") Python編碼與解碼
Python編碼與解碼
先做下科普:UNICODE字符編碼,也是一張字符與數(shù)字的映射,但是這里的數(shù)字被稱為代碼點(diǎn)(code point), 實(shí)際上就是十六進(jìn)制的數(shù)字。
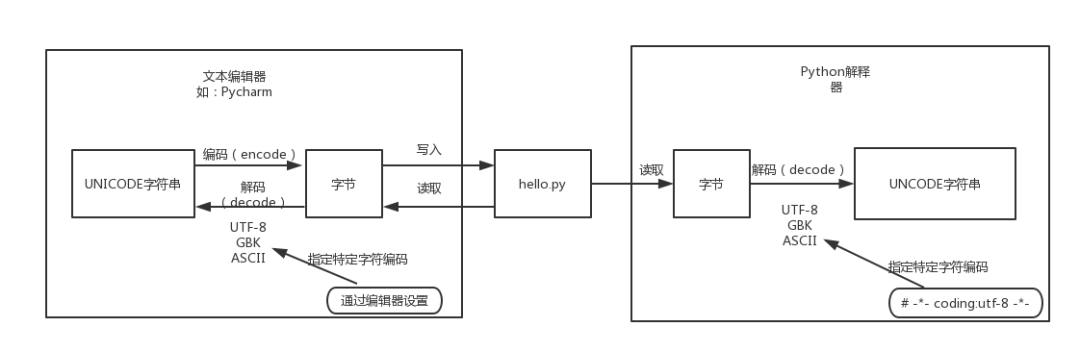
Python官方文檔中對Unicode字符串、字節(jié)串與編碼之間的關(guān)系有這樣一段描述:
Unicode字符串是一個(gè)代碼點(diǎn)(code point)序列,代碼點(diǎn)取值范圍為0到0x10FFFF(對應(yīng)的十進(jìn)制為1114111)。這個(gè)代碼點(diǎn)序列在存儲(包括內(nèi)存和物理磁盤)中需要被表示為一組字節(jié)(0到255之間的值),而將Unicode字符串轉(zhuǎn)換為字節(jié)序列的規(guī)則稱為編碼。
這里說的編碼不是指字符編碼,而是指編碼的過程以及這個(gè)過程中所使用到的Unicode字符的代碼點(diǎn)與字節(jié)的映射規(guī)則。這個(gè)映射不必是簡單的一對一映射,因此編碼過程也不必處理每個(gè)可能的Unicode字符,例如:
將Unicode字符串轉(zhuǎn)換為ASCII編碼的規(guī)則很簡單--對于每個(gè)代碼點(diǎn):
如果代碼點(diǎn)數(shù)值《128,則每個(gè)字節(jié)與代碼點(diǎn)的值相同
如果代碼點(diǎn)數(shù)值》=128,則Unicode字符串無法在此編碼中進(jìn)行表示(這種情況下,Python會引發(fā)一個(gè)UnicodeEncodeError異常)
將Unicode字符串轉(zhuǎn)換為UTF-8編碼使用以下規(guī)則:
如果代碼點(diǎn)數(shù)值《128,則由相應(yīng)的字節(jié)值表示(與Unicode轉(zhuǎn)ASCII字節(jié)一樣)
如果代碼點(diǎn)數(shù)值》=128,則將其轉(zhuǎn)換為一個(gè)2個(gè)字節(jié),3個(gè)字節(jié)或4個(gè)字節(jié)的序列,該序列中的每個(gè)字節(jié)都在128到255之間。
簡單總結(jié):
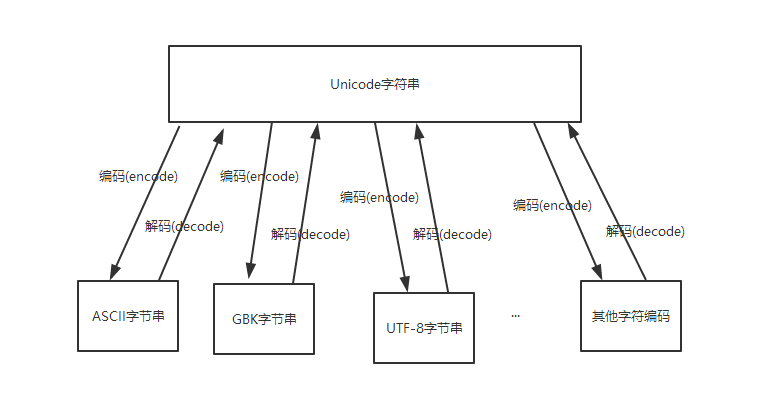
編碼(encode):將Unicode字符串(中的代碼點(diǎn))轉(zhuǎn)換特定字符編碼對應(yīng)的字節(jié)串的過程和規(guī)則
解碼(decode):將特定字符編碼的字節(jié)串轉(zhuǎn)換為對應(yīng)的Unicode字符串(中的代碼點(diǎn))的過程和規(guī)則
可見,無論是編碼還是解碼,都需要一個(gè)重要因素,就是特定的字符編碼。因?yàn)橐粋€(gè)字符用不同的字符編碼進(jìn)行編碼后的字節(jié)值以及字節(jié)個(gè)數(shù)大部分情況下是不同的,反之亦然。
-
編碼
+關(guān)注
關(guān)注
6文章
967瀏覽量
55496 -
python
+關(guān)注
關(guān)注
56文章
4825瀏覽量
86181
發(fā)布評論請先 登錄
正交編碼解碼原理及解碼思路
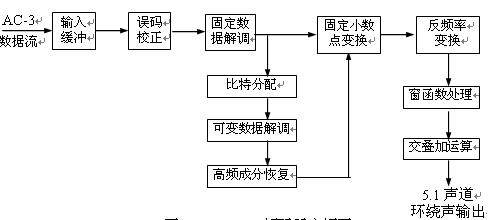
什么是音頻的編碼和解碼/HZ(赫茲)
短信編碼與解碼C語言
java實(shí)現(xiàn)的哈夫曼編碼與解碼

NVIDIA推出適用于Python的VPF,簡化開發(fā)GPU加速視頻編碼/解碼
STM32的音頻編碼與在PC端的解碼

基于transformer的編碼器-解碼器模型的工作原理
Python中的默認(rèn)編碼
Python字符編碼轉(zhuǎn)換
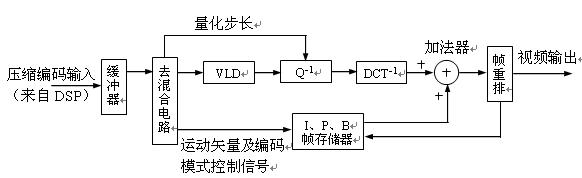
DVEVM/DVSDK 1.2的編碼解碼演示





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論