 多CPU下的Ring Buffer處理
多CPU下的Ring Buffer處理
1. 網卡處理數據包流程
一圖勝千言,先來看看網卡處理網絡數據流程圖:
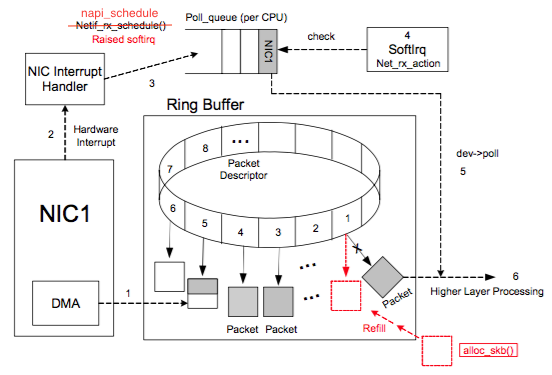
圖片來自參考鏈接1
上圖中虛線步驟的解釋:
1 DMA 將 NIC 接收的數據包逐個寫入 sk_buff ,一個數據包可能占用多個 sk_buff , sk_buff 讀寫順序遵循FIFO(先入先出)原則。
2 DMA 讀完數據之后,NIC 會通過 NIC Interrupt Handler 觸發 IRQ (中斷請求)。
3 NIC driver 注冊 poll 函數。
4 poll 函數對數據進行檢查,例如將幾個 sk_buff 合并,因為可能同一個數據可能被分散放在多個 sk_buff 中。
5 poll 函數將 sk_buff 交付上層網絡棧處理。
完整流程:
1 系統啟動時 NIC (network interface card) 進行初始化,系統分配內存空間給 Ring Buffer 。
2 初始狀態下,Ring Buffer 隊列每個槽中存放的 Packet Descriptor 指向 sk_buff ,狀態均為 ready。
3 DMA 將 NIC 接收的數據包逐個寫入 sk_buff ,一個數據包可能占用多個 sk_buff ,sk_buff 讀寫順序遵循FIFO(先入先出)原則。
4 被寫入數據的 sk_buff 變為 used 狀態。
5 DMA 讀完數據之后,NIC 會通過 NIC Interrupt Handler 觸發 IRQ (中斷請求)。
6 NIC driver 注冊 poll 函數。
7 poll 函數對數據進行檢查,例如將幾個 sk_buff 合并,因為可能同一個數據可能被分散放在多個 sk_buff 中。
8 poll 函數將 sk_buff 交付上層網絡棧處理。
9 poll 函數清理 sk_buff,清理 Ring Buffer 上的 Descriptor 將其指向新分配的 sk_buff 并將狀態設置為 ready。
2. 多 CPU 下的 Ring Buffer 處理
因為分配給 Ring Buffer 的空間是有限的,當收到的數據包速率大于單個 CPU 處理速度的時候 Ring Buffer 可能被占滿,占滿之后再來的新數據包會被自動丟棄。
如果在多核 CPU 的服務器上,網卡內部會有多個 Ring Buffer,NIC 負責將傳進來的數據分配給不同的 Ring Buffer,同時觸發的 IRQ 也可以分配到多個 CPU 上,這樣存在多個 Ring Buffer 的情況下, Ring Buffer 緩存的數據也同時被多個 CPU 處理,就能提高數據的并行處理能力。
當然,要實現“NIC 負責將傳進來的數據分配給不同的 Ring Buffer”,NIC 網卡必須支持 Receive Side Scaling(RSS) 或者叫做 multiqueue 的功能。RSS 除了會影響到 NIC 將 IRQ 發到哪個 CPU 之外,不會影響別的邏輯了。數據處理過程跟之前描述的是一樣的。
3. Ring Buffer 相關命令
在生產實踐中,因 Ring Buffer 寫滿導致丟包的情況很多。當環境中的業務流量過大且出現網卡丟包的時候,考慮到 Ring Buffer 寫滿是一個很好的思路。
總結下 Ring Buffer 相關的命令:
3.1 網卡收到的數據包統計
[root@test ]$ ethtool -S em1 | more
NIC statistics:
rx_packets: 35874336743
tx_packets: 35163830212
rx_bytes: 6337524253985
tx_bytes: 3686383656436
rx_broadcast: 15392577
tx_broadcast: 873436
rx_multicast: 45849160
tx_multicast: 1784024
RX 就是收到數據,TX 是發出數據。
3.2 帶有 drop 字樣的統計和 fifo_errors 的統計
[root@test ]$ethtool -S em1 | grep -iE "error|drop"
rx_crc_errors: 0
rx_missed_errors: 0
tx_aborted_errors: 0
tx_carrier_errors: 0
tx_window_errors: 0
rx_long_length_errors: 0
rx_short_length_errors: 0
rx_align_errors: 0
dropped_smbus: 0
rx_errors: 0
tx_errors: 0
tx_dropped: 0
rx_length_errors: 0
rx_over_errors: 0
rx_frame_errors: 0
rx_fifo_errors: 79270
tx_fifo_errors: 0
tx_heartbeat_errors: 0
rx_queue_0_drops: 16669
rx_queue_1_drops: 21522
rx_queue_2_drops: 0
rx_queue_3_drops: 5678
rx_queue_4_drops: 5730
rx_queue_5_drops: 14011
rx_queue_6_drops: 15240
rx_queue_7_drops: 420
發送隊列和接收隊列 drop 的數據包數量顯示在這里。并且所有 queue_drops 加起來等于 rx_fifo_errors。
所以總體上能通過 rx_fifo_errors 看到 Ring Buffer 上是否有丟包。如果有的話一方面是看是否需要調整一下每個隊列數據的分配,或者是否要加大 Ring Buffer 的大小。
3.3 查詢 Ring Buffer 大小
[root@test]$ ethtool -g em1
Ring parameters for em1:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 256
RX Mini: 0
RX Jumbo: 0
TX: 256
RX 和 TX 最大是 4096,當前值為 256 。隊列越大丟包的可能越小,但數據延遲會增加。
3.4 調整 Ring Buffer 隊列數量
[root@test]$ ethtool -l em1
Channel parameters for em1:
Pre-set maximums:
RX: 0
TX: 0
Other: 1
Combined: 8
Current hardware settings:
RX: 0
TX: 0
Other: 1
Combined: 8
Combined = 8,說明當前 NIC 網卡會使用 8 個進程處理網絡數據。
更改 eth0 網卡 Combined 的值:
ethtool -L eth0 combined 8
需要注意的是,ethtool 的設置操作可能都要重啟一下才能生效。
3.4 調整 Ring Buffer 隊列大小 查看當前 Ring Buffer 大小:
[root@test]$ ethtool -g em1
Ring parameters for em1:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 256
RX Mini: 0
RX Jumbo: 0
TX: 256
看到 RX 和 TX 最大是 4096,當前值為 256。隊列越大丟包的可能越小,但數據延遲會增加。
設置 RX 和 TX 隊列大小:
ethtool -G em1 rx 4096
ethtool -G em1 tx 4096
3.5 調整 Ring Buffer 隊列的權重
NIC 如果支持 mutiqueue 的話 NIC 會根據一個 Hash 函數對收到的數據包進行分發。能調整不同隊列的權重,用于分配數據。
[root@test]$ ethtool -x em1
RX flow hash indirection table for em1 with 8 RX ring(s):
0: 0 0 0 0 0 0 0 0
8: 0 0 0 0 0 0 0 0
16: 1 1 1 1 1 1 1 1
24: 1 1 1 1 1 1 1 1
32: 2 2 2 2 2 2 2 2
40: 2 2 2 2 2 2 2 2
48: 3 3 3 3 3 3 3 3
56: 3 3 3 3 3 3 3 3
64: 4 4 4 4 4 4 4 4
72: 4 4 4 4 4 4 4 4
80: 5 5 5 5 5 5 5 5
88: 5 5 5 5 5 5 5