") CVPR2023:IDEA與清華提出首個(gè)一階段3D全身人體網(wǎng)格重建算法
CVPR2023:IDEA與清華提出首個(gè)一階段3D全身人體網(wǎng)格重建算法
三維全身人體網(wǎng)格重建(3D Whole-Body Mesh Recovery)是三維人體重建領(lǐng)域的一個(gè)基礎(chǔ)任務(wù),是人類行為建模的一個(gè)重要環(huán)節(jié),用于從單目圖像中捕獲出準(zhǔn)確的全身人體姿態(tài)和形狀,在人體重建、人機(jī)交互等許多下游任務(wù)中有著廣泛的應(yīng)用。
來(lái)自粵港澳大灣區(qū)研究院(IDEA)與清華大學(xué)深研院的研究者們提出了首個(gè)用于全身人體網(wǎng)格重建的一階段算法OSX,通過(guò)模塊感知的Transformer網(wǎng)絡(luò),高效、準(zhǔn)確地重建出全身人體網(wǎng)格,并提出了一個(gè)大規(guī)模、關(guān)注真實(shí)應(yīng)用場(chǎng)景的上半身人體重建數(shù)據(jù)集UBody.
本文提出的算法從投稿至今(2022.11~2023.04),是AGORA榜單SMPL-X賽道的第一名。該工作已經(jīng)被計(jì)算機(jī)視覺頂會(huì)CVPR2023接收,算法代碼和預(yù)訓(xùn)練模型已經(jīng)全部開源。
三維全身人體網(wǎng)格重建(3D Whole-Body Mesh Recovery)是人類行為建模的一個(gè)重要環(huán)節(jié),用于從單目圖像中估計(jì)出人體姿態(tài)(Body Pose), 手勢(shì)(Hand Gesture)和臉部表情(Facial Expressions),該任務(wù)在許多下游現(xiàn)實(shí)場(chǎng)景中有著廣泛的應(yīng)用,例如動(dòng)作捕捉、人機(jī)交互等。得益于SMPLX等參數(shù)化模型的發(fā)展,全身人體網(wǎng)格重建精度得到了提升,該任務(wù)也得到越來(lái)越多的關(guān)注。
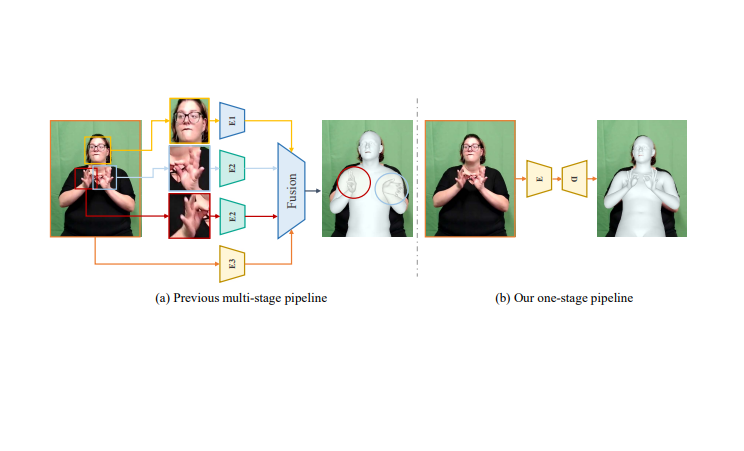
相比于身體姿態(tài)估計(jì)(Body-Only Mesh Recovery),全身人體網(wǎng)格重建需要額外估計(jì)手和臉部的參數(shù),而手和臉部的分辨率往往較小,導(dǎo)致難以通過(guò)一個(gè)一階段的網(wǎng)絡(luò),將全身參數(shù)估計(jì)出來(lái)。之前的方法大多采用多階段的復(fù)制-粘貼(Copy-Paste)框架,提前檢測(cè)出手和臉的包圍框(Bounding Box),將其裁剪出來(lái)并放大,輸入三個(gè)獨(dú)立的網(wǎng)絡(luò),分別估計(jì)出身體(Body), 手(Hand), 和臉(Face)的參數(shù),再進(jìn)行融合。這種多階段的做法可以解決手和臉?lè)直媛蔬^(guò)小的問(wèn)題,然而,由于三部分的參數(shù)估計(jì)相對(duì)獨(dú)立,容易導(dǎo)致最后的結(jié)果以及三部分之間的連接不夠自然和真實(shí),同時(shí)也會(huì)增加模型的復(fù)雜度。為了解決以上問(wèn)題,我們提出了首個(gè)一階段的算法OSX,我們使用一個(gè)模塊感知的Transformer模型,同時(shí)估計(jì)出人體姿態(tài), 手勢(shì)和臉部表情。該算法在較小計(jì)算量和運(yùn)行時(shí)間的情況下,在3個(gè)公開數(shù)據(jù)集(AGORA, EHF, 3DPW)上,超過(guò)了現(xiàn)有的全身人體網(wǎng)格重建算法。
我們注意到,目前的全身人體網(wǎng)格重建數(shù)據(jù)集,大部分是在實(shí)驗(yàn)室環(huán)境或者仿真環(huán)境下采集的,而這些數(shù)據(jù)集與現(xiàn)實(shí)場(chǎng)景有著較大的分布差異。這就容易導(dǎo)致訓(xùn)練出來(lái)的模型在應(yīng)用于現(xiàn)實(shí)場(chǎng)景時(shí),重建效果不佳。此外,現(xiàn)實(shí)中的許多場(chǎng)景,如直播、手語(yǔ)等,人往往只有上半身出現(xiàn)在畫面中,而目前的數(shù)據(jù)集全部都是全身人體,手和臉的分辨率往往較低。為了彌補(bǔ)這方面數(shù)據(jù)集的缺陷,我們提出了一個(gè)大規(guī)模的上半身數(shù)據(jù)集UBody,該數(shù)據(jù)集涵蓋了15個(gè)真實(shí)場(chǎng)景,包括100萬(wàn)幀圖片和對(duì)應(yīng)的全身關(guān)鍵點(diǎn)(2D Whole-Body Keypoint), 人體包圍框(Person BBox)、人手包圍框(Hand BBox)以及SMPLX標(biāo)簽。下圖是UBody的部分?jǐn)?shù)據(jù)可視化。

圖1 UBody數(shù)據(jù)集展示
本工作的貢獻(xiàn)點(diǎn)可以概括為:
我們提出了首個(gè)一階段的全身人體網(wǎng)格重建算法OSX,能夠用一個(gè)簡(jiǎn)單、高效的方式,估計(jì)出SMPLX參數(shù)。
我們的算法OSX在三個(gè)公開數(shù)據(jù)集上,超過(guò)了現(xiàn)有的全身人體網(wǎng)格重建算法。
我們提出了一個(gè)大規(guī)模的上半身數(shù)據(jù)集UBody,用以促進(jìn)全身人體網(wǎng)格重建這個(gè)基礎(chǔ)任務(wù)在現(xiàn)實(shí)場(chǎng)景中的應(yīng)用。
2. 一階段重建算法介紹
2.1 OSX整體框架
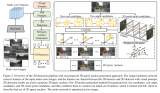
如下圖所示,我們提出了一個(gè)模塊感知(Component-Aware)的Transoformer模型,來(lái)同時(shí)估計(jì)全身人體參數(shù),再將其輸入SMPLX模型,得到全身人體網(wǎng)格。我們注意到,身體姿態(tài)(Body Pose)估計(jì)需要利用到全局的人體依賴信息,而手勢(shì)(Hand Gesture)和臉部表情(Facial Expression)則更多的聚焦于局部的區(qū)域特征。因而,我們?cè)O(shè)計(jì)了一個(gè)全局編碼器和一個(gè)局部解碼器,編碼器借助于全局自注意力機(jī)制(Global Self-attention),捕獲人體的全身依賴關(guān)系,估計(jì)出身體姿態(tài)和形狀(Body Pose and Shape),解碼器則對(duì)特征圖進(jìn)行上采樣,使用關(guān)鍵點(diǎn)引導(dǎo)的交叉注意力機(jī)制(Cross-Attention),用以估計(jì)手和臉部的參數(shù)。
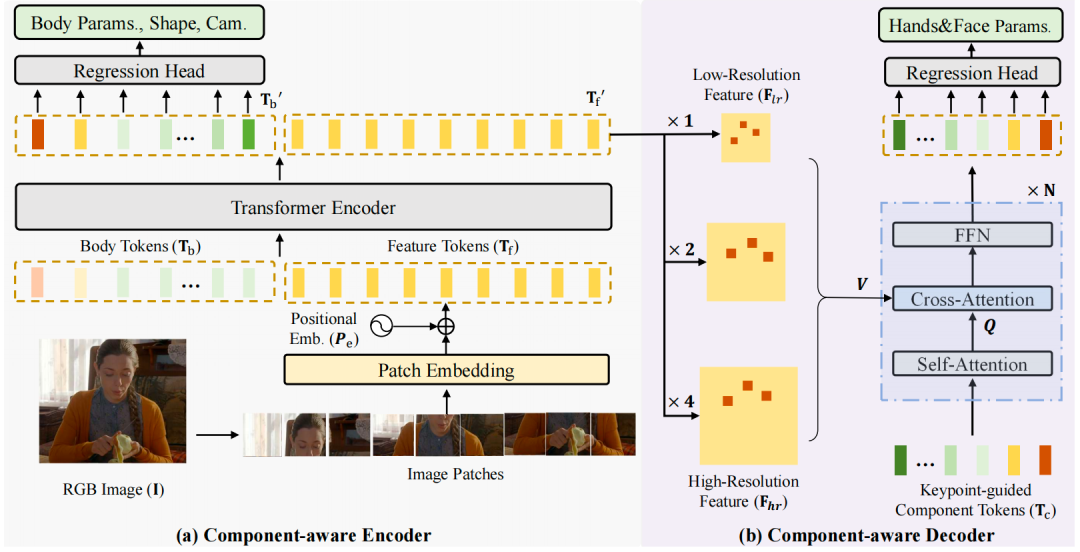
圖2 OSX網(wǎng)絡(luò)結(jié)構(gòu)示意圖
2.2 全局編碼器
在全局編碼器中,人體圖片首先被切為多個(gè)互不重蛩的塊,這些塊通過(guò)一個(gè)卷積層,加上位置編碼,轉(zhuǎn)換為特征令牌(Feature Token) ,接著,我們?cè)賹⑵渑c若干個(gè)由可學(xué)習(xí)參數(shù)構(gòu)成的人體令牌(Body Token) 進(jìn)行連接,輸入全局編碼器。全局編碼 器由多個(gè)Transformer塊組成,每個(gè)塊包含一個(gè)多頭自注意力、一個(gè)前饋網(wǎng)絡(luò)和兩個(gè)層歸一化模塊(Layer Normization)。 經(jīng)過(guò)這些 塊之后,人體各個(gè)部分之間的信息得到了交互,body token 捕捉了人體的全身依賴關(guān)系,輸入全連接層,回歸出人體姿態(tài)和 形狀。 Feature token則進(jìn)行重組(Reshape),轉(zhuǎn)換為特征圖,供解碼器使用。
2.3 高分辨率局部解碼器
在解碼器中,我們首先對(duì)特征圖進(jìn)行上采樣,以解決手和臉?lè)直媛蔬^(guò)低的問(wèn)題。具體的,我們使用一個(gè)可微分的感興趣區(qū)域?qū)R (Region of Interest Alignment)操作,將手和臉部的特征圖進(jìn)行上采樣,因而獲得多尺度的手、臉高分辨率特征 。接著,我們定義多個(gè)模塊令牌(Component Token) ,每一個(gè)token代表一個(gè)關(guān)鍵點(diǎn),將這些token輸入解碼器,通過(guò)關(guān)鍵點(diǎn) 引導(dǎo)的交叉注意力機(jī)制,從高分辨率特征中捕獲有用的信息,更新Component Token:
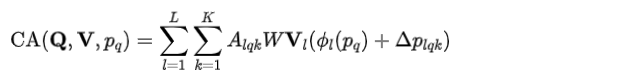
最終,這些模塊token通過(guò)全連接層,轉(zhuǎn)換為手勢(shì)和臉部表情,并與身體姿態(tài)和形狀一起,輸入SMPLX模型,轉(zhuǎn)換為人體網(wǎng)格。
3. 上半身數(shù)據(jù)集UBody介紹
3.1 數(shù)據(jù)集亮點(diǎn)
為了縮小全身人體網(wǎng)格重建這一基礎(chǔ)任務(wù)與下游任務(wù)的差異,我們從15個(gè)現(xiàn)實(shí)場(chǎng)景,包括音樂(lè)演奏、脫口秀、手語(yǔ)、魔術(shù)表演等,收集了超過(guò)100萬(wàn)的圖片,對(duì)其進(jìn)行標(biāo)注。這些場(chǎng)景與現(xiàn)有的數(shù)據(jù)集AGORA相比,由于只包含上半身,因而手和臉的分辨率更大,具有更加豐富的手部動(dòng)作和人臉表情。同時(shí),這些場(chǎng)景含有非常多樣的遮擋、交互、切鏡、背景和光照變化,因而更加具有挑戰(zhàn)性,更加符合現(xiàn)實(shí)場(chǎng)景。此外,UBody是視頻的形式,每個(gè)視頻都包含了音頻(Audio),因而未來(lái)也可以應(yīng)用于多模態(tài)等任務(wù)。

圖3 UBody 15個(gè)場(chǎng)景展示
3.2 IDEA自研高精度全身動(dòng)捕標(biāo)注框架
為了標(biāo)注這些大規(guī)模的數(shù)據(jù),我們提出了一個(gè)自動(dòng)化標(biāo)注方案,如下圖所示,我們首先訓(xùn)練一個(gè)基于ViT的關(guān)鍵點(diǎn)估計(jì)網(wǎng)絡(luò),估計(jì)出高精度的全身人體關(guān)鍵點(diǎn)。接著,我們使用一個(gè)多階段漸進(jìn)擬合技術(shù)(Progreesive Fitting),將OSX輸出的人體網(wǎng)格轉(zhuǎn)換為三維關(guān)鍵點(diǎn)(3D Keypoints),并投影到圖像平面,與估計(jì)的二維關(guān)鍵點(diǎn)(2D Keypoints)計(jì)算損失,用以優(yōu)化OSX網(wǎng)絡(luò)參數(shù),直至估計(jì)出來(lái)的網(wǎng)格與2D關(guān)鍵點(diǎn)能夠高度貼合。

圖4 全身動(dòng)捕標(biāo)注框架圖
以下是UBody數(shù)據(jù)集的15個(gè)場(chǎng)景及其標(biāo)注結(jié)果的展示:

SignLanguage

Singing

OnlineClass

Olympic

Entertainment

Fitness

LiveVlog

Conference

TVShow

ConductMusic

Speech

TalkShow

MagicShow
4. 實(shí)驗(yàn)結(jié)果
4.1 定量實(shí)驗(yàn)對(duì)比
OSX從投稿至今(2022.11~2023.04),是AGORA榜單上SMPLX賽道的榜首,在AGORA-test (https://agora-evaluation.is.tuebingen.mpg.de/)上的定量對(duì)比結(jié)果如下表所示:
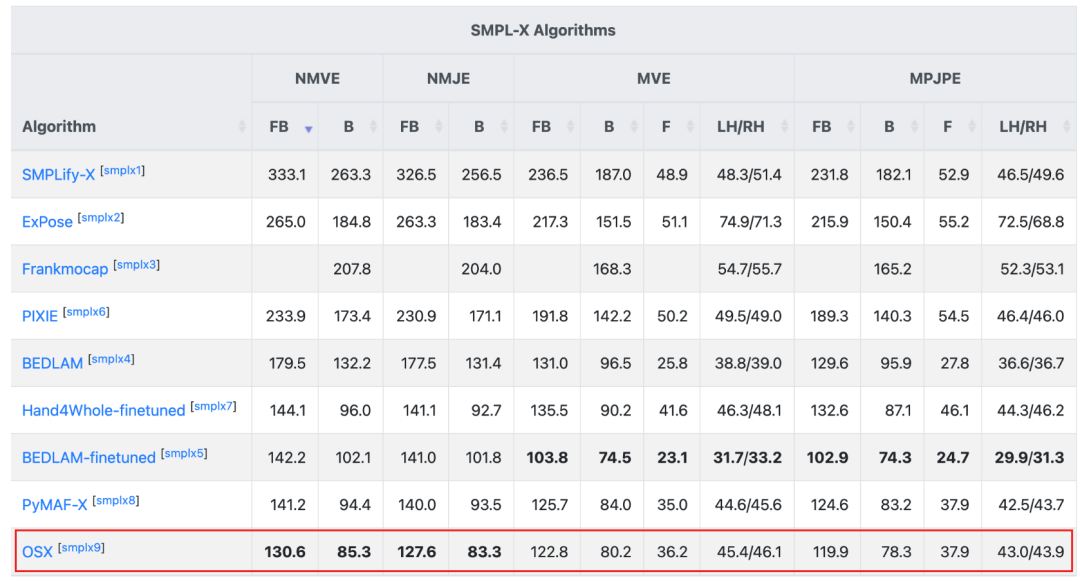
表1 OSX與SOTA算法在AGORA-test上的定量結(jié)果
在AGORA-val上的定量對(duì)比結(jié)果如下表所示:
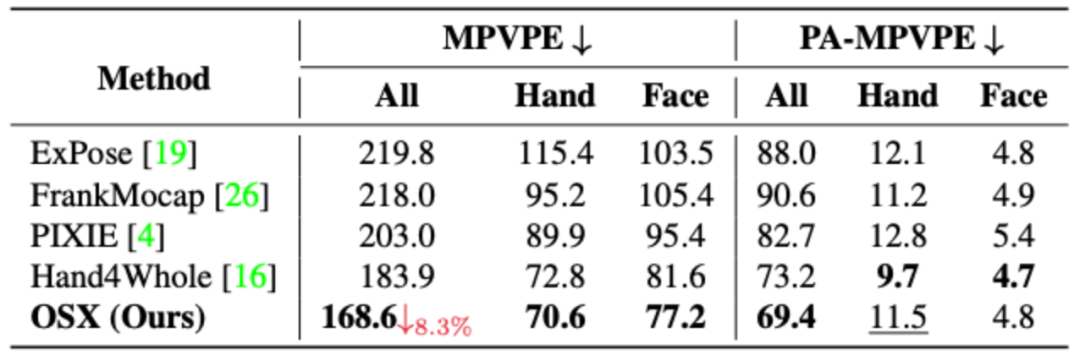
表2 OSX與SOTA算法在AGORA-val上的定量結(jié)果
在EHF和3DPW的定量結(jié)果如下:
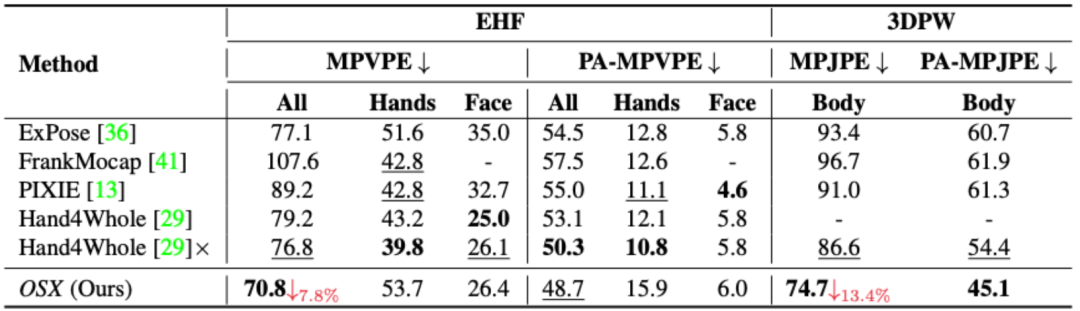
表3 OSX與SOTA算法在EHF及3DPW上的定量結(jié)果
可以看出,OSX由于使用了模塊感知的Transformer網(wǎng)絡(luò),能夠同時(shí)保證全局依賴關(guān)系的建模和局部特征的捕獲,在現(xiàn)有數(shù)據(jù)集,特別是AGORA這一較為困難的數(shù)據(jù)集上,顯著超過(guò)了之前的方法。
4.2 定性實(shí)驗(yàn)對(duì)比
在AGORA上的定性對(duì)比結(jié)果如圖所示:

從左到右依次為:輸入圖, ExPose, Hand4Whole, OSX(Ours)
在EHF上的定性對(duì)比結(jié)果如圖所示:

從左到右依次為:輸入圖, ExPose, Hand4Whole, OSX(Ours)
在UBody數(shù)據(jù)集上的對(duì)比結(jié)果如圖所示:

從左到右依次為:輸入圖, ExPose, Hand4Whole, OSX(Ours)
可以看出,我們的算法OSX能夠估計(jì)出更加準(zhǔn)確的身體姿勢(shì),手部動(dòng)作和臉部表情,重建出來(lái)的人體網(wǎng)格更加準(zhǔn)確,與原圖貼合的更好,更加魯棒。
5. 總結(jié)
OSX是首個(gè)一階段全身人體網(wǎng)格重建的算法,通過(guò)一個(gè)模塊感知的Transformer模型,同時(shí)估計(jì)了body pose, hand pose和facial experssion,在三個(gè)公開榜單上取得了目前最好whole-body mesh recovery最好的結(jié)果。此外,我們提出了一個(gè)大規(guī)模的上半身場(chǎng)景數(shù)據(jù)集UBody,用以促進(jìn)人體網(wǎng)格重建任務(wù)在下游場(chǎng)景中的應(yīng)用。我們的代碼已經(jīng)進(jìn)行了開源,希望能夠推動(dòng)該領(lǐng)域的發(fā)展。
審核編輯 :李倩
-
算法
+關(guān)注
關(guān)注
23文章
4698瀏覽量
94721 -
網(wǎng)格
+關(guān)注
關(guān)注
0文章
140瀏覽量
16269 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1222瀏覽量
25275
原文標(biāo)題:CVPR2023:IDEA與清華提出首個(gè)一階段3D全身人體網(wǎng)格重建算法,代碼開源!
文章出處:【微信號(hào):3D視覺工坊,微信公眾號(hào):3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
如何將一個(gè)3D散點(diǎn)圖與3D網(wǎng)格圖在一個(gè)三維坐標(biāo)系中顯示呢?
【ELT.ZIP】OpenHarmony啃論文俱樂(lè)部——即刻征服3D網(wǎng)格壓縮編碼
基于約束的地質(zhì)網(wǎng)格曲面重建算法
一種基于量化方法的3D模型盲水印算法
基于STL曲面網(wǎng)格重建算法
基于局部姿態(tài)先驗(yàn)的深度圖像3D人體運(yùn)動(dòng)捕獲方法
FAIR和INRIA的合作提出人體姿勢(shì)估計(jì)新模型,適用于人體3D表面構(gòu)建
我國(guó)首個(gè)衛(wèi)星物聯(lián)網(wǎng)完成第一階段建設(shè)
3D的感知技術(shù)及實(shí)踐

大規(guī)模3D重建的Power Bundle Adjustment
用于快速高保真RGB-D表面重建的神經(jīng)特征網(wǎng)格優(yōu)化的GO-Surf
生成高質(zhì)量 3D 網(wǎng)格,從重建到生成式 AI

NeurIPS 2023 | 清華ETH提出首個(gè)二值化光譜重建算法

3D人體生成模型HumanGaussian實(shí)現(xiàn)原理
Nullmax提出多相機(jī)3D目標(biāo)檢測(cè)新方法QAF2D





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論