") 訪問寄存器代替內(nèi)存引用
訪問寄存器代替內(nèi)存引用
我們先看一個例子:
有這么兩個程序:它們的目的就是將數(shù)組x中的數(shù),按照下標累加到數(shù)組y中,最后在把數(shù)組y中的數(shù)據(jù)累加到一個數(shù)dest里面。為了驗證效果,我們將這個過程重復(fù)10000遍。

Prog 1 Prog2
這兩個程序的區(qū)別就在Prog2中紅框里面的內(nèi)容。那么哪個程序運行的更快呢?
話不多說,我們看實際的結(jié)果:


這里為了說明效果,我們編譯的時候,并沒有采用優(yōu)化(編譯優(yōu)化,確實可以提高程序運行的效率,但是過高的編譯優(yōu)化等級會有一定的副作用,另外編譯器優(yōu)化也具有一定的局限性,高效的代碼仍然應(yīng)該是我們追求的目標)。可以看到,Prog2要明顯比Prog1快。
要想理解上面的例子,我們必須先介紹一下寄存器和匯編代碼的相關(guān)知識:
寄存器
CPU內(nèi)部用來存放數(shù)據(jù)的一些小型存儲區(qū)域, 注意寄存器是在CPU內(nèi)部,受限于CPU的物理尺寸,寄存器數(shù)量不會太多。我們只需要記住兩點:
1) 寄存器和CPU的L1 cache相比,速度雖然還在一個數(shù)量級,但是L1 cache的訪問速度還是要慢幾倍。具體的數(shù)據(jù)見下文表2
2) CPU只能從寄存器直接取數(shù)據(jù)或者指令,如果取不到,獲取的順序是L1-》L2-》L3-》主存-》磁盤。
從下文表2中可以看出,如果cpu的cache訪問miss了,性能損失還是很大的。如果內(nèi)存里面再miss了,那對性能來說不亞于一場災(zāi)難了。
計算機訪問速度分級:
表1 時間單位

以3.3GHz的CPU為例:
表2 系統(tǒng)的各種延時

正如你所見,CPU周期的時間非常短,這段時間,光的速度大約只能走0.5米。想象一下,是不是非常震撼?
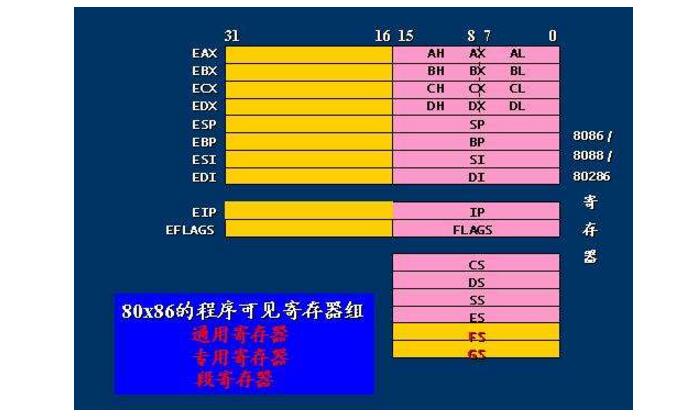
x86-64 CPU的整數(shù)寄存器:

我們無需刻意去記住這些寄存器的名稱,不同架構(gòu)的寄存器的數(shù)量和名稱也不一樣,我們只要知道他們是cpu內(nèi)部的效率極高的存儲單元即可。
回到前面的例子,為什么Prog2要比Prog1快,是因為Prog2里面用DEST這個局部變量代替了dest。DEST是一個局部變量,在匯編指令里是直接訪問寄存器,而dest則需要去訪問內(nèi)存cache。
-
寄存器
+關(guān)注
關(guān)注
31文章
5425瀏覽量
123544 -
cpu
+關(guān)注
關(guān)注
68文章
11049瀏覽量
216153 -
內(nèi)存
+關(guān)注
關(guān)注
8文章
3111瀏覽量
75032 -
程序
+關(guān)注
關(guān)注
117文章
3824瀏覽量
82504
發(fā)布評論請先 登錄
閃存存儲器是寄存器嗎?_寄存器和存儲器的區(qū)別
多寄存器Load/Store內(nèi)存訪問指令
為什么寄存器比內(nèi)存快_原因是這個
逆向基礎(chǔ)之寄存器和內(nèi)存詳解
RFM反射內(nèi)存5565控制和狀態(tài)寄存器
寄存器變量
零基礎(chǔ)學ARM:程序狀態(tài)寄存器訪問指令解析
寄存器與內(nèi)存的區(qū)別
C語言訪問MCU寄存器

Cortex-M3 內(nèi)部寄存器
訪問CXL 2.0設(shè)備中的內(nèi)存映射寄存器





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論