") iPhone都能微調(diào)大模型了嘛
iPhone都能微調(diào)大模型了嘛

自動測試分?jǐn)?shù)達(dá)到ChatGPT的99.3%,人類難以分辨兩者的回答……
這是開源大模型最新成果,來自羊駝家族的又一重磅成員——華盛頓大學(xué)原駝(Guanaco)。
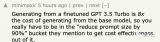
更關(guān)鍵的是,與原駝一起提出的新方法QLoRA把微調(diào)大模型的顯存需求從>780GB降低到<48GB。
開源社區(qū)直接開始狂歡,相關(guān)論文成為24小時(shí)內(nèi)關(guān)注度最高的AI論文。
以Meta的美洲駝LLaMA為基礎(chǔ),得到原駝650億參數(shù)版只需要48GB顯存單卡微調(diào)24小時(shí),330億參數(shù)版只需要24GB顯存單卡微調(diào)12小時(shí)。
24GB顯存,也就是一塊消費(fèi)級RTX3090或RTX4090顯卡足以。
不少網(wǎng)友在測試后也表示,更喜歡它而不是ChatGPT。
英偉達(dá)科學(xué)家Jim Fan博士對此評價(jià)為:大模型小型化的又一里程碑。
先擴(kuò)大規(guī)模再縮小,將成為開源AI社區(qū)的節(jié)奏。
而新的高效微調(diào)方法QLoRA迅速被開源社區(qū)接受,HuggingFace也在第一時(shí)間整合上線了相關(guān)代碼。
GPT-4做裁判,原駝得分達(dá)到ChatGPT的99.3%
論文中,團(tuán)隊(duì)對原駝總共做了三項(xiàng)測試,自動評估、隨機(jī)匹配和人類評估。
測試數(shù)據(jù)來自小羊駝Vicuna和Open Assistant。
自動評估由大模型天花板GPT-4當(dāng)裁判,對不同模型的回答進(jìn)行打分,以ChatGPT(GPT3.5)的成績作為100%。
最終原駝650億版得分達(dá)到ChatGPT的99.3%,而GPT-4自己的得分是114.5%,谷歌Bard是94.8%。
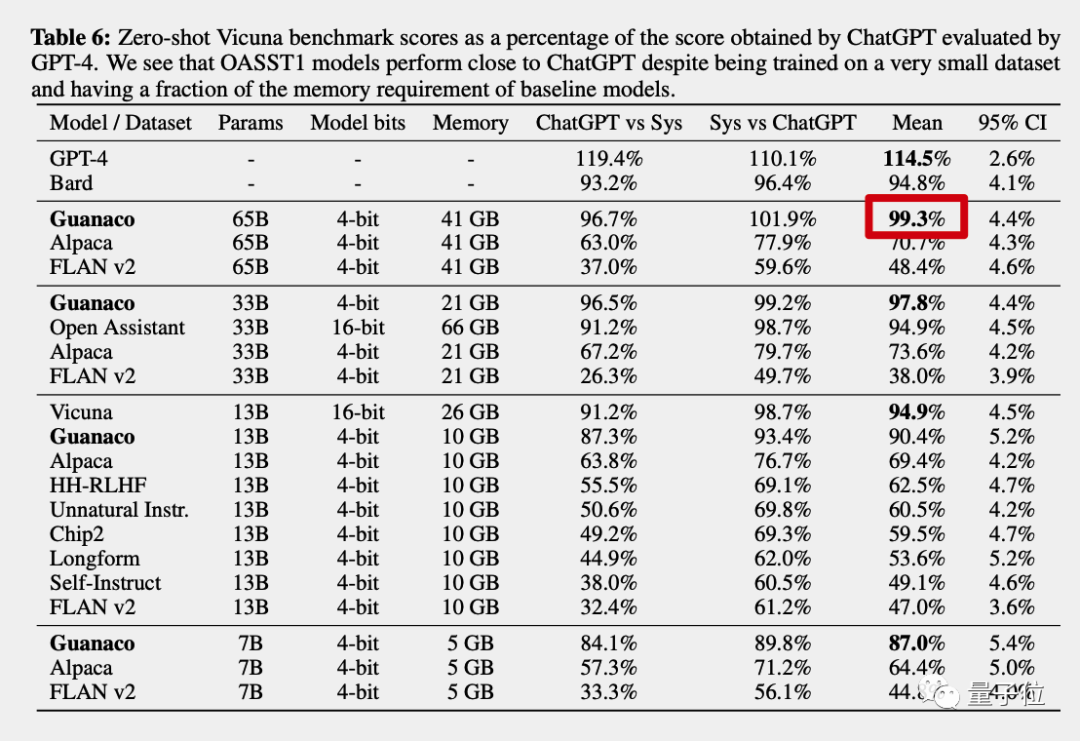
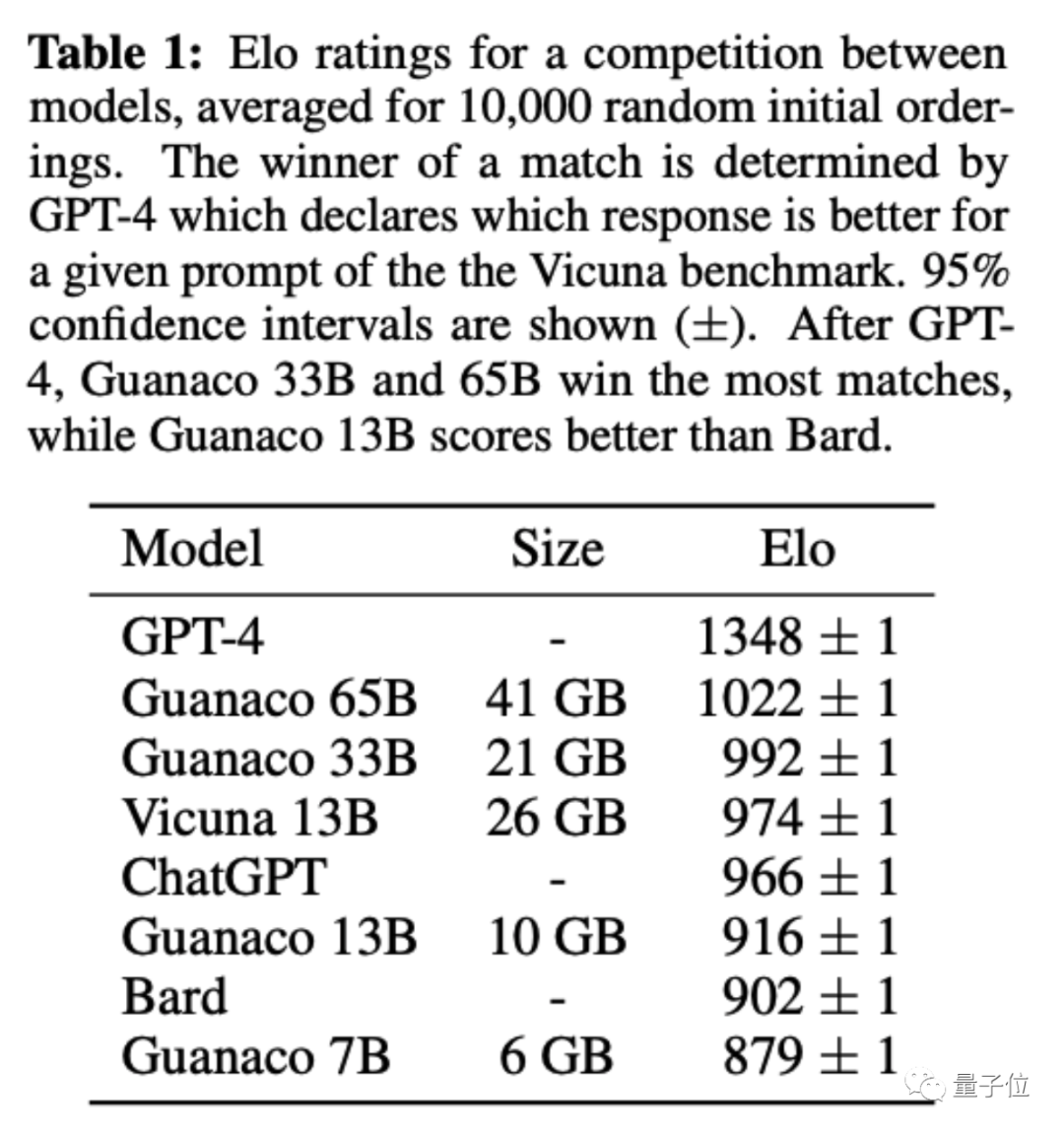
隨機(jī)匹配,采用棋類專業(yè)比賽和電子競技同款的Elo記分機(jī)制,由GPT-4和人類共同做裁判。
原駝650億和330億版最終得分超過ChatGPT(GPT3.5)。
人類評估,則是把原駝650億版的回答和ChatGPT的回答匿名亂序放在一起,人類來盲選哪個(gè)最好。
論文共同一作表示,研究團(tuán)隊(duì)里的人都很難分辨出來,并把測試做成了一個(gè)小游戲放在Colab上,開放給大家挑戰(zhàn)。
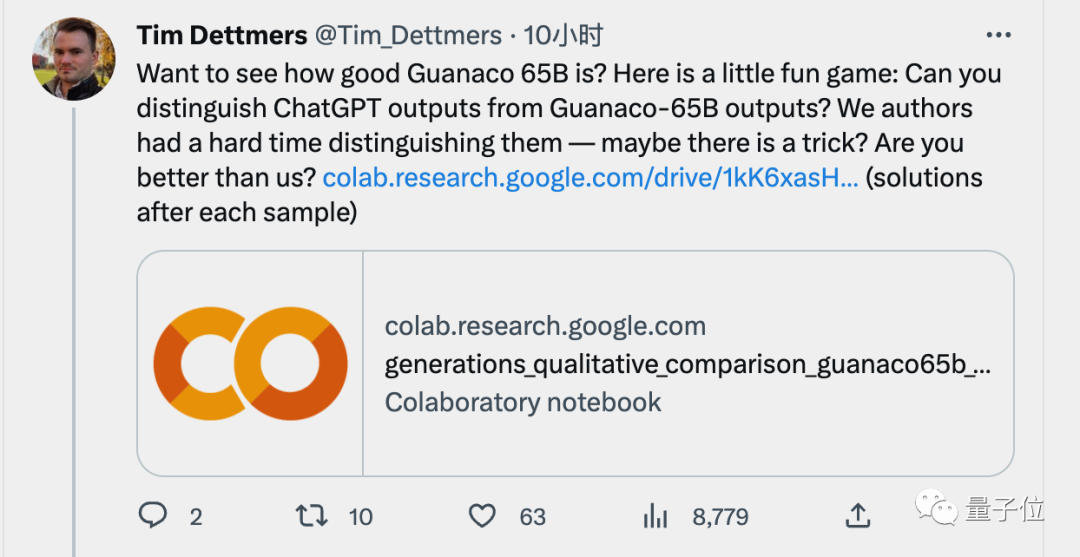
這里節(jié)選其中一個(gè)問題(附中文翻譯),你能分辨出哪個(gè)是ChatGPT回答的嗎?
問題:How can I improve my time management skills?(如何提高時(shí)間管理技能?)

總的來說,原駝的優(yōu)勢在于不容易被問題中的錯(cuò)誤信息誤導(dǎo),比如能指出地球從來沒有被科學(xué)界認(rèn)為是平的。
以及擅長心智理論(Theory of Mind),也就是能推測理解他人的心理狀態(tài)。

但原駝也并非沒有弱點(diǎn),團(tuán)隊(duì)發(fā)發(fā)現(xiàn)它不太擅長數(shù)學(xué),以及容易用提示注入攻擊把要求保密的信息從它嘴里套出來。
也有網(wǎng)友表示,雖然一個(gè)模型能在某個(gè)數(shù)據(jù)集上無限接近ChatGPT,但像ChatGPT那樣通用還是很難的。
全新方法QLoRA,iPhone都能微調(diào)大模型了
原駝?wù)撐牡暮诵呢暙I(xiàn)是提出新的微調(diào)方法QLoRA。
其中Q代表量化(Quantization),用低精度數(shù)據(jù)類型去逼近神經(jīng)網(wǎng)絡(luò)中的高精度浮點(diǎn)數(shù),以提高運(yùn)算效率。
LoRA是微軟團(tuán)隊(duì)在2021年提出的低秩適應(yīng)(Low-Rank Adaptation)高效微調(diào)方法,LoRA后來被移植到AI繪畫領(lǐng)域更被大眾熟知,但最早其實(shí)就是用于大語言模型的。
通常來說,LoRA微調(diào)與全量微調(diào)相比效果會更差,但團(tuán)隊(duì)將LoRA添加到所有的線性層解決了這個(gè)問題。
具體來說,QLoRA結(jié)合了4-bit量化和LoRA,以及團(tuán)隊(duì)新創(chuàng)的三個(gè)技巧:新數(shù)據(jù)類型4-bit NormalFloat、分頁優(yōu)化器(Paged Optimizers)和雙重量化(Double Quantization)。
最終QLoRA讓4-bit的原駝在所有場景和規(guī)模的測試中匹配16-bit的性能。
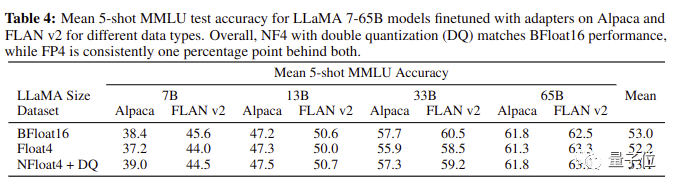
QLoRA的高效率,讓團(tuán)隊(duì)在華盛頓大學(xué)的小型GPU集群上每天可以微調(diào)LLaMA 100多次……
最終使用Open Assistant數(shù)據(jù)集微調(diào)的版本性能勝出,成為原駝大模型。
Open Assistant數(shù)據(jù)集來自非盈利研究組織LAION(訓(xùn)練Stable Diffusion的數(shù)據(jù)集也來自這里),雖然只有9000個(gè)樣本但質(zhì)量很高,經(jīng)過開源社區(qū)的人工仔細(xì)驗(yàn)證。
這9000條樣本用于微調(diào)大模型,比100萬條指令微調(diào)(Instruction Finetune)樣本的谷歌FLAN v2效果還好。
研究團(tuán)隊(duì)也據(jù)此提出兩個(gè)關(guān)鍵結(jié)論:
指令微調(diào)有利于推理,但不利于聊天
最后,QLoRA的高效率,還意味著可以用在手機(jī)上,論文共同一作Tim Dettmers估計(jì)以iPhone 12 Plus的算力每個(gè)晚上能微調(diào)300萬個(gè)單詞的數(shù)據(jù)量。
這意味著,很快手機(jī)上的每個(gè)App都能用上專用大模型。
責(zé)任編輯:彭菁
-
iPhone
+關(guān)注
關(guān)注
28文章
13500瀏覽量
206135 -
顯存
+關(guān)注
關(guān)注
0文章
112瀏覽量
13893 -
模型
+關(guān)注
關(guān)注
1文章
3519瀏覽量
50416
原文標(biāo)題:開源「原駝」爆火,iPhone都能微調(diào)大模型了,得分逼近ChatGPT!
文章出處:【微信號:zenRRan,微信公眾號:深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗(yàn)】+大模型微調(diào)技術(shù)解讀
使用OpenVINO?訓(xùn)練擴(kuò)展對水平文本檢測模型進(jìn)行微調(diào),收到錯(cuò)誤信息是怎么回事?
iPhone X Plus和iPhone 9的最新消息模型機(jī)和保護(hù)殼的體驗(yàn)
蘋果新款iPhone X Plus和LCD iPhone的機(jī)器模型泄露
文本分類任務(wù)的Bert微調(diào)trick大全
使用NVIDIA TAO工具包和Appen實(shí)現(xiàn)AI模型微調(diào)
有哪些省內(nèi)存的大語言模型訓(xùn)練/微調(diào)/推理方法?
調(diào)教LLaMA類模型沒那么難,LoRA將模型微調(diào)縮減到幾小時(shí)

中軟國際參加首期百度智能云文心千帆大模型SFT微調(diào)能力實(shí)訓(xùn)營

OpenAI開放大模型微調(diào)功能 GPT-3.5可以打造專屬ChatGPT
OpenAI開放大模型微調(diào)功能!
盤古大模型3.0是什么?
一種新穎的大型語言模型知識更新微調(diào)范式

四種微調(diào)大模型的方法介紹





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論