") 淺析從同步到RCU的引入
淺析從同步到RCU的引入

一、從同步開始
1.1 同步的產(chǎn)生
在閱讀或者編寫內(nèi)核代碼的時(shí)候,總是需要帶著一個(gè)默認(rèn)的前提條件:任意的一條執(zhí)行流,都可能在任意一條指令之后被中斷執(zhí)行,然后在并不確定的時(shí)間后再次回來(lái)執(zhí)行。
因此,常常需要考慮一個(gè)問(wèn)題:指令在被中斷到回到斷點(diǎn)繼續(xù)執(zhí)行的這個(gè)過(guò)程中,原本所依賴的執(zhí)行環(huán)境是不是會(huì)發(fā)生變化,對(duì)應(yīng)的問(wèn)題是,指令執(zhí)行所依賴的環(huán)境是獨(dú)享的還是共享的。如果它的獨(dú)享的,那就是安全的,而如果是共享的,那就可能存在被意外修改的問(wèn)題,由此引發(fā)一些同步問(wèn)題。處理同步問(wèn)題,通常是通過(guò)原子變量、加鎖這些同步機(jī)制來(lái)解決。
而大部分工程師對(duì)于是否使用同步機(jī)制的判斷基于一個(gè)樸素的觀念:全局變量的操作需要加鎖,而局部變量并不需要。
在絕大多數(shù)的情況下,這句話是適用的。之所以我將全局和局部替換為共享與獨(dú)享,是因?yàn)樵谔囟ㄇ闆r下,局部變量并不等于獨(dú)享資源,而全局變量也同樣如此,是否要引入同步機(jī)制這個(gè)問(wèn)題也并不是一成不變的,比如下面的幾種情況:
(1) 需要注意的一個(gè)問(wèn)題是,我們通常毫不思索地把返回指向棧上資源的指針這種行為視為絕對(duì)的 bug,但是卻忽略了這個(gè) bug 產(chǎn)生的原因:函數(shù)返回之后棧上的數(shù)據(jù)會(huì)被覆蓋。但是如果函數(shù)沒(méi)有返回呢??jī)?nèi)核中能看到這樣的代碼:在棧上初始化一些資源,然后將其鏈接到全局鏈表上,隨后陷入睡眠,棧上數(shù)據(jù)的生命周期也就保持到了被喚醒之后。既然棧上的數(shù)據(jù)可以導(dǎo)出到其它地方,自然也就由獨(dú)享變成了共享,也就需要考慮同步問(wèn)題。
(2) 當(dāng)我們把視線全部聚焦在數(shù)據(jù)上時(shí),或者像第一點(diǎn)提到的理所當(dāng)然地認(rèn)為棧就應(yīng)該是獨(dú)占的時(shí)候,其實(shí)我們忽略了它們本身存在的形式:不論是指令、亦或者是數(shù)據(jù),棧區(qū)也好,堆區(qū)也罷,它們都是存在于內(nèi)存當(dāng)中,而內(nèi)存本身的硬件屬性是可讀可寫的。而諸如代碼段只讀,棧獨(dú)立于每個(gè)進(jìn)程只是操作系統(tǒng)賦予它們的屬性,如果我們只是操作系統(tǒng)的使用者,自然可以默認(rèn)這些規(guī)律,但是如果我們是開發(fā)者,是不是存在修改代碼段或者其它非數(shù)據(jù)部分的需求?而這些修改又會(huì)不會(huì)存在同步問(wèn)題呢?所以有時(shí)候同步問(wèn)題并不僅僅局限于數(shù)據(jù)。
(3) 有些全局變量的定義可能僅僅是為了擴(kuò)大訪問(wèn)范圍,或者雖然它是共享資源,但是在特定場(chǎng)景下并沒(méi)有并發(fā)產(chǎn)生,(比如 per-task 的變量,percpu 變量)。因此,對(duì)于產(chǎn)生同步問(wèn)題來(lái)說(shuō),共享只是其中一個(gè)必要條件,它還有另一個(gè)必要條件:同時(shí)操作。也就是多條執(zhí)行流同時(shí)訪問(wèn)同一個(gè)共享資源。
同時(shí)操作中的同時(shí)如何理解?時(shí)間刻度下的同一時(shí)刻?如果是這樣判定,那從來(lái)就不存在真正意義上的同時(shí),我們所定義的同時(shí)是在 A 還沒(méi)完成某項(xiàng)工作的情況下,B 也參與進(jìn)來(lái),這種情況就視為 A 與 B 同時(shí)做這項(xiàng)工作。
比如,在單核環(huán)境下并不存在代碼執(zhí)行的同時(shí),所有代碼都是串行執(zhí)行的,但是依舊會(huì)產(chǎn)生同步問(wèn)題,比如 i++。這是因?yàn)椋珻 語(yǔ)言的最小粒度并非指令執(zhí)行的最小粒度,一個(gè) i++ 操作實(shí)際上由 load/modified/store 指令組成,如果在執(zhí)行 load 指令完成之后被打斷,在其它執(zhí)行流再操作 i,從 C 語(yǔ)言的執(zhí)行角度來(lái)說(shuō),i++ 是沒(méi)有被執(zhí)行完的,由此而帶來(lái)的一種”同時(shí)”。而這樣的概念同樣可以引申到復(fù)合結(jié)構(gòu)。
(4)多個(gè)執(zhí)行流對(duì)共享的數(shù)據(jù)進(jìn)行同時(shí)操作,當(dāng)這個(gè)場(chǎng)景出現(xiàn)時(shí),許多工程師會(huì)毫不猶豫地增加同步機(jī)制來(lái)避免出現(xiàn)問(wèn)題。不知道各位盆友有沒(méi)有想過(guò),如果不加鎖,是不是一定會(huì)造成程序上的 bug?要弄清楚這個(gè)問(wèn)題,我們需要知道 CPU 在執(zhí)行時(shí)的一些行為。
首先就是要區(qū)分讀和寫,通常我們所說(shuō)的問(wèn)題其實(shí)就是執(zhí)行讀操作時(shí)讀取到不符合預(yù)料之中的值,隨后的邏輯判斷或者隨后的寫操作就會(huì)出現(xiàn)邏輯問(wèn)題,而這種問(wèn)題就是同時(shí)寫共享資源帶來(lái)的。
另一方面,程序在執(zhí)行時(shí)如果不做同步,會(huì)遇到幾種亂序:
編譯器會(huì)對(duì)程序執(zhí)行優(yōu)化操作,編譯器會(huì)假定所編譯的程序都是在單執(zhí)行流環(huán)境下運(yùn)行的,在此基礎(chǔ)上進(jìn)行優(yōu)化,比如將代碼亂序,將計(jì)算結(jié)果使用寄存器緩存而不寫回內(nèi)存等等,自然地,如果你不希望編譯器這么做,就需要通過(guò) volatile 來(lái)禁用激進(jìn)的優(yōu)化項(xiàng),對(duì)于內(nèi)核而言,通常是使用 WRITE_ONCE/READ_ONCE 接口,或者試用 barrie 屏障防止特定代碼段的亂序行為。
為了進(jìn)一步提高并發(fā)性能,CPU 也會(huì)對(duì)代碼進(jìn)行亂序排列,通常 CPU 只會(huì)保證有邏輯依賴的指令按照順序執(zhí)行,比如一條指令依賴于上一條指令的執(zhí)行結(jié)果,就會(huì)按照順序執(zhí)行。而對(duì)于其它不存在邏輯依賴的指令,則不能保證順序,至于會(huì)怎么亂序,這個(gè)并不能做任何假設(shè),而在多線程多核環(huán)境下,這種亂序會(huì)帶來(lái)問(wèn)題,可以通過(guò) CPU 的屏障來(lái)禁止這種行為。
現(xiàn)代 CPU 弱序的內(nèi)存模型,這和處理器架構(gòu)相關(guān),在較弱的內(nèi)存模型中,寫操作并不會(huì)按照?qǐng)?zhí)行順序提交到內(nèi)存,一個(gè) CPU 寫完之后,另一個(gè) CPU 在下次訪問(wèn)時(shí)并不一定能立刻訪問(wèn)到新值,而且另一個(gè) CPU 的看到寫的順序也是不一定的,只有通過(guò)數(shù)據(jù)屏障或者特定內(nèi)存屏障來(lái)禁止這種行為。
因此,當(dāng)我們了解了程序在不使用同步機(jī)制會(huì)帶來(lái)什么問(wèn)題的情況下,就可以具體問(wèn)題具體分析,即使是針對(duì)同一共享數(shù)據(jù)的同時(shí)操作,比如出現(xiàn)下面的情況,即使不加鎖也不會(huì)出現(xiàn)問(wèn)題:
針對(duì)共享數(shù)據(jù)的只讀
即使存在同時(shí)讀寫,也不一定會(huì)產(chǎn)生 bug,最常見的例子是對(duì) /proc/ 目錄下的某些節(jié)點(diǎn)進(jìn)行設(shè)置操作,該設(shè)置對(duì)應(yīng)一個(gè)全局變量,而內(nèi)核代碼中只會(huì)讀取該變量,這種情況不加同步措施(或者只加編譯器屏障),通常也只會(huì)造成非常短的時(shí)間周期內(nèi)讀者讀到舊值,通常不會(huì)產(chǎn)生邏輯問(wèn)題。
而對(duì)于同時(shí)的寫,在特定應(yīng)用場(chǎng)景下也可以不加鎖。參考下圖:
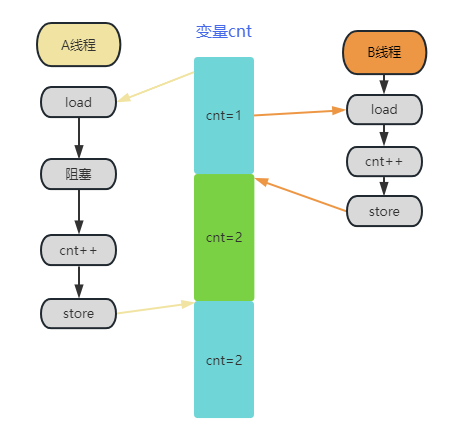
A 線程和 B 線程同時(shí)操作變量 cnt,盡管 A 和 B 都執(zhí)行了 cnt++ 操作,但是 B 的操作被覆蓋了,兩次 ++ 操作最終只有一次產(chǎn)生了效果,看起來(lái)這肯定是有問(wèn)題的。但是在諸如網(wǎng)絡(luò)數(shù)據(jù)包統(tǒng)計(jì)的時(shí)候,這種情況發(fā)生的概率非常低,和所有路徑加鎖帶來(lái)巨大的性能損失相比,統(tǒng)計(jì)值稍微有一點(diǎn)點(diǎn)誤差也不是不能接受,這種情況下我們可以只加一個(gè) WRITE_ONCE 來(lái)限制編譯器優(yōu)化。因此,當(dāng)我們了解了不同的同步措施所帶來(lái)的性能損失以及它實(shí)際能解決什么問(wèn)題的時(shí)候,更多的是做性能與準(zhǔn)確性(也可以是吞吐量、功耗之類的指標(biāo))之間的權(quán)衡,而并不是不由分說(shuō)地加鎖。
1.2 同步機(jī)制
聊到同步問(wèn)題,那自然就離不開它的解決方案:同步機(jī)制,當(dāng)然,我們討論最多的同步機(jī)制就是鎖。既然同步問(wèn)題產(chǎn)生的必要條件是 "共享" 和 "同時(shí)",那只需要破壞其中的某一個(gè)條件,就可以解決同步問(wèn)題。
最簡(jiǎn)單也是最經(jīng)典的方案就是 spinlock 和 mutex,只要接觸過(guò) linux,對(duì)這兩者基本上就不會(huì)陌生,這兩者所實(shí)現(xiàn)的邏輯就是建立一個(gè)臨界區(qū)來(lái)保護(hù)某一個(gè)共享資源的操作,一次只允許一個(gè)訪問(wèn)者進(jìn)入,等該訪問(wèn)者退出的時(shí)候,下一個(gè)再進(jìn)來(lái),破壞了 "同時(shí)" 這個(gè)條件,也就能解決同步問(wèn)題。
spinlock 在無(wú)法獲取鎖的時(shí)候會(huì)選擇自旋等待,而 mutex 無(wú)法獲取鎖的時(shí)候會(huì)選擇睡眠,它們應(yīng)用在不同的場(chǎng)景,對(duì)于一個(gè)操作系統(tǒng)而言,這兩者是必要的。但是很多朋友在看待它們之間的差異的時(shí)候,往往只注意到嘗試持鎖但失敗這個(gè)場(chǎng)景下的不同,而忽略了持鎖之后的差異:
(1) spinlock 持鎖是關(guān)搶占的,但是并不一定關(guān)中斷,也就是說(shuō)在 spinlock 臨界區(qū)中,不會(huì)出現(xiàn)調(diào)度,但是可能出現(xiàn)進(jìn)程環(huán)境的切換,比如中斷、軟中斷,這在某些場(chǎng)景下是需要考慮的。
(2) 而 mutex 是不能應(yīng)用在中斷環(huán)境下的,所以可以不用考慮進(jìn)程運(yùn)行環(huán)境的切換,但是 mutex 并不關(guān)搶占,所以 mutex 也會(huì)帶來(lái)嵌套持鎖的復(fù)雜問(wèn)題。
如果要深入研究代碼實(shí)現(xiàn)甚至對(duì)它們進(jìn)行優(yōu)化,這兩個(gè)問(wèn)題是無(wú)法回避的。而如果只是使用 spinlock、mutex 作為同步措施保護(hù)特定全局?jǐn)?shù)據(jù),這兩個(gè)問(wèn)題并不需要過(guò)多考慮,而且如果沒(méi)有其它方面諸如性能的需求,你只需要知道 mutex 和 spinlock 這兩個(gè)簡(jiǎn)單的接口就能應(yīng)付工作。
當(dāng)然,如果你是一個(gè)對(duì)事物本源有好奇心的朋友,可以再深入思考 spinlock(mutex) 的實(shí)現(xiàn)原理,就會(huì)發(fā)現(xiàn)一個(gè)矛盾點(diǎn):spinlock 的作用是對(duì)全局?jǐn)?shù)據(jù)的同時(shí)操作做互斥保護(hù),讓一個(gè)訪問(wèn)者進(jìn)入而其它訪問(wèn)者等待,而讓一個(gè)訪問(wèn)者進(jìn)入而其它訪問(wèn)者等待,做這件事本身就需要線程之間的通信。
換句話說(shuō),在 spinlock 的實(shí)現(xiàn)中,等待線程要知道鎖已經(jīng)被占用,而占用者在嘗試持鎖之初要知道自己已經(jīng)占用鎖,它們也必須通過(guò)訪問(wèn)某個(gè)全局的資源才能獲得這個(gè)信息,這是不是又產(chǎn)生了對(duì)某一個(gè)共享資源的同時(shí)訪問(wèn)?那誰(shuí)又來(lái)保護(hù) spinlock 本身的實(shí)現(xiàn)呢?
軟件無(wú)法解決,那就需要借助硬件來(lái)實(shí)現(xiàn),因此每個(gè)不同的硬件架構(gòu)都至少需要實(shí)現(xiàn)對(duì)單字長(zhǎng)變量的原子操作指令,比如 64 位平臺(tái)下,硬件必須支持一類或一組指令,該指令保證對(duì)一個(gè) long 型變量執(zhí)行諸如 ++ 操作時(shí),保證它的原子性。
借助于這個(gè)原子性的硬件操作,spinlock 就可以這樣實(shí)現(xiàn):先請(qǐng)求鎖的,就可以通過(guò)原子操作獲取到某個(gè)全局變量的所有權(quán),而后請(qǐng)求鎖的,必須等待之前的 owner 釋放其所有權(quán),也就是 unlock,而上面說(shuō)到的某個(gè)全局變量,就是鎖變量。
因此可以看到,對(duì)共享的全局?jǐn)?shù)據(jù)的操作,變成了對(duì)鎖的競(jìng)爭(zhēng),而對(duì)鎖的競(jìng)爭(zhēng)實(shí)際上就是對(duì)鎖變量的競(jìng)爭(zhēng),本質(zhì)上就是將復(fù)合數(shù)據(jù)的保護(hù)收斂成單字長(zhǎng)變量的保護(hù),然后使用硬件的原子指令來(lái)解決這個(gè)問(wèn)題。
舉個(gè)例子,多個(gè)執(zhí)行流對(duì)某個(gè) struct foo 結(jié)構(gòu)實(shí)例有讀寫操作,為了防止同步問(wèn)題,這些執(zhí)行流從競(jìng)爭(zhēng) struct foo 變成競(jìng)爭(zhēng) foo->spinlock,而 spinlock 是基于鎖變量lock->val實(shí)現(xiàn)的,所以,實(shí)際上所有執(zhí)行流競(jìng)爭(zhēng)的是鎖變量。基于此,不難發(fā)現(xiàn),鎖的實(shí)現(xiàn)并非消除了競(jìng)爭(zhēng),它只是將競(jìng)爭(zhēng)縮小到單變量的范圍。
而在隨后的發(fā)展中,因?yàn)樾枰胶庋舆t、吞吐量、功耗等因素,漸漸地對(duì)鎖又加入了更多的邏輯,比如 mutex 最開始實(shí)現(xiàn)了排隊(duì)機(jī)制,后續(xù)為了減少上下文切換引入樂(lè)觀自旋,又為了解決樂(lè)觀自旋帶來(lái)的公平性問(wèn)題引入 handoff 機(jī)制。而它的表兄弟 rwsem 在 mutex 的基礎(chǔ)上進(jìn)一步區(qū)分讀寫,實(shí)現(xiàn)則更加復(fù)雜。
俗話說(shuō),是藥三分毒,鎖是解決同步問(wèn)題的一劑猛藥,但是它帶來(lái)的問(wèn)題也不容小覷:
死鎖、餓死這些常見且直接導(dǎo)致系統(tǒng)死機(jī)。
鎖只是緩解競(jìng)爭(zhēng),而不是根治,所以競(jìng)爭(zhēng)依舊存在,在激烈條件下開銷依舊不小。
鎖實(shí)現(xiàn)越來(lái)越趨于復(fù)雜,也會(huì)消耗指令周期和 cache 空間,而且這種復(fù)雜度讓量化分析變得越來(lái)越難。
具體的鎖有具體的問(wèn)題,比如spinlock 機(jī)制會(huì)帶來(lái) cpu 的空轉(zhuǎn),在某些競(jìng)爭(zhēng)激烈的場(chǎng)景下,8 個(gè) cpu 同時(shí)競(jìng)爭(zhēng)同一個(gè) spinlock 鎖,因?yàn)殛P(guān)搶占的原因,這 8 個(gè) CPU 上除了處理中斷,再也做不了任何事,只是空轉(zhuǎn)浪費(fèi) CPU 資源。而 mutex 所帶來(lái)的無(wú)效喚醒以及本身的進(jìn)程切換也是有不小的開銷,比如 mutex 的環(huán)境下,當(dāng)多個(gè) cpu 在競(jìng)爭(zhēng)同一把鎖時(shí),不良的鎖使用或者不合時(shí)宜的設(shè)計(jì)會(huì)導(dǎo)致很多的無(wú)效喚醒,也就是很多進(jìn)程被喚醒之后卻無(wú)法獲取鎖,只能再次睡下,而這些開銷都是一種資源的浪費(fèi),在重載環(huán)境下這種浪費(fèi)程度是非常大的.
這些都是鎖本身的實(shí)現(xiàn)問(wèn)題,來(lái)自于性能、公平性、吞吐量之間不可調(diào)和的矛盾,而鎖競(jìng)爭(zhēng)所花費(fèi)的時(shí)間完全是產(chǎn)生不了任何效益的。
當(dāng)解決方案本身成為最大的問(wèn)題,當(dāng)屠龍的少年即將成為新的惡龍,我們不得不轉(zhuǎn)而去尋找更合適的同步方案。
1.3 其它同步解決方案
當(dāng)通用的鎖方案無(wú)法更進(jìn)一步時(shí),另一個(gè)方向是拆分使用場(chǎng)景,尋找特定場(chǎng)景下的針對(duì)性解決方案。
一種想法是繼續(xù)沿用鎖的形式,但是區(qū)分讀寫,因?yàn)樽x寫的性質(zhì)是完全不一樣的。
在上面的描述中,對(duì)共享資源進(jìn)行操作的角色我們統(tǒng)稱為訪問(wèn)者,但是從實(shí)際的硬件角度出發(fā),發(fā)現(xiàn)讀和寫對(duì)于共享數(shù)據(jù)的操作有根本性的不同,而寫操作通常才是帶來(lái)同步問(wèn)題的罪魁禍?zhǔn)祝槍?duì)多讀少寫的場(chǎng)景,在 spinlock、mutex 的基礎(chǔ)上衍生出了 rwlock、rwsem(rwsem 其實(shí)并沒(méi)有信號(hào)量的語(yǔ)義,它更像是睡眠版的 rwlock)。
另一種是無(wú)鎖設(shè)計(jì),無(wú)鎖設(shè)計(jì)也分成很多種類型,第一種是干脆不使用同步機(jī)制,或者最小化使用同步機(jī)制,因?yàn)槟承﹫?chǎng)景下,全局?jǐn)?shù)據(jù)的不同步是可以接受的。這一點(diǎn)在上面已經(jīng)論證過(guò)了。
另外的較常見的無(wú)鎖方案,通過(guò)結(jié)合應(yīng)用場(chǎng)景采用更細(xì)化的設(shè)計(jì),只使用硬件提供的原子操作,而不引入諸如 spinlock 這一類復(fù)雜的鎖邏輯,從而避免在鎖上消耗太多 CPU 資源。
除此之外,一種二次確認(rèn)的機(jī)制也比較常用,因?yàn)槟承┕蚕頂?shù)據(jù)的操作可能會(huì)帶來(lái)同步問(wèn)題,如果產(chǎn)生并發(fā)條件的概率足夠低,直接采用鎖有時(shí)候并沒(méi)有必要,我們大可以直接使用無(wú)鎖下的操作,然后對(duì)操作結(jié)果進(jìn)行檢查,如果結(jié)果不符合我們的預(yù)期,那就重新執(zhí)行一遍操作,以保證數(shù)據(jù)被正常更新。
還有很多的無(wú)鎖方案都是針對(duì)”共享”的條件來(lái)做的,比如使用額外的內(nèi)存來(lái)避免競(jìng)爭(zhēng)的產(chǎn)生,其中使用最多的就是內(nèi)核中的 percpu 機(jī)制,盡管大多數(shù)工程師通常并不會(huì)將它看成是一種同步的解決方案,但是它卻實(shí)際上地解決了同步問(wèn)題產(chǎn)生的"共享"這個(gè)條件,也就是將原本 cpu 之間共享的全局?jǐn)?shù)據(jù)分散到每個(gè) cpu 一份,這樣雖然依舊存在進(jìn)程環(huán)境與中斷環(huán)境的同步問(wèn)題,但是卻極大地降低了多 cpu 之間的同步問(wèn)題,從多核收斂到單核的環(huán)境。
同時(shí),針對(duì)一些特定的場(chǎng)景還涌現(xiàn)出一些無(wú)鎖方案,最常見的是在特定場(chǎng)景下存在冷熱路徑,通過(guò)增大冷路徑下的開銷這種設(shè)計(jì)來(lái)實(shí)現(xiàn)熱路徑下的無(wú)鎖方案,而冷熱路徑的定義完全是取決于應(yīng)用場(chǎng)景的,因此這些優(yōu)化都不能作為通用方案,因?yàn)樗鼈兊膶?shí)現(xiàn)是一些特殊情況下的權(quán)衡。
而我們今天要聊到的,RCU,也正是在特定場(chǎng)景下的一種無(wú)鎖方案。
二、RCU 是什么?
2.1 RCU 的基本概念
RCU,read-copy-update,也就是讀-拷貝-更新,其基本思想在于,當(dāng)我們需要對(duì)一個(gè)共享數(shù)據(jù)進(jìn)行操作的時(shí)候,我們可以先復(fù)制一份原有的數(shù)據(jù) B,將需要更新的部分在 B 上實(shí)現(xiàn),然后再使用 B 替換掉 A,這也是 RCU 最典型的使用場(chǎng)景。
很顯然,這種無(wú)鎖方案所針對(duì)的是 "共享" 這個(gè)特性,畢竟并不直接對(duì)目標(biāo)數(shù)據(jù)進(jìn)行操作。
從這個(gè)理念出發(fā),其實(shí)我們可以非常直觀地感受到 RCU 的第一個(gè)特點(diǎn):RCU 是針對(duì)多讀少寫的使用場(chǎng)景的,畢竟這種形式的實(shí)現(xiàn)明顯加大了寫端的開銷。
RCU 的設(shè)計(jì)理念簡(jiǎn)單到任何人在第一次聽到時(shí)就能夠理解它,但是當(dāng)我們嘗試像 spinlock 那樣通過(guò)它的 lock/unlock 接口來(lái)閱讀它的代碼實(shí)現(xiàn)時(shí),居然驚奇地發(fā)現(xiàn)它的 lock/unlock 實(shí)現(xiàn)僅僅只是開關(guān)一下?lián)屨迹诙啻未_認(rèn)內(nèi)核配置沒(méi)有問(wèn)題之后,發(fā)現(xiàn)事實(shí)確實(shí)是如此,從而產(chǎn)生一種很荒謬的感覺(jué):僅僅通過(guò)開關(guān)搶占是怎么實(shí)現(xiàn)讀-拷貝-更新的?
2.2 RCU 實(shí)現(xiàn)的核心問(wèn)題是什么?
很多對(duì) RCU 感興趣的朋友其實(shí)在網(wǎng)上也看過(guò)不少 RCU 相關(guān)的文章,知道了 RCU 的操作形式:讀-拷貝-更新,并自然而然地覺(jué)得這是個(gè)很好的想法,而且它好像確實(shí)不需要鎖來(lái)實(shí)現(xiàn),因?yàn)楦虏僮骱驮咀x者讀到的是不同的數(shù)據(jù),不滿足共享的條件,隨后再執(zhí)行替換就好了。而且,這三個(gè)操作步驟完全就可以由使用者自己完成,實(shí)在是想不到有什么地方需要操作系統(tǒng)來(lái)插手的。
如果一個(gè)問(wèn)題想不明白,那么我們就代入到真實(shí)的場(chǎng)景下來(lái)考慮這個(gè)問(wèn)題:假設(shè)現(xiàn)在有 3 個(gè)讀者和 1 個(gè)更新者需要對(duì)共享數(shù)據(jù)進(jìn)行訪問(wèn),讀者不間斷地對(duì)數(shù)據(jù)發(fā)起讀操作,而更新者需要更新時(shí),拷貝出一份新的數(shù)據(jù),操作完之后然后再替換舊的數(shù)據(jù),這樣就完成了數(shù)據(jù)的更新,而讀者就可以讀到新的數(shù)據(jù)。
看起來(lái)非常合理,效率也很高,但是這里有一個(gè)最大的問(wèn)題在于,我們默認(rèn)了一個(gè)并不存在的前提條件:新數(shù)據(jù)的替換立馬就對(duì)所有的讀者生效,替換之后就可以立刻刪除舊數(shù)據(jù),而讀者也可以立刻讀到新的數(shù)據(jù)。
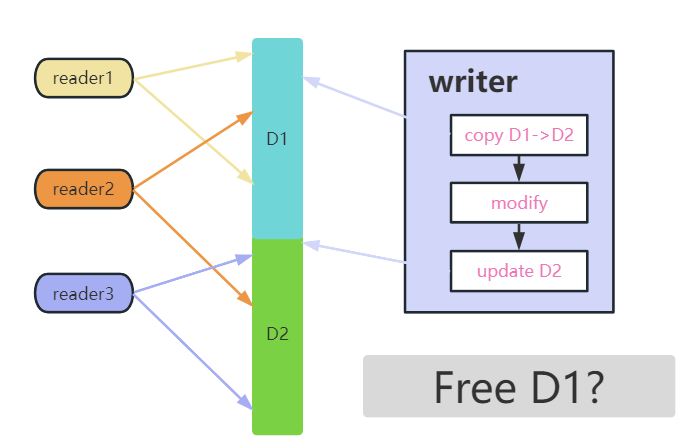
我們可以通過(guò)上圖來(lái)了解這個(gè)流程,其中存在三個(gè)讀者,讀者的兩個(gè)箭頭標(biāo)定讀操作的開始點(diǎn)和結(jié)束點(diǎn),中間的表示共享數(shù)據(jù)。
從圖中可以看到,writer 先是從 D1 copy 出一份 D2,接著對(duì)D2 執(zhí)行修改,緊接著將 D2 更新為新的共享數(shù)據(jù),這個(gè)過(guò)程就可以理解為一次 Read-Copy-Update 操作。
而在整個(gè)過(guò)程中,reader1 始終讀到 D1 數(shù)據(jù),而reader3 始終讀到 D2 的新數(shù)據(jù),但是 reader2 就比較麻煩了,它的讀操作跨越了 D1 到 D2 的更新過(guò)程,那么它讀到的是 D1 還是 D2,又或者說(shuō)讀到一半 D1 的數(shù)據(jù)和另一半 D2 的數(shù)據(jù)?
按照傳統(tǒng)的同步鎖做法,這時(shí)候需要寫者等所有舊讀者退出,然后讀者等待寫者更新完,才繼續(xù)進(jìn)讀臨界區(qū),對(duì)應(yīng)上圖就是 writer 必須等 reader2 先讀完再執(zhí)行更新。你有沒(méi)有意識(shí)到,寫者等讀者退出,讀者再等寫者更新完,這個(gè)操作實(shí)際上就是 rwlock 的實(shí)現(xiàn),難道 RCU 操作要基于 rwlock 來(lái)實(shí)現(xiàn)?那為什么我不直接使用 rwlock 呢?顯然讓替換立刻生效來(lái)實(shí)現(xiàn) RCU 的方式,只能說(shuō)你創(chuàng)造了一個(gè)新的同步機(jī)制,但它永遠(yuǎn)也不會(huì)有人用。
那么為了能超過(guò) rwlock 的性能,一方面不能做讀者與寫者之間的鎖同步,從而讓 RCU 能在特定場(chǎng)景下有性能優(yōu)勢(shì),另一方面,如果不做鎖同步,那就意味著讀者不知道寫者什么時(shí)候更新,寫者也不知道更新時(shí)是否存在讀者,唯一的方案是:即使 writer 在更新完之后,reader2 讀取的依舊是 D1 的舊數(shù)據(jù)(因?yàn)?reader2 不知道數(shù)據(jù)有更新),而更新完之后新來(lái)的讀者讀到的自然是新數(shù)據(jù)。
在這種情況下,也就意味著 RCU 不能像普通鎖一樣保護(hù)復(fù)合結(jié)構(gòu)的實(shí)例,而只能是針對(duì)指向動(dòng)態(tài)資源的數(shù)據(jù)指針,稍微深入地想一想,就能發(fā)現(xiàn),如果D1 和 D2是同一個(gè)結(jié)構(gòu)實(shí)例,D2 會(huì)覆蓋掉 D1 的數(shù)據(jù),就會(huì)產(chǎn)生reader2 讀到一半D1,更新后讀到另一半D2的錯(cuò)誤結(jié)果。而如果在更新完之后reader2依舊需要能夠讀取到 D1,那D1和D2必須是獨(dú)立的兩片內(nèi)存。
之前的問(wèn)題是如何處理跨越更新點(diǎn)的讀者,在確定這類讀者依舊讀取舊數(shù)據(jù)之后,現(xiàn)在剩下的問(wèn)題變成了:判斷什么時(shí)候這些讀者讀完了舊數(shù)據(jù),從而可以回收舊數(shù)據(jù)的資源?
這就是內(nèi)核中 RCU 實(shí)現(xiàn)所需要解決的問(wèn)題:如何低成本地實(shí)現(xiàn)等待依舊正在訪問(wèn)舊數(shù)據(jù)的讀者退出?而讀-拷貝-更新操作,完全可以留給用戶自己做,所以,RCU 在內(nèi)核中的實(shí)現(xiàn)實(shí)際上并不是 Read-Copy-Update 操作,而是實(shí)現(xiàn)一種等待讀者退出臨界區(qū)的機(jī)制。
同時(shí),由于通常情況下,RCU 等待所有舊讀者退出之后,主要的操作就是釋放舊數(shù)據(jù),所以它的實(shí)現(xiàn)也很像一種垃圾回收機(jī)制。
結(jié)合上面的兩點(diǎn)問(wèn)題,也就引出 RCU 的另外幾個(gè)特點(diǎn):
即使是在寫者更新完之后,依舊允許讀者讀到舊數(shù)據(jù)。而內(nèi)核的 RCU 實(shí)現(xiàn)需要保證所有能讀到舊數(shù)據(jù)的 RCU 退出,才刪除舊數(shù)據(jù)。
RCU 同步機(jī)制所保護(hù)的對(duì)象不能直接是復(fù)合結(jié)構(gòu),只能保護(hù)動(dòng)態(tài)分配數(shù)據(jù)對(duì)應(yīng)的指針
追求讀端的極限性能,這是 RCU 在內(nèi)核中的立足之本。
2.3 RCU 的實(shí)現(xiàn)討論
如果我上一小節(jié)已經(jīng)將 RCU 在內(nèi)核中實(shí)現(xiàn)的邏輯表達(dá)清楚,且你也已經(jīng)看明白,那下一步需要討論的就是:如何低成本地實(shí)現(xiàn)等待舊的讀者退出臨界區(qū)。也就是從現(xiàn)在開始,我們才真正進(jìn)入到 RCU 的實(shí)現(xiàn)中。
等待一件事情結(jié)束,最常用的也是容易想到的解決方案就是在開始的時(shí)候做一個(gè)標(biāo)記,憑票入場(chǎng),出場(chǎng)退票,這樣只需要通過(guò)判斷出入的記錄是否成對(duì)就能判斷是否還存在沒(méi)有退出者,當(dāng)然,這個(gè)想法在上面已經(jīng)被證實(shí)效率過(guò)低,記錄讀端的起始意味著需要執(zhí)行全局的寫操作,而讀端臨界區(qū)一旦需要執(zhí)行全局的寫操作,在多核上并發(fā)時(shí)就會(huì)產(chǎn)生同步問(wèn)題,這并不好解決,而且開銷并不小,當(dāng)然這個(gè)全局寫操作可以換成 percpu 類型的,從而減少一些性能的損失,不過(guò)這種方式總歸是治標(biāo)不治本,而我們的理想狀態(tài)是讀端沒(méi)有同步開銷,也就是不記錄讀臨界區(qū)的進(jìn)入。
另一個(gè)思路是,我們是否可以借用其它的事件來(lái)完成這個(gè)等待操作?也就是說(shuō)是否能通過(guò)一些既有事件來(lái)判斷我們需要等待的條件已經(jīng)滿足,而不需要進(jìn)行針對(duì)該事件直接的記錄行為。
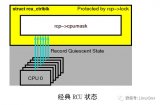
在內(nèi)核中,RCU 的實(shí)現(xiàn)就使用了一種非常巧妙的方式:簡(jiǎn)單地通過(guò)關(guān)-開搶占來(lái)實(shí)現(xiàn)一個(gè)讀臨界區(qū),讀者進(jìn)入臨界區(qū)將會(huì)關(guān)搶占,而退出臨界區(qū)時(shí)再將搶占打開,而進(jìn)程的調(diào)度只會(huì)在搶占開的時(shí)候發(fā)生,因此,寫者等待之前所有的讀者退出,只需要等待所有 cpu 上都執(zhí)行完一次調(diào)度就行了。
這里有必要進(jìn)一步解釋一下,上一段文字中非常重要的幾個(gè)字是:之前所有的讀者。
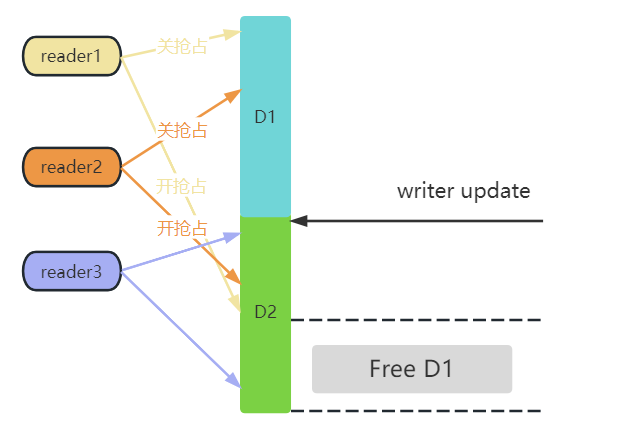
參考上圖,在writer更新之前,reader1 和 reader2 依舊引用的是 D1 數(shù)據(jù),而 reader3 已經(jīng)讀取到新的數(shù)據(jù)了,所以只需要等待 reader1 和 reader2 完成讀操作,就可以釋放 D1 了。
而在 reader1 整個(gè)讀的過(guò)程中,是處于關(guān)搶占的狀態(tài),如果 reader1 運(yùn)行在 cpu0 上,那 writer 更新完之后,只需要判斷 cpu0 上一旦發(fā)生了調(diào)度,就能判斷 reader1 已經(jīng)退出臨界區(qū),畢竟發(fā)生調(diào)度的前提是 cpu0 上開了搶占,也就意味著 reader1 已經(jīng)讀完了。
而更新者更新完數(shù)據(jù)之后,等待所有讀者退出臨界區(qū)這個(gè)過(guò)程,被命名為寬限期(grance period),也就是寬限期一過(guò),也就意味著數(shù)據(jù)的更新以及所有讀者退出這個(gè)過(guò)程已經(jīng)完成,這時(shí)候就可以釋放舊數(shù)據(jù)了,如果是單純的 add 操作,那自然就不需要?jiǎng)h除舊數(shù)據(jù),只需要確認(rèn)更新已經(jīng)完成就好。
當(dāng)然,等待所有之前的讀者退出臨界區(qū)這個(gè)過(guò)程可能會(huì)比較長(zhǎng),甚至到幾十毫秒。因此,在決定是否使用 RCU 作為同步之前需要考慮到這一點(diǎn)。
這也就引出 RCU 的另外兩個(gè)特點(diǎn):
Linux 實(shí)現(xiàn)下的RCU 讀端臨界區(qū)就是通過(guò)關(guān)-開搶占來(lái)實(shí)現(xiàn)的,性能以及多核擴(kuò)展性非常好,但是很明顯讀端臨界區(qū)不支持搶占和睡眠。
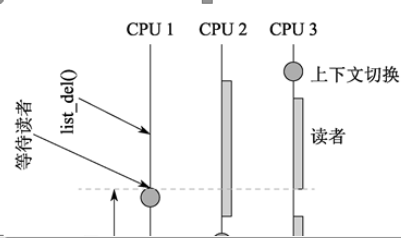
寫端具有一定的延遲。讀端在一定的時(shí)間周期內(nèi)會(huì)獲取到新或者舊數(shù)據(jù)。
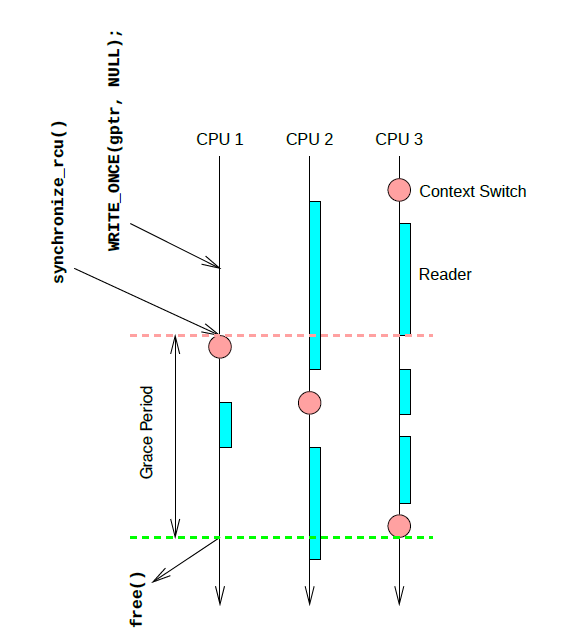
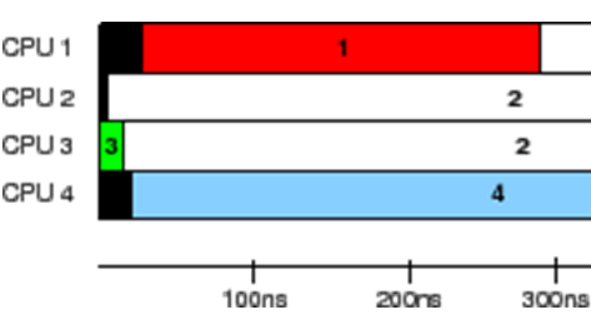
上圖是一個(gè)簡(jiǎn)單的示例,更新端在 CPU1 上對(duì) gptr 執(zhí)行了置 NULL 操作,然后調(diào)用 synchronize_rcu 阻塞等待所有之前的讀者退出臨界區(qū),synchronize_rcu 會(huì)立刻觸發(fā)一次調(diào)度,接著 CPU2 上在執(zhí)行完淺藍(lán)長(zhǎng)條對(duì)應(yīng)的讀端臨界區(qū)之后,執(zhí)行了一次調(diào)度,同時(shí)也意味著 CPU2 已經(jīng)渡過(guò)了臨界區(qū),而在 CPU3 上,實(shí)際上經(jīng)歷了三次進(jìn)入-退出讀臨界區(qū)的階段,但是因?yàn)闆](méi)有觸發(fā)進(jìn)程切換,RCU core 是無(wú)法判斷 CPU3 渡過(guò)了臨界區(qū)的,直到最后 CPU3 執(zhí)行了一次調(diào)度,整個(gè)系統(tǒng)也就渡過(guò)了一個(gè)完整的寬限期,CPU1 上阻塞的 task 得以繼續(xù)運(yùn)行,free 對(duì)應(yīng)的內(nèi)存。
同時(shí),再整體總結(jié)一下 RCU 的特點(diǎn):
RCU 是針對(duì)多讀少寫的使用場(chǎng)景
寫端具有一定的延遲。讀端在一定的時(shí)間周期內(nèi)會(huì)獲取到新或者舊數(shù)據(jù)
即使是在寫者更新完之后,依舊允許讀者讀到舊數(shù)據(jù)。而內(nèi)核的 RCU 實(shí)現(xiàn)需要保證所有能讀到舊數(shù)據(jù)的讀者退出,才刪除舊數(shù)據(jù)
RCU 同步機(jī)制所保護(hù)的對(duì)象不能直接是復(fù)合結(jié)構(gòu),只能是指針
RCU 追求讀端的極限性能,這是 RCU 在內(nèi)核中的立足之本
Linux 實(shí)現(xiàn)下的經(jīng)典RCU 讀端臨界區(qū)就是通過(guò)關(guān)-開搶占來(lái)實(shí)現(xiàn)的,性能以及多核擴(kuò)展性非常好,但是很明顯讀端臨界區(qū)不支持搶占和睡眠
三、結(jié)語(yǔ)
其實(shí)對(duì)于 RCU ,還有很多東西要講,包括RCU的使用、實(shí)現(xiàn)、RCU的變種、RCU的發(fā)展以及源代碼分析之類的,整個(gè) RCU 是一個(gè)非常龐大的體系。
按照我以往的經(jīng)驗(yàn),這種大段的文字且沒(méi)有什么趣味性的東西,篇幅還是不宜過(guò)長(zhǎng),如果各位對(duì) RCU 真的感興趣,下次咱們?cè)僖黄鹱哌M(jìn) RCU 的使用和實(shí)現(xiàn)。
審核編輯:劉清
-
處理器
+關(guān)注
關(guān)注
68文章
19890瀏覽量
235144 -
寄存器
+關(guān)注
關(guān)注
31文章
5434瀏覽量
124453 -
C語(yǔ)言
+關(guān)注
關(guān)注
180文章
7632瀏覽量
141690 -
rcu
+關(guān)注
關(guān)注
0文章
21瀏覽量
5613
原文標(biāo)題:RCU前傳:從同步到RCU的引入
文章出處:【微信號(hào):LinuxDev,微信公眾號(hào):Linux閱碼場(chǎng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
謝寶友教你學(xué)Linux:深入理解Linux RCU之從硬件說(shuō)起
從硬件引申出內(nèi)存屏障,帶你深入了解Linux內(nèi)核RCU
深入理解Linux RCU:經(jīng)典RCU實(shí)現(xiàn)概要
基于Linux內(nèi)核源碼的RCU實(shí)現(xiàn)方案
Linux內(nèi)核RCU鎖的原理與使用
深入理解RCU:玩具式實(shí)現(xiàn)
分級(jí)RCU的基礎(chǔ)知識(shí)
Linux內(nèi)核中RCU的用法
同步電機(jī)失步淺析
linux經(jīng)典的rcu如何實(shí)現(xiàn)?
linux內(nèi)核rcu機(jī)制詳解
深入理解Linux RCU:RCU是讀寫鎖的替代者






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論