個(gè)分割模型的準(zhǔn)確度。
可視化展示

審核編輯:劉清
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4807瀏覽量
102751 -
CRM
+關(guān)注
關(guān)注
1文章
148瀏覽量
21395 -
圖像分割
+關(guān)注
關(guān)注
4文章
182瀏覽量
18246 -
高斯噪聲
+關(guān)注
關(guān)注
0文章
11瀏覽量
8416
原文標(biāo)題:NeruIPS 2023 | SegRefiner:通過(guò)擴(kuò)散模型實(shí)現(xiàn)高精度圖像分割
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
基于擴(kuò)散模型的圖像生成過(guò)程

如何在PyTorch中使用擴(kuò)散模型生成圖像

基于GAC模型實(shí)現(xiàn)交互式圖像分割的改進(jìn)算法
使用全卷積網(wǎng)絡(luò)模型實(shí)現(xiàn)圖像分割
基于多級(jí)混合模型的圖像分割方法
基于像素聚類(lèi)進(jìn)行圖像分割的算法
基于活動(dòng)輪廓模型的圖像分割
基于圖像局部灰度差異的噪聲圖像分割模型
基于SEGNET模型的圖像語(yǔ)義分割方法
一種高精度的肝臟圖像自動(dòng)分割算法
SAM分割模型是什么?
近期分割大模型發(fā)展情況






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論