 讓Attention提速9倍!FlashAttention燃爆顯存,Transformer上下文長度史詩級提升
讓Attention提速9倍!FlashAttention燃爆顯存,Transformer上下文長度史詩級提升
FlashAttention新升級!斯坦福博士一人重寫算法,第二代實現了最高9倍速提升。
繼超快且省內存的注意力算法FlashAttention爆火后,升級版的2代來了。FlashAttention-2是一種從頭編寫的算法,可以加快注意力并減少其內存占用,且沒有任何近似值。比起第一代,FlashAttention-2速度提升了2倍。甚至,相較于PyTorch的標準注意力,其運行速度最高可達9倍。
一年前,StanfordAILab博士Tri Dao發布了FlashAttention,讓注意力快了2到4倍,如今,FlashAttention已經被許多企業和研究室采用,廣泛應用于大多數LLM庫。如今,隨著長文檔查詢、編寫故事等新用例的需要,大語言模型的上下文以前比過去變長了許多——GPT-4的上下文長度是32k,MosaicML的MPT上下文長度是65k,Anthropic的Claude上下文長度是100k。但是,擴大Transformer的上下文長度是一項極大的挑戰,因為作為其核心的注意力層的運行時間和內存要求,是輸入序列長度的二次方。Tri Dao一直在研究FlashAttention-2,它比v1快2倍,比標準的注意力快5到9倍,在A100上已經達到了225 TFLOP/s的訓練速度!

項目鏈接:
https://github.com/Dao-AILab/flash-attention
 ?
?FlashAttention-2:更好的算法、并行性和工作分區
端到端訓練GPT模型,速度高達225 TFLOP/s
雖說FlashAttention在發布時就已經比優化的基線快了2-4倍,但還是有相當大的進步空間。比方說,FlashAttention仍然不如優化矩陣乘法(GEMM)運算快,僅能達到理論最大FLOPs/s的25-40%(例如,在A100 GPU上的速度可達124 TFLOPs/s)。
對注意力計算重新排序
我們知道,FlashAttention是一種對注意力計算進行重新排序的算法,利用平鋪、重新計算來顯著加快計算速度,并將序列長度的內存使用量從二次減少到線性。
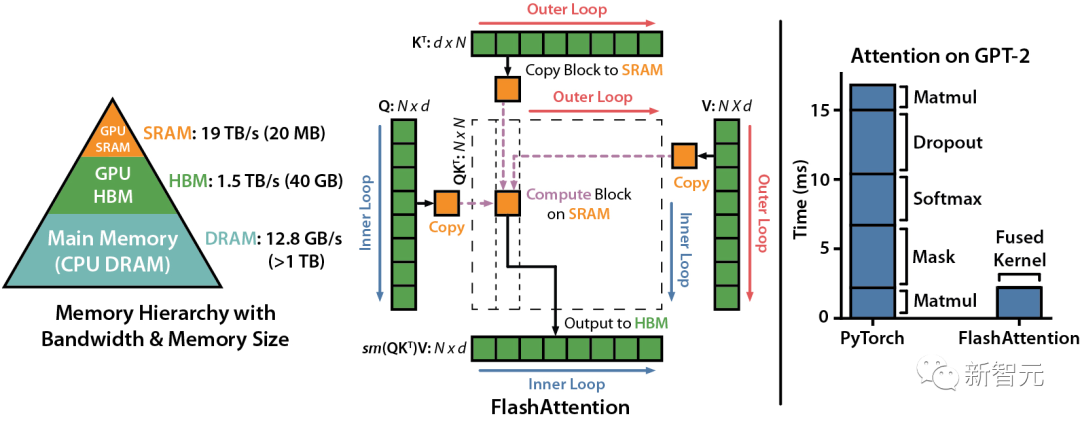
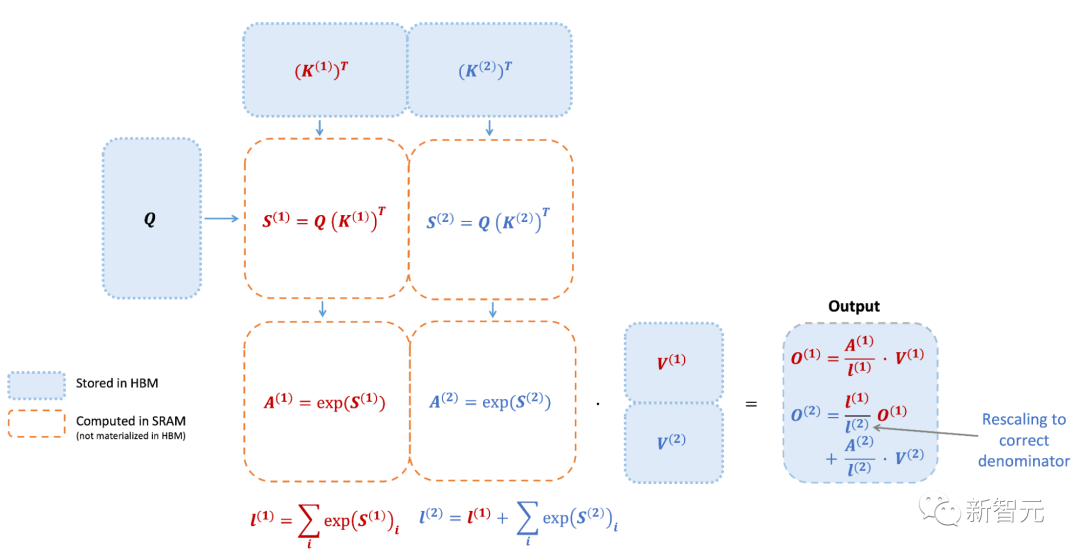
然而,FlashAttention仍然存在一些低效率的問題,這是由于不同線程塊之間的工作劃分并不理想,以及GPU上的warp——導致低占用率或不必要的共享內存讀寫。
更少的non-matmulFLOP(非矩陣乘法浮點計算數)
研究人員通過調整FlashAttention的算法來減少non-matmul FLOP的次數。這非常重要,因為現代GPU有專門的計算單元(比如英偉達GPU上的張量核心),這就使得matmul的速度更快。例如,A100 GPU FP16/BF16 matmul的最大理論吞吐量為312 TFLOPs/s,但non-matmul FP32的理論吞吐量僅為 19.5 TFLOPs/s。另外,每個非matmul FLOP比matmul FLOP要貴16倍。所以為了保持高吞吐量,研究人員希望在matmul FLOP上花盡可能多的時間。研究人員還重新編寫了FlashAttention中使用的在線softmax技巧,以減少重新縮放操作的數量,以及邊界檢查和因果掩碼操作,而無需更改輸出。更好的并行性
FlashAttention v1在批大小和部數量上進行并行化處理。研究人員使用1個線程塊來處理一個注意力頭,共有 (batch_size * head number) 個線程塊。
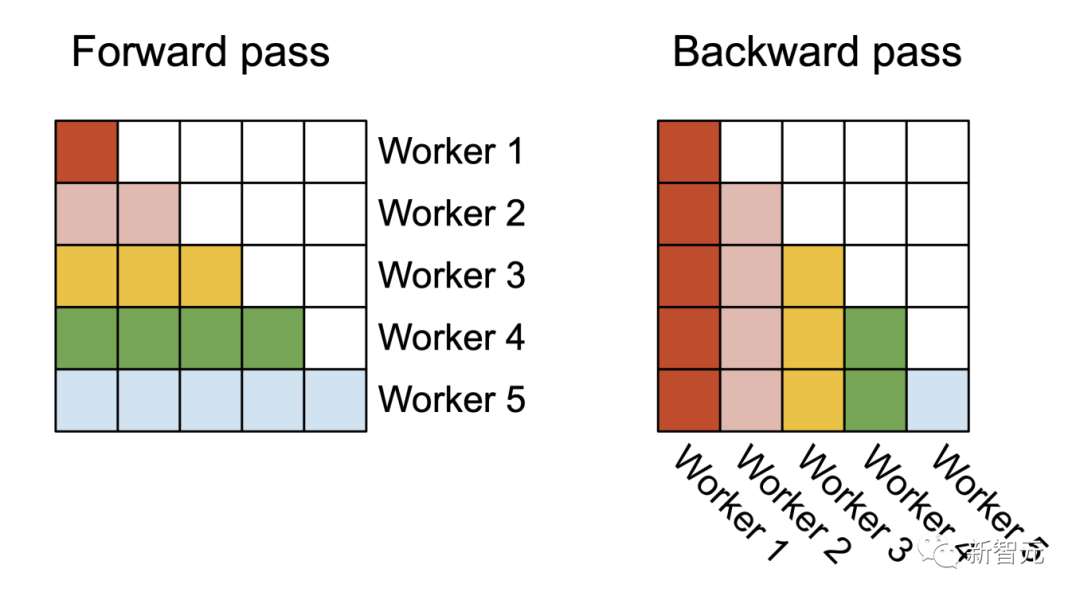
每個線程塊都在流式多處理器 (SM)運行,例如,A100 GPU上有108個這樣的處理器。當這個數字很大(比如 ≥80)時,這種調度是有效的,因為在這種情況下,可以有效地使用GPU上幾乎所有的計算資源。在長序列的情況下(通常意味著更小批或更少的頭),為了更好地利用GPU上的多處理器,研究人員在序列長度的維度上另外進行了并行化,使得該機制獲得了顯著加速。
更好的工作分區
即使在每個線程塊內,研究人員也必須決定如何在不同的warp(線程束)之間劃分工作(一組32個線程一起工作)。研究人員通常在每個線程塊使用4或8個warp,分區方案如下圖所示。研究人員在FlashAttention-2中改進了這種分區,減少了不同warp之間的同步和通信量,從而減少共享內存讀/寫。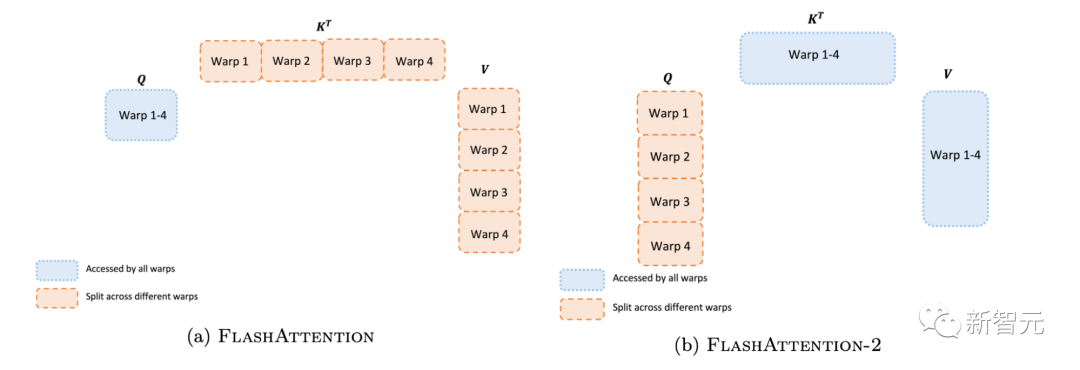 對于每個塊,FlashAttention將K和V分割到4個warp上,同時保持Q可被所有warp訪問。這稱為「sliced-K」方案。然而,這樣做的效率并不高,因為所有warp都需要將其中間結果寫入共享內存,進行同步,然后再將中間結果相加。而這些共享內存讀/寫會減慢FlashAttention中的前向傳播速度。在FlashAttention-2中,研究人員將Q拆分為4個warp,同時保持所有warp都可以訪問K和V。在每個warp執行矩陣乘法得到Q K^T的一個切片后,它們只需與共享的V切片相乘,即可得到相應的輸出切片。這樣一來,warp之間就不再需要通信。共享內存讀寫的減少就可以提高速度。
對于每個塊,FlashAttention將K和V分割到4個warp上,同時保持Q可被所有warp訪問。這稱為「sliced-K」方案。然而,這樣做的效率并不高,因為所有warp都需要將其中間結果寫入共享內存,進行同步,然后再將中間結果相加。而這些共享內存讀/寫會減慢FlashAttention中的前向傳播速度。在FlashAttention-2中,研究人員將Q拆分為4個warp,同時保持所有warp都可以訪問K和V。在每個warp執行矩陣乘法得到Q K^T的一個切片后,它們只需與共享的V切片相乘,即可得到相應的輸出切片。這樣一來,warp之間就不再需要通信。共享內存讀寫的減少就可以提高速度。
 ?新功能:頭的維度高達256,多查詢注意力
?新功能:頭的維度高達256,多查詢注意力FlashAttention僅支持最大128的頭的維度,雖說適用于大多數模型,但還是有一些模型被排除在外。FlashAttention-2現在支持256的頭的維度,這意味著GPT-J、CodeGen、CodeGen2以及Stable Diffusion 1.x等模型都可以使用FlashAttention-2來獲得加速和節省內存。v2還支持多查詢注意力(MQA)以及分組查詢注意力(GQA)。
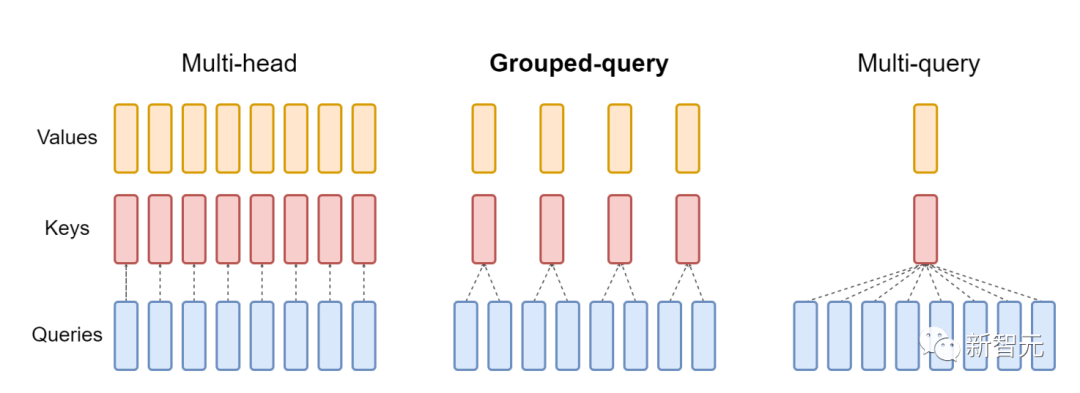
▲GQA為每組查詢頭共享單個key和value的頭,在多頭和多查詢注意之間進行插值
這些都是注意力的變體,其中多個查詢頭會指向key和value的同一個頭,以減少推理過程中KV緩存的大小,并可以顯著提高推理的吞吐量。
 ?
?注意力基準
研究人員人員在A100 80GB SXM4 GPU 上測量不同設置(有無因果掩碼、頭的維度是64或128)下不同注意力方法的運行時間。
 研究人員發現FlashAttention-2比第一代快大約2倍(包括在xformers庫和Triton中的其他實現)。與PyTorch中的標準注意力實現相比,FlashAttention-2的速度最高可達其9倍。
研究人員發現FlashAttention-2比第一代快大約2倍(包括在xformers庫和Triton中的其他實現)。與PyTorch中的標準注意力實現相比,FlashAttention-2的速度最高可達其9倍。
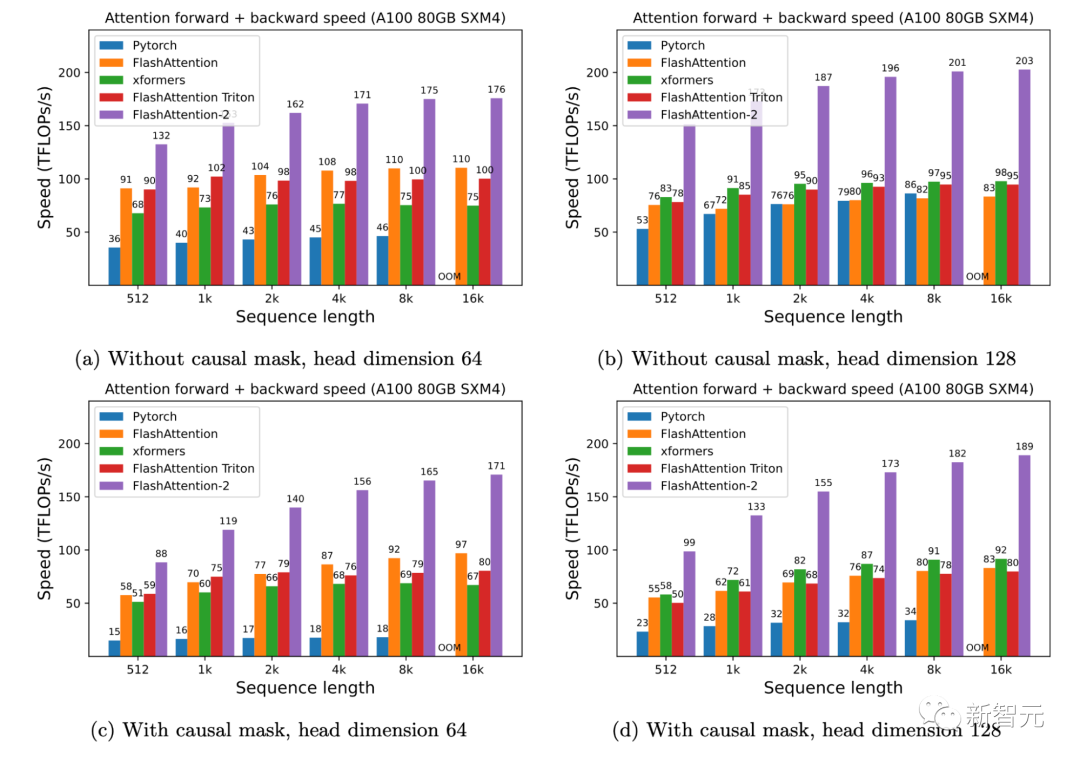
▲A100 GPU上的前向+后向速度
只需在H100 GPU上運行相同的實現(不需要使用特殊指令來利用TMA和第四代Tensor Core等新硬件功能),研究人員就可以獲得高達335 TFLOPs/s的速度。
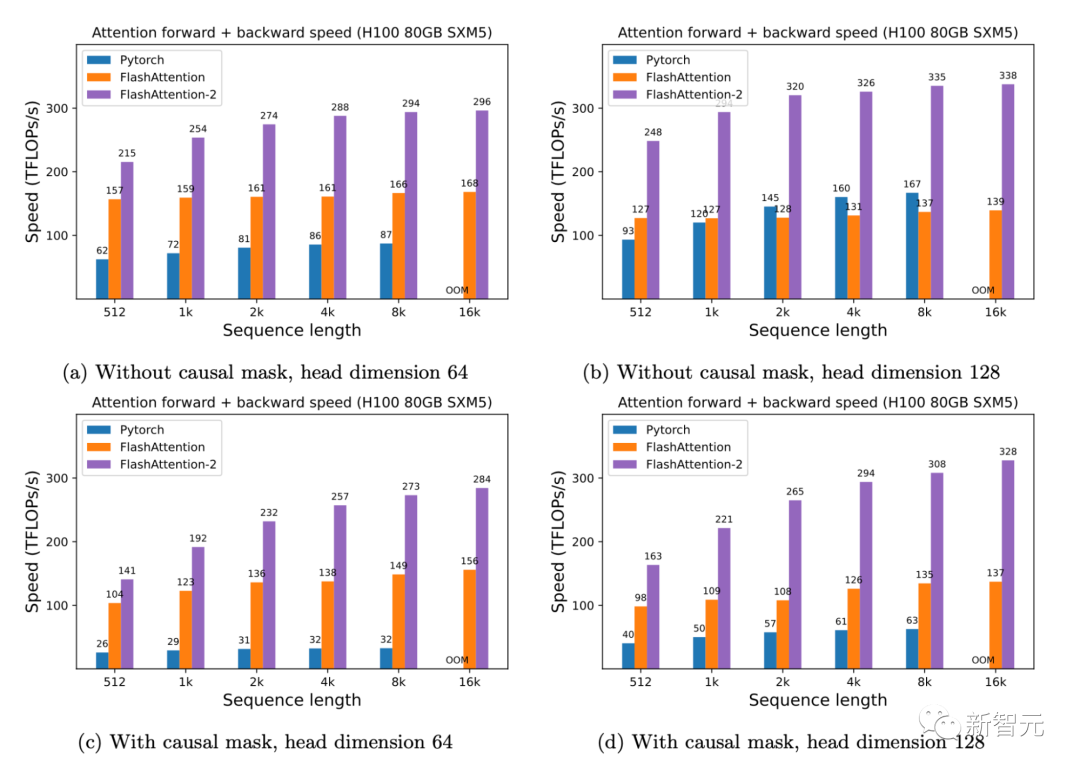
▲H100 GPU上的前向+后向速度
當用于端到端訓練GPT類模型時,FlashAttention-2能在A100 GPU上實現高達225TFLOPs/s的速度(模型FLOPs利用率為72%)。與已經非常優化的FlashAttention模型相比,端到端的加速進一步提高了1.3倍。
 ?
? ?
?未來的工作
速度上快2倍,意味著研究人員可以用與之前訓練8k上下文模型相同的成本,來訓練16k上下文長度的模型。這些模型可以理解長篇書籍和報告、高分辨率圖像、音頻和視頻。同時,FlashAttention-2還將加速現有模型的訓練、微調和推理。在不久的將來,研究人員還計劃擴大合作,使FlashAttention廣泛適用于不同類型的設備(例如H100 GPU、AMD GPU)以及新的數據類型(例如fp8)。下一步,研究人員計劃針對H100 GPU進一步優化FlashAttention-2,以使用新的硬件功能(TMA、第四代Tensor Core、fp8等等)。將FlashAttention-2中的低級優化與高級算法更改(例如局部、擴張、塊稀疏注意力)相結合,可以讓研究人員用更長的上下文來訓練AI模型。研究人員也很高興與編譯器研究人員合作,使這些優化技術更好地應用于編程。
 ?作者介紹
?作者介紹Tri Dao曾在斯坦福大學獲得了計算機博士學位,導師是Christopher Ré和Stefano Ermon。根據主頁介紹,他將從2024年9月開始,任職普林斯頓大學計算機科學助理教授。
Tri Dao的研究興趣在于機器學習和系統,重點關注高效訓練和長期環境:- 高效Transformer訓練和推理 - 遠程記憶的序列模型 - 緊湊型深度學習模型的結構化稀疏性。
值得一提的是,Tri Dao今天正式成為生成式AI初創公司Together AI的首席科學家。

原文標題:讓Attention提速9倍!FlashAttention燃爆顯存,Transformer上下文長度史詩級提升
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
物聯網
+關注
關注
2927文章
45863瀏覽量
387903
原文標題:讓Attention提速9倍!FlashAttention燃爆顯存,Transformer上下文長度史詩級提升
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯網技術研究所】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
UIAbility組件基本用法說明
UIAbility組件基本用法
UIAbility組件的基本用法包括:指定UIAbility的啟動頁面以及獲取UIAbility的上下文UIAbilityContext。
指定UIAbility
發表于 05-16 06:32
S32K在AUTOSAR中使用CAT1 ISR,是否需要執行上下文切換?
如果我們在 AUTOSAR 中使用 CAT1 ISR,是否需要執行上下文切換?另外,是否需要返回指令才能跳回到作系統?您有沒有帶有 CAT1 ISR 的 S32K3x4 微控制器的示例?
發表于 03-27 07:34
摩爾線程Round Attention優化AI對話
摩爾線程科研團隊發布研究成果《Round Attention:以輪次塊稀疏性開辟多輪對話優化新范式》,該方法端到端延遲低于現在主流的Flash Attention推理引擎,kv-cache 顯存占用節省55%到82% 。

北京大學兩部 DeepSeek 秘籍新出爐!(附全集下載)
Pre-trained Transformer)的簡寫。
其基本工作流程是:
收到提示詞
將輸入拆分為 token
利用 Transformer 架構處理 token
基于上下文預測下一個 token
發表于 02-27 17:57
DeepSeek推出NSA機制,加速長上下文訓練與推理
的特性,專為超快速的長上下文訓練和推理而設計。 NSA通過針對現代硬件的優化設計,顯著加快了推理速度,并大幅度降低了預訓練成本,同時保持了卓越的性能表現。這一機制在確保效率的同時,并未犧牲模型的準確性或功能。 在廣泛的基準測試、涉及長上下文的任務以及基于指令的推理場景中,
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
學習任務、上下文長度、記憶和隱藏狀態提高適應性。
任務適應
依賴數據采集和微調,可能效率較低。
利用復雜指令并自動從多樣的上下文中學習。
預訓練階段
專注于世界知識和理解硬件。
強調在各種任務上學
發表于 12-24 15:03
阿里通義千問發布Qwen2.5-Turbo開源AI模型
近日,阿里通義千問官方宣布,經過數月的精心優化與改進,正式推出了Qwen2.5-Turbo開源AI模型。這款新模型旨在滿足社區對更長上下文長度的迫切需求,為用戶帶來更加便捷、高效的AI
Llama 3 在自然語言處理中的優勢
領域的最新進展。 1. 高度的上下文理解能力 Llama 3的一個顯著優勢是其對上下文的深刻理解。傳統的NLP模型往往在處理復雜的語言結構和上下文依賴性時遇到困難。Llama 3通過使用先進的注意力機制和
英偉達推出歸一化Transformer,革命性提升LLM訓練速度
了新的突破。 相較于傳統的Transformer架構,nGPT在保持原有精度的同時,直接將大型語言模型(LLM)的訓練速度提升了高達20倍。這一顯著的性能提升,無疑將極大地推動AI技術
顯存技術不斷升級,AI計算中如何選擇合適的顯存
電子發燒友網報道(文/李彎彎)顯存,是顯卡上用于存儲圖像數據、紋理、幀緩沖區等的內存。它的大小直接決定了顯卡能夠同時處理的數據量。 ? 在AI計算中,顯存的大小對處理大規模數據集、深度學習模型的訓練
用AD8676設計了一個2級放大電路,輸出信號幅值正確,但是會上下漂移,為什么?
最近用AD8676設計了一個2級放大電路,放大器采用正負12V雙電源供電。輸入信號是mV級別的交流信號(由熱釋電傳感器輸出),一級放大400倍,2級放大2
發表于 08-27 06:36
SystemView上下文統計窗口識別阻塞原因
SystemView工具可以記錄嵌入式系統的運行時行為,實現可視化的深入分析。在新發布的v3.54版本中,增加了一項新功能:上下文統計窗口,提供了對任務運行時統計信息的深入分析,使用戶能夠徹底檢查每個任務,幫助開發人員識別阻塞原因。
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
能夠關注到輸入文本中的重要部分,從而提高預測的準確性和效率。這種機制允許模型在處理文本時同時考慮多個位置的信息,并根據重要性進行加權處理。
一些關鍵技術
1. 上下文理解
大語言模型能夠同時考慮句子前后
發表于 08-02 11:03
鴻蒙Ability Kit(程序框架服務)【UIAbility組件基本用法】
UIAbility組件的基本用法包括:指定UIAbility的啟動頁面以及獲取UIAbility的上下文[UIAbilityContext]。

鴻蒙Ability Kit(程序框架服務)【應用上下文Context】
[Context]是應用中對象的上下文,其提供了應用的一些基礎信息,例如resourceManager(資源管理)、applicationInfo(當前應用信息)、dir(應用文件路徑)、area





 工商網監
工商網監
評論