") 微軟正式發(fā)布一個27億參數(shù)的語言模型—Phi-2
微軟正式發(fā)布一個27億參數(shù)的語言模型—Phi-2
先后和 OpenAI、Meta 牽手推動大模型發(fā)展的微軟,也正在加快自家小模型的迭代。就在今天,微軟正式發(fā)布了一個 27 億參數(shù)的語言模型——Phi-2。這是一種文本到文本的人工智能程序,具有出色的推理和語言理解能力。
同時,微軟研究院也在官方 X 平臺上如是說道,“Phi-2 的性能優(yōu)于其他現(xiàn)有的小型語言模型,但它足夠小,可以在筆記本電腦或者移動設(shè)備上運行”。
Phi-2 的性能真能優(yōu)于大它 25 倍的模型?
對于Phi-2 的發(fā)布,微軟研究院在官方公告的伊始便直言,Phi-2 的性能可與大它 25 倍的模型相匹配或優(yōu)于。
這也讓人有些尷尬的事,不少網(wǎng)友評價道,這豈不是直接把 Google 剛發(fā)的 Gemini 最小型號的版本給輕松超越了?

那具體情況到底如何?
微軟通過時下一些如 Big Bench Hard (BBH)、常識推理(PIQA、WinoGrande、ARC easy 和 Challenge、SIQA)、語言理解(HellaSwag、OpenBookQA、MMLU(5-shot)、 SQuADv2、BoolQ)、數(shù)學(xué)(GSM8k)和編碼(HumanEval)等基準(zhǔn)測試,將 Phi-2 與 7B 和 13B 參數(shù)的 Mistral 和 Llama-2 進(jìn)行了比較。
最終得出僅擁有 27 億個參數(shù)的 Phi-2 ,超越了 Mistral 7B 和 Llama-2 7B 以及 13B 模型的性能。值得注意的是,與大它 25 倍的 Llama-2-70B 模型相比,Phi-2 還在多步推理任務(wù)(即編碼和數(shù)學(xué))上實現(xiàn)了更好的性能。
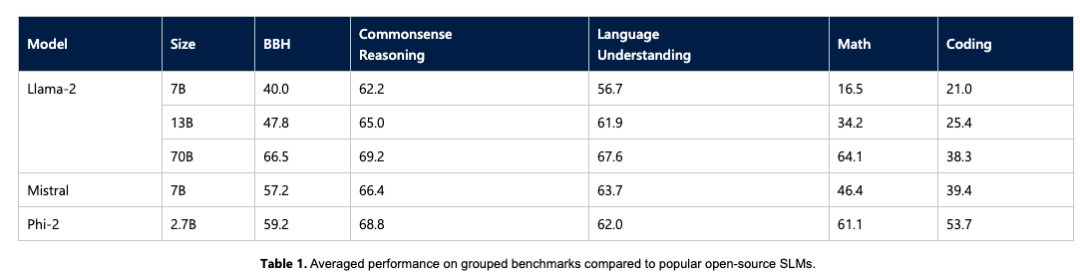
此外,如上文所提及的,微軟研究人員也直接在基準(zhǔn)測試中放上了其與Google 全新發(fā)布的 Gemini Nano 2 正面PK 的結(jié)果,不出所料,Phi-2盡管尺寸較小,但性能還是把Gemini Nano 2 超了。

除了這些基準(zhǔn)之外,研究人員似是在暗諷 Google 前幾日在Gemini 演示視頻中造假一事,因為當(dāng)時 Google 稱其即將推出的最大、最強大的新人工智能模型 Gemini Ultra 能夠解決相當(dāng)復(fù)雜的物理問題,并且甚至糾正學(xué)生的錯誤。
事實證明,盡管 Phi-2 的大小可能只是 Gemini Ultra 的一小部分,但它也能夠正確回答問題并使用相同的提示糾正學(xué)生。

微軟的改進(jìn)
Phi-2 小模型之所以有如此亮眼的成績,微軟研究院在博客中解釋了原因。
一是提升訓(xùn)練數(shù)據(jù)的質(zhì)量。Phi-2 是一個基于 Transformer 的模型,其目標(biāo)是預(yù)測下一個單詞,它在 1.4T 個詞組上進(jìn)行了訓(xùn)練,這些詞組來自 NLP 和編碼的合成數(shù)據(jù)集和網(wǎng)絡(luò)數(shù)據(jù)集,包括科學(xué)、日常活動和心理理論等用于教授模型常識和推理的內(nèi)容。Phi-2 的訓(xùn)練是在 96 個 A100 GPU 上耗時 14 天完成的。
其次,微軟使用創(chuàng)新技術(shù)進(jìn)行擴(kuò)展,將其知識嵌入到 27 億參數(shù) Phi-2 中。
微軟指出,Phi-2 是一個基礎(chǔ)模型,沒有通過人類反饋強化學(xué)習(xí)(RLHF)進(jìn)行調(diào)整,也沒有經(jīng)過指導(dǎo)性微調(diào)。盡管如此,與經(jīng)過對齊的現(xiàn)有開源模型相比,微軟觀察到在毒性和偏差方面,Phi-2 有更好的表現(xiàn)。
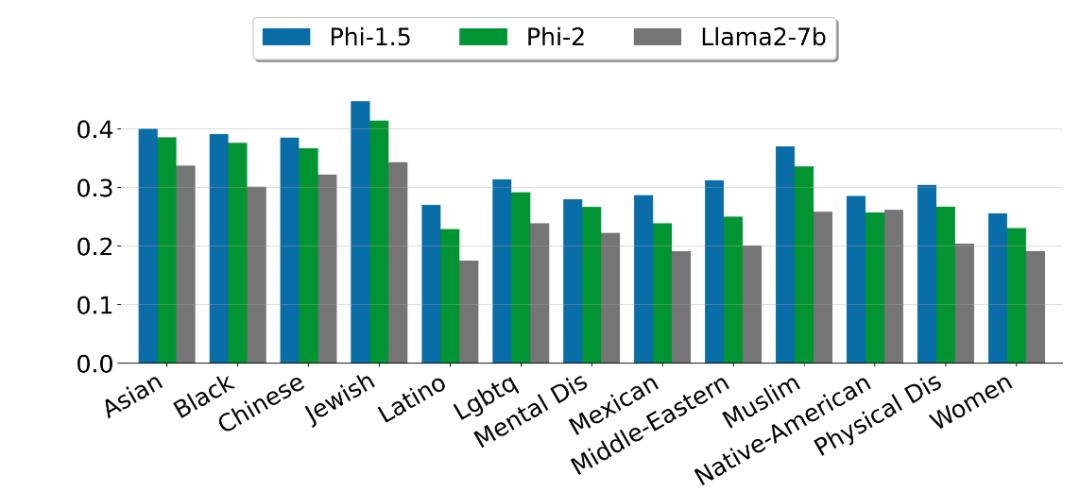
寫在最后
話說 Phi-2 的發(fā)布的確在小模型的性能上實現(xiàn)了突破,不過也有媒體發(fā)現(xiàn)它還存在很大的局限性。
因為根據(jù)微軟研究許可證顯示,其規(guī)定了 Phi -2 只能用于“非商業(yè)、非創(chuàng)收、研究目的”,而不是商業(yè)用途。因此,想要在其之上構(gòu)建產(chǎn)品的企業(yè)就不走運了。
審核編輯:劉清
-
編碼器
+關(guān)注
關(guān)注
45文章
3773瀏覽量
137122 -
OpenAI
+關(guān)注
關(guān)注
9文章
1201瀏覽量
8634 -
大模型
+關(guān)注
關(guān)注
2文章
3022瀏覽量
3819
原文標(biāo)題:只有 27 億參數(shù),微軟發(fā)布全新 Phi-2 模型!
文章出處:【微信號:AI科技大本營,微信公眾號:AI科技大本營】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
華為助力中國石油發(fā)布3000億參數(shù)昆侖大模型

小身板大能量:樹莓派玩轉(zhuǎn) Phi-2、Mistral 和 LLaVA 等AI大模型~

在算力魔方上本地部署Phi-4模型
微軟尋求在365 Copilot中引入非OpenAI模型
中國移動與中國石油發(fā)布700億參數(shù)昆侖大模型
AMD發(fā)布10億參數(shù)開源AI模型OLMo

騰訊發(fā)布開源MoE大語言模型Hunyuan-Large
大語言模型如何開發(fā)
在英特爾酷睿Ultra7處理器上優(yōu)化和部署Phi-3-min模型
中國石油發(fā)布330億參數(shù)昆侖大模型
Hugging Face科技公司推出SmolLM系列語言模型
谷歌Gemma 2大語言模型升級發(fā)布,性能與安全性雙重飛躍
谷歌發(fā)布新型大語言模型Gemma 2
大語言模型(LLM)快速理解






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論