") 從Google多模態(tài)大模型看后續(xù)大模型應(yīng)該具備哪些能力
從Google多模態(tài)大模型看后續(xù)大模型應(yīng)該具備哪些能力
前段時(shí)間Google推出Gemini多模態(tài)大模型,展示了不凡的對(duì)話能力和多模態(tài)能力,其表現(xiàn)究竟如何呢?
本文對(duì)Gemini報(bào)告進(jìn)行分析,總的來說Gemini模型在圖像、音頻、視頻和文本理解方面表現(xiàn)出卓越的能力。其包括 Ultra、Pro 和 Nano 尺寸,能夠適用于從復(fù)雜推理任務(wù)到設(shè)備內(nèi)存受限用例的各種應(yīng)用。
不像OpenAI接入多模態(tài)能力需要利用多個(gè)不同的模型,Google直接在預(yù)訓(xùn)練階段直接接受多模態(tài)的輸入是Gemini的特點(diǎn)之一,它能夠直接處理多模態(tài)的數(shù)據(jù),并且各項(xiàng)指標(biāo)都還不錯(cuò)。另外可以看出具備圖文理解等能力后,再結(jié)合大模型的對(duì)話能力,能夠帶來更驚艷的效果體驗(yàn)。
一、概述
1Motivation
發(fā)布Google的能與GPT4競(jìng)爭(zhēng)的大模型,同時(shí)兼具多模態(tài)能力,包括文字、圖像、視頻、音頻識(shí)別與理解能力。
2Methods
1 Gemini模型支持4種格式輸入,2種格式輸出
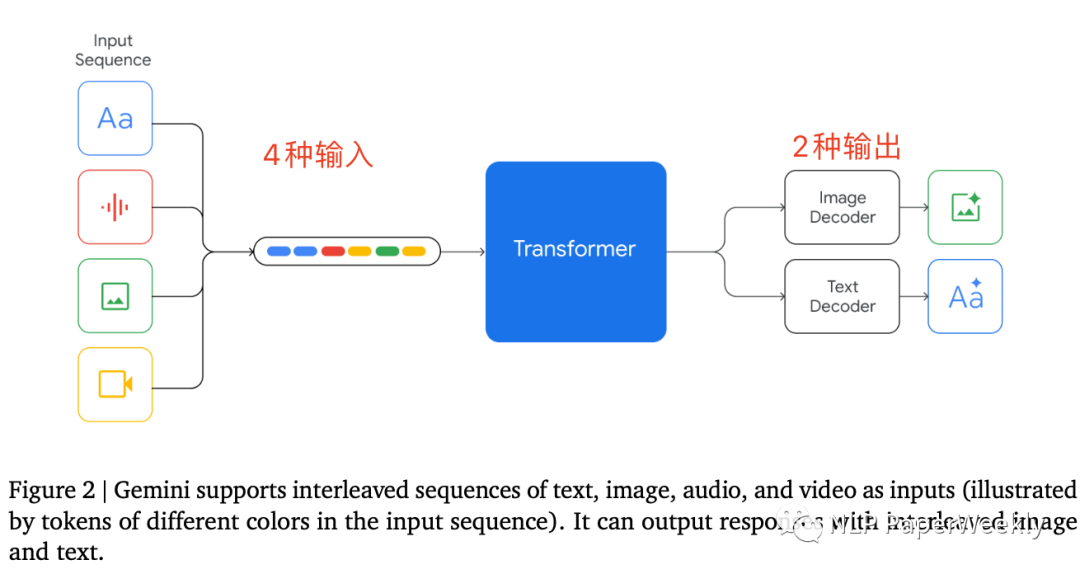
特點(diǎn):同時(shí)支持text文本,image圖像,video視頻和audio音頻輸入,支持文本和圖片的輸出。可以直接處理音頻文件,不需要將音頻轉(zhuǎn)為文字等。
猜測(cè)的訓(xùn)練方法:
多模態(tài)訓(xùn)練方法:Gemini是幾種模態(tài)一起聯(lián)合從頭訓(xùn)練的,包括文本、圖片、音頻、視頻等。這與目前通常的多模態(tài)做法不太一樣,目前的多模態(tài)模型一般是使用現(xiàn)成的語(yǔ)言大模型或者經(jīng)過預(yù)訓(xùn)練過的圖片模型(比如CLIP的圖片編碼部分),然后利用多模態(tài)訓(xùn)練數(shù)據(jù)在此基礎(chǔ)上加上新的網(wǎng)絡(luò)層訓(xùn)練;如果是幾個(gè)模態(tài)從頭開始一起訓(xùn)練,那么按理說應(yīng)該都遵循next token prediction的模式,就應(yīng)該是LVM的那個(gè)路子,其它模態(tài)的數(shù)據(jù)打成token,然后圖片、視頻等平面數(shù)據(jù)先轉(zhuǎn)換成比如16*16=256個(gè)token,然后搞成一維線性輸入,讓模型預(yù)測(cè)next token,這樣就把不同模態(tài)在訓(xùn)練階段統(tǒng)一起來。
解碼結(jié)構(gòu):Decoder only的模型結(jié)構(gòu),針對(duì)結(jié)構(gòu)和優(yōu)化目標(biāo)做了優(yōu)化,優(yōu)化目的是大規(guī)模訓(xùn)練的時(shí)候的訓(xùn)練和推理的穩(wěn)定性,所以大結(jié)構(gòu)應(yīng)該是類似GPT的Decoder-only預(yù)測(cè)next token prediction的模式。目前支持32K上下文。
命令理解方面:和GPT一樣,采用多模態(tài)instruct數(shù)據(jù)進(jìn)行SFT+RM+RLHF三階段,這里的RM部分在訓(xùn)練打分模型的時(shí)候,采用了加權(quán)的多目標(biāo)優(yōu)化,三個(gè)目標(biāo)helpfulness factuality和 safety,猜測(cè)應(yīng)該是對(duì)于某個(gè)prompt,模型生成的結(jié)果,按照三個(gè)指標(biāo)各自給了一個(gè)排序結(jié)果。
模型大小:從硬件描述部分來看,意思是動(dòng)用了前所未有的TPU集群,所以推測(cè)Gemini Ultra的模型規(guī)模應(yīng)該相當(dāng)大,猜測(cè)如果是MOE大概要對(duì)標(biāo)到GPT 4到1.8T的模型容量,如果是Dense模型估計(jì)要大于200B參數(shù)。考慮到引入視頻音頻(當(dāng)然是來自于Youtube了,難道會(huì)來自TikTok么)多模態(tài)數(shù)據(jù),所以總數(shù)據(jù)量*模型參數(shù),會(huì)是非常巨大的算力要求,技術(shù)報(bào)告說可以一周或者兩周做一次訓(xùn)練。
訓(xùn)練細(xì)節(jié):可能分成多個(gè)階段,最后階段提高了領(lǐng)域數(shù)據(jù)的混合配比,猜測(cè)應(yīng)該指的是邏輯和數(shù)學(xué)類的訓(xùn)練數(shù)據(jù)增加了配比,目前貌似很多這么做的,對(duì)于提升模型邏輯能力有直接幫助。
代碼能力:AlphaCode2是在Gemini pro基礎(chǔ)上,使用編程競(jìng)賽的數(shù)據(jù)fine-tune出來的,效果提升很明顯,在編程競(jìng)賽上排名超過85%的人類選手,之前的AlphaCode1超過50%的人類選手;
2 Gemini模型有多個(gè)版本,最小有1.8B

特點(diǎn):其中Nano首先從大模型蒸餾,然后4bit量化。Gemini Nano包含兩個(gè)版本:1.8B面向低端手機(jī),3.25B面向高端手機(jī)。
3 Conclusion
1 文本理解:Ultra性能超過了GPT4
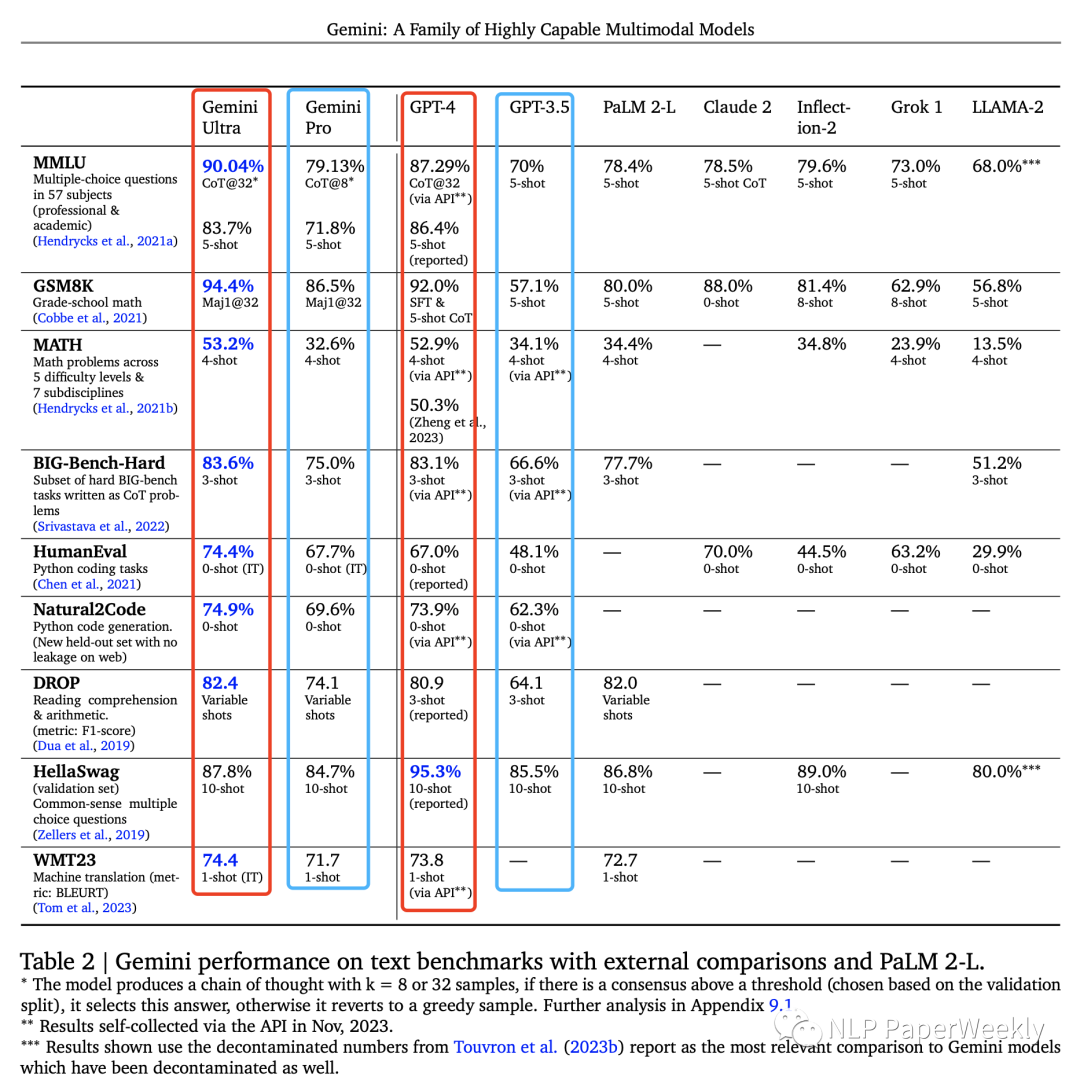
Ultra比gpt4效果好,pro比gpt3.5效果好,MMNLU第一次超過人類專家水平。
Gemini Ultra 在六個(gè)不同數(shù)據(jù)集上都是最佳。Gemini Pro是Gemini系列中的第二大模型,效率更高的同時(shí)也頗具競(jìng)爭(zhēng)力。
2 圖像理解:zero-shot效果超過很多微調(diào)后的模型
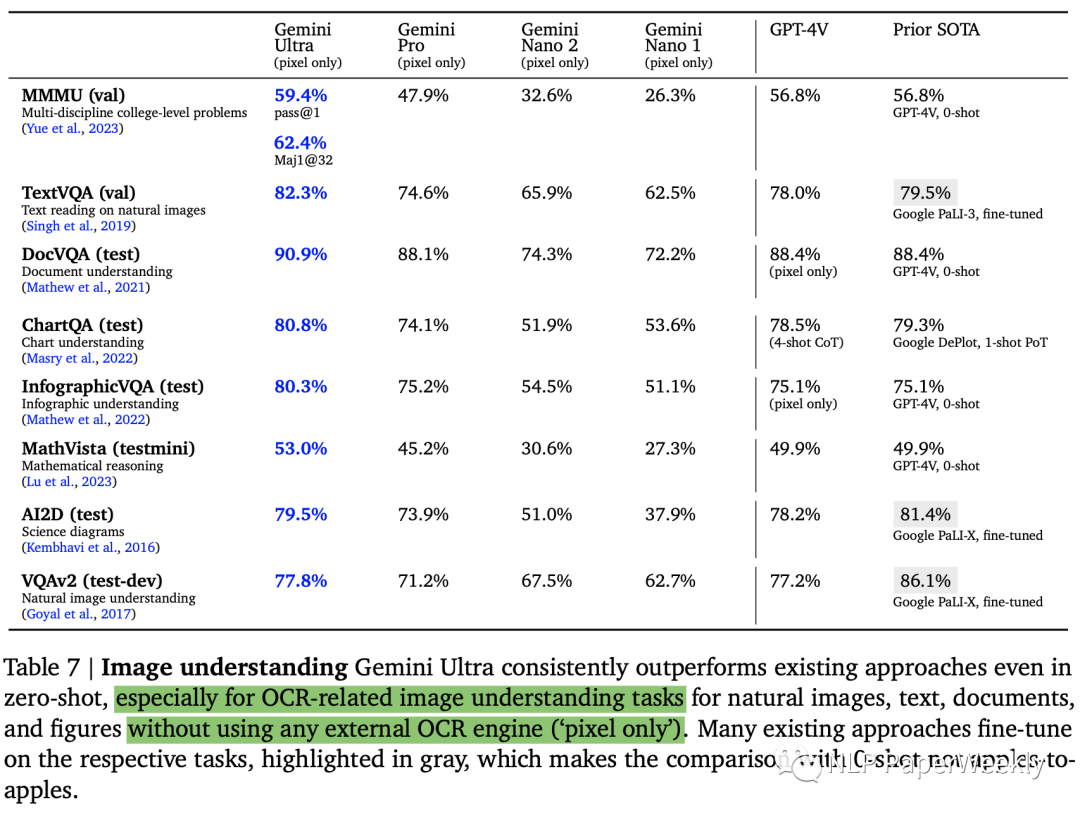
3 視頻理解:超過之前的few-shot SoTA模型
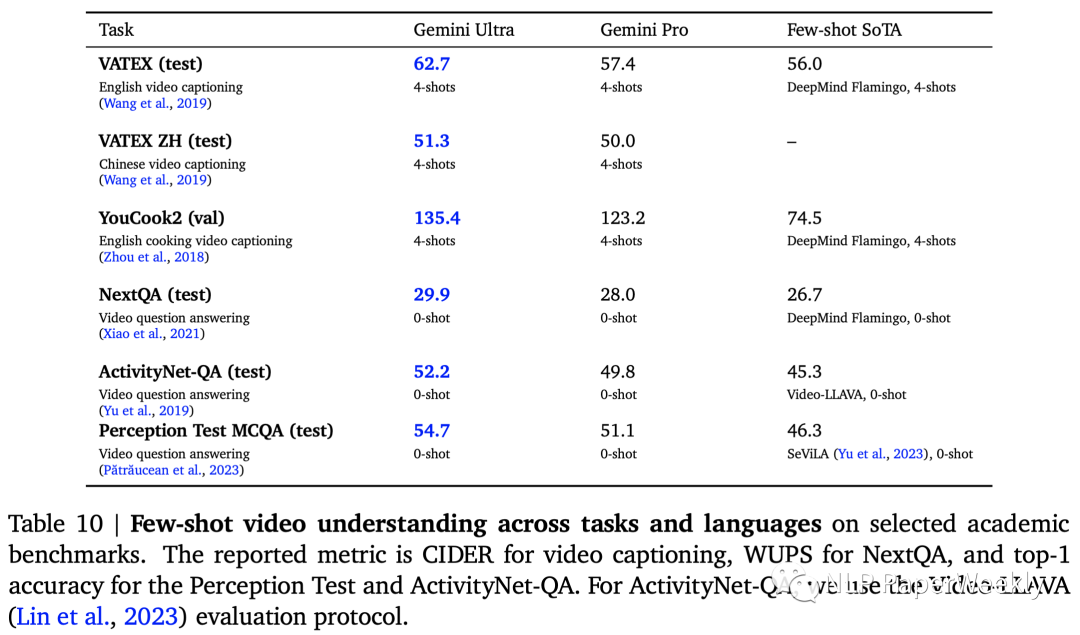
也是取得了SoTA,特別是英語(yǔ)視頻字幕數(shù)據(jù)集(VATEXT、YouCook2)上提升比較大,其他感覺提升沒那么大。相關(guān)評(píng)估指標(biāo)如下:視頻字幕 -> CIDER,NextQA -> WUPS,Perception Test -> top-1 accuracy,ActivityNet-QA -> ActivityNet-QA。
4 不同版Genmini模型的性能
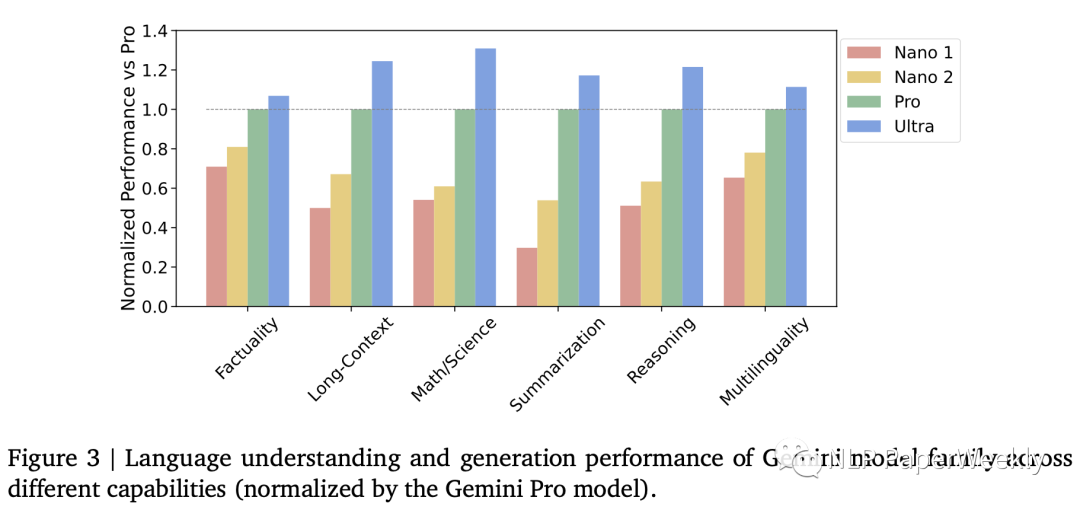
“事實(shí)性” :涵蓋開放/閉卷檢索和問題回答任務(wù);
“長(zhǎng)文本” :涵蓋長(zhǎng)篇摘要、檢索和問題回答任務(wù);
“數(shù)學(xué)/科學(xué)” :包括數(shù)學(xué)問題解決、定理證明和科學(xué)考試等任務(wù);
“推理” :需要算術(shù)、科學(xué)和常識(shí)推理的任務(wù);
“多語(yǔ)言” :用于多語(yǔ)言翻譯、摘要和推理的任務(wù)。
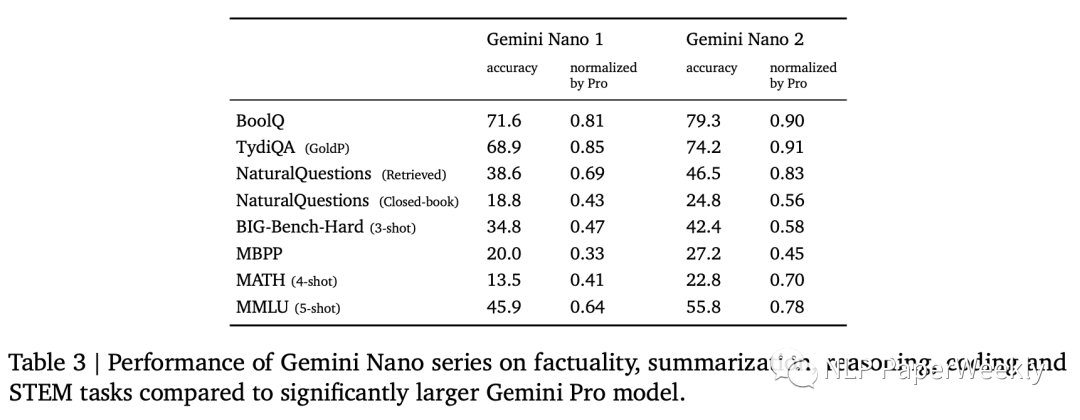
Nano2模型很多超過了Pro版本的50%,部分達(dá)到90的水平,效果還不錯(cuò)。
5 多語(yǔ)種翻譯:性能超過GPT4
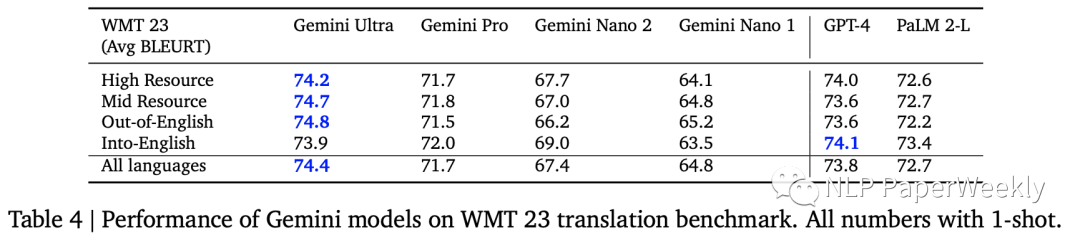
翻譯能力也是比GPT-4好,WMT23指標(biāo)中4個(gè)有3個(gè)超過GPT4的表現(xiàn)。
6 圖像理解數(shù)據(jù)集:MMMU數(shù)據(jù)集表現(xiàn)
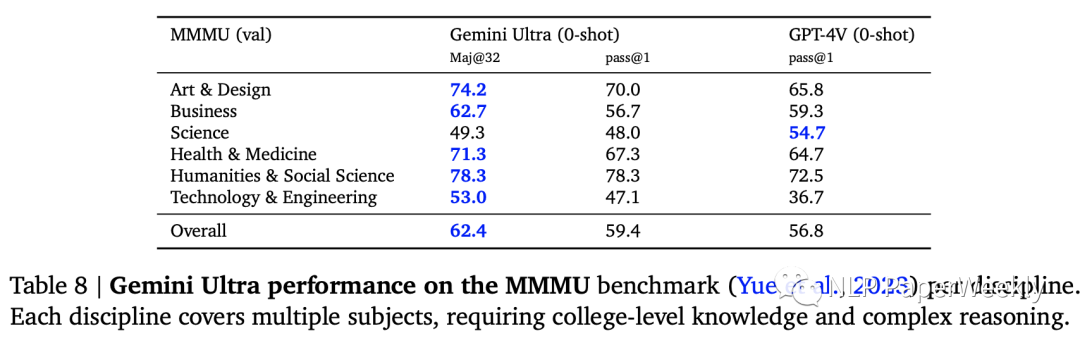
MMMU(Yue et al., 2023):是最近發(fā)布的評(píng)估基準(zhǔn),由6個(gè)學(xué)科的圖像問題組成,每個(gè)學(xué)科內(nèi)有多個(gè)主題,需要大學(xué)水平的知識(shí)來解決這些問題。
Gemini Ultra將最先進(jìn)的結(jié)果提高了 5 個(gè)百分點(diǎn)以上,6個(gè)學(xué)科中有5個(gè)學(xué)科中超越了之前的最佳成績(jī),展示了其多模態(tài)推理能力。
二、詳細(xì)內(nèi)容
1 多模態(tài)推理能力:識(shí)別手寫答案,對(duì)物理問題進(jìn)行解答

特點(diǎn):識(shí)別書寫結(jié)果,這個(gè)和OpenAI之前演示的根據(jù)草圖寫前端代碼是一樣的,不過識(shí)別的準(zhǔn)確率是存疑的。
2 多模態(tài)推理能力:重新組織子圖順序
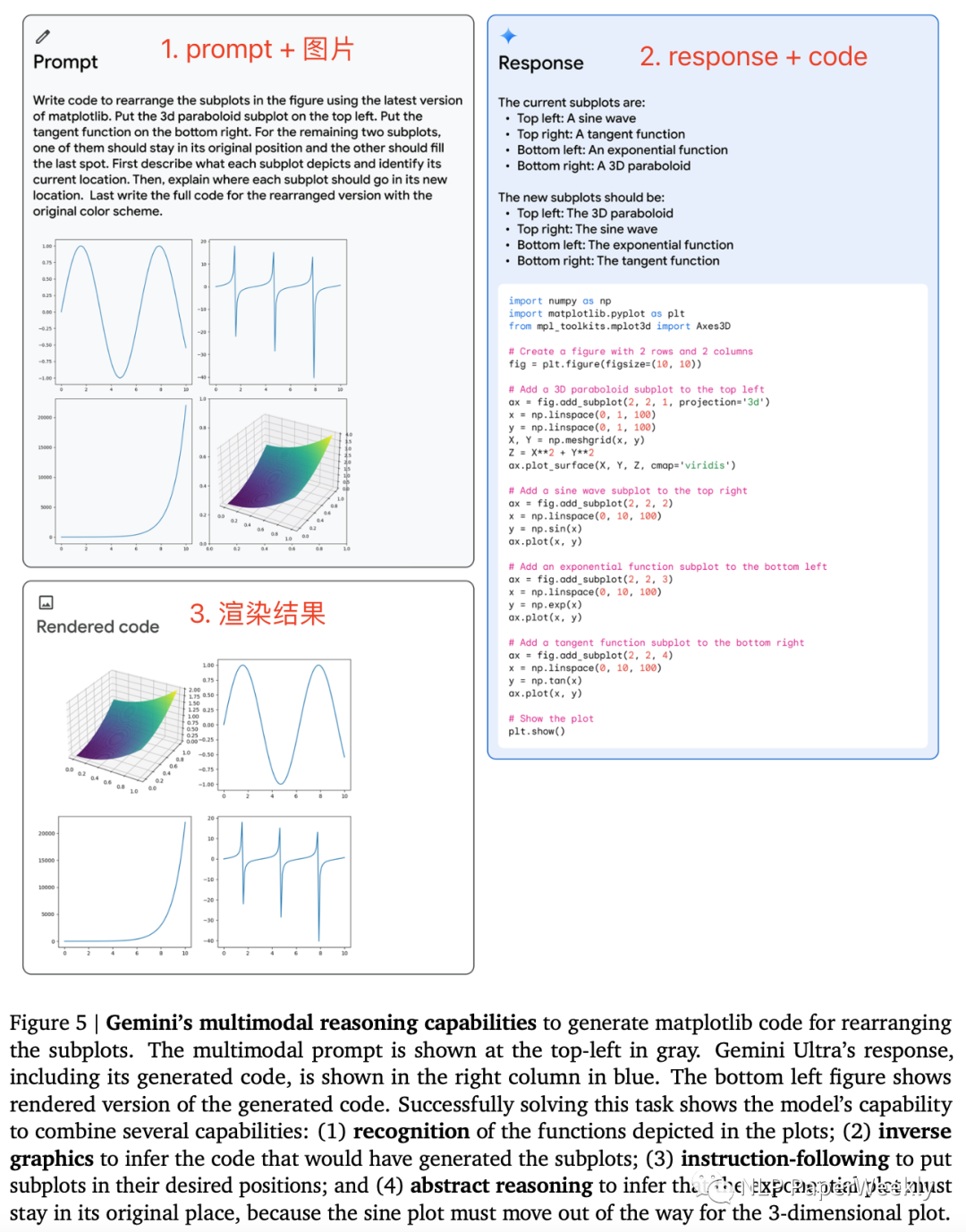
Gemini的多模態(tài)推理能力可生成用于重新排列子圖的matplotlib代碼。
Prompt:識(shí)別當(dāng)前子圖的結(jié)果,重新組織子圖的順序并解釋。
解決此任務(wù)需要模型具備以下能力:
(1) 識(shí)別圖中描繪的函數(shù);
(2) 逆向圖形來推斷生成子圖的代碼;
(3) 按照指令將子圖放置在所需的位置;
(4) 抽象推理,推斷指數(shù)圖必須留在原來的位置,因?yàn)檎覉D必須為 3 維圖移動(dòng)。
3 圖像生成能力:多模態(tài)理解+圖像生成
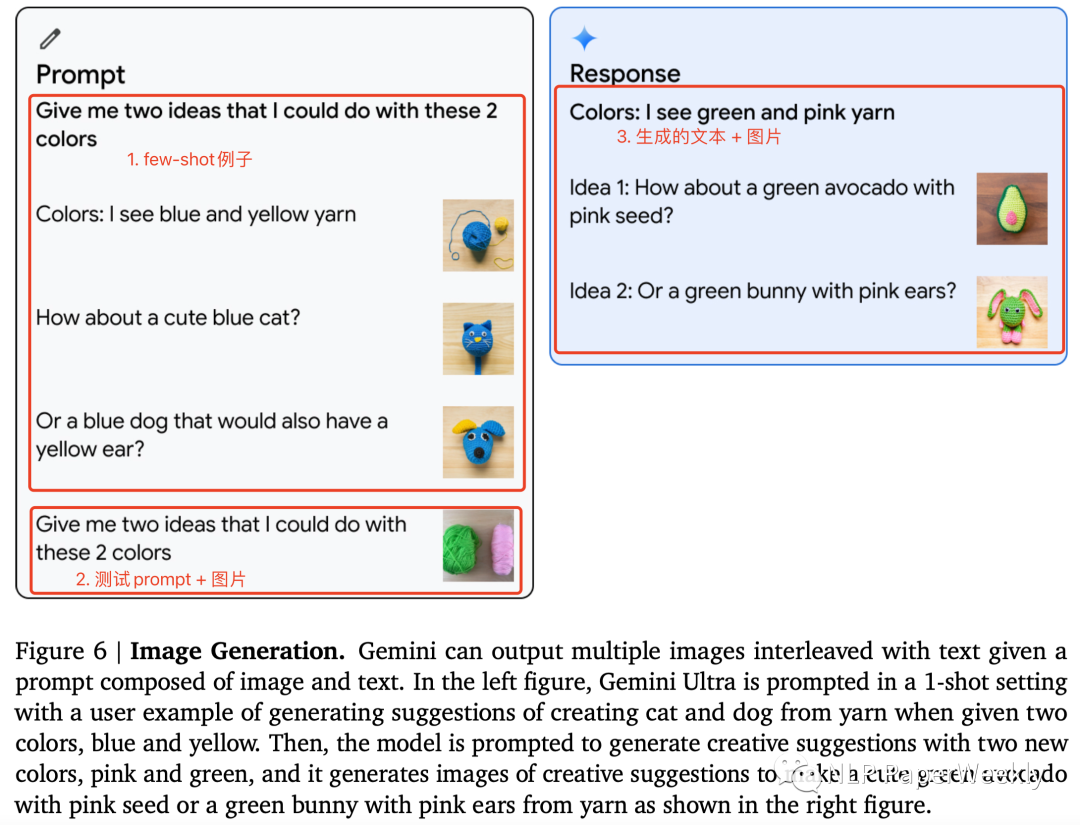
要具備上面的功能需要以下能力:
(1)識(shí)別圖像中的顏色。這個(gè)難度不大。
(2)生成文字+圖片結(jié)果。這個(gè)難度好像也沒有那么大,可能有two-stage的實(shí)現(xiàn)方法或者end-to-end的實(shí)現(xiàn)方法。不太確定google用的哪種方法。
4 語(yǔ)音理解能力:具備語(yǔ)音識(shí)別和語(yǔ)音翻譯能力
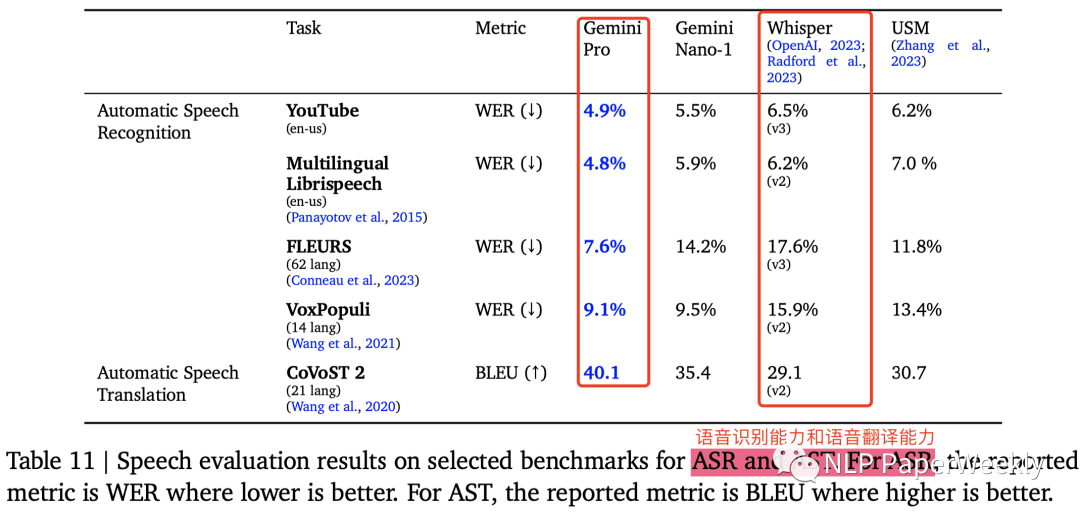
對(duì)比的是OpenAI的Whisper,看著Gemini就是把多個(gè)SoTA模型包裝起來了。
5 多模態(tài)理解:支持圖片+音頻輸入

這個(gè)gptv+加個(gè)語(yǔ)音轉(zhuǎn)文字的模型可以做,這里的特點(diǎn)可能是直接用一個(gè)模型就可以解決?
三、多模態(tài)能力展示
1 幾何推理能力:求平行四邊形的高

2 視覺多模態(tài)推理能力:根據(jù)圖片確定地點(diǎn)

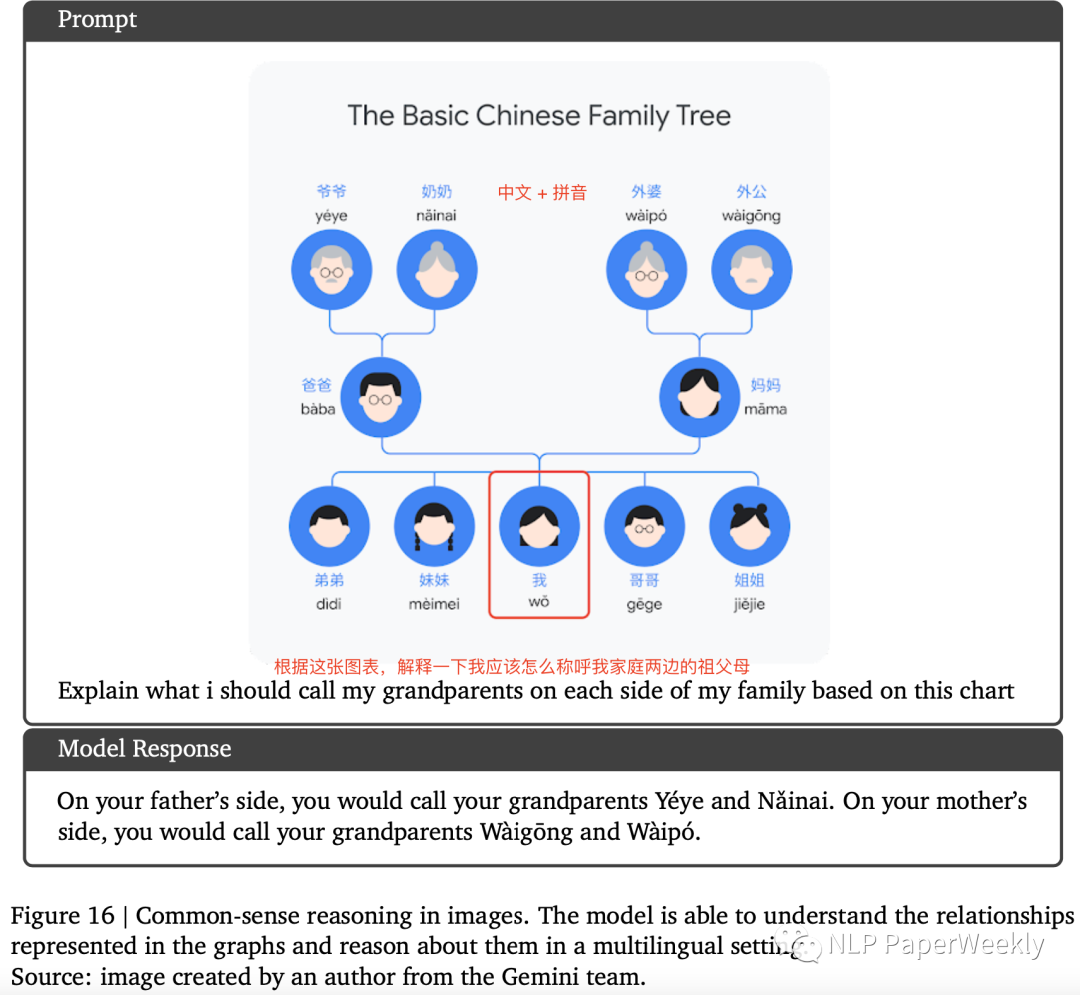
3 多語(yǔ)言常識(shí)推理:識(shí)別中文關(guān)系圖
4 視頻理解能力:分析視頻中的人如何提升足球技術(shù)

四、總結(jié)
直接支持多模態(tài)的能力是Gemini的特點(diǎn),Google從預(yù)訓(xùn)練階段就統(tǒng)一了多模態(tài)大模型的訓(xùn)練,該策略也可能是后續(xù)大模型的發(fā)展趨勢(shì),但是其具體實(shí)現(xiàn)方法、帶來的增益、以及cost還未知。OpenAI多模態(tài)的能力是引入(支持語(yǔ)音)其他模型或者通過插件(支持圖像)來實(shí)現(xiàn)。
Gemini的多模態(tài)能力比GPT4-V要強(qiáng),科學(xué)推理能力可能稍微弱于GPT4。
圖文理解+視頻理解等多模態(tài)能力與最新的大模型強(qiáng)強(qiáng)組合確實(shí)能帶來驚艷的效果,但是其穩(wěn)定性,是否真實(shí)能落地還有待進(jìn)一步觀察。例如結(jié)合圖像信息求平行四邊行的高,在教育領(lǐng)域相對(duì)于純文本可能會(huì)更有價(jià)值,但是OCR等技術(shù)還面臨魯棒性偏差的問題,Google的模型段時(shí)間應(yīng)該還是沒辦法解決這些問題。
審核編輯:劉清
-
SFT
+關(guān)注
關(guān)注
0文章
9瀏覽量
6877 -
TPU
+關(guān)注
關(guān)注
0文章
152瀏覽量
21085 -
GPT
+關(guān)注
關(guān)注
0文章
368瀏覽量
15951 -
OpenAI
+關(guān)注
關(guān)注
9文章
1202瀏覽量
8650
原文標(biāo)題:Gemini技術(shù)報(bào)告解讀:從Google多模態(tài)大模型看后續(xù)大模型應(yīng)該具備哪些能力
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
愛芯通元NPU適配Qwen2.5-VL-3B視覺多模態(tài)大模型

簡(jiǎn)單的模型進(jìn)行流固耦合的模態(tài)分析
VisCPM:邁向多語(yǔ)言多模態(tài)大模型時(shí)代

更強(qiáng)更通用:智源「悟道3.0」Emu多模態(tài)大模型開源,在多模態(tài)序列中「補(bǔ)全一切」

北大&華為提出:多模態(tài)基礎(chǔ)大模型的高效微調(diào)

探究編輯多模態(tài)大語(yǔ)言模型的可行性
大模型+多模態(tài)的3種實(shí)現(xiàn)方法

機(jī)器人基于開源的多模態(tài)語(yǔ)言視覺大模型

李未可科技正式推出WAKE-AI多模態(tài)AI大模型

商湯科技發(fā)布5.0多模態(tài)大模型,綜合能力全面對(duì)標(biāo)GPT-4 Turbo
智譜AI發(fā)布全新多模態(tài)開源模型GLM-4-9B
云知聲山海多模態(tài)大模型UniGPT-mMed登頂MMMU測(cè)評(píng)榜首






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論