") 高并發(fā)內(nèi)存池項(xiàng)目實(shí)現(xiàn)
高并發(fā)內(nèi)存池項(xiàng)目實(shí)現(xiàn)
本項(xiàng)目實(shí)現(xiàn)了一個(gè)高并發(fā)內(nèi)存池,參考了Google的開(kāi)源項(xiàng)目tcmalloc實(shí)現(xiàn)的簡(jiǎn)易版;其功能就是實(shí)現(xiàn)高效的多線程內(nèi)存管理。由功能可知,高并發(fā)指的是高效的多線程,而內(nèi)存池則是實(shí)現(xiàn)內(nèi)存管理的。
內(nèi)存池相關(guān)知識(shí)
1、池化技術(shù)
池化技術(shù)就是程序先向系統(tǒng)申請(qǐng)過(guò)量的資源,并將這些資源管理起來(lái),避免頻繁的申請(qǐng)和釋放資源導(dǎo)致的開(kāi)銷(xiāo)。
內(nèi)存池可以使用池化技術(shù)來(lái)維護(hù)可用內(nèi)存塊的鏈表。當(dāng)程序需要分配內(nèi)存時(shí),內(nèi)存池會(huì)從鏈表中分配一個(gè)可用的內(nèi)存塊。如果沒(méi)有可用的內(nèi)存塊,內(nèi)存池會(huì)從操作系統(tǒng)申請(qǐng)更多的內(nèi)存,并將新分配的內(nèi)存塊添加到鏈表中。當(dāng)程序釋放內(nèi)存時(shí),內(nèi)存池會(huì)將內(nèi)存塊添加回鏈表中,以便將來(lái)使用。
池化技術(shù)可以有效地減少內(nèi)存碎片,因?yàn)樗梢詫⒍鄠€(gè)小內(nèi)存塊組合成更大的內(nèi)存塊,這樣就可以分配更大的連續(xù)內(nèi)存空間,并減少碎片。此外,池化技術(shù)還可以提高內(nèi)存使用效率,因?yàn)樗梢钥焖俜峙浜歪尫艃?nèi)存,而無(wú)需每次都調(diào)用操作系統(tǒng)的內(nèi)存分配和釋放函數(shù)。
2、內(nèi)存池
內(nèi)存池指的是程序預(yù)先向操作系統(tǒng)申請(qǐng)足夠大的一塊內(nèi)存空間;此后,程序中需要申請(qǐng)內(nèi)存時(shí),不需要直接向操作系統(tǒng)申請(qǐng),而是直接從內(nèi)存池中獲取;同理,程序釋放內(nèi)存時(shí),也不是將內(nèi)存直接還給操作系統(tǒng),而是將內(nèi)存歸還給內(nèi)存池。當(dāng)程序退出(或者特定時(shí)間)時(shí),內(nèi)存池才將之前申請(qǐng)的內(nèi)存真正釋放。
3、內(nèi)存池主要解決的問(wèn)題
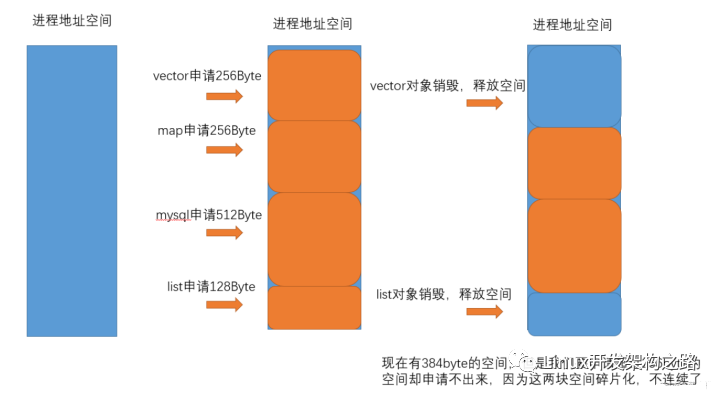
由上可知,內(nèi)存池首要解決的是效率問(wèn)題,其次從系統(tǒng)的內(nèi)存分配器角度出發(fā),還需要解決內(nèi)存碎片的問(wèn)題。那么什么是內(nèi)存碎片問(wèn)題呢?
內(nèi)存碎片分為外碎片和內(nèi)碎片。
- 外碎片由下圖所示:對(duì)于程序員申請(qǐng)的內(nèi)存,可能因?yàn)轭l繁的申請(qǐng)和釋放內(nèi)存導(dǎo)致內(nèi)存空間不連續(xù),那么就會(huì)出現(xiàn)明明由足夠大的內(nèi)存空間,但程序員卻申請(qǐng)不出連續(xù)的空間出來(lái),這便是外碎片問(wèn)題了。
- 內(nèi)碎片則是由于一些對(duì)齊的需求,導(dǎo)致分配出去的內(nèi)存空間無(wú)法被利用,比如本項(xiàng)目中的Round(Size)對(duì)size進(jìn)行的對(duì)齊。
4、malloc
C語(yǔ)言中動(dòng)態(tài)申請(qǐng)內(nèi)存是通過(guò)malloc函數(shù)去申請(qǐng)內(nèi)存的,但是實(shí)際上malloc并不是直接向堆申請(qǐng)內(nèi)存的,而malloc也可以使用內(nèi)存池來(lái)管理內(nèi)存分配,在某些情況下,操作系統(tǒng)或C語(yǔ)言標(biāo)準(zhǔn)庫(kù)可能會(huì)使用內(nèi)存池來(lái)管理堆內(nèi)存,以提高內(nèi)存分配效率。當(dāng)程序?qū)alloc管理的內(nèi)存池中內(nèi)存全部申請(qǐng)完時(shí),malloc函數(shù)就會(huì)繼續(xù)向操作系統(tǒng)申請(qǐng)空間。
設(shè)計(jì)思路
第一階段–設(shè)計(jì)一個(gè)定長(zhǎng)的內(nèi)存池
我們知道m(xù)alloc函數(shù)申請(qǐng)內(nèi)存空間是通用的,即任何場(chǎng)景下都可以使用,但是各方面都通用就意味著各方面都不頂尖,那么我們可以設(shè)計(jì)一個(gè)定長(zhǎng)內(nèi)存池來(lái)保證特定場(chǎng)景下的內(nèi)存申請(qǐng)效率要高于malloc函數(shù)。
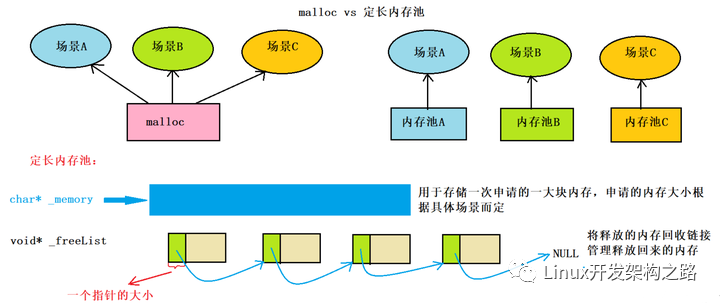
適應(yīng)平臺(tái)的指針?lè)桨?/h3>
在這里,我們想取出一塊對(duì)象內(nèi)存中的前4個(gè)字節(jié)(32位系統(tǒng))或者8個(gè)字節(jié)(64位系統(tǒng))的內(nèi)存來(lái)存儲(chǔ)一個(gè)指針指向下一塊釋放回來(lái)的自由對(duì)象內(nèi)存,那么在這里為了不作平臺(tái)系統(tǒng)的判斷,可以使用一個(gè)小技巧,即將對(duì)象內(nèi)存強(qiáng)轉(zhuǎn)成void**的類(lèi)型,那么再對(duì)這個(gè)二級(jí)指針類(lèi)型解引用就可以取出當(dāng)前對(duì)象的前4個(gè)字節(jié)(32位系統(tǒng))或8個(gè)字節(jié)(64位系統(tǒng))。
由于這個(gè)操作之后會(huì)頻繁使用,因此定義為內(nèi)斂函數(shù)放在common.h頭文件中方便調(diào)用:
{
return *(void**)obj;
}
由此,我們就可以設(shè)計(jì)出定長(zhǎng)內(nèi)存池的對(duì)象:
定長(zhǎng)內(nèi)存池池的基本思想是在程序運(yùn)行時(shí)預(yù)先分配一大塊內(nèi)存,然后在需要使用某個(gè)對(duì)象時(shí),從這塊內(nèi)存中分配給它。當(dāng)對(duì)象不再使用時(shí),將它歸還給對(duì)象池,供其他對(duì)象使用。這樣做的好處在于減少了內(nèi)存分配和釋放的次數(shù),從而減少了內(nèi)存碎片的產(chǎn)生,并降低了內(nèi)存分配的開(kāi)銷(xiāo)。
在這段代碼中,ObjectPool 類(lèi)的主要功能包括:
- New() 函數(shù):用于分配一個(gè)新的對(duì)象,如果有自由鏈表中有空閑的對(duì)象,則直接從自由鏈表中取出;否則,如果當(dāng)前剩余內(nèi)存塊大小不夠一個(gè)對(duì)象的大小,則重新申請(qǐng)一個(gè)內(nèi)存塊。申請(qǐng)到內(nèi)存后,調(diào)用對(duì)象的構(gòu)造函數(shù)來(lái)進(jìn)行初始化。
- Delete() 函數(shù):用于釋放一個(gè)對(duì)象,調(diào)用對(duì)象的析構(gòu)函數(shù)進(jìn)行清理,然后將其加入自由鏈表中。
在這段代碼中,ObjectPool類(lèi)的成員變量包括:
- _memory:指向當(dāng)前申請(qǐng)的內(nèi)存塊的指針。
- _remainBytes:當(dāng)前內(nèi)存塊剩余的字節(jié)數(shù)。
- _freeList:自由鏈表的頭指針,用于保存當(dāng)前有哪些對(duì)象可以被重復(fù)利用。
在這段代碼中,還有一個(gè)函數(shù) SystemAlloc(),這是為了避免使用malloc而使用的,它的作用是申請(qǐng)一個(gè)新的內(nèi)存塊。如果申請(qǐng)失敗,則拋出 std::bad_alloc 異常。
總的來(lái)說(shuō),這段代碼實(shí)現(xiàn)了一個(gè)簡(jiǎn)單的對(duì)象池,可以有效地管理類(lèi)型為 T 的對(duì)象的內(nèi)存分配和釋放,從而減少了內(nèi)存碎片的產(chǎn)生,并降低了內(nèi)存分配的開(kāi)銷(xiāo)。
class ObjectPool
{
public:
T* New()
{
T* obj = nullptr;
// 如果自由鏈表非空,以“頭刪”的方式從自由鏈表取走內(nèi)存塊,重復(fù)利用
if (_freeList)
{
// 技巧:(void**)強(qiáng)轉(zhuǎn)方便32位下獲取前4字節(jié),64位下獲取前8字節(jié)
void* next = *((void**)_freeList);
obj = (T*)_freeList;
_freeList = next;
}
else
{
// 剩余內(nèi)存_remainBytes不夠一個(gè)對(duì)象大小時(shí),重新開(kāi)一塊大空間
if (_remainBytes < sizeof(T))
{
_remainBytes = 128 * 1024;
// 分配了 _remainBytes 個(gè)字節(jié)的空間,即(128 *1024字節(jié),128KB)
// memory = (char*)malloc(_remainBytes);
// >>13 其實(shí)就是一頁(yè)8KB的大小,可以得到具體多少頁(yè)
_memory = (char*)SystemAlloc(_remainBytes >> 13);
if (_memory == nullptr)
{
throw std::bad_alloc();
}
}
obj = (T*)_memory;
// 保證一次分配的空間夠存放下當(dāng)前平臺(tái)的指針
size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);
// 大塊內(nèi)存塊往后走,前面objSize大小的內(nèi)存該分配出去了
_memory += objSize;
_remainBytes -= objSize;
}
// 定位new顯式調(diào)用T類(lèi)型構(gòu)造函數(shù):在內(nèi)存地址obj處創(chuàng)建一個(gè)新的T類(lèi)型的對(duì)象,并調(diào)用該對(duì)象的構(gòu)造函數(shù)。
// 與普通的new運(yùn)算符不同的是,它不會(huì)使用動(dòng)態(tài)內(nèi)存分配器來(lái)分配內(nèi)存,而是使用指定的內(nèi)存地址。
new(obj)T;
return obj;
}
//將obj這塊內(nèi)存鏈接到_freeList中
void Delete(T* obj)
{
//顯式調(diào)用obj對(duì)象的析構(gòu)函數(shù),清理空間
obj->~T();
//將obj內(nèi)存塊頭插
*(void**)obj = _freeList;
_freeList = obj;
}
private:
char* _memory = nullptr; // 指向大塊內(nèi)存的指針
size_t _remainBytes = 0; // 大塊內(nèi)存在切分過(guò)程中的剩余字節(jié)數(shù)
void* _freeList = nullptr; // 自由鏈表的頭指針,用于保存當(dāng)前有哪些對(duì)象可以被重復(fù)利用。
};
對(duì)于我們?cè)O(shè)計(jì)的定長(zhǎng)內(nèi)存池,可以通過(guò)下面的測(cè)試代碼來(lái)比較一下malloc與定長(zhǎng)內(nèi)存池的效率:
{
int _val;
TreeNode* _left;
TreeNode* _right;
TreeNode():_val(0), _left(NULL),_right(NULL){}
TreeNode(int x) : _val(x), _left(nullptr), _right(nullptr) {}
};
void TestObjectPool()
{
// 申請(qǐng)釋放的輪次
const size_t Rounds = 5;
// 每輪申請(qǐng)釋放多少次
const size_t N = 1000000;
size_t begin1 = clock();
std::vector v1;
v1.reserve(N);
for (size_t j = 0; j < Rounds; ++j)
{
for (int i = 0; i < N; ++i)
{
v1.push_back(new TreeNode);
}
for (int i = 0; i < N; ++i)
{
delete v1[i];
}
v1.clear();
}
size_t end1 = clock();
ObjectPool TNPool;
size_t begin2 = clock();
std::vector v2;
v2.reserve(N);
for (size_t j = 0; j < Rounds; ++j)
{
for (int i = 0; i < N; ++i)
{
v2.push_back(TNPool.New());
}
for (int i = 0; i < 100000; ++i)
{
TNPool.Delete(v2[i]);
}
v2.clear();
}
size_t end2 = clock();
cout << "new cost time:" << end1 - begin1 << endl;
cout << "object pool cost time:" << end2 - begin2 << endl;
}*>*>
可以明顯的看出,定長(zhǎng)內(nèi)存池的開(kāi)銷(xiāo)是要低于malloc的,由此可見(jiàn),在特定場(chǎng)景下,定長(zhǎng)內(nèi)存池的效率高于malloc函數(shù)。
第二階段–高并發(fā)內(nèi)存池整體框架設(shè)計(jì)
現(xiàn)代開(kāi)發(fā)環(huán)境大多都是多核多線程,那么在申請(qǐng)內(nèi)存的場(chǎng)景下,必然存在激烈的鎖競(jìng)爭(zhēng)問(wèn)題。其實(shí),malloc本身就已經(jīng)足夠優(yōu)秀了,但本項(xiàng)目的原型tcmalloc將在多線程高并發(fā)的場(chǎng)景下更勝一籌。
而本項(xiàng)目實(shí)現(xiàn)的內(nèi)存池將考慮以下幾方面的問(wèn)題:
- 1.性能問(wèn)題
- 2.多線程場(chǎng)景下的鎖競(jìng)爭(zhēng)問(wèn)題
- 3.內(nèi)存碎片問(wèn)題
concurrent memory pool(并發(fā)內(nèi)存池),主要有以下3個(gè)部分組成:
1.線程緩存(thread cache)
線程緩存是每個(gè)線程獨(dú)有的,用于小于256kb內(nèi)存的分配。那么對(duì)于每一個(gè)線程從thread cache申請(qǐng)資源,就無(wú)需考慮加鎖問(wèn)題,每個(gè)線程獨(dú)享一個(gè)緩存(cache),這也是并發(fā)線程池高效的地方。
2.中心緩存(central cache)
中心緩存有所有線程所共享,thread cache 按需從central cache處獲取對(duì)象,而central cache在合適的時(shí)機(jī)從thread cache處回收對(duì)象從而避免一個(gè)線程占用太多資源,導(dǎo)致其他線程資源吃緊,進(jìn)而實(shí)現(xiàn)內(nèi)存分配在多個(gè)線程更加均衡的按需調(diào)度。由于所有thread cache都從一個(gè)central cache中取內(nèi)存對(duì)象,故central cache是存在競(jìng)爭(zhēng)的,也就是說(shuō)從central cache中取內(nèi)存對(duì)象需要加鎖,但我們?cè)赾entral cache這里用的是桶鎖,且只有thread cache中沒(méi)有對(duì)象后才會(huì)來(lái)central cache處取對(duì)象,因此鎖的競(jìng)爭(zhēng)不會(huì)很激烈。
3.頁(yè)緩存(page cache)
頁(yè)緩存是中心緩存上一級(jí)的緩存,存儲(chǔ)并分配以頁(yè)為單位的內(nèi)存,central cache中沒(méi)有內(nèi)存對(duì)象時(shí),會(huì)從page cache中分配出一定數(shù)量的page,并切割成定長(zhǎng)大小的小塊內(nèi)存,給central cache。當(dāng)page cache中一個(gè)span的幾個(gè)跨度頁(yè)都回收以后,page cache會(huì)回收central cache中滿足條件的span對(duì)象,并且合并相鄰的頁(yè),組成更大的頁(yè),從而緩解內(nèi)存碎片(外碎片)的問(wèn)題。

第三階段–三級(jí)緩存的具體實(shí)現(xiàn)
1.Thread Cache框架構(gòu)建及核心實(shí)現(xiàn)
thread cache是哈希桶結(jié)構(gòu),每個(gè)桶是一個(gè)根據(jù)桶位置映射的掛接內(nèi)存塊的自由鏈表,每個(gè)線程都會(huì)有一個(gè)thread cache對(duì)象,這樣就可以保證線程在申請(qǐng)和釋放對(duì)象時(shí)是無(wú)鎖訪問(wèn)的。

申請(qǐng)與釋放內(nèi)存的規(guī)則及無(wú)鎖訪問(wèn)
申請(qǐng)內(nèi)存
- 當(dāng)內(nèi)存申請(qǐng)大小size不超過(guò)256KB,則先獲取到線程本地存儲(chǔ)的thread cache對(duì)象,計(jì)算size映射的哈希桶自由鏈表下標(biāo)i。
- 如果自由鏈表_freeLists[i]中有對(duì)象,則直接Pop一個(gè)內(nèi)存對(duì)象返回。
- 如果_freeLists[i]中沒(méi)有對(duì)象時(shí),則批量從central cache中獲取一定數(shù)量的對(duì)象,插入到自由鏈表并返回一個(gè)對(duì)象。
釋放內(nèi)存
1.當(dāng)釋放內(nèi)存小于256kb時(shí)將內(nèi)存釋放回thread cache,計(jì)算size映射自由鏈表桶位置i,將對(duì)象Push到_freeLists[i]。
2.當(dāng)鏈表的長(zhǎng)度過(guò)長(zhǎng),則回收一部分內(nèi)存對(duì)象到central cache。
tls - thread local storage
線程局部存儲(chǔ)(tls),是一種變量的存儲(chǔ)方法,這個(gè)變量在它所在的線程內(nèi)是全局可訪問(wèn)的,但是不能被其他線程訪問(wèn)到,這樣就保持了數(shù)據(jù)的線程獨(dú)立性。而熟知的全局變量,是所有線程都可以訪問(wèn)的,這樣就不可避免需要鎖來(lái)控制,增加了控制成本和代碼復(fù)雜度。
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
管理內(nèi)存對(duì)齊和映射等關(guān)系
計(jì)算對(duì)齊大小映射的規(guī)則
thread cache中的哈希桶映射比例比非均勻的,如果將內(nèi)存大小均勻劃分的話,則會(huì)劃分出大量的哈希桶,比如256kb如果按照8byte劃分,則會(huì)創(chuàng)建32768個(gè)哈希桶,這就有較大的內(nèi)存開(kāi)銷(xiāo);而如果按照更大的字節(jié)劃分,那么內(nèi)存開(kāi)銷(xiāo)雖然減少了,但照顧到的場(chǎng)景也少了,且會(huì)產(chǎn)生內(nèi)碎片問(wèn)題。
那么參考tcmalloc項(xiàng)目,為了保證內(nèi)碎片的浪費(fèi)整體控制在10%左右進(jìn)行的區(qū)間映射,同時(shí)沒(méi)有那么大的開(kāi)銷(xiāo)。使用RoundUp 函數(shù)的將輸入的 size 對(duì)齊到一個(gè)固定的對(duì)齊值。對(duì)齊值是根據(jù) size 的大小而定的,它分成了五個(gè)區(qū)間:
- 如果 size 位于 [1,128] 之間,那么 size 將被對(duì)齊到 8 字節(jié)。
- 如果 size 位于 [128+1,1024] 之間,那么 size 將被對(duì)齊到 16 字節(jié)。
- 如果 size 位于 [1024+1,8*1024] 之間,那么 size 將被對(duì)齊到 128 字節(jié)。
- 如果 size 位于 [81024+1,641024] 之間,那么 size 將被對(duì)齊到 1024 字節(jié)。
- 如果 size 位于 [641024+1,2561024] 之間,那么 size 將被對(duì)齊到 8192 字節(jié)。
這個(gè)函數(shù)內(nèi)部使用了另外一個(gè)靜態(tài)函數(shù)_RoundUp來(lái)實(shí)際計(jì)算對(duì)齊后的值。
也就是說(shuō),對(duì)于1byte到128byte的內(nèi)存對(duì)象,按照8byte對(duì)齊,劃分為下標(biāo)0-15號(hào)的哈希桶,而129byte到1kb的內(nèi)存對(duì)象,按照16byte對(duì)齊,劃分下標(biāo)16-71號(hào)的哈希桶,以此類(lèi)推,最終劃分為0-207號(hào)總共208個(gè)哈希桶,這樣就保證了內(nèi)存較小的開(kāi)銷(xiāo),同時(shí)各個(gè)對(duì)齊關(guān)系中內(nèi)碎片浪費(fèi)控制在10%左右,比如129byte到144byte區(qū)間,取144byte的內(nèi)存對(duì)象,浪費(fèi)率為(144 - 129) / 144 = 10.42%,當(dāng)然對(duì)于最開(kāi)始的1byte申請(qǐng)8byte內(nèi)存對(duì)象,雖然浪費(fèi)高達(dá)87.5%,但考慮到最終內(nèi)碎片浪費(fèi)了7byte,對(duì)比后續(xù)內(nèi)碎片一次浪費(fèi)7kb來(lái)說(shuō)可以忽略不計(jì)了。
這便是申請(qǐng)的內(nèi)存對(duì)象大小對(duì)齊的映射關(guān)系,這個(gè)關(guān)系在后續(xù)central cache及page cache中仍有應(yīng)用,因此可以將其定義在頭文件common.h中,以后內(nèi)存大小對(duì)齊的管理。
計(jì)算相應(yīng)內(nèi)存映射在哪一個(gè)哈希桶中
這里使用Index 函數(shù)計(jì)算將輸入的 size 映射到哪個(gè)自由鏈表桶(freelist)。和RoundUp函數(shù)一樣,這個(gè)函數(shù)也根據(jù)size的大小將它分成了五個(gè)區(qū)間,但是它返回的是一個(gè)數(shù)組下標(biāo)。數(shù)組的大小和每個(gè)區(qū)間內(nèi)的自由鏈表桶數(shù)量是固定的。
這個(gè)函數(shù)內(nèi)部使用了另一個(gè)靜態(tài)函數(shù)_Index來(lái)計(jì)算桶的下標(biāo)。在代碼中,size表示要被對(duì)齊的內(nèi)存塊的大小,alignNum表示對(duì)齊的值,align_shift表示對(duì)齊的值的二進(jìn)制位數(shù)。
關(guān)于 _RoundUp和 _Index:
對(duì)于 _RoundUp 函數(shù),它使用位運(yùn)算將 size 對(duì)齊到最接近它的大于等于它的 alignNum 的倍數(shù)。這里有一個(gè)簡(jiǎn)單的例子:假設(shè)我們有一個(gè)值 size=11,我們想將它對(duì)齊到 alignNum=8 的倍數(shù)。那么 _RoundUp 函數(shù)會(huì)返回 16,因?yàn)?16 是最接近 11 且大于等于 11 的 alignNum 的倍數(shù)。
對(duì)于 _Index 函數(shù),它計(jì)算的是將 size 映射到桶鏈的下標(biāo)。它的計(jì)算方法是將 size 向上對(duì)齊到最接近它的大于等于它的 2^align_shift 的倍數(shù),然后再減去 1。這個(gè)函數(shù)的作用和 _RoundUp 函數(shù)類(lèi)似,但是它返回的是下標(biāo)而不是對(duì)齊后的值。
size_t _RoundUp(size_t size, size_t alignNum)
{
size_t alignSize;
if (size % alignNum != 0)
{
alignSize = (size / alignNum + 1) * alignNum;
}
else
{
alignSize = size;
}
return alignSize;
}
//計(jì)算對(duì)應(yīng)鏈桶的下標(biāo)
static inline size_t _Index(size_t bytes, size_t alignNum)
{
if (bytes % alignNum == 0)
{
return bytes / alignNum - 1;
}
else
{
return bytes / alignNum;
}
}
但是參考tcmalloc源碼,考慮到位移運(yùn)算更加接近底層,效率更高,而實(shí)際應(yīng)用中映射對(duì)應(yīng)關(guān)系的計(jì)算是相當(dāng)頻繁的,因此使用位運(yùn)算來(lái)改進(jìn)算法。
{
return ((bytes + alignNum - 1) & ~(alignNum - 1));
}
static inline size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}
代碼實(shí)現(xiàn)
class SizeClass
{
public:
// 整體控制在最多10%左右的內(nèi)碎片浪費(fèi)
// [1,128] 8byte對(duì)齊 freelist[0,16)
// [128+1,1024] 16byte對(duì)齊 freelist[16,72)
// [1024+1,8*1024] 128byte對(duì)齊 freelist[72,128)
// [8*1024+1,64*1024] 1024byte對(duì)齊 freelist[128,184)
// [64*1024+1,256*1024] 8*1024byte對(duì)齊 freelist[184,208)
// 使用位運(yùn)算將 size 對(duì)齊到最接近它的大于等于它的 alignNum 的倍數(shù)
// 比如size = 11對(duì)齊到16
static inline size_t _RoundUp(size_t bytes, size_t alignNum)
{
return ((bytes + alignNum - 1) & ~(alignNum - 1));
}
static inline size_t RoundUp(size_t size)
{
if (size <= 128)
{
return _RoundUp(size, 8);
}
else if (size <= 1024)
{
return _RoundUp(size, 16);
}
else if (size <= 8 * 1024)
{
return _RoundUp(size, 128);
}
else if (size <= 64 * 1024)
{
return _RoundUp(size, 1024);
}
else if (size <= 256 * 1024)
{
return _RoundUp(size, 8 * 1024);
}
else
{
assert(false);
return -1;
}
}
// 將 size 映射到桶鏈的下標(biāo):
// 這個(gè)函數(shù)的作用和 _RoundUp 函數(shù)類(lèi)似,但是它返回的是下標(biāo)而不是對(duì)齊后的值。
// 比如size = 11映射下標(biāo)到(2 - 1 = 1)
static inline size_t _Index(size_t bytes, size_t align_shift)
{
return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;
}
// 計(jì)算映射的哪一個(gè)自由鏈表桶
static inline size_t Index(size_t bytes)
{
assert(bytes <= MAX_BYTES);
// 每個(gè)區(qū)間有多少個(gè)鏈
static int group_array[4] = { 16, 56, 56, 56 };// 打表
if (bytes <= 128)
{
return _Index(bytes, 3);
}
else if (bytes <= 1024)
{
return _Index(bytes - 128, 4) + group_array[0];
}
else if (bytes <= 8 * 1024)
{
return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];
}
else if (bytes <= 64 * 1024)
{
return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];
}
else if (bytes <= 256 * 1024)
{
return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];
}
else
{
assert(false);
}
return -1;
}
// 計(jì)算ThreadCache一次從中心緩存CentralCache獲取多少個(gè)小對(duì)象,總的大小就是MAX_BYTES = 256KB
static size_t NumMoveSize(size_t size)
{
assert(size > 0);
// [2, 512],一次批量移動(dòng)多少個(gè)對(duì)象的(慢啟動(dòng))上限值
// 小對(duì)象一次批量上限高
// 小對(duì)象一次批量上限低
int num = MAX_BYTES / size;
if (num < 2)
num = 2;
if (num > 512)
num = 512;
return num;
}
// 計(jì)算中心緩存CentralCache一次向PageCache獲取多少頁(yè)
// 單個(gè)對(duì)象 8byte
// ...
// 單個(gè)對(duì)象 256KB
static size_t NumMovePage(size_t size)
{
// 計(jì)算一次從中心緩存獲取的對(duì)象個(gè)數(shù)num
size_t num = NumMoveSize(size);
// 單個(gè)對(duì)象大小與對(duì)象個(gè)數(shù)相乘,獲得一次需要向PageCache申請(qǐng)的內(nèi)存大小
size_t npage = num * size;
npage >>= PAGE_SHIFT;
if (npage == 0)
{
npage = 1;
}
return npage;
}
};
NumMoveSize 函數(shù)的作用是計(jì)算一次從中心緩存獲取多少個(gè)對(duì)象。它的計(jì)算方法是首先將單個(gè)對(duì)象大小除以總的緩存大小 MAX_BYTES,得到的結(jié)果即為一次從中心緩存獲取的對(duì)象個(gè)數(shù)。為了避免數(shù)量太少或太多,可以設(shè)置一個(gè)范圍,在 [2, 512] 之間。如果計(jì)算出的對(duì)象數(shù)量不在這個(gè)范圍內(nèi),就取邊界值。
NumMovePage函數(shù)的作用是計(jì)算中心緩存CentralCache一次向PageCache獲取多少頁(yè)。一頁(yè)的大小是由PAGE_SHIFT指定的。本項(xiàng)目中一個(gè)頁(yè)大小是8KB,即2的13次方,所以PAGE_SHIFT = 13。NumMovePage函數(shù)先調(diào)用NumMoveSize函數(shù)計(jì)算出一次從CentralCache獲取多少個(gè)對(duì)象,然后乘上對(duì)象大小,就獲得需要向PageCache申請(qǐng)的內(nèi)存大小,然后除以單個(gè)頁(yè)的大小(左移PAGE_SHIFT)即可獲得向PageCache申請(qǐng)的總頁(yè)數(shù)。
突擊檢查:static inline 函數(shù)和 inline函數(shù)有什么區(qū)別呢?
inline內(nèi)聯(lián)函數(shù):為了減少因函數(shù)調(diào)用而引起的系統(tǒng)開(kāi)銷(xiāo),內(nèi)聯(lián)函數(shù)實(shí)際上是以空間換效率的一種做法。編譯器會(huì)盡量將 inline 函數(shù)的代碼插入到調(diào)用函數(shù)的代碼中,從而減少函數(shù)調(diào)用的開(kāi)銷(xiāo)。inline 函數(shù)的主要優(yōu)點(diǎn)是可以提高程序的執(zhí)行效率,因?yàn)槭∪チ撕瘮?shù)調(diào)用的開(kāi)銷(xiāo)。但是,inline 函數(shù)的缺點(diǎn)是會(huì)降低程序的可讀性,代碼會(huì)變得復(fù)雜。
static inline 函數(shù)是一種特殊的函數(shù),它同時(shí)具有 inline 函數(shù)的優(yōu)點(diǎn)和 static 函數(shù)的優(yōu)點(diǎn)。static 函數(shù)是指在編譯期間就將函數(shù)體內(nèi)的代碼插入到調(diào)用函數(shù)的代碼中,并且只在本文件中可見(jiàn)。static 函數(shù)的主要優(yōu)點(diǎn)是可以隱藏函數(shù)的實(shí)現(xiàn)細(xì)節(jié),只提供接口。所以在頭文件中務(wù)必要加上static inline,否則和普通函數(shù)一樣,當(dāng)多個(gè)CPP文件包含是就會(huì)重復(fù)定義。所以加入static提高代碼健壯性。
因此,static inline 函數(shù)既可以提高程序的執(zhí)行效率,又可以隱藏函數(shù)的實(shí)現(xiàn)細(xì)節(jié),是一種很好的函數(shù)聲明方式。
自由鏈表的設(shè)計(jì)
在有了上面的基礎(chǔ)之后,我們來(lái)設(shè)計(jì)自由鏈表,其實(shí)就是實(shí)現(xiàn)一個(gè)單鏈表,方便插入刪除,同時(shí)標(biāo)識(shí)鏈表長(zhǎng)度 _size以方便后續(xù)釋放流程,以及定義 _maxSize來(lái)保住thread cache一次申請(qǐng)對(duì)象批次的下限。
static void*& NextObj(void* obj)
{
return *(void**)obj;
}
class FreeList
{
public:
void Push(void* obj)
{
// 將歸還的內(nèi)存塊對(duì)象頭插進(jìn)自由鏈表
NextObj(obj) = _freeList;
_freeList = obj;
++_size;
}
void PushRange(void* start, void* end, size_t size)
{
NextObj(end) = _freeList;
_freeList = start;
_size += size;
}
void* Pop()
{
assert(_freeList);
//將自由鏈表中的內(nèi)存塊頭刪出去
void* obj = _freeList;
_freeList = NextObj(obj);
--_size;
return obj;
}
void PopRange(void*& start, void*& end, size_t n)
{
assert(n >= _size);
start = _freeList;
end = start;
for (size_t i = 0; i < n - 1; i++)
{
end = NextObj(end);
}
_freeList = NextObj(end);
_size -= n;
NextObj(end) = nullptr;
}
bool Empty()
{
return _freeList == nullptr;
}
size_t& MaxSize()// 傳引用
{
return _maxSize;
}
size_t& Size()
{
return _size;
}
private:
void* _freeList = nullptr;
size_t _maxSize = 1;//慢增長(zhǎng)用于保住申請(qǐng)批次下限
size_t _size = 0;//計(jì)算鏈表長(zhǎng)度
};
thread cache框架構(gòu)建
在有了上述基礎(chǔ)后,我們來(lái)搭建thread cache的框架,其實(shí)就是一個(gè)哈希桶,每個(gè)桶中掛接著自由鏈表對(duì)象。
_declspec(thread)是一個(gè)Windows平臺(tái)專(zhuān)用的關(guān)鍵字,用于聲明線程局部存儲(chǔ)(TLS)變量。在這里,它聲明了一個(gè)指向ThreadCache對(duì)象的指針變量pTLSThreadCache,該變量的值對(duì)于每個(gè)線程來(lái)說(shuō)都是獨(dú)立的,可以使線程在向thread cache申請(qǐng)內(nèi)存對(duì)象的時(shí)候?qū)崿F(xiàn)無(wú)鎖訪問(wèn)。
{
public:
// 申請(qǐng)和釋放內(nèi)存對(duì)象
void* Allocate(size_t size);
void Deallocate(void* ptr, size_t size);
// 從中心緩存獲取對(duì)象
void* FetchFromCentralCache(size_t index, size_t size);
// 釋放內(nèi)存時(shí),如果自由鏈表過(guò)長(zhǎng),回收內(nèi)存到CentralCache中心緩存
void ListTooLong(FreeList& list, size_t size);
private:
// 哈希桶,每個(gè)桶中掛接著自由鏈表對(duì)象
FreeList _freeLists[NFREELIST];
};
// pTLSThreadCache是一個(gè)指向ThreadCache對(duì)象的指針,每個(gè)線程都有一個(gè)獨(dú)立的pTLSThreadCache
// 可以使線程在向thread cache申請(qǐng)內(nèi)存對(duì)象的時(shí)候?qū)崿F(xiàn)無(wú)鎖訪問(wèn)
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
thread cache核心實(shí)現(xiàn)
1.FetchFromCentralCache(size_t index, size_t size)
從中央緩存(CentralCache)獲取內(nèi)存塊。接受兩個(gè)參數(shù):ThreadCache自由鏈表對(duì)應(yīng)的桶索引和想獲取的內(nèi)存塊大小。
{
// 慢開(kāi)始反饋調(diào)節(jié)算法
// 1、最開(kāi)始不會(huì)一次向central cache一次批量要太多,因?yàn)橐嗔丝赡苡貌煌?br /> // 2、如果你不要這個(gè)size大小內(nèi)存需求,那么batchNum就會(huì)不斷增長(zhǎng),直到上限
// 3、size越大,一次向central cache要的batchNum就越小
// 4、size越小,一次向central cache要的batchNum就越大
size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));
if (_freeLists[index].MaxSize() == batchNum)
{
_freeLists[index].MaxSize() += 1;
}
void* start = nullptr;
void* end = nullptr;
size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);
// 至少要獲得一塊
assert(actualNum > 0);
if (actualNum == 1)// 只有一個(gè)內(nèi)存塊
{
assert(start == end);
return start;
}
else// 除了起始地址外的其他內(nèi)存塊插入當(dāng)前線程的緩存的自由鏈表中
{
_freeLists[index].PushRange(NextObj(start), end, actualNum - 1);
return start;
}
}
2.Allocate(size_t size)
線程內(nèi)分配內(nèi)存
{
assert(size <= MAX_BYTES);
// 計(jì)算出內(nèi)存塊的對(duì)齊大小 alignSize 和內(nèi)存塊所在的自由鏈表的下標(biāo) index
size_t alignSize = SizeClass::RoundUp(size);
size_t index = SizeClass::Index(size);
// _freeLists[index] 如果不為空,就從 _freeLists[index] 中彈出一個(gè)內(nèi)存塊并返回。
if (!_freeLists[index].Empty())
{
return _freeLists[index].Pop();
}
// 如果為空,就調(diào)用 FetchFromCentralCache 函數(shù)從中央緩存獲取內(nèi)存塊;
else
{
FetchFromCentralCache(index, alignSize);
}
}
3.Deallocate(void* ptr, size_t size)
線程內(nèi)回收內(nèi)存,傳入內(nèi)存塊的指針: ptr 和內(nèi)存塊的大小: size
{
assert(ptr);
assert(size <= MAX_BYTES);
// 計(jì)算出映射的自由鏈表桶index,并將 ptr 插入到 _freeLists[index] 中
size_t index = SizeClass::Index(size);
_freeLists[index].Push(ptr);
// 當(dāng)鏈表長(zhǎng)度大于一次批量申請(qǐng)的內(nèi)存時(shí),就開(kāi)始還一段list給CentralCache
if (_freeLists[index].Size() >= _freeLists[index].MaxSize())
{
ListTooLong(_freeLists[index], size);
}
}
4.ListTooLong(FreeList& list, size_t size)
處理線程內(nèi)過(guò)長(zhǎng)自由鏈表,還一部分給中心緩存的span
{
void* start = nullptr;
void* end = nullptr;
// MaxSize就是歸還的list的長(zhǎng)度,自由鏈表結(jié)點(diǎn)個(gè)數(shù)
list.PopRange(start, end, list.MaxSize());
CentralCache::GetInstance()->ReleaseListToSpans(start, size);
}
2.central cache框架構(gòu)建及核心實(shí)現(xiàn)
central cache也是一個(gè)哈希表結(jié)構(gòu),其映射關(guān)系與thread cache是一樣的,不同的是central cache的哈希桶位置所掛接的是SpanList鏈表結(jié)構(gòu),不過(guò)每個(gè)桶下的span對(duì)象被切分成了一塊塊小內(nèi)存掛接在span對(duì)象的自由鏈表freeList中。
圖稍微有點(diǎn)不對(duì),sapn鏈?zhǔn)菐ь^雙向循環(huán)鏈表,最后不該指向NULL,應(yīng)該指向頭。
申請(qǐng)與釋放內(nèi)存規(guī)則
申請(qǐng)內(nèi)存
1.當(dāng)thread cache中沒(méi)有內(nèi)存后,就會(huì)向central cache中申請(qǐng)大塊內(nèi)存。這里的申請(qǐng)過(guò)程采用的是類(lèi)似網(wǎng)絡(luò)tcp協(xié)議擁塞控制的慢開(kāi)始算法,而central cache中哈希映射的spanlist下掛著的span則向thread cache提供大塊內(nèi)存,而從span中取出對(duì)象給thread cache是需要加鎖的,這里為了保證效率,提供的是桶鎖。
慢開(kāi)始算法
線程緩存從中央緩存獲取內(nèi)存塊的數(shù)量是按照“慢開(kāi)始反饋調(diào)節(jié)算法”遞增的:
1、最開(kāi)始不會(huì)一次向central cache一次批量要太多,因?yàn)橐嗔丝赡苡貌煌?/p>
2、如果你不要這個(gè)size大小內(nèi)存需求,那么batchNum就會(huì)不斷增長(zhǎng),直到上限
3、size越大,一次向central cache要的batchNum就越小
4、size越小,一次向central cache要的batchNum就越大
size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));
if (_freeLists[index].MaxSize() == batchNum)
_freeLists[index].MaxSize() += 1;
舉個(gè)例子,線程申請(qǐng)7塊大小相同的內(nèi)存,第一次申請(qǐng)的批次數(shù)量為1塊,第二次再來(lái)申請(qǐng)時(shí),此時(shí)thread cache的自由鏈表下已經(jīng)沒(méi)有空閑的內(nèi)存了,則又需要繼續(xù)向central cache申請(qǐng)內(nèi)存,申請(qǐng)的批次數(shù)量為2塊,第3次直接從thread cache的自由鏈表中獲取內(nèi)存塊;第4次再申請(qǐng)時(shí),則需要向central cache申請(qǐng)內(nèi)存,此時(shí)申請(qǐng)的批次數(shù)量為3塊,掛接在thread cache的自由鏈表下,直到第7次來(lái)申請(qǐng)內(nèi)存時(shí),向central cache申請(qǐng)的內(nèi)存批次數(shù)量為4,這時(shí)線程取走一塊內(nèi)存,則掛接在thread cache的自由鏈表下還有3塊空閑的內(nèi)存。
2.當(dāng)central cache中映射的spanlist下所掛接的所有span對(duì)象都沒(méi)有內(nèi)存后,則需要向page cache申請(qǐng)一塊新的span對(duì)象,central cache拿到這塊span對(duì)象后會(huì)按照所管理內(nèi)存的大小將span對(duì)象劃分成多塊,再掛接到central cache的審判l(wèi)ist中;然后再?gòu)倪@塊新申請(qǐng)的span對(duì)象中去內(nèi)存分配給thread cache。
3.在這里,為了方便后續(xù)的回收,span對(duì)象每分配出一塊內(nèi)存,其成員變量_useCount就++;相反thread cache每釋放歸還一塊內(nèi)存后,_useCount就–。
釋放內(nèi)存
當(dāng)thread_cache過(guò)長(zhǎng)或者線程銷(xiāo)毀,則會(huì)將內(nèi)存釋放回central cache中的,釋放回來(lái)時(shí)–_useCount。當(dāng)_useCount變?yōu)?后,說(shuō)明所有分配出去的內(nèi)存都?xì)w還回來(lái)了,那么就將這個(gè)span對(duì)象歸還給page cache,page cache會(huì)對(duì)歸還回來(lái)的span進(jìn)行前后頁(yè)合并。
管理多個(gè)大塊內(nèi)存的跨度結(jié)構(gòu)Span及SpanList定義
在上面我們知道central cache的哈希桶下掛接著的是跨度結(jié)構(gòu)Span對(duì)象,其實(shí)Span對(duì)象是管理以頁(yè)為單位的大塊內(nèi)存的結(jié)構(gòu)體。而為了方便后續(xù)回收span對(duì)象到page cache,需要將任意位置span對(duì)象從spanlist中刪除,那么將spanlist定義為一個(gè)雙向鏈表更好一些。
由此,span及spanlist的定義如下:
struct Span
{
PAGE_ID _pageId = 0; // 大塊內(nèi)存起始頁(yè)的頁(yè)號(hào)
size_t _n = 0; // 頁(yè)的數(shù)量
Span* _next = nullptr; // 指向下一個(gè)內(nèi)存塊的指針
Span* _prev = nullptr; // 指向上一個(gè)內(nèi)存塊的指針
size_t _objSize = 0; // 切好的小對(duì)象大小
size_t _useCount = 0; // 已分配給ThreadCache的小塊內(nèi)存的數(shù)量
void* _freeList = nullptr; // 已分配給ThreadCache的小塊內(nèi)存的自由鏈表
bool _isUse = false; // 標(biāo)記當(dāng)前span內(nèi)存跨度是否在被使用
};
// 帶頭雙向循環(huán)鏈表
class SpanList
{
public:
// 構(gòu)造函數(shù),創(chuàng)建帶頭雙向循環(huán)鏈表
SpanList()
{
_head = new Span;
_head->_next = _head;
_head->_prev = _head;
}
Span* Begin()
{
return _head->_next;
}
Span* End()
{
return _head;
}
bool Empty()
{
return _head->_next == _head;
}
// 頭插
void PushFront(Span* span)
{
Insert(Begin(), span);
}
// 頭刪,并返回刪除的結(jié)點(diǎn)指針
Span* PopFront()
{
Span* front = _head->_next;
Erase(front);
return front;
}
// 在鏈表的指定位置插入新的內(nèi)存塊
void Insert(Span* pos, Span* newSpan)
{
assert(pos);
assert(newSpan);
Span* prev = pos->_prev;
prev->_next = newSpan;
newSpan->_next = pos;
newSpan->_prev = prev;
pos->_prev = newSpan;
}
// 從鏈表中刪除指定的內(nèi)存塊
void Erase(Span* pos)
{
assert(pos);
// 不能指向鏈表的頭,這是帶頭雙向循環(huán)鏈表,頭結(jié)點(diǎn)的意義就如同“刷題”里的啞結(jié)點(diǎn),是虛擬的,只是為了操作方便。
assert(pos != _head);
Span* prev = pos->_prev;
Span* next = pos->_next;
prev->_next = next;
next->_prev = prev;
}
private:
Span* _head;// 鏈表的頭指針
public:
std::mutex _mtx;// 桶鎖
};
central cache框架構(gòu)建
在明確了span與spanlist的定義描述后,也不能設(shè)計(jì)出central cache的框架結(jié)構(gòu),central cache是一個(gè)哈希表結(jié)構(gòu),其映射的是spanlist與哈希桶位置(內(nèi)存大小)的關(guān)系。
其次,在這里我們將central cache設(shè)計(jì)為餓漢式單例模式,類(lèi)的唯一實(shí)例在程序啟動(dòng)時(shí)就已經(jīng)被創(chuàng)建出來(lái),并且在整個(gè)程序的生命周期內(nèi)都只有這一個(gè)實(shí)例。餓漢式優(yōu)點(diǎn)是線程安全,因?yàn)閷?shí)例在程序啟動(dòng)時(shí)就已經(jīng)被創(chuàng)建,在整個(gè)程序的生命周期內(nèi)都只有這一個(gè)實(shí)例,不會(huì)存在多線程競(jìng)爭(zhēng)的情況。
{
public:
// 單例模式的定義,作用:獲取唯一實(shí)例的靜態(tài)方法
static CentralCache* GetInstance()
{
// &_sInst 返回 _sInst 對(duì)象的地址,因?yàn)?_sInst 是一個(gè)靜態(tài)變量
// 所以它的地址是固定的,其他代碼也可以通過(guò)該地址訪問(wèn) _sInst 對(duì)象
return &_sInst;
}
// 獲取一個(gè)非空的span
Span* GetOneSpan(SpanList& list, size_t byte_size);
// 從中心緩存獲取一定數(shù)量的對(duì)象給ThreadCache線程緩存
size_t FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size);
// 將一定數(shù)量的對(duì)象釋放到中心緩存的span跨度
void ReleaseListToSpans(void* start, size_t byte_size);
private:
SpanList _spanLists[NFREELIST];
private:
// 構(gòu)造函數(shù)和一個(gè)拷貝構(gòu)造函數(shù)私有化
CentralCache()
{}
CentralCache(const CentralCache&) = delete;
// 定義一個(gè)靜態(tài)的變量 _sInst,該變量保存著 CentralCache 類(lèi)的唯一實(shí)例
static CentralCache _sInst;
};
central cache核心實(shí)現(xiàn)
1.GetOneSpan(SpanList& list, size_t size)
從中心緩存獲取一個(gè)空閑的Span對(duì)象,如果當(dāng)前中心緩存的對(duì)應(yīng)大小類(lèi)別的桶中沒(méi)有空閑的Span對(duì)象,則會(huì)從頁(yè)緩存中獲取一個(gè)新的Span對(duì)象并將其添加到中心緩存的桶中。
{
// 查看當(dāng)前的spanlist中是否有還有未分配對(duì)象的span
Span* it = list.Begin();
while (it != list.End())
{
if (it->_freeList != nullptr)
{
return it;
}
else
{
it = it->_next;
}
}
// 先把central cache的桶鎖解掉,這樣如果其他線程釋放內(nèi)存對(duì)象回來(lái),不會(huì)阻塞
list._mtx.unlock();
// 走到這里說(shuō)沒(méi)有空閑span了,只能找page cache要
PageCache::GetInstance()->_pageMtx.lock();
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
span->_isUse = true;
span->_objSize = size;
PageCache::GetInstance()->_pageMtx.unlock();
// 對(duì)獲取span進(jìn)行切分,不需要加鎖,因?yàn)檫@時(shí)候這個(gè)span是當(dāng)前進(jìn)程單例創(chuàng)建的,其他線程訪問(wèn)不到這個(gè)span
// 計(jì)算span的大塊內(nèi)存的起始地址和大塊內(nèi)存的大小(字節(jié)數(shù))
char* start = (char*)(span->_pageId << PAGE_SHIFT);
size_t bytes = span->_n << PAGE_SHIFT;
char* end = start + bytes;
// 把大塊內(nèi)存切成自由鏈表鏈接起來(lái)
// 先切一塊下來(lái)去做頭,方便尾插
span->_freeList = start;
start += size;
void* tail = span->_freeList;
int i = 1;
while (start < end)
{
i++;
NextObj(tail) = start;
tail = NextObj(tail);
start += size;
}
NextObj(tail) = nullptr; // 記得置空
// 切好span以后,需要把span掛到中心緩存對(duì)應(yīng)的哈希桶里面去的時(shí)候,再加鎖
list._mtx.lock();
list.PushFront(span);
return span;
}
2.FetchRangeObj(void*& start, void*& end, size_t batchNum, size_t size)
從中心緩存獲取一定數(shù)量的對(duì)象給thread cache
值得注意void *& start 和 void *& end 都是傳址的形式傳入的參數(shù),也就是所謂的輸入輸出型參數(shù)
void *& start:輸出參數(shù),返回獲取到的內(nèi)存塊的起始地址。
void *& end:輸出參數(shù),返回獲取到的內(nèi)存塊的結(jié)束地址。
size_t batchNum:輸入?yún)?shù),指定從中心緩存獲取的內(nèi)存塊的數(shù)量。
size_t size:輸入?yún)?shù),指定要獲取的內(nèi)存塊的大小
{
// 中央緩存CentralCache哈希桶的映射規(guī)則和線程緩存ThreadCache哈希桶映射規(guī)則一樣
size_t index = SizeClass::Index(size);
_spanLists[index]._mtx.lock();
Span* span = GetOneSpan(_spanLists[index], size);
assert(span);// 檢查獲取的span是否為空
assert(span->_freeList);// 檢查獲取的span的自由鏈表是否為空
// 從span中獲取batchNum個(gè)對(duì)象
// 如果不夠batchNum個(gè),有多少拿多少
start = span->_freeList;
end = start;
size_t i = 0;
size_t actualNum = 1;
while (i < batchNum - 1 && NextObj(end) != nullptr)
{
end = NextObj(end);
i++;
actualNum++;
}
span->_freeList = NextObj(end);// span的[start, end]被取走了
NextObj(end) = nullptr;// 置空
span->_useCount += actualNum;
// 調(diào)試:條件斷點(diǎn)
int j = 0;
void* cur = start;
while (cur)
{
cur = NextObj(cur);
++j;
}
if (j != actualNum)
{
int x = 0;
}
_spanLists[index]._mtx.unlock();
return actualNum;
}
3.ReleaseListToSpans(void* start, size_t size)
將一段線程緩存的自由鏈表還給中心緩存的span。
{
size_t index = SizeClass::Index(size);
_spanLists[index]._mtx.lock();
while (start)
{
void* next = NextObj(start);
// 把start開(kāi)頭的這一串自由鏈表內(nèi)存還給他屬于的span,一次循環(huán)還一個(gè),一直還
Span* span = PageCache::GetInstance()->MapObjectToSpan(start);
NextObj(start) = span->_freeList;
span->_freeList = start;
span->_useCount--;
// 說(shuō)明span的切分出去的所有小塊內(nèi)存都回來(lái)了,那就清理一下span,然后把完整的span交給page
// 這個(gè)span就可以再回收給page cache,pagecache可以再嘗試去做前后頁(yè)的合并
if (span->_useCount == 0)
{
_spanLists[index].Erase(span);
span->_freeList = nullptr;
span->_next = nullptr;
span->_prev = nullptr;
// 釋放span給page cache時(shí),span已經(jīng)從_spanLists[index]刪除了,不需要再加桶鎖了
// 這時(shí)把桶鎖解掉,使用page cache的鎖就可以了,方便其他線程申請(qǐng)/釋放內(nèi)存
_spanLists[index]._mtx.unlock();
PageCache::GetInstance()->_pageMtx.lock();
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
PageCache::GetInstance()->_pageMtx.unlock();
_spanLists[index]._mtx.lock();
}
start = next;
}
_spanLists[index]._mtx.unlock();
}
3.page cache框架構(gòu)建及核心實(shí)現(xiàn)
page cache與前兩級(jí)緩存略有不同,其映射關(guān)系不再是哈希桶位置與自由鏈表或spanlist的映射,而是頁(yè)號(hào)與spanlist的映射,這里我們?cè)O(shè)計(jì)的是128頁(yè)的page cache。

申請(qǐng)與釋放內(nèi)存
申請(qǐng)內(nèi)存
1.當(dāng)central cache向page cache申請(qǐng)內(nèi)存時(shí),page cache先檢查對(duì)應(yīng)位置有沒(méi)有span,如果沒(méi)有則向更大頁(yè)尋找一個(gè)span,如果找到則分裂成兩個(gè)。比如:申請(qǐng)的是1頁(yè)page,1頁(yè)page后面沒(méi)有掛span,則向后面尋找更大的span,假設(shè)在100頁(yè)page位置找到一個(gè)span,則將100頁(yè)page的span分裂為一個(gè)1頁(yè)page span和一個(gè)99頁(yè)page span。
2.如果找到_spanList[128]都沒(méi)有合適的span,則向系統(tǒng)使用mmap、brk或者是VirtualAlloc等方式申請(qǐng)128頁(yè)page span掛在自由鏈表中,再重復(fù)1中的過(guò)程。
3.需要注意的是central cache和page cache 的核心結(jié)構(gòu)都是spanlist的哈希桶,但是他們是有本質(zhì)區(qū)別的,central cache中哈希桶,是按跟thread cache一樣的大小對(duì)齊關(guān)系映射的,他的spanlist中掛的span中的內(nèi)存都被按映射關(guān)系切好鏈接成小塊內(nèi)存的自由鏈表。而page cache 中的spanlist則是按下標(biāo)桶號(hào)映射的,也就是說(shuō)第i號(hào)桶中掛的span都是i頁(yè)內(nèi)存。
釋放內(nèi)存
如果central cache釋放回一個(gè)span,則依次尋找span的前后page id的沒(méi)有在使用的空閑span,看是否可以合并,如果合并繼續(xù)向前尋找。這樣就可以將切小的內(nèi)存合并收縮成大的span,減少內(nèi)存碎片。
直接向堆申請(qǐng)或釋放以頁(yè)為單位的大塊內(nèi)存
這里我們?yōu)榱吮苊馐褂胢alloc及free函數(shù)接口去向堆申請(qǐng)和釋放內(nèi)存,因此使用系統(tǒng)調(diào)用接口直接向堆申請(qǐng)和釋放內(nèi)存。
這里的系統(tǒng)調(diào)用接口在window下為VirtualAlloc與VirtualFree系統(tǒng)調(diào)用接口;在Linux系統(tǒng)下為mmap與munmap,brk與sbrk兩對(duì)系統(tǒng)調(diào)用接口。
{
#ifdef _WIN32
void* ptr = VirtualAlloc(0, kPage << PAGE_SHIFT, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else
//Linux下brk mmap等
#endif // _WIN32
//拋異常
if (ptr == nullptr)
throw std::bad_alloc();
return ptr;
}
Span跨度結(jié)構(gòu)以頁(yè)為單位管理從堆申請(qǐng)的內(nèi)存
我們向堆申請(qǐng)內(nèi)存后會(huì)返回這塊內(nèi)存的起始地址,那么我們將這個(gè)地址看作一個(gè)無(wú)符號(hào)整型,將其除以8*1024作為Span結(jié)構(gòu)的_pageId,再將申請(qǐng)內(nèi)存時(shí)用的頁(yè)號(hào)賦給 _n,這里為了方便后續(xù)回收分配出去的Span跨度結(jié)構(gòu),我們使用STL的unordered_map來(lái)構(gòu)建 _pageId與Span對(duì)象的映射關(guān)系。
page cache框架構(gòu)建
與central cache類(lèi)似的是,page cache也是單例模式;不過(guò)page cache加的不是桶鎖,而是整級(jí)加的一把大鎖,即每次central cache向page cache申請(qǐng)內(nèi)存時(shí),page cache都要加鎖防止出現(xiàn)安全問(wèn)題。
{
public:
static PageCache* GetInstance()
{
return &_sInst;
}
// 獲取從對(duì)象到span的映射
Span* MapObjectToSpan(void* obj);
// 釋放空閑span回到Pagecache,并合并相鄰的span
void ReleaseSpanToPageCache(Span* span);
// 獲取一個(gè)k頁(yè)的span
Span* NewSpan(size_t k);
std::mutex _pageMtx;
private:
SpanList _spanLists[NPAGES];// PageCache自己的雙鏈表哈希桶,映射方式是按照頁(yè)數(shù)直接映射
ObjectPool _spanPool;
// std::unordered_map _idSpanMap;
TCMalloc_PageMap1<32 - PAGE_SHIFT> _idSpanMap;
PageCache()
{}
PageCache(const PageCache&) = delete;
static PageCache _sInst;
};,>
page cache核心實(shí)現(xiàn)
1.NewSpan(size_t k)
獲取一個(gè)K頁(yè)的span
首先會(huì)檢查第k個(gè)桶里面是否有span,如果有就直接返回;如果沒(méi)有,則檢查后面的桶里面是否有更大的span,如果有就可以將它進(jìn)行切分,切出一個(gè)k頁(yè)的span返回,剩下的頁(yè)數(shù)的span放到對(duì)應(yīng)的桶里;如果后面的桶里也沒(méi)有span,就去系統(tǒng)堆申請(qǐng)一個(gè)大小為128頁(yè)的span,并把它放到對(duì)應(yīng)的桶里。然后再遞歸調(diào)用自己,直到獲取到一個(gè)k頁(yè)的span為止。
{
assert(k > 0);
// 大于128 page的直接向堆申請(qǐng),這里的128頁(yè)相當(dāng)于128*8*1024 = 1M
if (k > NPAGES - 1)
{
void* ptr = SystemAlloc(k);
//Span* span = new Span;
Span* span = _spanPool.New();
span->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;// 頁(yè)號(hào):地址右移PAGE_SHIFT獲得
span->_n = k; // 頁(yè)數(shù)
// _idSpanMap[span->_pageId] = span;
_idSpanMap.set(span->_pageId, span);
return span;
}
// 先檢查第k個(gè)桶里面有沒(méi)有span
if (!_spanLists[k].Empty())
{
Span* kSpan = _spanLists[k].PopFront();
// 建立id和span的映射,方便central cache回收小塊內(nèi)存時(shí),查找對(duì)應(yīng)的span
for (PAGE_ID i = 0; i < kSpan->_n; i++)
{
// _idSpanMap[kSpan->_pageId + i] = kSpan;
_idSpanMap.set(kSpan->_pageId + i, kSpan);
}
return kSpan;
}
// 檢查一下后面的桶里面有沒(méi)有span,如果有可以把他它進(jìn)行切分
for (size_t i = k + 1; i < NPAGES; i++)
{
if (!_spanLists[i].Empty())
{
Span* nSpan = _spanLists[i].PopFront();
// Span* kSpan = new Span;
Span* kSpan = _spanPool.New();
// 在nSpan的頭部切一個(gè)k頁(yè)下來(lái)
// k頁(yè)span返回
// nSpan再掛到對(duì)應(yīng)映射的位置
kSpan->_pageId = nSpan->_pageId;// 標(biāo)記起始頁(yè)
kSpan->_n = k;// 標(biāo)記頁(yè)數(shù)
nSpan->_pageId += k;
nSpan->_n -= k;
_spanLists[nSpan->_n].PushFront(nSpan); // 被切分掉的另一塊放入對(duì)應(yīng)哈希桶
// 存儲(chǔ)nSpan的首尾頁(yè)號(hào)跟nSpan映射,方便page cache回收內(nèi)存時(shí)進(jìn)行的合并查找
// 因?yàn)闆](méi)被中心緩存拿走,所以只標(biāo)記了首尾就夠了
// _idSpanMap[nSpan->_pageId] = nSpan;
// _idSpanMap[nSpan->_pageId + nSpan->_n - 1] = nSpan;
_idSpanMap.set(nSpan->_pageId, nSpan);
_idSpanMap.set(nSpan->_pageId + nSpan->_n - 1, nSpan);
// 建立id和span的映射,方便central cache回收小塊內(nèi)存時(shí),查找對(duì)應(yīng)的span
for (PAGE_ID i = 0; i < kSpan->_n; i++)
{
// _idSpanMap[kSpan->_pageId + i] = kSpan;
_idSpanMap.set(kSpan->_pageId + i, kSpan);
}
return kSpan;
}
}
// 走到這個(gè)位置就說(shuō)明后面沒(méi)有大頁(yè)的span了
// 這時(shí)就去找堆要一個(gè)128頁(yè)的span
Span* bigSpan = new Span;
void* ptr = SystemAlloc(NPAGES - 1);
// 通過(guò)將 ptr 地址強(qiáng)制轉(zhuǎn)換為 PAGE_ID 類(lèi)型,再使用二進(jìn)制位運(yùn)算符 >> 將指針的地址右移 PAGE_SHIFT 位
// 最終得到的結(jié)果就是這個(gè)指針?biāo)诘摹绊?yè)的編號(hào)”
bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;
bigSpan->_n = NPAGES - 1;
_spanLists[bigSpan->_n].PushFront(bigSpan);
return NewSpan(k);// 遞歸調(diào)用自己,這一次一定能成功!
}
2.MapObjectToSpan(void* obj)
建立內(nèi)存地址和span的映射。前期映射方式是哈希或者紅黑樹(shù),后期性能優(yōu)化成基數(shù)樹(shù)。
{
PAGE_ID id = (PAGE_ID)obj >> PAGE_SHIFT;
/* std::unique_lock lock(_pageMtx);// 可以自動(dòng)解鎖
auto ret = _idSpanMap.find(id);
if (ret != _idSpanMap.end())
{
return ret->second;
}
else
{
assert(false);
return nullptr;
} */
// 基數(shù)樹(shù)優(yōu)化后不需要加鎖了
auto ret = (Span*)_idSpanMap.get(id);
assert(ret != nullptr);
return ret;
}
3.ReleaseSpanToPageCache(Span* span)
緩解外碎片問(wèn)題,對(duì)span前后的頁(yè),嘗試進(jìn)行合并,緩解內(nèi)存碎片問(wèn)題
{
// 大于128 page的直接還給堆,這里的128頁(yè)相當(dāng)于128*8*1024 = 1M
if (span->_n > NPAGES - 1)
{
void* ptr = (void*)(span->_pageId << PAGE_SHIFT);
//delete span;
SystemFree(ptr); // span結(jié)構(gòu)釋放,內(nèi)存還給堆,類(lèi)似free
_spanPool.Delete(span);// 放入定長(zhǎng)內(nèi)存池的自由鏈表,以便下次申請(qǐng)
return;
}
// 向前合并
while (1)
{
PAGE_ID prevId = span->_pageId - 1;
/*auto ret = _idSpanMap.find(prevId);
if (ret == _idSpanMap.end())
{
break;
}*/
auto ret = (Span*)_idSpanMap.get(prevId);
if (ret == nullptr)
{
break;
}
// 前面相鄰頁(yè)的span在使用,不合并了
// Span* prevSpan = ret->second;
Span* prevSpan = ret;
if (prevSpan->_isUse == true)
{
break;
}
// 合并出超過(guò)128頁(yè)的span沒(méi)辦法管理,不合并了
if (prevSpan->_n + span->_n > NPAGES - 1)
{
break;
}
span->_pageId = prevSpan->_pageId;
span->_n += prevSpan->_n;
_spanLists[prevSpan->_n].Erase(prevSpan);// 將prevSpan從頁(yè)緩存對(duì)應(yīng)的哈希桶的鏈表中刪掉
// delete prevSpan;// 為什么delete?
_spanPool.Delete(prevSpan);
}
// 向后合并
while (1)
{
PAGE_ID nextId = span->_pageId + span->_n;
/*auto ret = _idSpanMap.find(nextId);
if (ret == _idSpanMap.end())
{
break;
}*/
auto ret = (Span*)_idSpanMap.get(nextId);
if (ret == nullptr)
{
break;
}
// Span* nextSpan = ret->second;
Span* nextSpan = ret;
if (nextSpan->_isUse == true)
{
break;
}
if (nextSpan->_n + span->_n > NPAGES - 1)
{
break;
}
span->_n += nextSpan->_n;
_spanLists[nextSpan->_n].Erase(nextSpan);
// delete nextSpan;
_spanPool.Delete(nextSpan);
}
_spanLists[span->_n].PushFront(span);// 將合并完的span掛到頁(yè)緩存的對(duì)應(yīng)的哈希桶里面。
span->_isUse = false;
//_idSpanMap[span->_pageId] = span;// 首尾存起來(lái),方便被合并
//_idSpanMap[span->_pageId + span->_n - 1] = span;
_idSpanMap.set(span->_pageId, span);
_idSpanMap.set(span->_pageId + span->_n - 1, span);
}
上述代碼delete的作用:這里的delete操作是用來(lái)釋放prevSpan和nextSpan這兩個(gè)Span結(jié)構(gòu)體的內(nèi)存的。這兩個(gè)Span結(jié)構(gòu)體可能是之前由PageCache單例創(chuàng)建的,也可能是之前從中心緩存移動(dòng)過(guò)來(lái)的。無(wú)論是哪一種情況,它們都不再被使用了,因?yàn)橐呀?jīng)被合并到了當(dāng)前的span中。所以可以直接釋放掉它們的內(nèi)存。
這里的delete操作并不會(huì)影響prevSpan和nextSpan管理的內(nèi)存。這些內(nèi)存依然存在,只是沒(méi)有了管理它們的Span結(jié)構(gòu)體。在進(jìn)行合并的時(shí)候,這些內(nèi)存就被合并到了當(dāng)前的span中,當(dāng)前的span繼續(xù)管理這些內(nèi)存。因此,這里的delete操作僅僅是釋放了prevSpan和nextSpan這兩個(gè)Span結(jié)構(gòu)體的內(nèi)存,這個(gè)span管理的內(nèi)存并不受影響。
delete釋放掉span結(jié)構(gòu)體本身,不會(huì)同時(shí)釋放掉它管理的內(nèi)存。舉個(gè)例子,假如你有一個(gè)對(duì)象A,它管理了一個(gè)數(shù)組arr,那么你調(diào)用delete A時(shí),只會(huì)釋放掉A對(duì)象本身占用的內(nèi)存,而arr數(shù)組的內(nèi)存依然存在。
細(xì)節(jié)與性能優(yōu)化
使用定長(zhǎng)內(nèi)存池配合脫離使用new
我們定義一個(gè)Span結(jié)構(gòu)體時(shí)是new一個(gè)對(duì)象,但new的本質(zhì)是malloc,而本項(xiàng)目是不依賴malloc的,因此我們可以運(yùn)用我們自己實(shí)現(xiàn)的定長(zhǎng)內(nèi)存池來(lái)脫離new的使用。
對(duì)于Page Cache,由于要多次定義Span結(jié)構(gòu),因此我們定義一個(gè)特化Span對(duì)象的定長(zhǎng)內(nèi)存池:
ObjectPool _spanPool;
而對(duì)于Thread Cache,由于要保證對(duì)于線程而言,全局只有唯一一個(gè)Thread Cache對(duì)象,故在頭文件內(nèi)定義為靜態(tài)變量的定長(zhǎng)內(nèi)存池:
static ObjectPool tcPool;
//pTLSThreadCache = new ThreadCache;
pTLSThreadCache = tcPool.New();
解決內(nèi)存大于256kb的申請(qǐng)釋放問(wèn)題

1.ConcurrentAlloc() 時(shí),對(duì)于線程申請(qǐng)大于256kb內(nèi)存的情況, 直接向頁(yè)緩存申請(qǐng)即可:
{
size_t alignSize = SizeClass::RoundUp(size);// size對(duì)齊
size_t kPage = alignSize >> PAGE_SHIFT;// 獲取頁(yè)數(shù)
PageCache::GetInstance()->_pageMtx.lock();
Span* span = PageCache::GetInstance()->NewSpan(kPage);// 找頁(yè)緩存要kpage頁(yè)span
span->_objSize = size;// 會(huì)有一點(diǎn)內(nèi)碎片,標(biāo)記成alignSize也行
PageCache::GetInstance()->_pageMtx.unlock();
void* ptr = (void*)(span->_pageId << PAGE_SHIFT);// 獲取對(duì)應(yīng)地址
return ptr;
}
2.當(dāng)然了頁(yè)緩存的NewSpan()正常分配內(nèi)存的能力也有上限,大于128 page的選擇直接向堆申請(qǐng),這里的128頁(yè)相當(dāng)于128 * 8KB = 1M。
{
void* ptr = SystemAlloc(k);
//Span* span = new Span;
Span* span = _spanPool.New();
span->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;// 頁(yè)號(hào):地址右移PAGE_SHIFT獲得
span->_n = k; // 頁(yè)數(shù)
// _idSpanMap[span->_pageId] = span;
_idSpanMap.set(span->_pageId, span);
return span;
}
3.同樣的,ConcurrentFree()時(shí),大于256kb的內(nèi)存的釋放就直接釋放給頁(yè)緩存即可:
{
//找到ptr對(duì)應(yīng)的那塊span
PageCache::GetInstance()->_pageMtx.lock();
PageCache::GetInstance()->RealeaseSpanToPageCache(span);
PageCache::GetInstance()->_pageMtx.unlock();
}
4.ReleaseSpanToPageCache(Span* span)合并頁(yè)時(shí),若釋放的span大于128頁(yè),即span的頁(yè)數(shù)大于NPAGES - 1,則直接將內(nèi)存釋放到堆。
{
void* ptr = (void*)(span->_pageId << PAGE_SHIFT);
SystemFree(ptr);
//delete span;
_spanPool.Delete(span);
return;
}
使用基數(shù)樹(shù)進(jìn)行性能優(yōu)化
如果我們?cè)赑age Cache中使用STL的unordered_map容器來(lái)構(gòu)建_pageId與span的映射關(guān)系,那么通過(guò)測(cè)試發(fā)現(xiàn),當(dāng)前項(xiàng)目的運(yùn)行效率是要滿于malloc的。

接下來(lái)分析下項(xiàng)目的性能瓶頸:





分析得到項(xiàng)目在unordered_map _idSpanMap;中的鎖競(jìng)爭(zhēng)上浪費(fèi)了大量性能,這主要是unordered_map是線程不安全的,因此多線程下使用時(shí)需要加鎖,而大量加鎖導(dǎo)致資源的消耗。
因此,這里參考tcmalloc,使用基數(shù)樹(shù)來(lái)進(jìn)行性能的優(yōu)化。tcmalloc設(shè)計(jì)了三種基數(shù)樹(shù),即一層、二層與三層的基數(shù)樹(shù),其中一層和二層的基數(shù)樹(shù)是適配32位系統(tǒng)下的,而三層基數(shù)樹(shù)則是適配64位系統(tǒng)。
這里簡(jiǎn)單介紹以下一層和二層基數(shù)樹(shù),三層基數(shù)樹(shù)類(lèi)似于二層:
32位系統(tǒng)下,一個(gè)頁(yè)大小213,進(jìn)程地址空間大小232,所以一共有219個(gè)頁(yè),所以一層基數(shù)樹(shù)需要開(kāi)辟219個(gè)元素的數(shù)組,每個(gè)位置存一個(gè)指針,需要的內(nèi)存是4*2^19 = 2M。

32位系統(tǒng)下,兩層基數(shù)樹(shù)的結(jié)構(gòu)是第一層一個(gè)25個(gè)元素,第二層每個(gè)結(jié)點(diǎn)又有214個(gè)元素,這樣也就構(gòu)成了2^19個(gè)的數(shù)量。這樣的話拿到一個(gè)頁(yè)號(hào),(這個(gè)頁(yè)號(hào)二進(jìn)制下有32位,忽略高13位)這個(gè)頁(yè)號(hào)高13位之后的高5位決定了他在第一層的哪個(gè)位置,這個(gè)頁(yè)號(hào)高13位之后的高6位~高19位決定了他在第二層的哪個(gè)位置。
多層相較于1層還有個(gè)好處,多層不需要一次性開(kāi)辟所有空間,可以到具體需要時(shí)再開(kāi)辟空間。

基數(shù)樹(shù)相較于哈希桶的優(yōu)勢(shì)在于如果要寫(xiě)入_pageId和span的映射關(guān)系的話,并不會(huì)像哈希桶可能有結(jié)構(gòu)上的改變(紅黑樹(shù)翻轉(zhuǎn)、哈希桶擴(kuò)容等)(一個(gè)線程在讀的時(shí)候,另一個(gè)線程在寫(xiě)),而是一旦基數(shù)樹(shù)構(gòu)建好映射關(guān)系后,就不會(huì)改變其結(jié)構(gòu),之后只會(huì)有讀的操作,因此多線程環(huán)境下無(wú)需加鎖,從而減少了資源的消耗,優(yōu)化了性能。

只有NewSpan和ReleaseSpanToPageCache的時(shí)候,會(huì)去建立id和 span的映射,進(jìn)行所謂的“寫(xiě)”操作,但是這倆都加了鎖,絕對(duì)安全。事實(shí)上,即便不加鎖也沒(méi)事,因?yàn)槲覀儾豢赡茉谕粋€(gè)位置進(jìn)行寫(xiě),不可能同時(shí)創(chuàng)建一個(gè)span和釋放一個(gè)span。且基數(shù)樹(shù)寫(xiě)之前已經(jīng)開(kāi)好空間了,“寫(xiě)”的過(guò)程不會(huì)改變基數(shù)樹(shù)的結(jié)構(gòu)。
采用基數(shù)樹(shù)不需要加鎖的原因:
- 因?yàn)橥鶖?shù)樹(shù)建立映射的時(shí)候span沒(méi)有在central cache不會(huì)給外層使用,并且建立好一次映射關(guān)系,后續(xù)不需要再建立了,后續(xù)都是讀了。讀寫(xiě)分離了。
template
class TCMalloc_PageMap1
{
private:
static const int LENGTH = 1 << BITS;// 32 - 13 = 19
void** _array;
public:
typedef uintptr_t Number;//存儲(chǔ)指針的一個(gè)無(wú)符號(hào)整型類(lèi)型
explicit TCMalloc_PageMap1()//一次將數(shù)組所需空間開(kāi)好
{
//計(jì)算數(shù)組開(kāi)辟空間所需的大小
size_t size = sizeof(void*) << BITS;
size_t alignSize = SizeClass::_RoundUp(size, 1 << PAGE_SHIFT);
//由于要開(kāi)辟的空間是2M,已經(jīng)很大了,故直接想堆申請(qǐng)
_array = (void**)SystemAlloc(alignSize >> PAGE_SHIFT);
memset(_array, 0, size);
}
void Set(Number key, void* v)//key的范圍是[0, 2^BITS - 1],_pageId
{
_array[key] = v;
}
void* Get(Number key) const
{
if ((key >> BITS) > 0)//若key超出范圍或還未被設(shè)置,則返回空
{
return nullptr;
}
return _array[key];
}
};
// Two-level radix tree
template
class TCMalloc_PageMap2 {
private:
// Put 32 entries in the root and (2^BITS)/32 entries in each leaf.
static const int ROOT_BITS = 5;
static const int ROOT_LENGTH = 1 << ROOT_BITS;
static const int LEAF_BITS = BITS - ROOT_BITS;// 19 - 5 = 14
static const int LEAF_LENGTH = 1 << LEAF_BITS;// 1左移14位
// Leaf node
struct Leaf {
void* values[LEAF_LENGTH];
};
Leaf* root_[ROOT_LENGTH]; // Pointers to 32 child nodes
void* (*allocator_)(size_t); // Memory allocator
public:
typedef uintptr_t Number;
//explicit TCMalloc_PageMap2(void* (*allocator)(size_t)) {
explicit TCMalloc_PageMap2() {
//allocator_ = allocator;
memset(root_, 0, sizeof(root_));
PreallocateMoreMemory();
}
void* get(Number k) const {
const Number i1 = k >> LEAF_BITS;
const Number i2 = k & (LEAF_LENGTH - 1);// 獲取k低14位
if ((k >> BITS) > 0 || root_[i1] == NULL) {
return NULL;
}
return root_[i1]->values[i2];
}
void set(Number k, void* v) {
const Number i1 = k >> LEAF_BITS;
const Number i2 = k & (LEAF_LENGTH - 1);
ASSERT(i1 < ROOT_LENGTH);
root_[i1]->values[i2] = v;
}
// 確保從start頁(yè)開(kāi)始,往后n頁(yè)的基數(shù)樹(shù)位置都給你開(kāi)好
bool Ensure(Number start, size_t n) {
for (Number key = start; key <= start + n - 1;) {
const Number i1 = key >> LEAF_BITS;
// Check for overflow
if (i1 >= ROOT_LENGTH)
return false;
// Make 2nd level node if necessary
if (root_[i1] == NULL) {
//Leaf* leaf = reinterpret_cast((*allocator_)(sizeof(Leaf)));
//if (leaf == NULL) return false;
static ObjectPool leafPool;
Leaf* leaf = (Leaf*)leafPool.New();
memset(leaf, 0, sizeof(*leaf));
root_[i1] = leaf;
}
// Advance key past whatever is covered by this leaf node
key = ((key >> LEAF_BITS) + 1) << LEAF_BITS;
}
return true;
}
void PreallocateMoreMemory() {
// Allocate enough to keep track of all possible pages
Ensure(0, 1 << BITS);
}
};
// Three-level radix tree
template
class TCMalloc_PageMap3 {
private:
// How many bits should we consume at each interior level
static const int INTERIOR_BITS = (BITS + 2) / 3; // Round-up
static const int INTERIOR_LENGTH = 1 << INTERIOR_BITS;
// How many bits should we consume at leaf level
static const int LEAF_BITS = BITS - 2 * INTERIOR_BITS;
static const int LEAF_LENGTH = 1 << LEAF_BITS;
// Interior node
struct Node {
Node* ptrs[INTERIOR_LENGTH];
};
// Leaf node
struct Leaf {
void* values[LEAF_LENGTH];
};
Node* root_; // Root of radix tree
void* (*allocator_)(size_t); // Memory allocator
Node* NewNode() {
Node* result = reinterpret_cast((*allocator_)(sizeof(Node)));
if (result != NULL) {
memset(result, 0, sizeof(*result));
}
return result;
}
public:
typedef uintptr_t Number;
explicit TCMalloc_PageMap3(void* (*allocator)(size_t)) {
allocator_ = allocator;
root_ = NewNode();
}
void* get(Number k) const {
const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);
const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);
const Number i3 = k & (LEAF_LENGTH - 1);
if ((k >> BITS) > 0 ||
root_->ptrs[i1] == NULL || root_->ptrs[i1]->ptrs[i2] == NULL) {
return NULL;
}
return reinterpret_cast(root_->ptrs[i1]->ptrs[i2])->values[i3];
}
void set(Number k, void* v) {
ASSERT(k >> BITS == 0);
const Number i1 = k >> (LEAF_BITS + INTERIOR_BITS);
const Number i2 = (k >> LEAF_BITS) & (INTERIOR_LENGTH - 1);
const Number i3 = k & (LEAF_LENGTH - 1);
reinterpret_cast(root_->ptrs[i1]->ptrs[i2])->values[i3] = v;
}
bool Ensure(Number start, size_t n) {
for (Number key = start; key <= start + n - 1;) {
const Number i1 = key >> (LEAF_BITS + INTERIOR_BITS);
const Number i2 = (key >> LEAF_BITS) & (INTERIOR_LENGTH - 1);
// Check for overflow
if (i1 >= INTERIOR_LENGTH || i2 >= INTERIOR_LENGTH)
return false;
// Make 2nd level node if necessary
if (root_->ptrs[i1] == NULL) {
Node* n = NewNode();
if (n == NULL) return false;
root_->ptrs[i1] = n;
}
// Make leaf node if necessary
if (root_->ptrs[i1]->ptrs[i2] == NULL) {
Leaf* leaf = reinterpret_cast((*allocator_)(sizeof(Leaf)));
if (leaf == NULL) return false;
memset(leaf, 0, sizeof(*leaf));
root_->ptrs[i1]->ptrs[i2] = reinterpret_cast(leaf);
}
// Advance key past whatever is covered by this leaf node
key = ((key >> LEAF_BITS) + 1) << LEAF_BITS;
}
return true;
}
void PreallocateMoreMemory() {
}
};*>*>*>*>*>*>
項(xiàng)目總結(jié)
結(jié)果演示
可以看到通過(guò)基數(shù)樹(shù)優(yōu)化后的高并發(fā)內(nèi)存池在性能上是要優(yōu)于malloc函數(shù)的。

項(xiàng)目對(duì)比malloc性能高的原因
malloc底層是采用邊界標(biāo)記法將內(nèi)存劃分成很多塊,從而對(duì)內(nèi)存的分配與回收進(jìn)行管理。簡(jiǎn)單來(lái)說(shuō),malloc分配內(nèi)存時(shí)會(huì)先獲取分配區(qū)的鎖,然后根據(jù)申請(qǐng)內(nèi)存的大小一級(jí)一級(jí)的去獲取內(nèi)存空間,最后返回。
所以在高并發(fā)的場(chǎng)景下,malloc在申請(qǐng)內(nèi)存時(shí)需要加鎖,以避免多個(gè)線程同時(shí)修改內(nèi)存分配信息,這會(huì)導(dǎo)致性能下降。而內(nèi)存池可以通過(guò)維護(hù)自由鏈表來(lái)分配內(nèi)存,避免了加鎖的開(kāi)銷(xiāo)。
總結(jié)出本項(xiàng)目效率相對(duì)較高的3點(diǎn)原因:
- 1.第一級(jí)thread cache通過(guò)tls技術(shù)實(shí)現(xiàn)了無(wú)鎖訪問(wèn)。
- 2.第二級(jí)central cache加的是桶鎖,可以更好的實(shí)現(xiàn)多線程的并行。
- 3.第三級(jí)page cache通過(guò)基數(shù)樹(shù)優(yōu)化,有效減少了鎖的競(jìng)爭(zhēng)。
項(xiàng)目擴(kuò)展及缺陷
1.實(shí)際上在釋放內(nèi)存時(shí)由thread cache將自由鏈表對(duì)象歸還給central cache只使用了鏈表過(guò)長(zhǎng)這一個(gè)條件,但是實(shí)際中這個(gè)條件大概率不能恰好達(dá)成,那么就會(huì)出現(xiàn)thread cache中自由鏈表掛著許多未被使用的內(nèi)存塊,從而出現(xiàn)了線程結(jié)束時(shí)可能導(dǎo)致內(nèi)存泄露的問(wèn)題。
解決方法就是使用動(dòng)態(tài)tls或者通過(guò)回調(diào)函數(shù)來(lái)回收這部分的內(nèi)存,并且通過(guò)申請(qǐng)批次統(tǒng)計(jì)內(nèi)存占有量,保證線程不會(huì)過(guò)多占有資源。
2.可以將這個(gè)項(xiàng)目打成靜態(tài)庫(kù)或動(dòng)態(tài)庫(kù)替換調(diào)用系統(tǒng)調(diào)用malloc,不同平臺(tái)替換方式不同。 基于unix的系統(tǒng)上的glibc,使用了weak alias的方式替換。具體來(lái)說(shuō)是因?yàn)檫@些入口函數(shù)都被定義成了weak symbols,再加上gcc支持 alias attribute,所以替換就變成了這種通用形式:
因此所有malloc的調(diào)用都跳轉(zhuǎn)到了tc_malloc的實(shí)現(xiàn)。有些平臺(tái)不支持這樣的東西,需要使用hook的鉤子技術(shù)來(lái)做。
-
內(nèi)存
+關(guān)注
關(guān)注
8文章
3108瀏覽量
74984 -
操作系統(tǒng)
+關(guān)注
關(guān)注
37文章
7081瀏覽量
124940 -
多線程
+關(guān)注
關(guān)注
0文章
279瀏覽量
20304
發(fā)布評(píng)論請(qǐng)先 登錄
詳解內(nèi)存池技術(shù)的原理與實(shí)現(xiàn)
C++內(nèi)存池的設(shè)計(jì)與實(shí)現(xiàn)
從服務(wù)端視角看高并發(fā)難題
內(nèi)存池可以調(diào)節(jié)內(nèi)存的大小嗎
內(nèi)存池的概念和實(shí)現(xiàn)原理概述
關(guān)于RT-Thread內(nèi)存管理的內(nèi)存池簡(jiǎn)析
ATC'22頂會(huì)論文RunD:高密高并發(fā)的輕量級(jí) Serverless 安全容器運(yùn)行時(shí) | 龍蜥技術(shù)
RT-Thread內(nèi)存管理之內(nèi)存池實(shí)現(xiàn)分析
解密高并發(fā)業(yè)務(wù)場(chǎng)景下典型的秒殺系統(tǒng)的架構(gòu)
什么是內(nèi)存池

了解連接池、線程池、內(nèi)存池、異步請(qǐng)求池
如何實(shí)現(xiàn)一個(gè)高性能內(nèi)存池
內(nèi)存池的使用場(chǎng)景
nginx內(nèi)存池源碼設(shè)計(jì)
內(nèi)存池主要解決的問(wèn)題





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論