 石墨文檔Websocket百萬長連接技術實踐
石墨文檔Websocket百萬長連接技術實踐

1 引言
在石墨文檔的部分業務中,例如文檔分享、評論、幻燈片演示和文檔表格跟隨等場景,涉及到多客戶端數據同步和服務端批量數據推送的需求,一般的 HTTP 協議無法滿足服務端主動 Push 數據的場景,因此選擇采用 WebSocket 方案進行業務開發。
隨著石墨文檔業務發展,目前日連接峰值已達百萬量級,日益增長的用戶連接數和不符合目前量級的架構設計導致了內存和 CPU 使用量急劇增長,因此我們考慮對網關進行重構。
基于 Spring Boot + MyBatis Plus + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
- 項目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 視頻教程:https://doc.iocoder.cn/video/
2 網關 1.0
網關 1.0 是使用 Node.js 基于 Socket.IO 進行修改開發的版本,很好的滿足了當時用戶量級下的業務場景需求。
2.1 架構
網關 1.0 版本架構設計圖:

網關 1.0 客戶端連接流程:
- 用戶通過 NGINX 連接網關,該操作被業務服務感知;
- 業務服務感知到用戶連接后,會進行相關用戶數據查詢,再將消息 Pub 到 Redis;
- 網關服務通過 Redis Sub 收到消息;
- 查詢網關集群中的用戶會話數據,向客戶端進行消息推送。
2.2 痛點
雖然 1.0 版本的網關在線上運行良好,但是不能很好的支持后續業務的擴展,并且有以下幾個問題需要解決:
- 資源消耗:Nginx 僅使用 TLS 解密,請求透傳,產生了大量的資源浪費,同時之前的 Node 網關性能不好,消耗大量的 CPU、內存。
- 維護與觀測:未接入石墨的監控體系,無法和現有監控告警聯通,維護上存在一定的困難;
- 業務耦合問題:業務服務與網關功能被集成到了同一個服務中,無法針對業務部分性能損耗進行針對性水平擴容,為了解決性能問題,以及后續的模塊擴展能力,都需要進行服務解耦。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 實現的后臺管理系統 + 用戶小程序,支持 RBAC 動態權限、多租戶、數據權限、工作流、三方登錄、支付、短信、商城等功能
3 網關 2.0
網關 2.0 需要解決很多問題:石墨文檔內部有很多組件:文檔、表格、幻燈片和表單等等。在 1.0 版本中組件對網關的業務調用可以通過:Redis、Kafka 和 HTTP 接口,來源不可查,管控困難。此外,從性能優化的角度考慮也需要對原有服務進行解耦合,將 1.0 版本網關拆分為網關功能部分和業務處理部分,網關功能部分為 WS-Gateway:集成用戶鑒權、TLS 證書驗證和 WebSocket 連接管理等;業務處理部分為 WS-API:組件服務直接與該服務進行 gRPC 通信。可針對具體的模塊進行針對性擴容;服務重構加上 Nginx 移除,整體硬件消耗顯著降低;服務整合到石墨監控體系。
3.1 整體架構
網關 2.0 版本架構設計圖:

網關 2.0 客戶端連接流程:
- 客戶端與 WS-Gateway 服務通過握手流程建立 WebSocket 連接;
- 連接建立成功后,WS-Gateway 服務將會話進行節點存儲,將連接信息映射關系緩存到 Redis 中,并通過 Kafka 向 WS-API 推送客戶端上線消息;
- WS-API 通過 Kafka 接收客戶端上線消息及客戶端上行消息;
- WS-API 服務預處理及組裝消息,包括從 Redis 獲取消息推送的必要數據,并進行完成消息推送的過濾邏輯,然后 Pub 消息到 Kafka;
- WS-Gateway 通過 Sub Kafka 來獲取服務端需要返回的消息,逐個推送消息至客戶端。
3.2 握手流程
網絡狀態良好的情況下,完成如下圖所示步驟 1 到步驟 6 之后,直接進入 WebSocket 流程;網絡環境較差的情況下,WebSocket 的通信模式會退化成 HTTP 方式,客戶端通過 POST 方式推送消息到服務端,再通過 GET 長輪詢的方式從讀取服務端返回數據。客戶端初次請求服務端連接建立的握手流程:
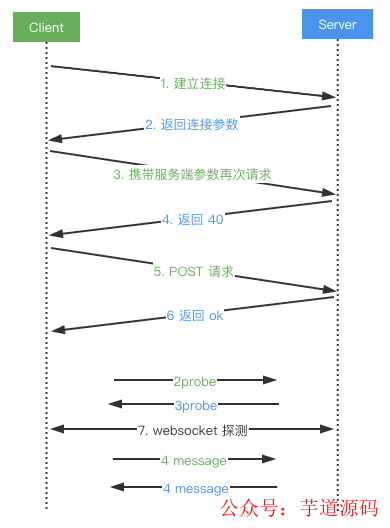
- Client 發送 GET 請求嘗試建立連接;
- Server 返回相關連接數據,sid 為本次連接產生的唯一 Socket ID,后續交互作為憑證;
{"sid":"xxx","upgrades":["websocket"],"pingInterval":xxx,"pingTimeout":xxx}
- Client 攜帶步驟 2 中的 sid 參數再次請求;
- Server 返回 40,表示請求接收成功;
- Client 發送 POST 請求確認后期降級通路情況;
- Server 返回 ok,此時第一階段握手流程完成;
- 嘗試發起 WebSocket 連接,首先進行 2probe 和 3probe 的請求響應,確認通信通道暢通后,即可進行正常的 WebSocket 通信。
3.3 TLS 內存消耗優化
客戶端與服務端連接建立采用的 wss 協議,在 1.0 版本中 TLS 證書掛載在 Nginx 上,HTTPS 握手過程由 Nginx 完成,為了降低 Nginx 的機器成本,在 2.0 版本中我們將證書掛載到服務上,通過分析服務內存,如下圖所示,TLS 握手過程中消耗的內存占了總內存消耗的大概 30% 左右。
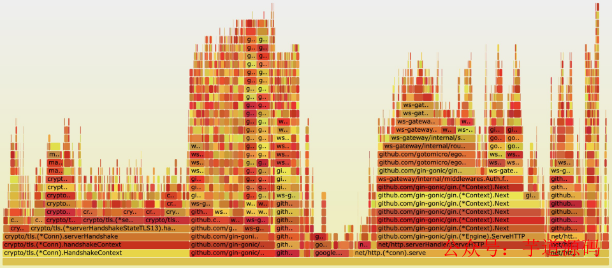
這個部分的內存消耗無法避免,我們有兩個選擇:
- 采用七層負載均衡,在七層負載上進行 TLS 證書掛載,將 TLS 握手過程移交給性能更好的工具完成;
- 優化 Go 對 TLS 握手過程性能,在與業內大佬曹春暉(曹大)的交流中了解到,他最近在 Go 官方庫提交的 PR https://github.com/golang/go/issues/43563 ,以及相關的性能測試數據 https://github.com/golang/go/pull/48229 。
3.4 Socket ID 設計
對每次連接必須產生一個唯一碼,如果出現重復會導致串號,消息混亂推送的問題。選擇 SnowFlake 算法作為唯一碼生成算法。
物理機場景中,對副本所在物理機進行固定編號,即可保證每個副本上的服務產生的 Socket ID 是唯一值。
K8S 場景中,這種方案不可行,于是采用注冊下發的方式返回編號,WS-Gateway 所有副本啟動后向數據庫寫入服務的啟動信息,獲取副本編號,以此作為參數作為 SnowFlake 算法的副本編號進行 Socket ID 生產,服務重啟會繼承之前已有的副本編號,有新版本下發時會根據自增 ID 下發新的副本編號。于此同時,Ws-Gateway 副本會向數據庫寫入心跳信息,以此作為網關服務本身的健康檢查依據。
3.5 集群會話管理方案:事件廣播
客戶端完成握手流程后,會話數據在當前網關節點內存存儲,部分可序列化數據存儲到 Redis,存儲結構說明如下:
| 鍵 | 說明 |
|---|---|
| wsclients:${uid} | 存儲用戶和 WebSocket 連接的關系,采用有序集合方式存儲 |
| wsclients:${guid} | 存儲文件和 WebSocket 連接的關系,采用有序結合方式存儲 |
| ws${socket.id} | 存儲當前 WebSocket 連接下的全部用戶和文件關系數據,采用 Redis Hash 方式進行存儲,對應 key 為 user 和 guid |
由客戶端觸發或組件服務觸發的消息推送,通過 Redis 存儲的數據結構,在 WS-API 服務查詢到返回消息體的目標客戶端的 Socket ID,再有 WS-Gateway 服務進行集群消費,如果 Socket ID 不在當前節點,則需要進行節點與會話關系的查詢,找到客端戶 Socket ID 實際對應的 WS-Gateway 節點,通常有以下兩種方案:
| 優點 | 缺點 | |
|---|---|---|
| 事件廣播 | 實現簡單 | 消息廣播數量會隨著節點數量上升 |
| 注冊中心 | 會話與節點映射關系清晰 | 注冊中心強依賴,額外運維成本 |
在確定使用事件廣播方式進行網關節點間的消息傳遞后,進一步選擇使用哪種具體的消息中間件,列舉了三種待選的方案:
| 特性 | Redis | Kafka | RocKetMQ |
|---|---|---|---|
| 開發語言 | C | Scala | Java |
| 單機吞吐量 | 10w+ | 10w+ | 10w+ |
| 可用性 | 主從架構 | 分布式架構 | 分布式架構 |
| 特點 | 功能簡單 | 吞吐量、可用性極高 | 功能豐富、定制化強,吞吐量、可用性高 |
| 功能特性 | 數據 10K 以內性能優異,功能簡單,適用于簡單業務場景 | 支持核心的 MQ 功能,不支持消息查詢或消息回溯等功能 | 支持核心的 MQ 功能,擴展性強 |
于是對 Redis 和其他 MQ 中間件進行 100w 次的入隊和出隊操作,在測試過程中發現在數據小于 10K 時 Redis 性能表現十分優秀,進一步結合實際情況:廣播內容的數據量大小在 1K 左右,業務場景簡單固定,并且要兼容歷史業務邏輯,最后選擇了 Redis 進行消息廣播。
后續還可以將 WS-API 與 WS-Gateway 兩兩互聯,使用 gRPC stream 雙向流通信節省內網流量。
3.6 心跳機制
會話在節點內存與 Redis 中存儲后,客戶端需要通過心跳上報持續更新會話時間戳,客戶端按照服務端下發的周期進行心跳上報,上報時間戳首先在內存進行更新,然后再通過另外的周期進行 Redis 同步,避免大量客戶端同時進行心跳上報對 Redis 產生壓力。
- 客戶端建立 WebSocket 連接成功后,服務端下發心跳上報參數;
- 客戶端依據以上參數進行心跳包傳輸,服務端收到心跳后會更新會話時間戳;
- 客戶端其他上行數據都會觸發對應會話時間戳更新;
- 服務端定時清理超時會話,執行主動關閉流程;
- 通過 Redis 更新的時間戳數據進行 WebSocket 連接、用戶和文件之間的關系進行清理。會話數據內存以及 Redis 緩存清理邏輯:
for{
select{
case<-t.C:
????????varnow=time.Now().Unix()
varclients=make([]*Connection,0)
dispatcher.clients.Range(func(_,vinterface{})bool{
client:=v.(*Connection)
lastTs:=atomic.LoadInt64(&client.LastMessageTS)
ifnow-lastTs>int64(expireTime){
clients=append(clients,client)
}else{
dispatcher.clearRedisMapping(client.Id,client.Uid,lastTs,clearTimeout)
}
returntrue
})
for_,cli:=rangeclients{
cli.WsClose()
}
}
}
在已有的兩級緩存刷新機制上,進一步通過動態心跳上報頻率的方式降低心跳上報產生的服務端性能壓力,默認場景中客戶端對服務端進行間隔 1s 的心跳上報,假設目前單機承載了 50w 的連接數,當前的 QPS 為:QPS1 = 500000/1
從服務端性能優化的角度考慮,實現心跳正常情況下的動態間隔,每 x 次正常心跳上報,心跳間隔增加 a,增加上限為 y,動態 QPS 最小值為:QPS2=500000/y
極限情況下,心跳產生的 QPS 降低 y 倍。在單次心跳超時后服務端立刻將 a 值變為 1s 進行重試。采用以上策略,在保證連接質量的同時,降低心跳對服務端產生的性能損耗。
3.7 自定義 Headers
使用 Kafka 自定義 Headers 的目的是避免網關層出現對消息體解碼而帶來的性能損耗,客戶端 WebSocket 連接建立成功后,會進行一系列的業務操作,我們選擇將 WS-Gateway 和 WS-API 之間的操作指令和必要的參數放到 Kafka 的 Headers 中,例如通過 X-XX-Operator 為廣播,再讀取 X-XX-Guid 文件編號,對該文件內的所有用戶進行消息推送。
| 字段 | 說明 | 描述 |
|---|---|---|
| X-ID | WebSocket ID | 連接 ID |
| X-Uid | 用戶 ID | 用戶 ID |
| X-Guid | 文件 ID | 文件 ID |
| X-Inner | 網關內部操作指令 | 用戶加入、用戶退出 |
| X-Event | 網關事件 | Connect/Message/Disconnect |
| X-Locale | 語言類型設置 | 語言類型設置 |
| X-Operator | api 層操作指令 | 單播、廣播、網關內部操作 |
| X-Auth-Type | 用戶鑒權類型 | SDKV2、主站、微信、移動端、桌面 |
| X-Client-Version | 客戶端版本 | 客戶端版本 |
| X-Server-Version | 網關版本 | 服務端版本 |
| X-Push-Client-ID | 客戶端 ID | 客戶端 ID |
| X-Trace-ID | 鏈路 ID | 鏈路 ID |
在 Kafka Headers 中寫入了 trace id 和 時間戳,可以追中某條消息的完整消費鏈路以及各階段的時間消耗。
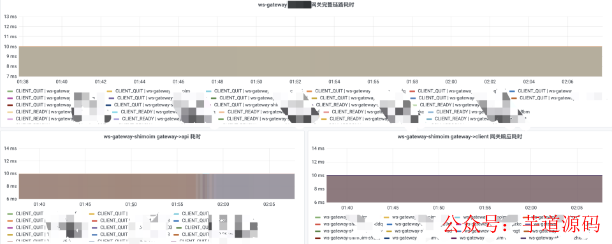
3.8 消息接收與發送
typePacketstruct{
...
}
typeConnectstruct{
*websocket.Con
sendchanPacket
}
funcNewConnect(connnet.Conn)*Connect{
c:=&Connect{
send:make(chanPacket,N),
}
goc.reader()
goc.writer()
returnc
}
客戶端與服務端的消息交互第一版的寫法類似以上寫法,對 Demo 進行壓測,發現每個 WebSocket 連接都會占用 3 個 goroutine,每個 goroutine 都需要內存棧,單機承載連十分有限,主要受制于大量的內存占用,而且大部分時間 c.writer() 是閑置狀態,于是考慮,是否只啟用 2 個 goroutine 來完成交互。
typePacketstruct{
...
}
typeConnectstruct{
*websocket.Conn
muxsync.RWMutex
}
funcNewConnect(connnet.Conn)*Connect{
c:=&Connect{
send:make(chanPacket,N),
}
goc.reader()
returnc
}
func(c*Connect)Write(data[]byte)(errerror){
c.mux.Lock()
deferc.mux.Unlock()
...
returnnil
}
保留 c.reader() 的 goroutine,如果使用輪詢方式從緩沖區讀取數據,可能會產生讀取延遲或者鎖的問題,c.writer() 操作調整為主動調用,不采用啟動 goroutine 持續監聽,降低內存消耗。
調研了 gev 和 gnet 等基于事件驅動的輕量級高性能網絡庫,實測發現在大量連接場景下可能產生的消息延遲的問題,所以沒有在生產環境下使用。
3.9 核心對象緩存
確定數據接收與發送邏輯后,網關部分的核心對象為 Connection 對象,圍繞 Connection 進行了 run、read、write、close 等函數的開發。使用 sync.pool 來緩存該對象,減輕 GC 壓力,創建連接時,通過對象資源池獲取 Connection 對象,生命周期結束之后,重置 Connection 對象后 Put 回資源池。在實際編碼中,建議封裝 GetConn()、PutConn() 函數,收斂數據初始化、對象重置等操作。
varConnectionPool=sync.Pool{
New:func()interface{}{
return&Connection{}
},
}
funcGetConn()*Connection{
cli:=ConnectionPool.Get().(*Connection)
returncli
}
funcPutConn(cli*Connection){
cli.Reset()
ConnectionPool.Put(cli)//放回連接池
}
3.10 數據傳輸過程優化
消息流轉過程中,需要考慮消息體的傳輸效率優化,采用 MessagePack 對消息體進行序列化,壓縮消息體大小。調整 MTU 值避免出現分包情況,定義 a 為探測包大小,通過如下指令,對目標服務 ip 進行 MTU 極限值探測。
ping-s{a}{ip}
a = 1400 時,實際傳輸包大小為:1428。其中 28 由 8(ICMP 回顯請求和回顯應答報文格式)和 20(IP 首部)構成。

如果 a 設置過大會導致應答超時,在實際環境包大小超過該值時會出現分包的情況。
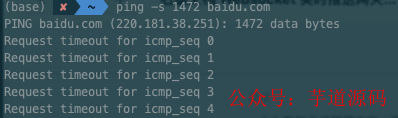
在調試合適的 MTU 值的同時通過 MessagePack 對消息體進行序列號,進一步壓縮數據包的大小,并減小 CPU 的消耗。
3.11 基礎設施支持
使用 EGO 框架( https://github.com/gotomicro/ego )進行服務開發:業務日志打印,異步日志輸出,動態日志級別調整等功能,方便線上問題排查提升日志打印效率;微服務監控體系,CPU、P99、內存、goroutine 等監控。
客戶端 Redis 監控:
客戶端 Kafka 監控:
自定義監控大盤:
4 性能壓測
4.1 壓測準備
- 選擇一臺配置為 4 核 8G 的虛擬機,作為服務機,目標承載 48w 連接;
- 選擇八臺配置為 4 核 8G 的虛擬機,作為客戶機,每臺客戶機開放 6w 個端口。
4.2 場景一
用戶上線,50w 在線用戶。
| 服務 | CPU | Memory | 數量 | CPU% | Mem% |
|---|---|---|---|---|---|
| WS-Gateway | 16 核 | 32G | 1 臺 | 22.38% | 70.59% |
單個 WS-Gateway 每秒建立連接數峰值為:1.6w 個/s,每個用戶占用內存:47K。
4.3 場景二
測試時間 15 分鐘,在線用戶 50w,每 5s 推送一條所有用戶,用戶有回執。推送內容為:
42["message",{"type":"xx","data":{"type":"xx","clients":[{"id":xx,"name":"xx","email":"[email protected]","avatar":"ZgG5kEjCkT6mZla6.png","created_at":1623811084000,"name_pinyin":"","team_id":13,"team_role":"member","merged_into":0,"team_time":1623811084000,"mobile":"+xxxx","mobile_account":"","status":1,"has_password":true,"team":null,"membership":null,"is_seat":true,"team_role_enum":3,"register_time":1623811084000,"alias":"","type":"anoymous"}],"userCount":1,"from":"ws"}}]
測試經過 5 分鐘后,服務異常重啟,重啟原因是內存使用量到超過限制。
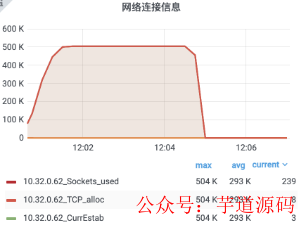
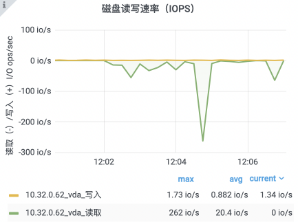
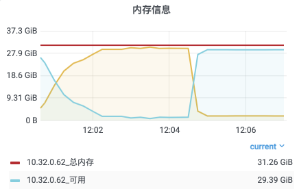
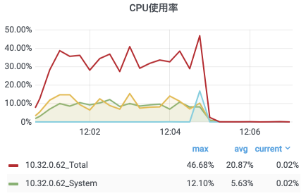
分析內存超過限制的原因:
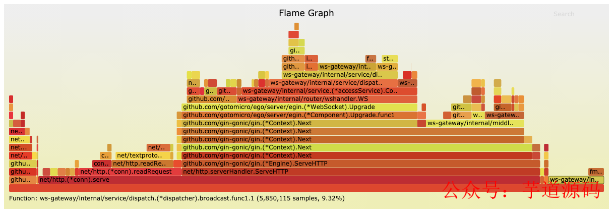
新增的廣播代碼用掉了 9.32% 的內存。
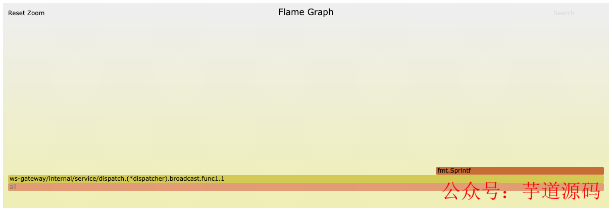
接收用戶回執消息的部分消耗了 10.38% 的內存。
進行測試規則調整,測試時間 15 分鐘,在線用戶 48w,每 5s 推送一條所有用戶,用戶有回執。推送內容為:
42["message",{"type":"xx","data":{"type":"xx","clients":[{"id":xx,"name":"xx","email":"[email protected]","avatar":"ZgG5kEjCkT6mZla6.png","created_at":1623811084000,"name_pinyin":"","team_id":13,"team_role":"member","merged_into":0,"team_time":1623811084000,"mobile":"+xxxx","mobile_account":"","status":1,"has_password":true,"team":null,"membership":null,"is_seat":true,"team_role_enum":3,"register_time":1623811084000,"alias":"","type":"anoymous"}],"userCount":1,"from":"ws"}}]
| 服務 | CPU | Memory | 數量 | CPU% | Mem% |
|---|---|---|---|---|---|
| WS-Gateway | 16 核 | 32G | 1 臺 | 44% | 91.75% |
連接數建立峰值:1w 個/s,接收數據峰值:9.6w 條/s,發送數據峰值 9.6w 條/s。
4.4 場景三
測試時間 15 分鐘,在線用戶 50w,每 5s 推送一條所有用戶,用戶無需回執。推送內容為:
["message",{"type":"xx","data":{"type":"xx","clients":[{"id":xx,"name":"xx","email":"[email protected]","avatar":"ZgG5kEjCkT6mZla6.png","created_at":1623811084000,"name_pinyin":"","team_id":13,"team_role":"member","merged_into":0,"team_time":1623811084000,"mobile":"+xxxx","mobile_account":"","status":1,"has_password":true,"team":null,"membership":null,"is_seat":true,"team_role_enum":3,"register_time":1623811084000,"alias":"","type":"anoymous"}],"userCount":1,"from":"ws"}}]
| 服務 | CPU | Memory | CPU% | Mem% | |
|---|---|---|---|---|---|
| WS-Gateway | 16 核 | 32G | 1 臺 | 30% | 93% |
連接數建立峰值:1.1w 個/s,發送數據峰值 10w 條/s,出內存占用過高之外,其他沒有異常情況。

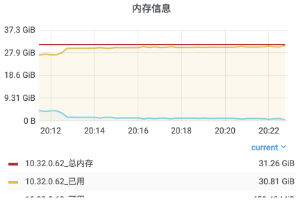
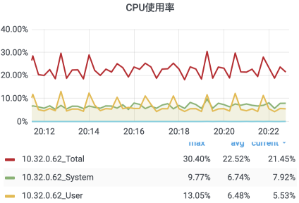
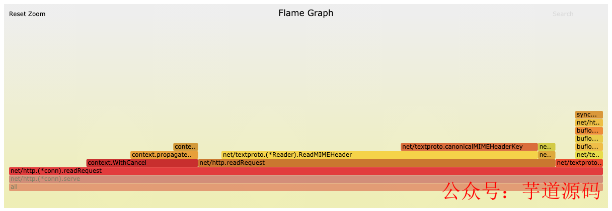
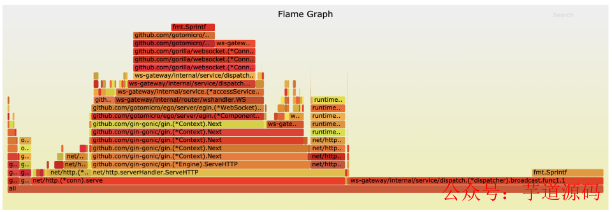
內存消耗極高,分析火焰圖,大部分消耗在定時 5s 進行廣播的操作上。
4.5 場景四
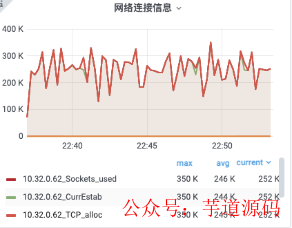
測試時間 15 分鐘,在線用戶 50w,每 5s 推送一條所有用戶,用戶有回執。每秒 4w 用戶上下線。推送內容為:
42["message",{"type":"xx","data":{"type":"xx","clients":[{"id":xx,"name":"xx","email":"[email protected]","avatar":"ZgG5kEjCkT6mZla6.png","created_at":1623811084000,"name_pinyin":"","team_id":13,"team_role":"member","merged_into":0,"team_time":1623811084000,"mobile":"+xxxx","mobile_account":"","status":1,"has_password":true,"team":null,"membership":null,"is_seat":true,"team_role_enum":3,"register_time":1623811084000,"alias":"","type":"anoymous"}],"userCount":1,"from":"ws"}}]
| 服務 | CPU | Memory | 數量 | CPU% | Mem% |
|---|---|---|---|---|---|
| WS-Gateway | 16 核 | 32G | 1 臺 | 46.96% | 65.6% |
連接數建立峰值:18570 個/s,接收數據峰值:329949 條/s,發送數據峰值 393542 條/s,未出現異常情況。
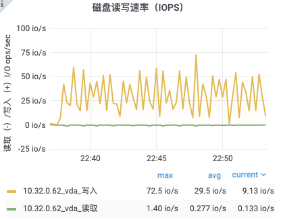
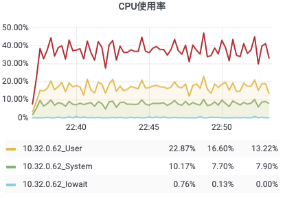
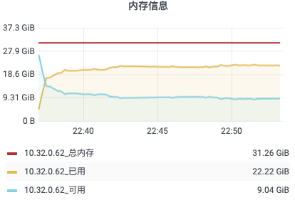
4.6 壓測總結
在 16C 32G 內存的硬件條件下,單機 50w 連接數,進行以上包括用戶上下線、消息回執等四個場景的壓測,內存和 CPU 消耗都符合預期,并且在較長時間的壓測下,服務也很穩定。滿足目前量級下的資源節約要求,可在此基礎上繼續完善功能開發。
5 總結
面臨日益增加的用戶量,網關服務的重構是勢在必行,本次重構主要是:
-
對網關服務與業務服務的解耦,移除對 Nginx 的依賴,讓整體架構更加清晰。
-
從用戶建立連接到底層業務推送消息的整體流程分析,對其中這些流程進行了具體的優化。以下各個方面讓 2.0 版本的網關有了更少的資源消耗,更低的單位用戶內存損耗、更加完善的監控報警體系,讓網關服務本身更加可靠:
- 可降級的握手流程;
- Socket ID 生產;
- 客戶端心跳處理過程的優化;
- 自定義 Headers 避免了消息解碼,強化了鏈路追蹤與監控;
- 消息的接收與發送代碼結構設計上的優化;
- 對象資源池的使用,使用緩存降低 GC 頻率;
- 消息體的序列化壓縮;
- 接入服務觀測基礎設施,保證服務穩定性。
-
在保證網關服務性能過關的同時,更進一步的是收斂底層組件服務對網關業務調用的方式,從以前的 HTTP、Redis、Kafka 等方式,統一為 gRPC 調用,保證了來源可查可控,為后續業務接入打下了更好的基礎。
-
cpu
+關注
關注
68文章
11076瀏覽量
217008 -
算法
+關注
關注
23文章
4709瀏覽量
95349 -
網關
+關注
關注
9文章
5654瀏覽量
52961
原文標題:石墨文檔Websocket百萬長連接技術實踐
文章出處:【微信號:芋道源碼,微信公眾號:芋道源碼】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Django3如何使用WebSocket實現WebShell
一文詳解WebSocket協議
鴻蒙原生應用開發-網絡管理WebSocket連接
在websocket.c RTOS演示中缺少對wifi_connect()的調用怎么辦?
人工合成石墨片與天然石墨片的差別
請問有誰做過websocket連接的?能提供一下思路嗎?
如何通過Java來使用WebSocket
什么是WebSocket?進行通信解析 WebSocket 報文及實現
Python如何爬取實時變化的WebSocket數據

如何使用SpringBoot集成Netty開發一個基于WebSocket的聊天室說明
WebSocket有什么優點
WebSocket工作原理及使用方法

websocket協議的原理
鴻蒙開發網絡管理:ohos.net.webSocket WebSocket連接





 工商網監
工商網監
評論