 基于VQVAE的長文本生成 利用離散code來建模文本篇章結構的方法
基于VQVAE的長文本生成 利用離散code來建模文本篇章結構的方法
寫在前面
近年來,多個大規模預訓練語言模型 GPT、BART、T5 等被提出,這些預訓練模型在自動文摘等多個文本生成任務上顯著優于非預訓練語言模型。但對于開放式生成任務,如故事生成、新聞生成等,其輸入信息有限,而要求輸出內容豐富,經常需要生成多個句子或段落,在這些任務上預訓練語言模型依然存在連貫性較差、缺乏常識等問題。本次與大家分享一篇建模長文本篇章結構的工作,用以提升生成文本的連貫性。
論文題目
《DISCODVT: Generating Long Text with Discourse-Aware Discrete Variational Transformer》
論文作者
Haozhe Ji, Minlie Huang
論文單位
清華大學
論文鏈接
https://github.com/cdjhz/DiscoDVT,EMNP2021/
1
動機(Motivation)
●
文本的全局連貫性一般表現為:
內容表達的流暢度;
內容之間的自然過渡。
如下圖示例文本中的話語關系詞(after, then, and, but 等),這些篇章關系詞將連續的文本片段(text span)進行合理安排,從而形成結構、邏輯較好的文本。雖然預訓練語言模型在關聯與主題相關的內容時表現較好,但用好的篇章結構來安排內容仍然存在很多挑戰。針對此問題,研究者提出建模文本內部片段與片段之間的篇章關系,利用篇章結構指導生成,以期能夠改進生成文本的連貫性。

圖 1 EDU片段和篇章關系示例
2
方法(Method)
●
任務定義
首先,長文本生成的任務可以定義為:給定輸入 ,模型自動生成的過程,即。 基于以上的討論,該工作基于 VQVAE 的方法提出 DiscoDVT(Discourse-aware Discrete Variational Transformer),首先引入一個離散code序列,學習文本中每個局部文本片段(span)的高層次結構,其中每一個從大小為的 code vocabulary 中得到。隨后作者進一步提出一個篇章關系預測目標,使離散 code 能夠捕獲相鄰文本片段之間顯式的篇章關系,比如圖 1 中的篇章關系,after,then 等。 整個方法包括后驗網絡、生成器和先驗網絡,使用類似 VAE 的學習目標,該方法通過最大化 ELBO 來優化。 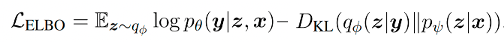 ? 訓練過程分為兩個階段:
? 訓練過程分為兩個階段:
第一階段聯合訓練后驗網絡和生成器,使后驗網絡根據推導出離散的code序列,其中要求能夠學習到的高層次結構,生成器則根據和 code 序列重構;
第二階段訓練先驗網絡,使其能夠根據,預測離散 code 序列。
兩階段訓練完成之后,在生成階段,先驗網絡首先根據預測離散 code 序列,隨后用于指導生成文本,中帶有篇章結構信息,因此能夠提升生成文本的連貫性。
學習離散隱變量
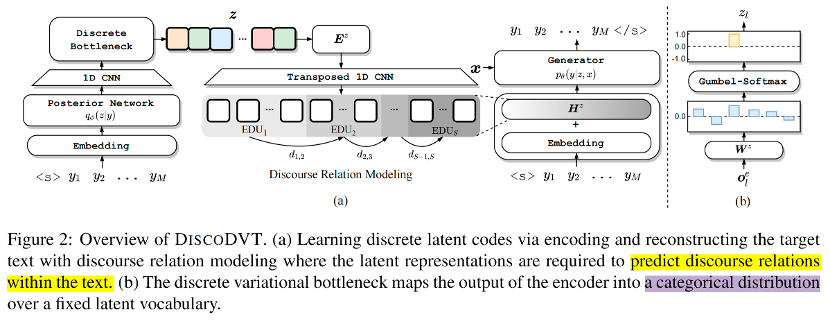
圖 2 模型整體框架 這部分主要解決如何學習隱變量 code 序列,使其能夠保留文本的篇章結構。模型框架如上圖所示,在編碼階段,首先使用編碼器編碼得到語境化的表示,隨后使用 CNN 和 Discrete Variational Bottleneck 技術得到離散 code 序列;在解碼階段,首先使用 transposed cnn 將 code embedding 序列的長度重新調整到文本的長度,然后添加到解碼器的嵌入層中進行 step-wise 的控制,重構生成。重構生成的優化目標能夠使離散 code 序列保存文本中高層次的結構信息。 具體計算過程如下: 定義 code vocabulary 的大小為,以及隨機初始化的 code embedding matrix 為:
首先使用 Bart encoder 編碼得到語境化的表;
為了抽象出與文本的全局結構相對應的 high-level feature, 使用多層 CNN 對進行卷積操作,得到 span-level 的表示;
隨后使用 Discrete Variational Bottleneck 技術獲得離散 code。具體地,將 CNN 的輸出線性映射到離散空間:
訓練階段通過 gumbel-softmax 方法采樣得到 soft categorical distribution : 隨后 categorical distribution 與相乘得到 code embedding 。 在推理階段則通過 argmax 方式得到離散 code 序列:
為了使每個 code 能夠指導局部文本的生成,首先利用 Transposed CNN 網絡(與步驟2中使用的CNN對稱),將code embedding 重新調整到。(這里類似上采樣的操作,將離散的 code embedding 序列的長度,恢復到原始文本的長度,可以看到的長度恢復為。)之后,與解碼器輸入的 token embedding 相加用于重構文本。重構優化目標如下:
篇章關系建模 為了將文本的篇章結構抽象為 latent representation,作者設計了一個輔助的篇章關系感知目標,將篇章關系嵌入到離散化的 code 中。使用 bi-affine 建模相鄰 EDU 片段和的篇章關系,使得和EDU 片段對應的 latent representation 能夠預測出兩者之間的篇章關系。 最大化下述的對數概率: 其中,和分別表示第個和個EDU 片段的隱表示(latent representation)。 正則化隱變量 此外,作者在前期的實驗中發現模型傾向于僅利用這個 code vocabulary 中少量的離散 code,這種現象會損害離散 code 的表達能力。為了鼓勵模型盡可能等概率的利用離散 code,作者還引入基于熵的正則方法。
訓練目標 在第一階段中,聯合上述的幾個優化目標來訓練后驗網絡和生成器,總的優化目標為: 離散 code 學習完成之后,作者使用額外的一個基于編碼-解碼的先驗網絡來學習給定條件下離散 code 的先驗分布,優化目標如下: 這里因為離散 code 已經學習完成,得到后驗網絡,對于原始的數據集 中的每一個,可以通過后驗網絡得到離散 code 序列,從而形成一個數據集,該數據集用于訓練先驗網絡。
3
實驗
●
數據集
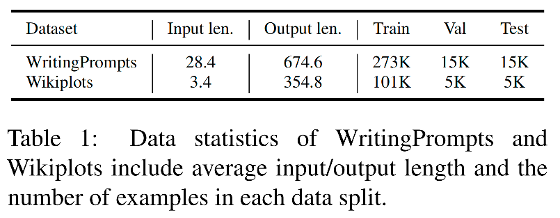
作者在公開的故事生成數據集 WritingPrompts 和 Wikiplots 數據集上評測所提方法,數據統計信息如下表所示。
baseline 模型對比
對比的 baseline 模型如下:
Seq2Seq:它是采用與 Bart 相同框架的編碼-解碼模型,沒有經過預訓練;
Bart:采用預訓練 Bart 模型,并在下游數據集上對其微調;
Bart-LM:同樣采用預訓練 Bart 模型,先使用 bookcorpus 數據對其繼續訓練,隨后在下游數據集進行微調;
BART-CVAE:基于 CVAE 的框架,引入連續隱變量到 Bart 模型,將隱變量加到解碼器的 embedding 層指導生成文本;
Aristotelian Rescoring:它采用內容規劃的方法,給定輸入,它首先生成一個基于SRL 的情節,然后根據情節打分模型修改情節,最后基于修改的情節生成文本。
結果分析
下表展示了所有模型在兩個數據集的自動評測結果。
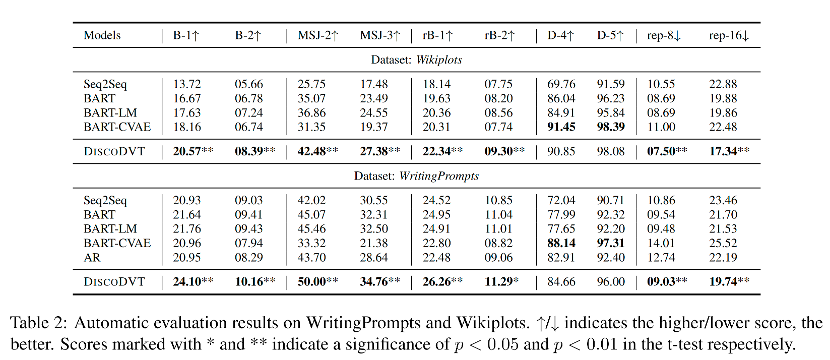
可以看到,在兩個數據集上,在基于參考的指標上,DiscoDVT 生成的文本獲得最高的n-gram 重疊度(BLEU)和相似度(MSJ)。多樣性方面,DiscoDVT 在 distinct 指標上略微低于 BART-CVAE,這里作者進一步檢查了 BART-CVAE 的生成文本,發現BART-CVAE 會生成不出現在參考文本中的虛假單詞,從而提高了多樣性。在重復度方面,由于 DiscoDVT 使用了 step-wise 的控制,因此 rep-有較大幅度領先。 基于規劃的方法 AR 可以獲得較高的多樣性,但在基于參考的指標上 BLEU、MSJ、rB 上的結果較低,這可能是多階段方法中的暴露偏差,對生成質量有負面影響。
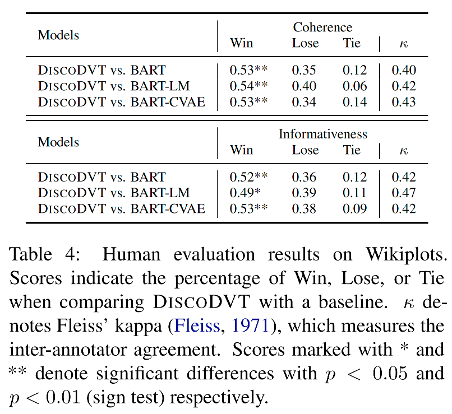
人工評測結果顯示,在生成文本的連貫性和信息度方面,大多數 DiscoDVT 生成文本的質量要優于 BART, BART-LM 和 BART-CAVE baseline。

如上圖所示,作者進一步對學習的 code 進行分析,可以發現離散的 code 確實能夠學習到篇章關系,比如 and, so, when, however 等。
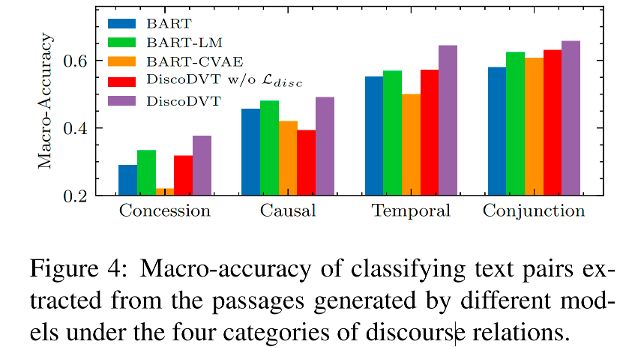
作者利用 discourse marker classifification 任務評測生成的篇章關系詞是否正確,如上圖所示。在讓步、因果、時序和連接 4 種篇章關系上,DiscoDVT 生成文本中的篇章關系準確率最高,說明 DiscoDVT 生成的文本在篇章關系上質量更好。當去掉篇章關系建模的優化目標,生成的篇章關系準確率有明顯下降,從而證明了篇章關系建模方法的有效性。
4
結語
●
本次分享展示了一種利用離散 code 來建模文本篇章結構的方法。該方法引入一個離散 code 序列學習文本的篇章結構,隨后采用 step-wise 解碼指導生成文本。為了建模顯式的篇章關系,作者進一步提出了篇章關系建模優化目標。自動評測和人工評測結果證明了該方法的有效性。對于 code 的分析實驗驗證了離散 code 確實能夠保留篇章關系的信息。
文本連貫性是自然語言生成的重要課題,目前改進的方法包括基于規劃、建模高層次結構等方面,主要流程是首先生成文本大綱,再根據大綱生成完整的文本,其中大綱可以由關鍵詞序列或者事件序列構成。整體來看,長文本生成中的篇章結構建模還仍不夠成熟,存在諸多問題,期待未來有更多的工作取得改進。
作者來自:瀾舟科技楊二光 在此特別鳴謝!
北京交通大學自然語言處理實驗室四年級博士生,導師為張玉潔教授,研究方向為可控文本生成、復述生成、故事生成。在瀾舟科技實習期間主要從事長文本生成、營銷文案生成等課題。
-
Code
+關注
關注
0文章
70瀏覽量
15699 -
GPT
+關注
關注
0文章
368瀏覽量
15929 -
cnn
+關注
關注
3文章
354瀏覽量
22627 -
nlp
+關注
關注
1文章
490瀏覽量
22477 -
edu
+關注
關注
0文章
15瀏覽量
1849
原文標題:基于 VQVAE 的長文本生成
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
如何構建文本生成器?如何實現馬爾可夫鏈以實現更快的預測模型
KUKA-C4機器人如何導出/導入長文本
如何優雅地使用bert處理長文本

給KUKA-C4機器人導入長文本方法
文本生成任務中引入編輯方法的文本生成

受控文本生成模型的一般架構及故事生成任務等方面的具體應用
基于GPT-2進行文本生成
KUKA-C4機器人導出/導入長文本

ETH提出RecurrentGPT實現交互式超長文本生成

面向結構化數據的文本生成技術研究

Meta發布一款可以使用文本提示生成代碼的大型語言模型Code Llama






 工商網監
工商網監
評論