") 面向結(jié)構(gòu)化數(shù)據(jù)的文本生成技術(shù)研究
面向結(jié)構(gòu)化數(shù)據(jù)的文本生成技術(shù)研究
導讀今天討論的是面向結(jié)構(gòu)化數(shù)據(jù)的文本生成技術(shù)研究,這是現(xiàn)在AIGC特別火的場景之一。這種技術(shù)不同于傳統(tǒng)的文本生成,它的輸入是一種比較特殊的結(jié)構(gòu),比如幾百條不同的三元組或者很多種數(shù)字的信息。在使用傳統(tǒng)的ChatGPT時,我們可以通過做一些摘要任務、翻譯任務等來隨意提出問題,但是對于結(jié)構(gòu)化數(shù)據(jù),它需要更高的生成能力,因為它包含了更多的信息。因此,我們今天選擇這個主題來給大家講解。
01
文本生成介紹
首先介紹一下現(xiàn)階段熱門的文本生成。
1.人工智能的發(fā)展階段
人工智能的發(fā)展經(jīng)歷了許多次的突破。早期,李世石下棋戰(zhàn)勝了電腦,但后來又輸給了AlphaGo,這拉開了人工智能快速發(fā)展的序幕。之后,無人車的感知智能以及能看會讀的人工智能模型也受到了很多資本的青睞。近幾個月來,以ChatGPT、GPT-4以及文心一言為首的對話式人工智能模型受到了巨大的關(guān)注,甚至被認為是一種認知智能。它基本上可以對人的問題以及意圖達到90%以上的理解能力,并且能根據(jù)意圖很好地生成你所要的文本。這被認為是當前最核心的一種前沿技術(shù)之一,這種方式通過大量無監(jiān)督的學習再加上和人的對齊,實現(xiàn)了一種通用人工智能。經(jīng)過不斷的發(fā)展,人工智能技術(shù)水平也在不斷提高。
2.文本生成概念

今天我們要講的文本生成是現(xiàn)在最流行的研究領(lǐng)域之一。文本生成的目標是讓計算機像人類一樣學會表達,目前看基本上接近實現(xiàn)。這些突然的技術(shù)涌現(xiàn),使得計算機能夠撰寫出高質(zhì)量的自然文本,滿足特定的需求。典型的一些任務有文本到文本的生成,例如傳統(tǒng)的摘要、翻譯以及回答等。除了傳統(tǒng)的文本生成,還有一種輸入結(jié)構(gòu)化數(shù)據(jù)的生成,例如天氣預報、比賽數(shù)據(jù)以及傳感器數(shù)據(jù)等。雖然這些數(shù)據(jù)以結(jié)構(gòu)化數(shù)據(jù)的形式進行存儲,但并不便于人們?nèi)ダ斫饣蛘哒业狡渲械奶攸c。因此,希望能通過文本的形式更易于閱讀或者理解。另外,最近混合模態(tài)的生成已經(jīng)得到了突破,輸入圖像或者視頻可以對應輸出相關(guān)的文本。這些是之前文本生成領(lǐng)域主要做的一些研究。
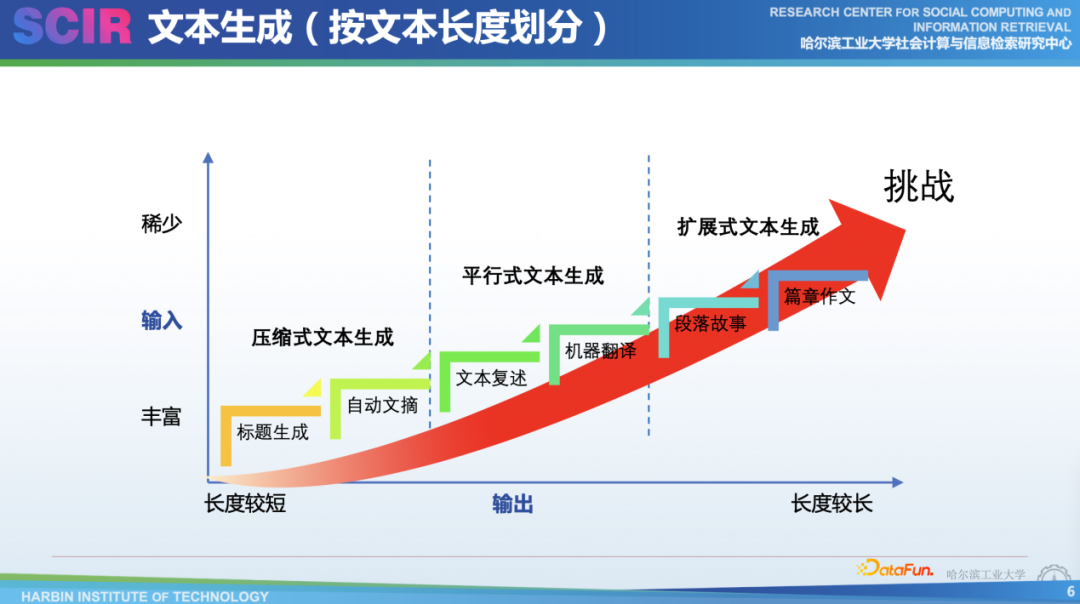
如果不考慮不同的模態(tài),它實際上是按照輸入的長短來生成的。起初我們常常用它來做一些比較簡單的任務,比如壓縮式的文本生成。輸入比較長,而輸出比較短,比如只有簡單的標題或者100多個字符的摘要。再之后,還有一種平行式的文本生成,比如我們來復述一句話或者潤色一句話。機器翻譯也是典型的平行式文本生成任務,只是我們會控制它用不同的語言來進行生成。其次,還有一種比較有挑戰(zhàn)性的擴展式的文本生成。比如,提供一個意圖生成篇章級文本,我們可以讓ChatGPT和GPT-4寫出好故事,甚至,它可以寫一些比較好的報告。我們認為,隨著輸入輸出比的不斷變化,讓它的挑戰(zhàn)也變得更多,因為隨著文本的輸出更長,它所要遵循的邏輯、層次以及其內(nèi)部本身文本上有一些退化問題,都更具挑戰(zhàn)。
3.文本生成模型
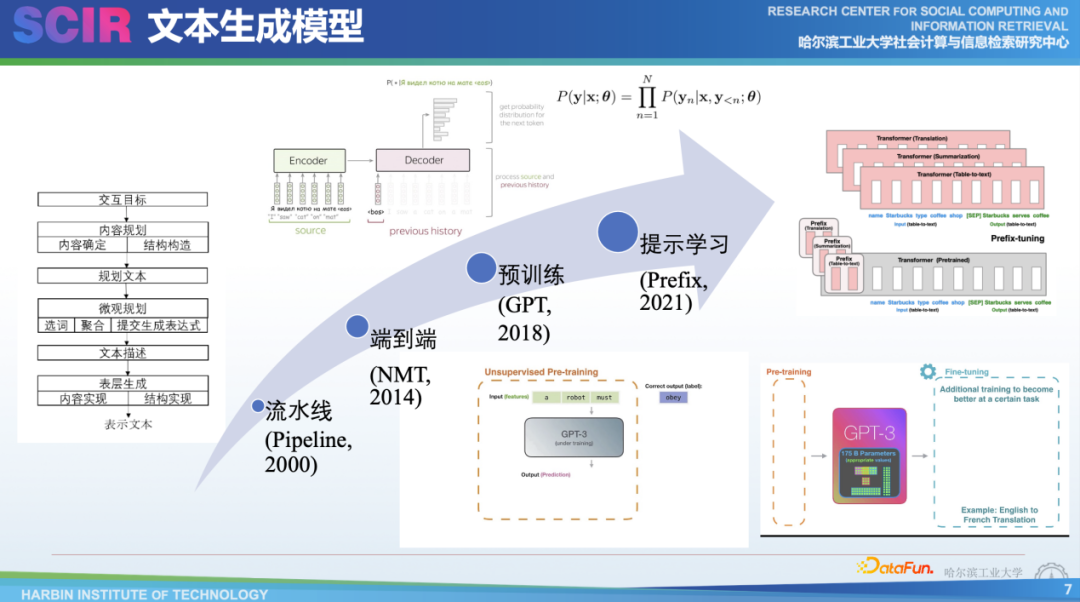
技術(shù)層面,最早在2000年前后,生成方式采用的是所謂pipeline流水線的方式。它通過目標任務來找到寫作對應的一些詞單元,把這些單元和詞進行規(guī)劃、排序,再把每個單元合并成句子,最后再套入模板中,這是很復雜的流水線過程。
在2014年,我們采用了一種端到端的編碼器解碼器的方式,也就是基于深度學習的方式,典型的任務是機器翻譯,比如我們把每個詞變成向量,輸入到神經(jīng)網(wǎng)絡里面,就可以把向量進行編碼。最后傳給解碼器進行解碼,每次解碼的時候,它實際上是從很大的幾萬個詞表中選取概率最大的詞作為當前的輸出。這種方式在機器翻譯領(lǐng)域或者當時的文本摘要任務上非常成功。
后來在2018年,人工智能領(lǐng)域又發(fā)生了一次變革,這次變革中出現(xiàn)了預訓練模型的方法,比較典型的有三個不同的模型:GPT-1、GPT-2、GPT-3。這三個模型在使用時,像GPT-1和GPT-2這樣的小模型通常采用微調(diào)的范式,即讓其提前學習海量的文本和知識,并在小規(guī)模數(shù)據(jù)上進行調(diào)優(yōu),以便更好地適應下游任務。當預訓練模型的規(guī)模變得非常大時,很難對模型內(nèi)的參數(shù)進行finefune,這時就通過提示學習的方式,為不同的任務設(shè)計不同的表示,以引導模型輸出想要的內(nèi)容。最新的方法被稱為instruct tuning(指令微調(diào)),它不需要改變預訓練模型,也不需要為每個任務學習專門的特征或表示,只需利用所有的自然語言文本即可。
4.文本生成技術(shù)
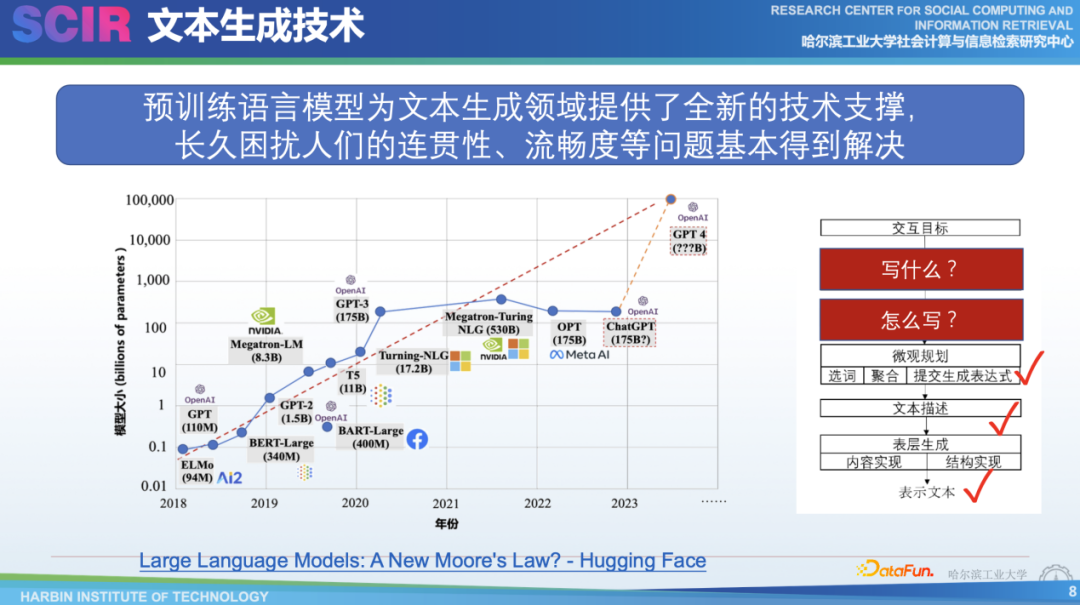
隨著預訓練模型的發(fā)展,其規(guī)模呈現(xiàn)出指數(shù)級的增長。目前,比較大的預訓練模型有Megatron- Turning和 OPT,它們分別來自于Nvidia和Meta。目前我們不知道ChatGPT相比于GPT-3在模型大小上的區(qū)別,也不確定GPT-4是達到了十萬億的參數(shù)還是像GPT-3一樣保持相對較小的規(guī)模。隨著新的預訓練語言模型的不斷提出,它們改變了我們基于傳統(tǒng)pipeline學習的文本生成方法,這些新的模型能夠解決過去在連貫性等方面所遇到的問題,例如微觀規(guī)劃。它們在詞的使用、詞的表達以及句子合成方面都更加流暢自然,讓人感覺與真人寫作的差別不大,甚至有時更好。現(xiàn)在,我們更關(guān)注的是如何圍繞輸入的內(nèi)容來寫作,以及如何寫作。這些問題值得我們作為文本生成研究者去思考。
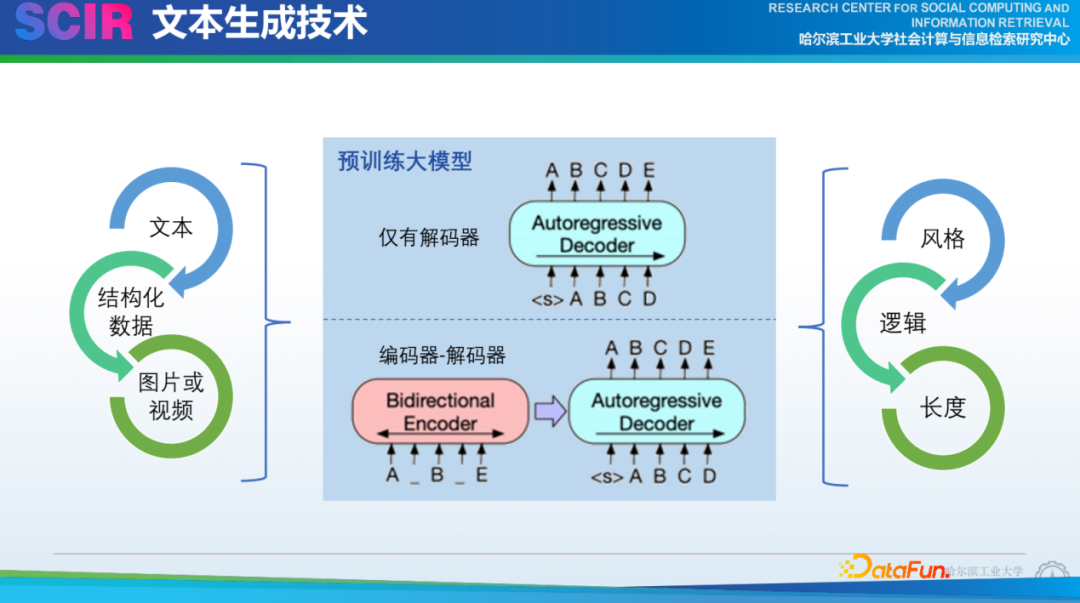
一方面我們主要圍繞不同的編碼器,如編碼文本、結(jié)構(gòu)化數(shù)據(jù)(如表格)、圖像等,但GPT-4的多模態(tài)能力給這種任務帶來了巨大的沖擊。解碼會有不同的風格,例如,ChatGPT可以很好地生成一首李白風格的詩,雖然有可能存在一些事實性的問題。另外在寫長文本時,我們需要關(guān)注邏輯、主題、重復性等,也需要控制長度。這些問題在ChatGPT之前就經(jīng)常被討論,但未來在具體實現(xiàn)方式上仍需深入研究。
02面向結(jié)構(gòu)化數(shù)據(jù)的文本生成
接下來,將討論面向結(jié)構(gòu)化數(shù)據(jù)的文本生成。
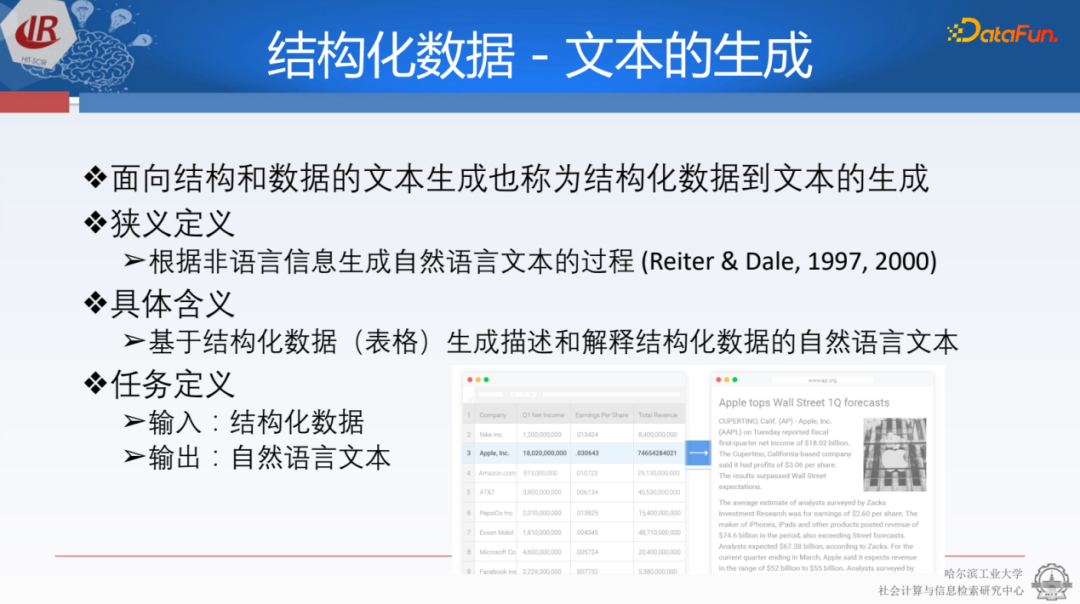
狹義上,這種生成任務是根據(jù)非語言結(jié)構(gòu)信息生成自然語言文本的過程,這意味著只要輸入不是自然語言,都可以屬于這類范疇。具體地我們可以輸入表格,如財務報表,然后把它們生成為簡單的報表,使人們更容易理解。這與AIGC非常相似,它可以賦能企業(yè)自動寫作的場景,減輕企業(yè)用戶在撰寫報告方面的成本。整個任務的定義輸入是結(jié)構(gòu)化數(shù)據(jù),可以看作是知識圖譜中的三元組,包括不同的節(jié)點,例如數(shù)字和實體等。輸出則為自然語言文本,這可以被用來生成結(jié)構(gòu)化數(shù)據(jù)的文本。

這種技術(shù)的應用也有著重要意義。知識圖譜的價值在于它更易于計算機理解,但不太便于人類理解,因此需要將結(jié)構(gòu)化數(shù)據(jù)轉(zhuǎn)化為人類易于理解的文本。例如,當播報天氣預報時,不能簡單地說出“溫度-32度-哈爾濱”,而應該將其轉(zhuǎn)化為易于理解的文本形式。另外,在撰寫賽事報道時,原始的輸入數(shù)據(jù)以三元組的形式存儲在Excel表格或其它數(shù)據(jù)庫中,之前需要編輯去寫作,而現(xiàn)在騰訊、新浪等一些新聞網(wǎng)站已經(jīng)可以通過自動化的方式將其轉(zhuǎn)化為易于理解的文本。另外,我們做了很多種柱狀圖或者是餅圖,其背后的原理都是一種三元組,可以把這種三元組都轉(zhuǎn)化成文本的形式,便于大家去閱讀和理解。

具體的場景,例如輸入體育比賽這種相對復雜一點的結(jié)構(gòu)化表格,輸出一篇報道。隨著ChatGPT或者GPT-4的出現(xiàn),自動化生產(chǎn)文本的能力得到了很大的提升,未來很多文本都會用這種技術(shù)來做。我們可以把它看成簡單的實體存儲的描述,用這種方式來播報它的具體內(nèi)容,以便于人們理解。還可以把不同區(qū)域的經(jīng)濟數(shù)值轉(zhuǎn)換成財報,這對很多銀行或者金融保險企業(yè)來說很重要,因為他們需要實時了解各地方的情況。還可以通過一些好的生成方法讓它自動挖掘出一些風險點,或者是誰的業(yè)績比較好等信息。

上圖中列舉了一些之前國內(nèi)以及國外比較典型的生成系統(tǒng),其中包括國內(nèi)的新華社推出的快筆小新、阿里巴巴等。還有國外的一些種初創(chuàng)公司,獲得了很多的關(guān)注,比如美國明星企業(yè)Narrative Science、Automated Insights等,但是目前這種企業(yè)在ChatGPT和GPT-4的沖擊下具體情況還未可知。
這里也羅列一些近20年來自然語言處理領(lǐng)域中的典型任務。最早有數(shù)據(jù)支撐的任務是在2009年,涉及天氣預報數(shù)據(jù)集。2016年,出現(xiàn)了描述人物的維基百科任務,可以看作是簡單圖譜的分支。隨后在2017年,開始研究餐館的描述,例如給美團每個餐館打上廣告。此外,還有一些更偏向推理的任務,如棒球比賽等。在2020年之后,基于推理、事實一致性和數(shù)值計算成為更受關(guān)注的方向。事實一致性最早出現(xiàn)在結(jié)構(gòu)化數(shù)據(jù)文本生成中,目前也被認為是ChatGPT沒有解決的最核心的問題。而針對如何解決事實不一致性問題,領(lǐng)域相關(guān)工作者可以進一步深入研究。
最后再說一下該任務的意義。它可以很好地提升我們工作的效率,幫助用戶理解離散的數(shù)據(jù)并進行正確的決策。面向結(jié)構(gòu)化數(shù)據(jù),未來我們可以把不同的圖像如餅圖、線圖等轉(zhuǎn)化為文字的形式,有廣泛的應用空間。實際上,GPT-4采用的策略不一定是三元組的存儲,而是采用一種視覺的方式。
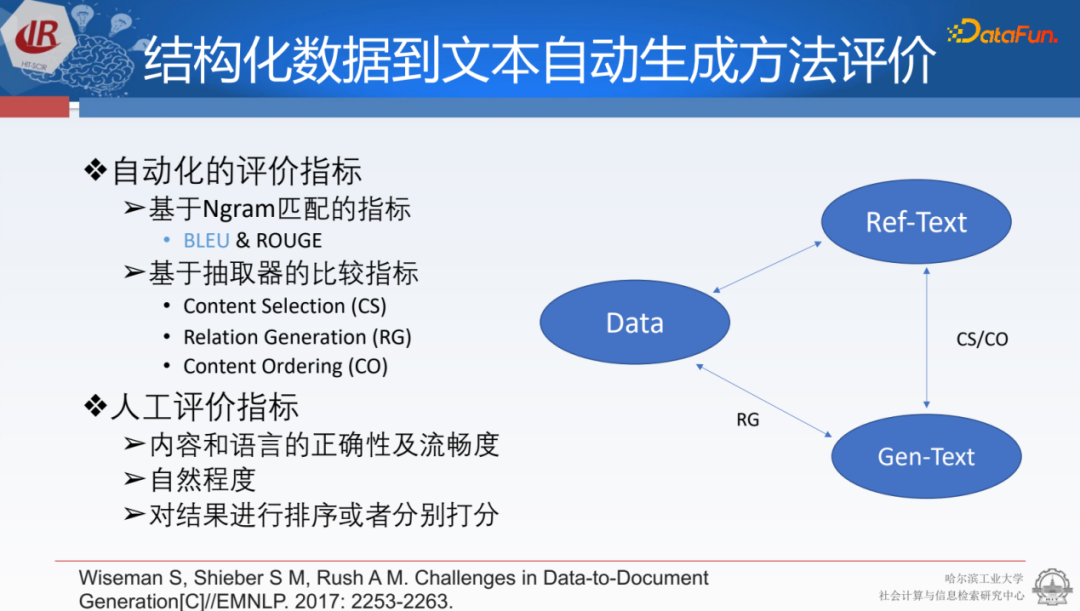
結(jié)構(gòu)化數(shù)據(jù)文本生成,與傳統(tǒng)的文本生成在評價指標上有一些不同。傳統(tǒng)的文本生成有經(jīng)典的評價指標,如BLEU和ROUGE。在結(jié)構(gòu)化數(shù)據(jù)上,更加關(guān)注抽取的三元組內(nèi)容(content Selection),以及所寫的內(nèi)容和原本輸入的結(jié)構(gòu)化表格是否對應(Relation Generation),內(nèi)容的順序是否一致(Content Ordering)。它構(gòu)建了一些自己的打分方法,同時還會用一些經(jīng)典的人工評價來指導或說明生成系統(tǒng)的好壞。

接下來介紹主要的技術(shù)架構(gòu):
最早期是使用pipeline的方式,研究了傳統(tǒng)的內(nèi)容規(guī)劃,通過決定哪些內(nèi)容是三元組來進行選擇,然后將這些三元組放到有序的條件下,最后將它們進行文字模板的嵌套生成最終的結(jié)果。這種方法的好處是易于控制,因為你了解其中每一步背后的含義,并且可以進行改進。但缺點是需要人為地從中寫入一些特征,并且存在錯誤傳播的現(xiàn)象。
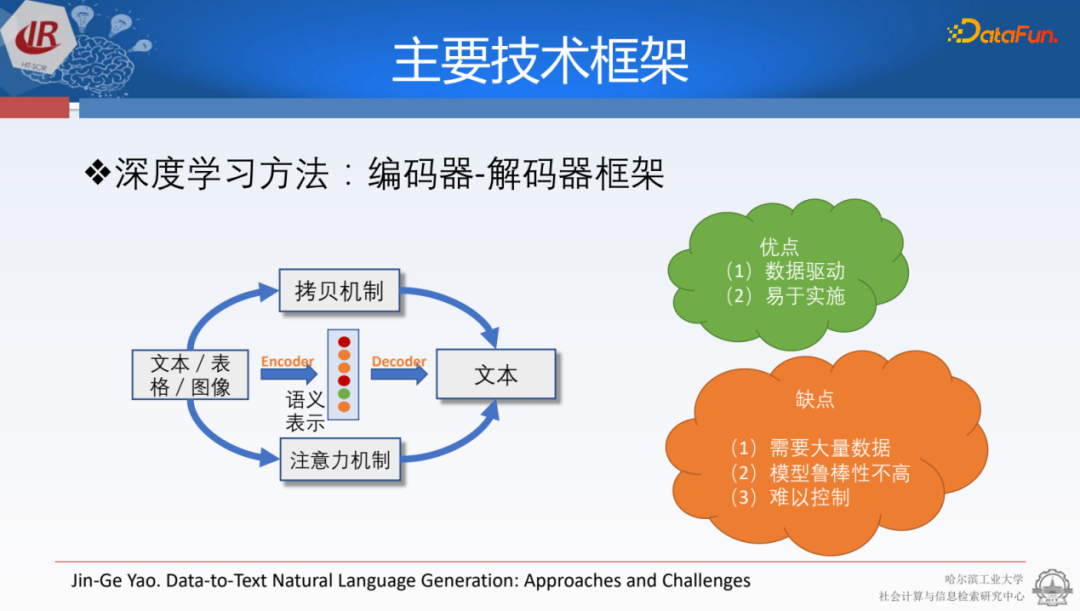
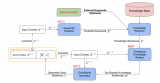
之后采用了基于深度學習的方法,通過編碼器-解碼器來生成文本。其中編碼器是面向于結(jié)構(gòu)化數(shù)據(jù)特殊設(shè)計的一種層次化的編碼器。通過解碼器加上注意力文本和拷貝文本,我們就能生成想要的合適的輸出。這種方法的好處是可以通過數(shù)據(jù)驅(qū)動的方式實施,只要收集足夠多的數(shù)據(jù),就可以得到比較好的生成文本。但是它的問題是可解釋性比較強,難以針對某個錯誤進行控制。

很多人認為隨著ChatGPT的出現(xiàn),整個NLP或NLG領(lǐng)域就不存在了。事實上,我們?nèi)钥吹綄τ谝恍┓浅碗s的結(jié)構(gòu)化表格,在建模能力方面它并沒有我們想象的那樣強大。首先,我們把整個表格以三組的形式或者以json的形式輸入到ChatGPT,這里它犯了一些錯誤,后面會講到如何解決。
首先,在講分數(shù)時選擇或者生成了錯誤的數(shù)據(jù),犯了事實不一致的問題。例如,它提到國王和布魯克林的比分是99比90,但實際上應該是107比99。
第二,它對大小的認知程度不夠。例如,它寫到球隊中最高分的球員得了24分,但實際上我們在表格中看到有人得了更高的25分。盡管ChatGPT經(jīng)過了很多輪的更新,但這種選擇性錯誤和不符合邏輯的表達表明它在數(shù)字的理解方面仍然很薄弱。
03目前主要挑戰(zhàn)
接下來介紹目前的主要挑戰(zhàn),也是我們所研究的主要內(nèi)容。

我們希望能夠?qū)o定樣式的表格,能夠比較好地顯示它的結(jié)果。然而,結(jié)果是當前比較困難的,例如與其它數(shù)據(jù)集相比,這個賽事表格有600多個不同的單元和三元組。它使用的長度也很長,因此無法將所有信息都輸進去。我們需要解決如何選擇合理的結(jié)構(gòu)化信息或單元來進行描寫,以及如何更好地表示數(shù)字的大小,使其能夠合理地輸出。例如很多情況不一定是完全要遵照表格數(shù)據(jù),有時需要呈現(xiàn)兩個隊的比分以及分差,需要通過計算器計算的結(jié)果,這是任務本身不具備的能力。此外,還有一些風格的控制,例如每個人寫的新聞報道都有自己的風格,我們是否能夠通過參考之前報道的風格來寫整個內(nèi)容。這些都是我們關(guān)于內(nèi)容上不同方面的研究。
1.內(nèi)容選擇
對于ChatGPT來說,其輸入通常是文本,是典型的序列化輸入,只有上下文。但對于結(jié)構(gòu)化的表格來說,每一列和每一行之間都存在典型的相關(guān)性。例如,一列可以代表當前球隊誰得分最高,一行可以顯示有多少個得分,籃板和助攻等特殊信息,是否拿到了兩雙或三雙等等。同時,我們需要考慮一些球隊的歷史信息,比如球隊表現(xiàn)的差異等。因此,我們需要解決如何更好地表示這些信息。
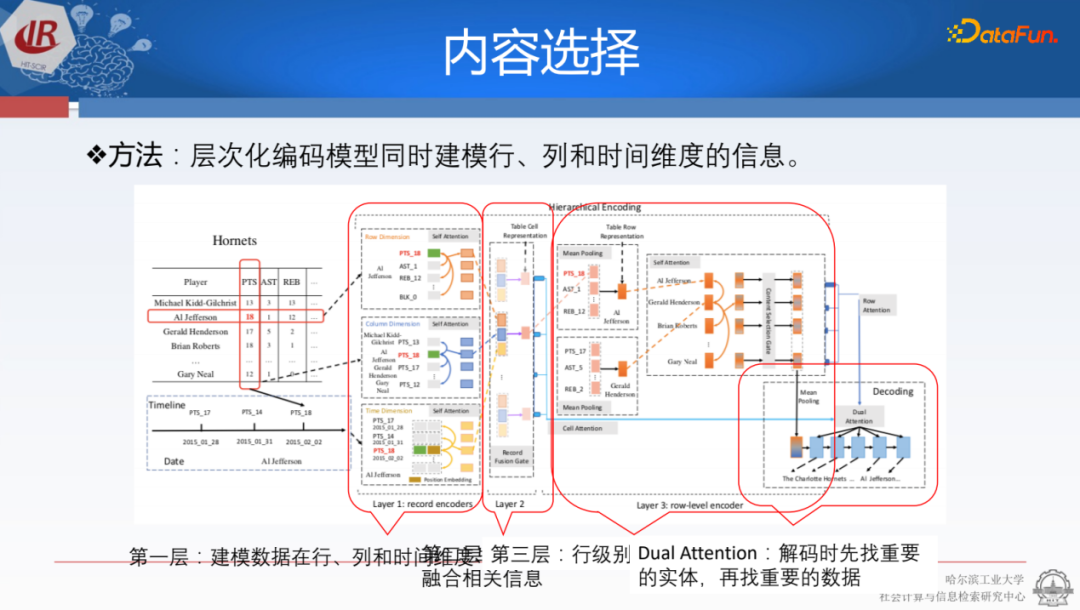
對此,研究人員進行了一種層次化的建模,首先使用行的編碼器來確定各項數(shù)值之間的比較,同時使用列的編碼器來整合不同維度的信息,以及用不同的三元組來建模人物整體的表示,判斷是否應該被選擇出來。
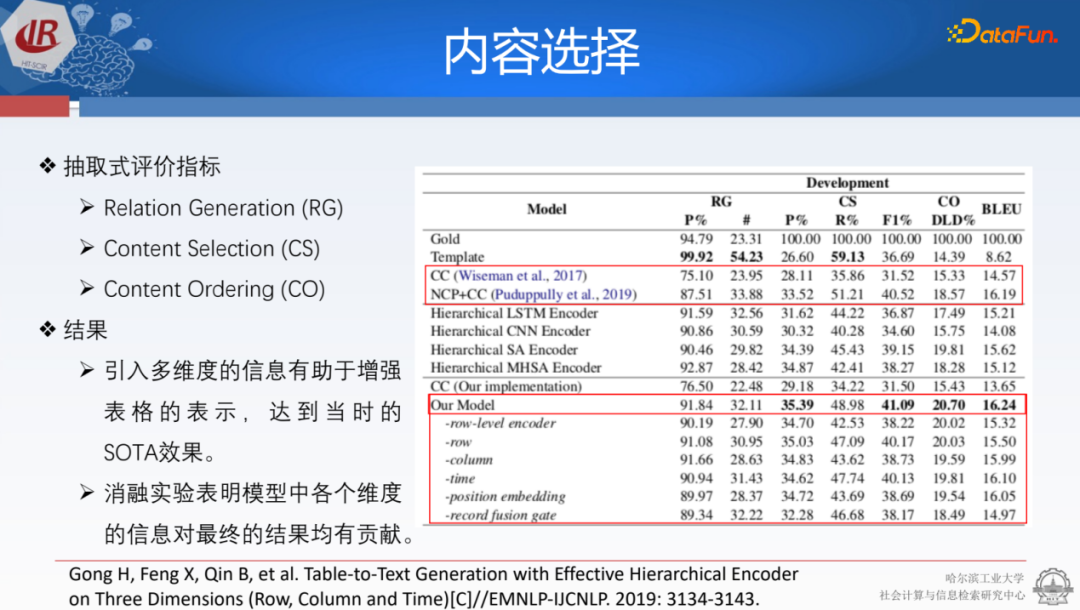
基于之前提到的RG、CS、CO評估指標,效果很明顯,且在各個指標上都達到了最優(yōu)效果。這種層次化的方式實際上也是比較符合結(jié)構(gòu)化數(shù)據(jù)的,但是剛才跟ChatGPT做對比的時候,實際上是把它當作一種json模式在用。
2.數(shù)字表示
如何讓模型更好地學習數(shù)字表示,我們發(fā)現(xiàn)ChatGPT在選擇數(shù)字大小時會出現(xiàn)錯誤,因此需要將數(shù)字大小的信息嵌入到寫作過程中,這是非常核心的內(nèi)容。由于ChatGPT是典型地根據(jù)概率去建模生成內(nèi)容,即本質(zhì)上是0/1問題,兩者存在不一致性,這導致ChatGPT在數(shù)值問題上建模能力稍有欠缺。
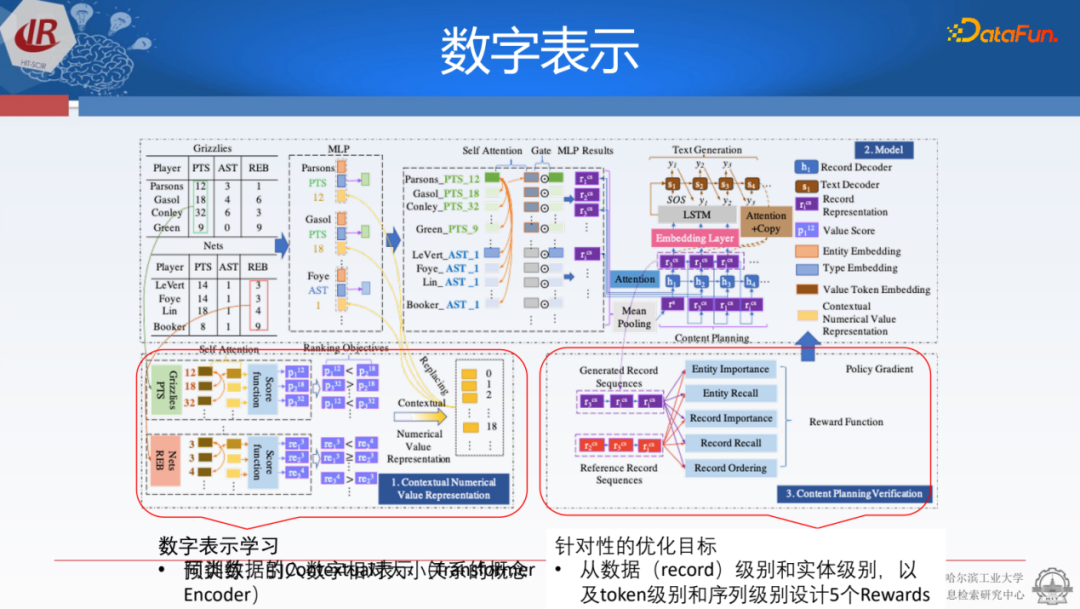
我們嘗試將數(shù)值之間的大小關(guān)系轉(zhuǎn)化為模型中的表示,以便比較大小關(guān)系。我們獲取同類型的content表示,并將比較信息嵌入到數(shù)字表示過程中。這樣,在理解表格和結(jié)構(gòu)化信息時就可以更加準確,這相當于在預訓練過程中學習了數(shù)字大小比較能力。其次,在建模每個三元組時,我們會設(shè)計多維度的reward,以提升模型選擇內(nèi)容的能力。
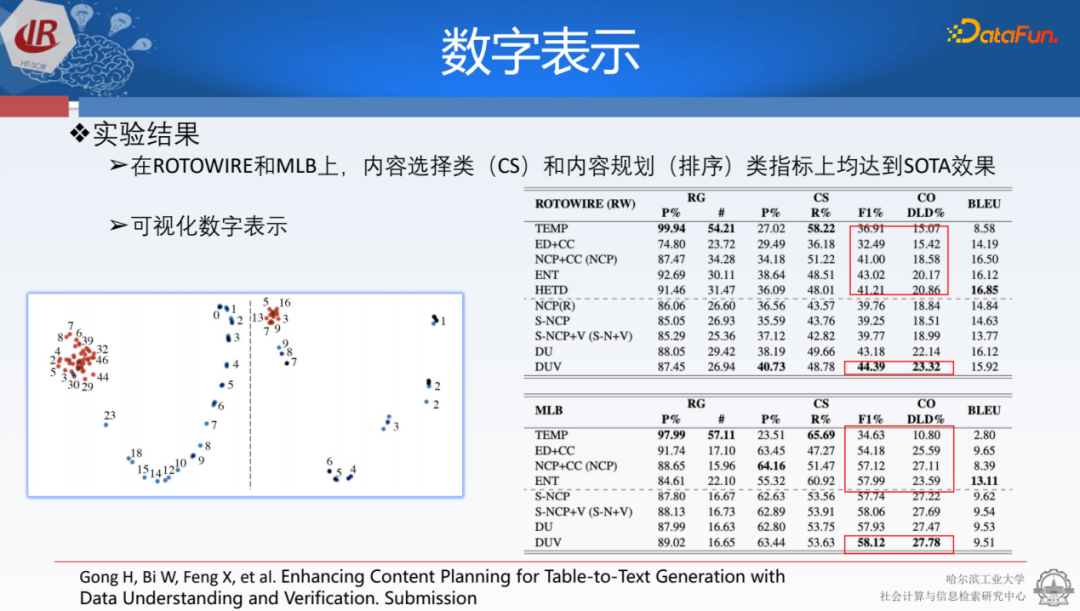
最后新的方法在結(jié)果上也獲得了很好的性能。其中一個值得探索的問題是,我們是否加入了數(shù)字大小的能力。我們在不同的比賽或數(shù)據(jù)上做了二維空間映射的對比實驗,其中紅色表示之前的建模方法,藍色表示加入數(shù)字大小后的方法。結(jié)果顯示,加入數(shù)字大小后,模型的不同維度表示之間呈現(xiàn)出典型的線性關(guān)系,這樣就能更好地拉寬不同數(shù)字之間的屬性或表示的性質(zhì),從而更好地選擇要生成的內(nèi)容。
3.數(shù)值推理
另外,我們也希望模型能在數(shù)值推理時能夠合理地推出原始表中沒有出現(xiàn)的信息,并根據(jù)這些信息給出總結(jié)性或分析性的結(jié)論。以賽事表格為例,表格中除了有像107代表一隊的總分,103代表另一隊的總分的信息之外,還有很多數(shù)字是與原始表格里不匹配的,比如有兩個球員一起合作得到了9分,還有兩隊有4分的差別,差距對應的是險勝。這些信息實際上從原始的表格是得不到的,需要對數(shù)字內(nèi)容實現(xiàn)推理來計算。
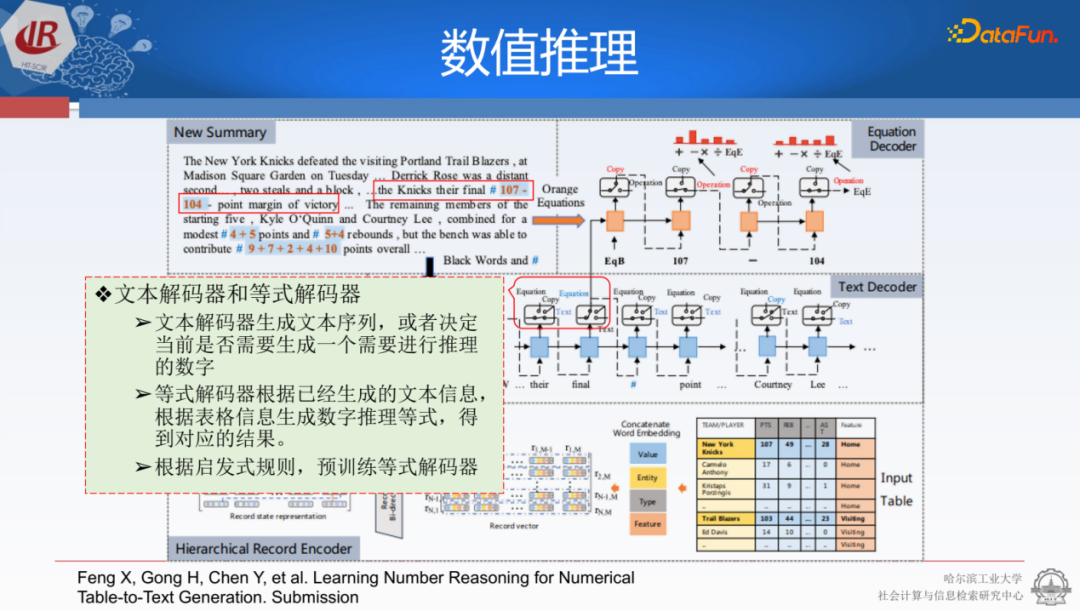
在生成過程中可以采用一種填槽的方式。我們采用了雙解碼器的策略。除了文本解碼器外,還可以建模表格中的實體、類型和分數(shù),使用三元組的方式將其結(jié)構(gòu)化。在解碼文本時,除了解碼文本本身外,我們還會使用關(guān)鍵的槽位。這些槽位類似于觸發(fā)器或gate。當槽位被啟動時,就會引入公式的計算。我們嘗試用這種方式讓它解碼出不同的數(shù)字。例如,針對當前的三分,它可以解碼出差距是三分的107-104。但在真實場景中,它無法直接計算答案,因為基本的語言模型不具備計算能力。因此可以將其放在計算器中計算出結(jié)果,然后將結(jié)果放回原文中使用。這種方式可以很好地將數(shù)值推理的能力嵌入到文本中。
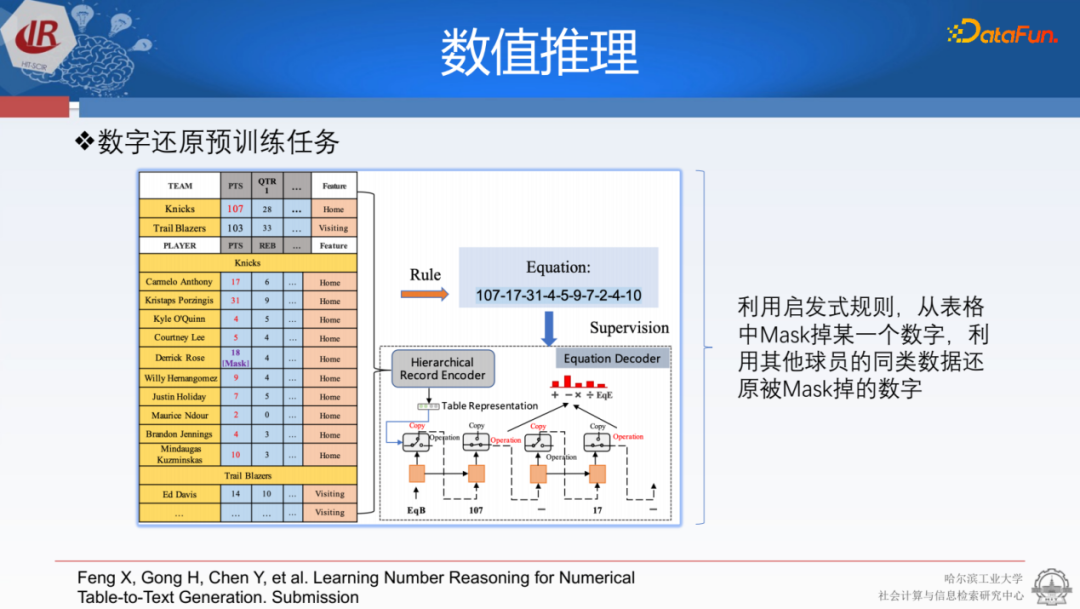
為了更好地讓它理解表格的結(jié)構(gòu)和數(shù)據(jù),結(jié)合我們的任務,我們提出了一種叫做tablemask的策略。我們可以隨意從表格中摳掉一些,然后使用它的行列嘗試恢復它。例如,如果某個球員的得分被扣掉了,我們可以用總分減去其它所有區(qū)域的分數(shù)來獲得該球員的分數(shù)。這樣就可以基于樣例來訓練,提前保證預訓練公式計算器的解碼能力。之后,把解碼能力嵌入到文本解碼器內(nèi),兩者相互配合就可以得到比較好的結(jié)果。
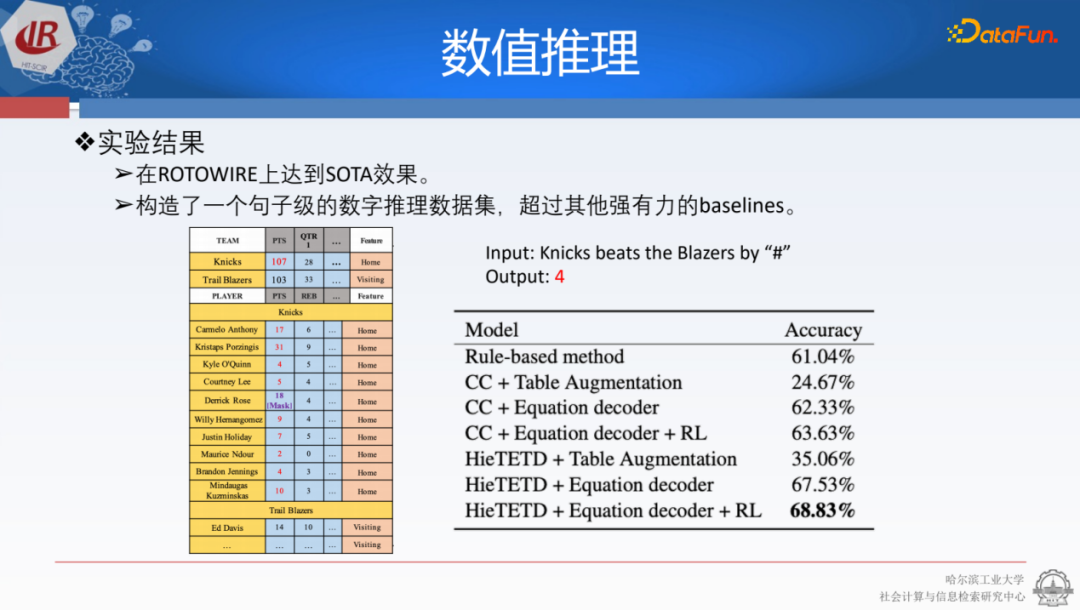
從實驗數(shù)據(jù)來看,我們除了做文本生成任務,也去看能否產(chǎn)生比較有意思的結(jié)果。我們就做了一些對比,例如“尼克斯戰(zhàn)勝了灰熊”,給它“#”,讓模型生成下一個詞。因為當時很多用的都是transformer,沒有預訓練。我們看到,通過調(diào)整數(shù)字構(gòu)造器的方法,大于70% 的數(shù)字都是可以正確生成的,而這些數(shù)字都是通過計算得到的,并不是在原始的表格里存在的。
同時我們找了一些其它好的例子,發(fā)現(xiàn)確實是可以生成原始內(nèi)容中沒有的信息。比如生成兩隊在上半場的比分,在實際數(shù)據(jù)中只有每一節(jié)的分數(shù),沒有上半場的總分數(shù),就需要分別計算兩個球隊上半場分數(shù)之和,相加之后再把兩個數(shù)字導回去,獲得合理的生成結(jié)果。
4.風格控制
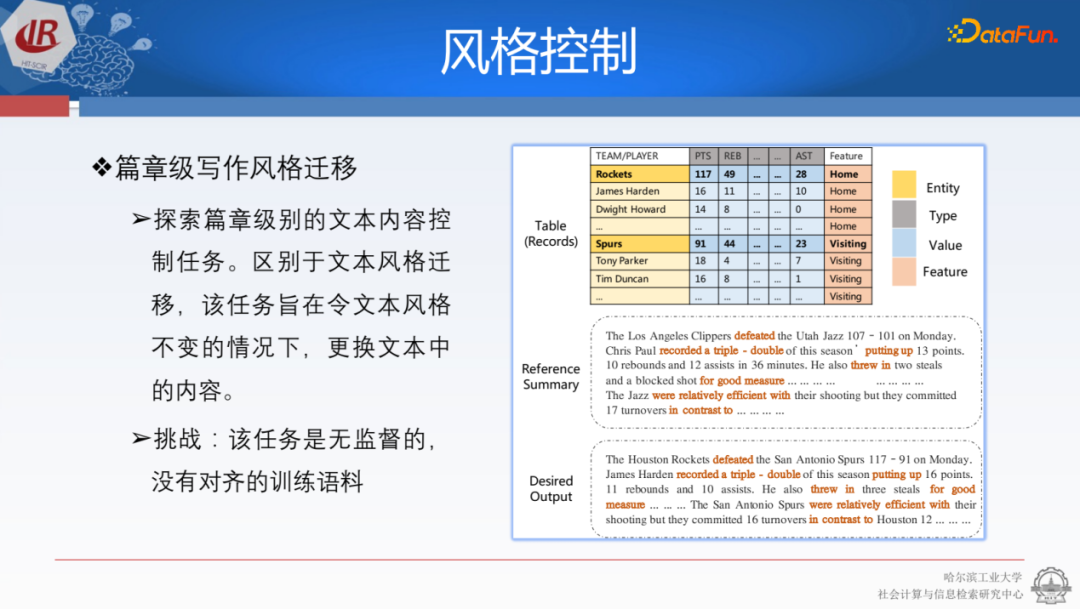
我們還希望能夠指定寫作的風格。前文介紹的更加傾向于能夠產(chǎn)生有價值的信息,現(xiàn)在是考慮是否能遵照不同人的風格生成更加可定制、個性化的內(nèi)容。我們提出了一種篇章級的風格遷移任務。以前的風格遷移是源于圖像視覺領(lǐng)域,比如要求模型畫一個達芬奇風格的畫。后來在文本中,我們會希望模型生成積極的表達,或者生成更加正式的一段表達。
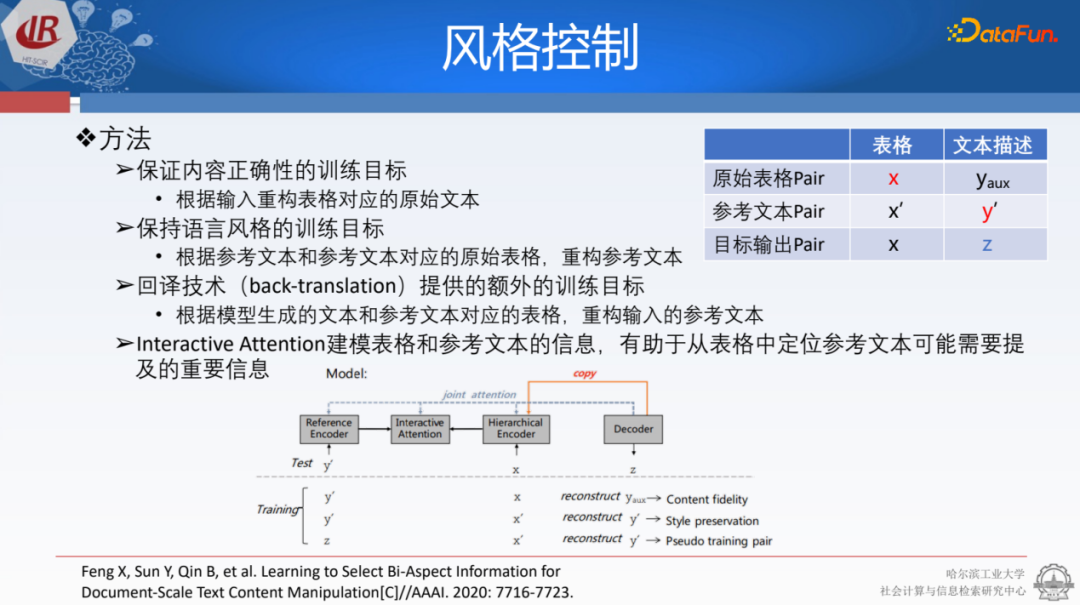
我們提到的篇章級風格控制是指,給定一個表格和需要新聞報道的樣式素材,將這些材料整合為一篇文章。由于這些數(shù)據(jù)本身并不匹配,因此要寫出符合這種文體的文章是一項具有挑戰(zhàn)性的任務,只能通過一種無監(jiān)督的方式進行。為了解決這個任務,我們設(shè)計了不同種學習的損失函數(shù),保證內(nèi)容可信度和語言風格,并生成類似于back-translation的內(nèi)容,以指導我們將文章寫回原來的文本。
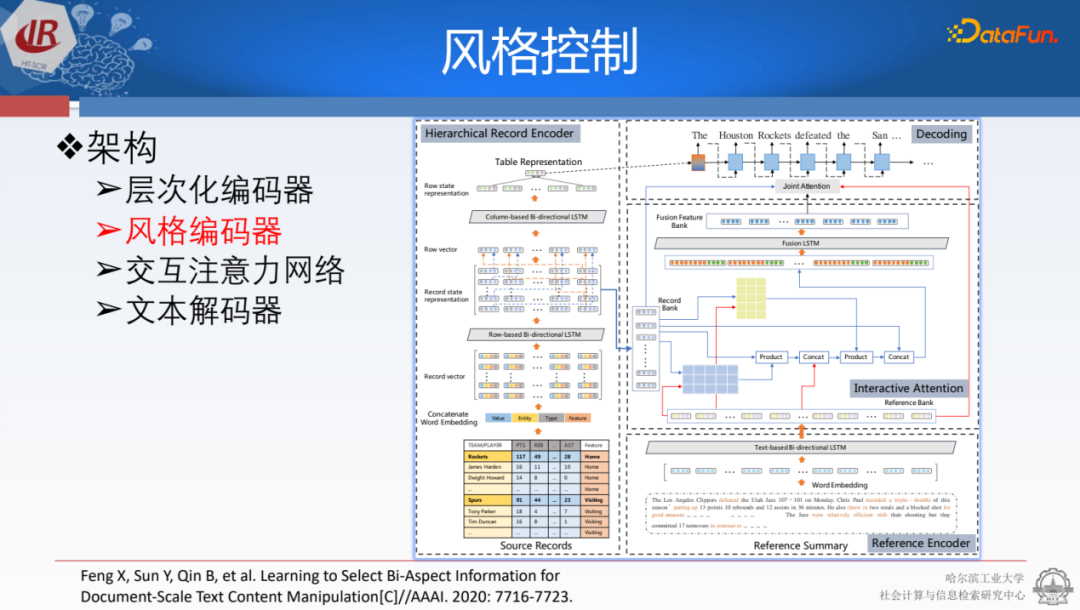
在建模方面,我們將表格和參考文本用層次化的方式建模,再進行attention交互的矩陣計算,最后我們用它來指導文章生成。
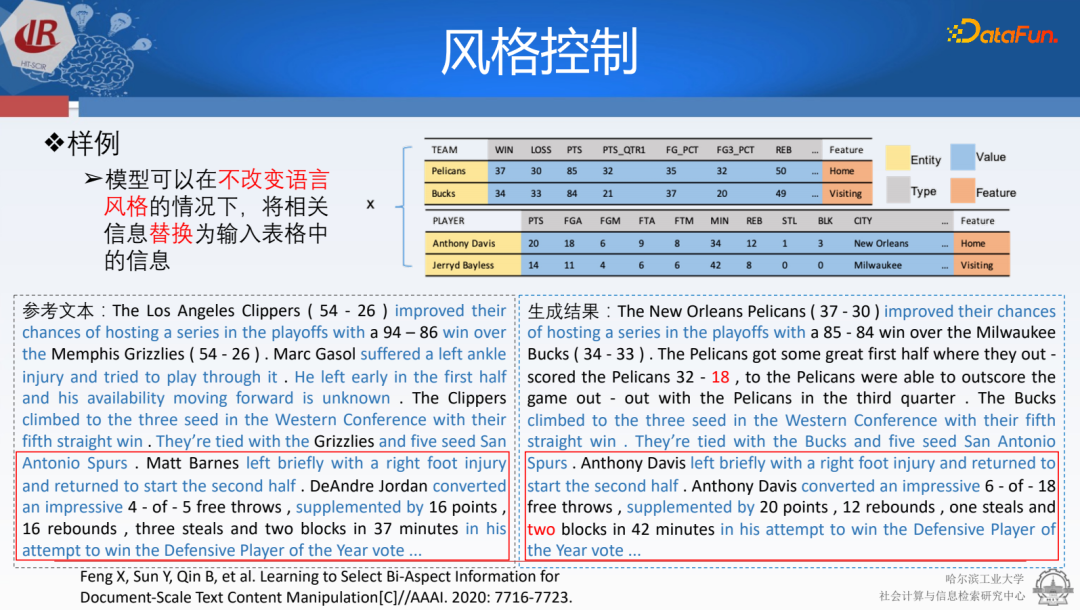
文章在風格表達方面達到了比較好的效果。直接把原始文本上的數(shù)字摳掉去填充,這種風格匹配是百分之百的,一些內(nèi)容可行性上的準確率、召回率以及BLEU值都還是很好的。實際上,在生成內(nèi)容方面,模型的效果還不錯,比如輸入表格和左側(cè)文本,能夠按照風格生成理想中的內(nèi)容。由于模型建模能力有限,還是會犯一些小錯誤,不過大部分情況下,它都能夠?qū)W習并正確生成所需的文本。
04總結(jié)
最后做一個簡單的總結(jié),首先隨著ChatGPT的出現(xiàn),結(jié)構(gòu)化數(shù)據(jù)的文本生成的應用會越來越多,未來很難找到一些典型的問題。其次,ChatGPT可以幫助我們做文本生成的評價,因為目前文本生成評價的進展依舊不容樂觀。另外,我們還需要對ChatGPT做一些特殊的優(yōu)化,比如如何設(shè)計給ChatGPT的結(jié)構(gòu)化數(shù)據(jù)的模板形式。同時我們還可以設(shè)計一些特殊的prompt。這方面還有研究空間。此外,現(xiàn)在是以三元組方式去建模,但是在做summarization的時候,它是以一種跨模態(tài)的圖片形式,我們也需要思考表格是否能采用這種多模態(tài)的形式處理。
05Q&A
Q1:table2txt的工作中,行編碼器或者列編碼器會將table中的數(shù)據(jù)解析成三元組的形式,喂給到模型中進行建模嗎?
A1:是的,這確實是個很好的問題。它確實是以三元組形式輸入到我們的模型中。因為當時它不一定都是序列化的,像現(xiàn)在這種transformer的編碼方式。比如我們把人名和他的對應的得分加上他的分數(shù),他們?nèi)齻€組合成三元組的形式,通過MLP的簡單形式進行編碼。它的效果還可以,讓我們覺得這種方式還不錯。
Q2:大規(guī)模的結(jié)構(gòu)化數(shù)據(jù)的建模(大寬表,freebas)有什么比較好的思路嗎?
A2:我們還試驗了其他例子,剛才給大家展示的是ChatGPT,它生成會存在的一些問題。那我們內(nèi)部也測了一下,GPT-4能讀一些結(jié)構(gòu)化的信息,就比如你把它存成json這種有一定層次的表達也可以讀取。而且它的輸入效果要比ChatGPT好,基本上找不出來明顯的錯誤。
Q3:多元時序結(jié)構(gòu)化的數(shù)據(jù)表的建模,請問有好的建模的思路嗎?
A3:我覺得可以參考我們在做序列化建模時候加入類似position embedding的時間戳的做法,這是一種最直接的方式。
Q4:GPT對于知識圖譜的研究最大的挑戰(zhàn)和啟示是什么?未來知識圖譜的研究會發(fā)生根本性的轉(zhuǎn)變嗎?
A4:我覺得確實也是現(xiàn)在很值得思考的問題。我覺得也是我們要開次峰會的原因,因為大家看到把知識存到參數(shù)化的效果里面是很好的,那很多時候我們基本上也不需要去搜索知識圖譜或者是檢索一些外部知識,它就能給出來很好的答案。像采用New Bing的形式,我通過實時檢索,返回一些文本信息,它來作為補充,那這對于時效性和準確性的提升也是很明顯的。那在整個過程中,圖譜能發(fā)揮的作用確實是值得我們?nèi)ニ伎肌N覀€人感覺可以想辦法,他們有的文章提出可以讓模型去恢復圖譜,去預測圖譜中的節(jié)點。可以說能把知識的這種方式嵌入到我的模型中,就類似先Mask原本的文本再去恢復它,這樣你能學到文本的上下文。那你把圖譜中的節(jié)點刪除摳掉之后,你讓模型去恢復圖譜,你就能學到些不同知識間的相關(guān)性。確實是很難回答的問題。
-
人工智能
+關(guān)注
關(guān)注
1804文章
48660瀏覽量
246188 -
結(jié)構(gòu)化
+關(guān)注
關(guān)注
0文章
27瀏覽量
10387 -
知識圖譜
+關(guān)注
關(guān)注
2文章
132瀏覽量
7917
原文標題:面向結(jié)構(gòu)化數(shù)據(jù)的文本生成技術(shù)研究
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
結(jié)構(gòu)化程序設(shè)計和面向對象程序設(shè)計
如何使用西門子結(jié)構(gòu)化文本編程
結(jié)構(gòu)化文本語言ST編程的學習課件

文本生成任務中引入編輯方法的文本生成

受控文本生成模型的一般架構(gòu)及故事生成任務等方面的具體應用
基于GPT-2進行文本生成
結(jié)構(gòu)化文本(ST)編程參考手冊

MELSEC Q/L結(jié)構(gòu)體編程手冊(結(jié)構(gòu)化文本篇)
MELSEC iQ R結(jié)構(gòu)化文本(ST)編程指南
基于VQVAE的長文本生成 利用離散code來建模文本篇章結(jié)構(gòu)的方法
通過循環(huán)訓練實現(xiàn)忠實的低資源數(shù)據(jù)文本生成






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論