") 什么是RoCE?如何實現(xiàn)RoCE?
什么是RoCE?如何實現(xiàn)RoCE?
RoCE全稱RDMA over Converged Ethernet,是基于融合以太網的RDMA,那什么是RDMA?在了解RoCE之前先了解下RDMA技術。
1 、什么是 RDMA ?
RDMA(Remote Direct Memory Access), 全稱遠程內存直接訪問技術,是一種數據傳輸技術。 允許在計算機之間實現(xiàn)高性能、低延遲、高吞吐量的數據傳輸,由網絡適配器直接處理主機內存之間的數據傳輸,以大大減少了CPU在數據傳輸過程中的參與**(即從一個主機或服務器的內存直接訪問另一個主機或服務器的內存,這個過程無需使用** CPU )。 RDMA最早在Infiniband傳輸網絡上實現(xiàn),技術先進,但是價格高昂(只有Mellanox和Intel供應商提供全套網絡解決方案),后來業(yè)界廠家把RDMA移植到傳統(tǒng)Ethernet以太網上,降低了RDMA的使用成本,推動了RDMA技術普及。
我們知道,傳統(tǒng)應用要發(fā)送數據,??需要通過OS封裝TCP/IP,??然后依次經過主緩存、網卡緩存,??再發(fā)出去。??這個過程存在2個限制:1)TCP/IP協(xié)議棧處理會帶來數10微秒的 時延 。??TCP協(xié)議棧在接收發(fā)送報文時,??內核需要做多次上下文的切換,??每次切換需要耗費5-10微秒。?另外還需要至少三次的數據拷貝??和依賴CPU進行協(xié)議工作,??這導致僅僅協(xié)議上處理就會帶來數10微秒的??固定時延,??協(xié)議棧時延成為最明顯的瓶頸。?;2)TCP協(xié)議棧處理導致服務器CPU負載??居高不下。??除了固定時延較長的問題,TCP/IP網絡需要主機CPU??多次參與協(xié)議的內存拷貝,??網絡規(guī)模越大,??網絡帶寬越高,??CPU在收發(fā)數據時的調度負擔越大,??導致CPU 持續(xù)高負載 。??
在數據中心內部,超大規(guī)模分布式計算存儲資源之間,如果使用傳統(tǒng)的TCP/IP進行網絡互連,將占用系統(tǒng)大量的計算資源,造成****IO 瓶頸,無法滿足更高吞吐,更低時延的網絡需求。 RDMA****是一種高帶寬、低延遲、低CPU消耗的網絡互聯(lián)技術,克服了傳統(tǒng)TCP/IP網絡的高時延、高CPU負載等困難。
為了更形象的理解RDMA和TCP技術的區(qū)別。傳統(tǒng)的TCP/IP方式,可比作為人工收費一樣需要取卡,人工核實,手動繳費,找零錢等等才能完成汽車上下高速。在車輛很多的情況下就會出現(xiàn)排隊的情況,很浪費時間。而RDMA則像是 ETC ,跳過人工取卡,收費等步驟,直接刷卡,極速通過。既節(jié)省了時間,又節(jié)省了人力。
RDMA相比TCP/IP,既降低了對計算資源的占用,又提升了數據的傳輸速率。RDMA的內核旁路機制??允許應用與網卡之間的直接數據讀寫,??這樣可以將服務器內的數據傳輸時延降低到??接近1微秒。同時,RDMA的??內存零拷貝機制允許接收端直接從發(fā)送端的內存讀取數據,??極大地減少了CPU的負擔,??提高了CPU的利用率。使用RDMA的好處包括:
1 )內存零拷貝( Zero Copy ) :RDMA應用程序可以繞過內核網絡棧直接進行數據傳輸,不需要再將數據從應用程序的用戶態(tài)內存空間拷貝到內核網絡棧內存空間。
2 )內核旁路( Kernel bypass ) :RDMA應用程序可以直接在用戶態(tài)發(fā)起數據傳輸,不需要在內核態(tài)與用戶態(tài)之間做上下文切換。
3 ) CPU 減負( CPU offload ) :RDMA可以直接訪問遠程主機內存,不需要消耗遠程主機中的任何CPU,這樣遠端主機的CPU可以專注自己的業(yè)務,避免其cache被干擾并充滿大量被訪問的內存內容。
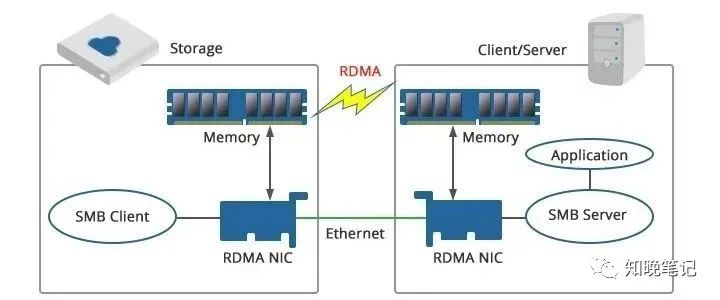
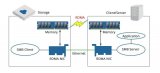
例如上圖,使用RDMA可以簡單理解為利用相關的硬件和網絡技術,服務器1的網卡可以直接讀寫服務器2的內存,最終達到高帶寬、低延遲和低資源利用率的效果。因此,RDMA可以簡單理解為利用相關的硬件和網絡技術,服務器的 網卡之間可以直接讀內存 ,最終達到高帶寬、低延遲和低資源利用率的效果。應用程序不需要參與數據傳輸過程,只需要指定內存讀寫地址,開啟傳輸并等待傳輸完成即可
2 、什么是 RoCE ?
RoCE全稱是RDMA over Converged Ethernet(以太網上的RDMA),是在InfiniBand Trade Association(IBTA)標準中定義的網絡協(xié)議,允許通過以太網絡使用 RDMA 。即****RoCE 允許在以太網上實現(xiàn)高性能、低延遲、高吞吐量的數據傳輸,不需要使用特殊的網絡硬件設備,只需要通過標準化的以太網設備就可以實現(xiàn),大大降低了成本 (可以通過支持RDMA的以太網適配器和交換機實現(xiàn)高性能、低延遲、高吞吐量的數據傳輸,無需在傳輸過程中頻繁地進行CPU參與)。RoCE技術遵循與InfinBand相同的傳輸機制,允許網絡適配器直接訪問主機內存,從而大大降低了延遲,并提高了吞吐量。
目前, 大致有三類RDMA網絡,分別是Infiniband(IB),internet Wide Area RDMA Protocol(iWARP)和RDMA over Converged Ethernet(RoCE) 。其中,Infiniband是一種專為RDMA設計的網絡,從硬件級別保證可靠傳輸 ,而RoCE 和 iWARP都是基于以太網的RDMA技術,支持相應的verbs接口。如下:
- InfiniBand:設計之初就考慮了 RDMA,重新設計了物理鏈路層、網絡層、傳輸層,從硬件級別,保證可靠傳輸,提供更高的帶寬和更低的時延。但是成本高,需要支持IB網卡和交換機。
- iWARP:基于TCP的RDMA網絡,利用TCP達到可靠傳輸。相比RoCE,在大型組網的情況下,iWARP的大量TCP連接會占用大量的內存資源,對系統(tǒng)規(guī)格要求更高。可以使用普通的以太網交換機,但是需要支持iWARP的網卡。
- RoCE:基于 Ethernet的RDMA,RoCEv1版本基于網絡鏈路層,無法跨網段,基本無應用。RoCEv2基于UDP,可以跨網段具有良好的擴展性,而且可以做到吞吐,時延相對性能較好,所以是大規(guī)模被采用的方案。RoCE消耗的資源比 iWARP 少,支持的特性比 iWARP 多。可以使用普通的以太網交換機,避免了使用高成本的Infiniband網絡設備,可以降低成本,但是需要支持RoCE的網卡。

RoCE協(xié)議存在RoCEv1和RoCEv2兩個版本,這取決于所使用的網絡適配器或網卡。從 2010 年開始,RMDA 開始引起越來越多的關注,當時IBTA發(fā)布了第一個在融合以太網 (RoCE) 上運行 RMDA 的規(guī)范。然而,最初的規(guī)范將 RoCE 部署限制在單個第 2 層域,因為 RoCE 封裝幀沒有路由功能。2014 年,IBTA 發(fā)布了 RoCEv2,它更新了最初的 RoCE 規(guī)范以支持跨第 3 層網絡的路由,使其更適合超大規(guī)模數據中心網絡和企業(yè)數據中心等。
RoCEv1
2010年4月,IBTA發(fā)布了RoCE,此標準是作為Infiniband Architecture Specification的附加件發(fā)布的,所以也稱為IBoE(InfiniBand over Ethernet)。這時的RoCE標準是在以太鏈路層之上用IB網絡層代替了TCP/IP網絡層,所以不支持IP路由功能。RoCE V1協(xié)議在以太層的typeID是0x8915。
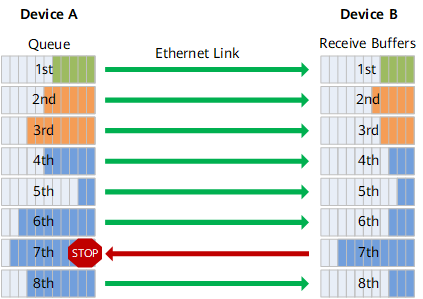
在RoCE中,infiniband的鏈路層協(xié)議頭被去掉,用來表示地址的GUID被轉換成以太網的MAC。Infiniband依賴于無損的物理傳輸,RoCE也同樣依賴于無損的以太傳輸,這一要求會給以太網的部署帶來了成本和管理上的開銷。
以太網的無損傳輸必須依靠L2的QoS支持,比如PFC(Priority Flow Control),接收端在buffer池超過閾值時會向發(fā)送方發(fā)出pause幀,發(fā)送方MAC層在收到pause幀后,自動降低發(fā)送速率。這一要求,意味著整個傳輸環(huán)節(jié)上的所有節(jié)點包括end、switch、router,都必須全部支持L2 QoS,否則鏈路上的PFC就不能在兩端發(fā)揮有效作用。
RoCEv2
由于RoCEv1的數據幀不帶IP頭部,所以只能在L2子網內通信。為了解決此問題,IBTA于2014年提出了RoCE V2,RoCEv2擴展了RoCEv1,通過改變數據包封裝,將GRH(Global Routing Header)換成UDP header +IP header,RoCE v2現(xiàn)在可以跨L2和L3網絡使用。
針對RoCE v1和RoCE v2,以下兩點值得注意:
- RoCE v1(Layer 2)運作在Ehternet Link Layer(Layer 2)所以Ethertype 0x8915,所以正常的Frame大小為1500 bytes,而Jumbo Frame則是9000 bytes。
- RoCE v2(Layer 3)運作在UDP/IPv4或UDP/IPv6之上(Layer 3),采用UDP Port 4791進行傳輸。因為 RoCE v2的封包是在 Layer 3上可進行路由,所以有時又會稱為Routable RoCE或簡稱RRoCE。
RoCE,無損先行
由于RDMA要求承載網絡無丟包,否則效率就會急劇下降,所以RoCE技術如果選用以太網進行承載,就需要通過PFC,ECN以及DCQCN等技術對傳統(tǒng)以太網絡改造,打造無損以太網絡,以確保零丟包。
PFC:基于優(yōu)先級的流量控制。PFC為多種類型的流量提供基于每跳優(yōu)先級的流量控制。設備在轉發(fā)報文時,通過在優(yōu)先級映射表中查找報文的優(yōu)先級,將報文分配到隊列中進行調度和轉發(fā)。當802.1p優(yōu)先級報文的發(fā)送速率超過接收速率且接收端的數據緩存空間不足時,接收端向發(fā)送端發(fā)送PFC暫停幀。當發(fā)送端收到 PFC 暫停幀時,發(fā)送端停止發(fā)送具有指定 802.1p 優(yōu)先級的報文,直到發(fā)送端收到 PFC XON 幀或老化定時器超時。配置PFC時,特定類型報文的擁塞不影響其他類型報文的正常轉發(fā),
ECN:顯式擁塞通知。ECN 定義了基于 IP 層和傳輸層的流量控制和端到端擁塞通知機制。當設備擁塞時,ECN 會在數據包的 IP 頭中標記 ECN 字段。接收端發(fā)送擁塞通知包(CNP)通知發(fā)送端放慢發(fā)送速度。ECN 實現(xiàn)端到端的擁塞管理,減少擁塞的擴散和加劇。
DCQCN(Data Center Quantized Congestion Notification):目前在RoCEv2網絡種使用最廣泛的擁塞控制算法。融合了QCN算法和DCTCP算法,需要數據中心交換機支持WRED和ECN。DCQCN可以提供較好的公平性,實現(xiàn)高帶寬利用率,保證低的隊列緩存占用率和較少的隊列緩存抖動情況。
為什么RoCE是目前主流的RDMA協(xié)議?
RDMA最早在Infiniband傳輸網絡上實現(xiàn),技術先進,但是價格高昂,后來業(yè)界廠家把RDMA移植到傳統(tǒng)Ethernet以太網上,降低了RDMA的使用成本,推動了RDMA技術普及。在Ethernet以太網上,根據協(xié)議棧融合度的差異,分為iWARP和RoCE兩種技術,而RoCE又包括RoCEv1和RoCEv2 兩個版本 (RoCEv2的最大改進是支持IP 路由 ) ,各RDMA網絡協(xié)議棧的對比如下圖所示。
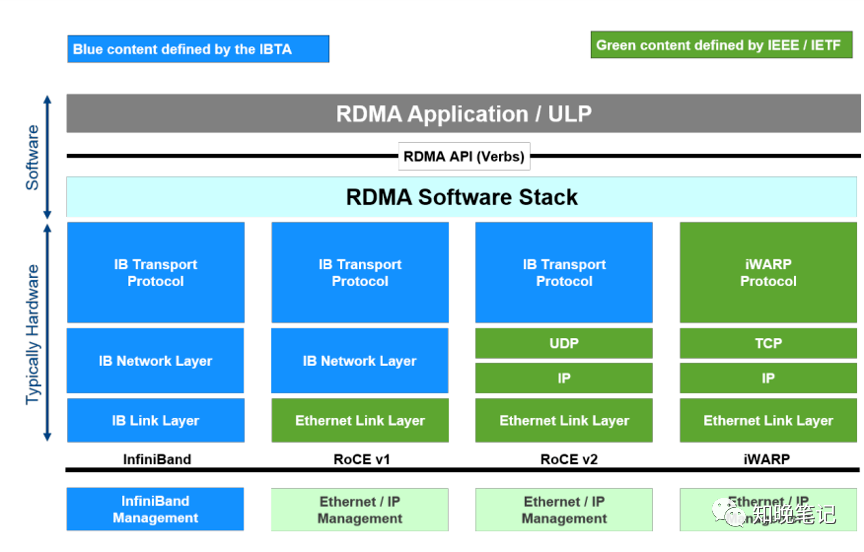
1)iWARP,iWARP協(xié)議棧相比其他兩者更為復雜,并且由于TCP的限制,只能支持可靠傳輸。所以iWARP的發(fā)展不如RoCE和Infiniband。
2)Infiniband協(xié)議本身定義了一套全新的層次架構,從鏈路層到傳輸層,都無法與現(xiàn)有的以太網設備兼容。舉例來看,如果某個數據中心因為性能瓶頸,想要把數據交換方式從以太網切換到Infiniband技術,那么需要購買全套的Infiniband設備,包括網卡、線纜、交換機和路由器等等,成本太高
3)RoCE協(xié)議的優(yōu)勢在這里就很明顯了,用戶從以太網切換到RoCE只需要購買支持RoCE 的網卡就可以了 ( 只需網卡是支持 RoCE ),其他網絡設備都是兼容的。所以RoCE相比于Infiniband****主要優(yōu)勢在于成本更低。
3 、如何實現(xiàn) RoCE ?
實現(xiàn)RoCE,可以安裝支持****RoCE 的網卡或卡驅動程序 。所有以太網NIC都需要RoCE網絡適配器卡。RoCE驅動程序在Red Hat、Linux、Microsoft Windows和其他常見操作系統(tǒng)中使用。RoCE有兩種可用方式:對于網絡交換機,可以選擇使用支持PFC(優(yōu)先流控制)操作系統(tǒng)的交換機;對于機架服務器或主機,需要使用網卡。使用RoCE的好處:
1)低CPU占用率:訪問遠程交換機或服務器的內存,無需消耗遠程服務器上的CPU周期,從而可以充分利用可用帶寬和更高的可伸縮性。
2)零復制:向遠程緩沖區(qū)發(fā)送數據和接收數據。
3)高效:由于RoCE改善了延遲和吞吐量,網絡性能得到了很大提高。
4)節(jié)省成本:借助RoCE,無需購買新設備或更換以太網基礎設施即可處理大量數據,從而大大節(jié)省了公司的資本支出。使用IB必須是支持IB的一整套設備。
-
以太網
+關注
關注
40文章
5582瀏覽量
174765 -
交換機
+關注
關注
21文章
2720瀏覽量
101344 -
網絡適配器
+關注
關注
0文章
42瀏覽量
11756 -
RDMA
+關注
關注
0文章
82瀏覽量
9204 -
TCP通信
+關注
關注
0文章
146瀏覽量
4461
發(fā)布評論請先 登錄
RoCE與IB對比分析(一):協(xié)議棧層級篇
是德科技與中國移動合作開發(fā)RoCE測試方案:首次使用通用測試儀表
在ZTR無配置大規(guī)模中實現(xiàn)的縮放零接觸RoCE技術
RoCE技術在HPC中的應用分析
網卡啟動版本10.2iSCSI RoCE FCoE協(xié)議用戶手冊

什么是RDMA?什么是RoCE網絡技術?
引導版本10.3適用于網卡、iSCSI、FCoE和RoCE協(xié)議用戶手冊
適用于網卡、iSCSI、FCoE和RoCE協(xié)議用戶手冊 引導版本10.4
適用于網卡、iSCSI、FCoE和RoCE協(xié)議 引導版本10.6
深度解讀RoCE v2的核心技術原理
RoCE協(xié)議簡介和應用分析

RoCE與IB對比分析(二):功能應用篇
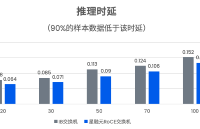
算力革命:RoCE實測推理時延比InfiniBand低30%的底層邏輯





 工商網監(jiān)
工商網監(jiān)
評論