") Python中的默認(rèn)編碼
Python中的默認(rèn)編碼
####1. Python源代碼文件的執(zhí)行過程
我們都知道,磁盤上的文件都是以二進(jìn)制格式存放的,其中文本文件都是以某種特定編碼的字節(jié)形式存放的。對(duì)于程序源代碼文件的字符編碼是由編輯器指定的,比如我們使用Pycharm來編寫Python程序時(shí)會(huì)指定工程編碼和文件編碼為UTF-8,那么Python代碼被保存到磁盤時(shí)就會(huì)被轉(zhuǎn)換為UTF-8編碼對(duì)應(yīng)的字節(jié)(encode過程)后寫入磁盤。當(dāng)執(zhí)行Python代碼文件中的代碼時(shí),Python解釋器在讀取Python代碼文件中的字節(jié)串之后,需要將其轉(zhuǎn)換為UNICODE字符串(decode過程)之后才執(zhí)行后續(xù)操作。
上面已經(jīng)解釋過,這個(gè)轉(zhuǎn)換過程(decode,解碼)需要我們指定文件中保存的字節(jié)使用的字符編碼是什么,才能知道這些字節(jié)在UNICODE這張萬(wàn)國(guó)碼和統(tǒng)一碼中找到其對(duì)應(yīng)的代碼點(diǎn)是什么。這里指定字符編碼的方式大家都很熟悉,如下所示:
# -*- coding:utf-8 -*-
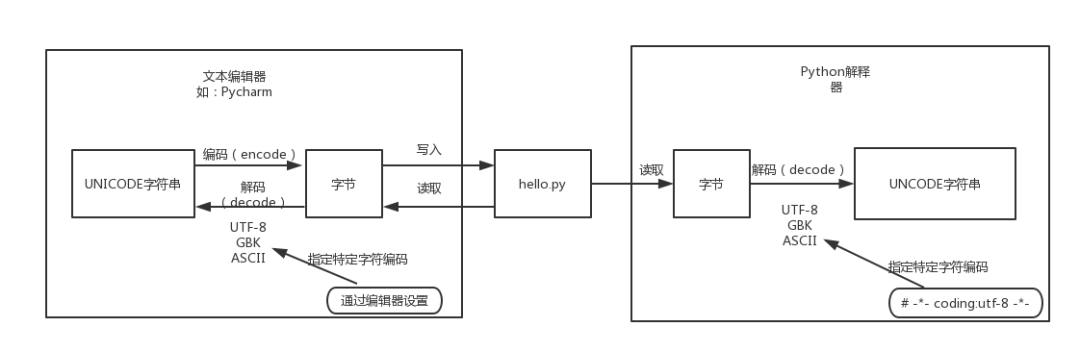
2. 默認(rèn)編碼
那么,如果我們沒有在代碼文件開始的部分指定字符編碼,Python解釋器就會(huì)使用哪種字符編碼把從代碼文件中讀取到的字節(jié)轉(zhuǎn)換為UNICODE代碼點(diǎn)呢?就像我們配置某些軟件時(shí),有很多默認(rèn)選項(xiàng)一樣,需要在Python解釋器內(nèi)部設(shè)置默認(rèn)的字符編碼來解決這個(gè)問題,這就是文章開頭所說的“默認(rèn)編碼”。因此大家所說的Python中文字符問題就可以總結(jié)為一句話: 當(dāng)無法通過默認(rèn)的字符編碼對(duì)字節(jié)進(jìn)行轉(zhuǎn)換時(shí),就會(huì)出現(xiàn)解碼錯(cuò)誤(UnicodeEncodeError) 。
Python2和Python3的解釋器使用的默認(rèn)編碼是不一樣的,我們可以通過sys.getdefaultencoding()來獲取默認(rèn)編碼:
>> > # Python2
>> > import sys
>> > sys.getdefaultencoding()
'ascii'
>> > # Python3
>> > import sys
>> > sys.getdefaultencoding()
'utf-8'
因此,對(duì)于Python2來講,Python解釋器在讀取到中文字符的字節(jié)碼嘗試解碼操作時(shí),會(huì)先查看當(dāng)前代碼文件頭部是否有指明當(dāng)前代碼文件中保存的字節(jié)碼對(duì)應(yīng)的字符編碼是什么。如果沒有指定則使用默認(rèn)字符編碼"ASCII"進(jìn)行解碼導(dǎo)致解碼失敗,導(dǎo)致如下錯(cuò)誤:
SyntaxError: Non-ASCII character '\\xc4' in file xxx.py on line 11, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
對(duì)于Python3來講,執(zhí)行過程是一樣的,只是Python3的解釋器以"UTF-8"作為默認(rèn)編碼,但是這并不表示可以完全兼容中文問題。比如我們?cè)赪indows上進(jìn)行開發(fā)時(shí),Python工程及代碼文件都使用的是默認(rèn)的GBK編碼,也就是說Python代碼文件是被轉(zhuǎn)換成GBK格式的字節(jié)碼保存到磁盤中的。Python3的解釋器執(zhí)行該代碼文件時(shí),試圖用UTF-8進(jìn)行解碼操作時(shí),同樣會(huì)解碼失敗,導(dǎo)致如下錯(cuò)誤:
SyntaxError: Non-UTF-8 code starting with '\\xc4' in file xxx.py on line 11, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
3. 最佳實(shí)踐
- 創(chuàng)建一個(gè)工程之后先確認(rèn)該工程的字符編碼是否已經(jīng)設(shè)置為UTF-8
- 為了兼容Python2和Python3,在代碼頭部聲明字符編碼:
-*- coding:utf-8 -*-
-
編碼
+關(guān)注
關(guān)注
6文章
967瀏覽量
55509 -
python
+關(guān)注
關(guān)注
56文章
4825瀏覽量
86225
發(fā)布評(píng)論請(qǐng)先 登錄
Python中文亂碼怎么處理?python中文亂碼解決辦法
python默認(rèn)的解釋器并不支持tab補(bǔ)全
從5個(gè)方面來解析計(jì)算機(jī)中的字符編碼概念

從RHEL 8 Beta開始不再默認(rèn)系統(tǒng)Python版本
Python的編碼規(guī)范是怎么樣的

科普:Python函數(shù)默認(rèn)返回 None 的原因
Python 函數(shù)默認(rèn)返回None的原因
Python中最基本的10個(gè)內(nèi)容
如何在Ubuntu中安裝IDLE Python IDE
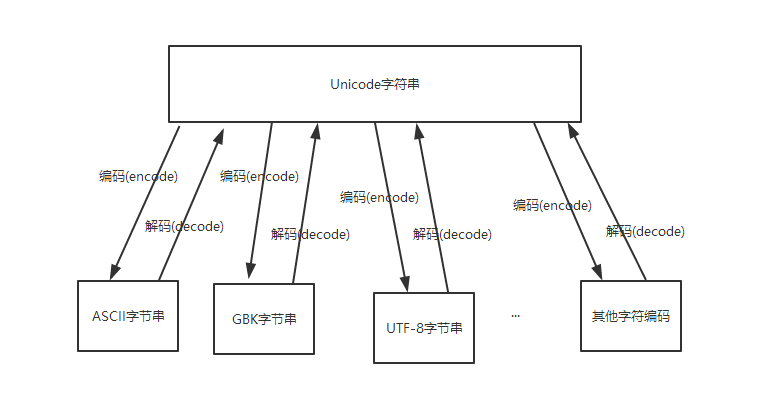
Python編碼與解碼
Python2與Python3中對(duì)字符串的支持
Python字符編碼轉(zhuǎn)換





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論