") ChatGPT背后的核心技術報告
ChatGPT背后的核心技術報告
輸入幾個簡單的關鍵詞,AI能幫你生成一篇短篇小說甚至是專業(yè)論文。最近大火的ChatGPT在郵件撰寫、文本翻譯、代碼編寫等任務上強大表現,讓埃隆·馬斯克都聲稱感受到了AI的“危險”。ChatGPT的計算邏輯來自于一個名為transformer的算法,它來源于2017年的一篇科研論文《Attention is all your need》。原本這篇論文是聚焦在自然語言處理領域,但由于其出色的解釋性和計算性能開始廣泛地使用在AI各個領域,成為最近幾年最流行的AI算法模型,無論是這篇論文還是transformer模型,都是當今AI科技發(fā)展的一個縮影。以此為前提,本文分析了這篇論文的核心要點和主要創(chuàng)新初衷。
01緣起
從Transformer提出到“大規(guī)模與訓練模型” GPT(Generative Pre-Training)的誕生,再到GPT2的迭代標志Open AI成為營利性公司,以及GPT3和ChatGPT的“出圈”;再看產業(yè)界,多個重要領域比如生物醫(yī)療,智能制造紛紛有以transformer落地的技術產生。在這個浪潮下,我的思考是:
一是,未來很長一段時間在智能化領域,我們都將經歷“科研、算力、基礎架構、工程、數據、解決方案”這個循環(huán)的快速迭代;流動性、創(chuàng)新性短期不會穩(wěn)定下來,而是會越來越強。我們很難等到科技封裝好,把這些知識全部屏蔽掉,再去打磨產品。未來在競爭中獲勝的,將是很好地“解決了產品化和科研及工程創(chuàng)新之間平衡”的團隊。我們一般理解的研發(fā)實際上是工程,但AI的實踐科學屬性需要團隊更好的接納這種“流動性”。因此對所有從業(yè)者或者感興趣智能化的小伙伴了解全棧知識成了一個剛需。
二是,通過對這篇論文的探討,可以更直觀地理解:在科研端發(fā)生了什么,以什么樣的速度和節(jié)奏發(fā)生;哪些是里程碑?是科學界的梅西橫空出世,帶我們發(fā)現真理;哪些是微創(chuàng)新?可能方向明確了,但還有很多空間可以拓展;哪些更像煉金術?仍然在摸索,尚需要很長一段時間,或者一直會保持這個狀態(tài)。
三是,在AI領域,由于技術原因,更多的論文是開源代碼的,一方面,促進了更多人參與進來改進迭代;另一方面,科研跟工程實現無縫連接,一篇論文可以拉動從核心代碼到平臺,到具體應用很大范圍的價值擴散。一篇論文很可能就是一個領域,一條賽道,甚至直接驅動業(yè)務價值和客戶價值的大幅提升。
四是, AI技術發(fā)展有很多領域(感知,認知,感知又分圖像、語音、文字等,認知也可以分出很多層次)之前這些領域的算法邏輯存在很大差別,transformer的出現有一定程度上推動各個領域匯聚的跡象,介紹清楚這篇論文,對把握整體可能有些作用。另外ChatGPT屬于現象級應用,大家更有直觀感受,未來這類應用的體驗提升和更新速度只會更快,理解了其背后的邏輯,更有助于我們把握這個趨勢。
02 論文介紹
下面步入正題,開始介紹這篇論文,會涉及一些技術細節(jié)及公式,可能還需要仔細看一下(先收藏,留出15-20分鐘比較好),相信一旦看進去,你會對AI的理解加深很多。
總體把握
這篇論文的結構非常精煉,提出問題,分析問題,解決問題,給出測試數據。頂刊文章講究言簡意賅,有描述,有代碼,有結果;其中最核心的是以下這張圖,作者團隊提出transformer的核心算法結構:
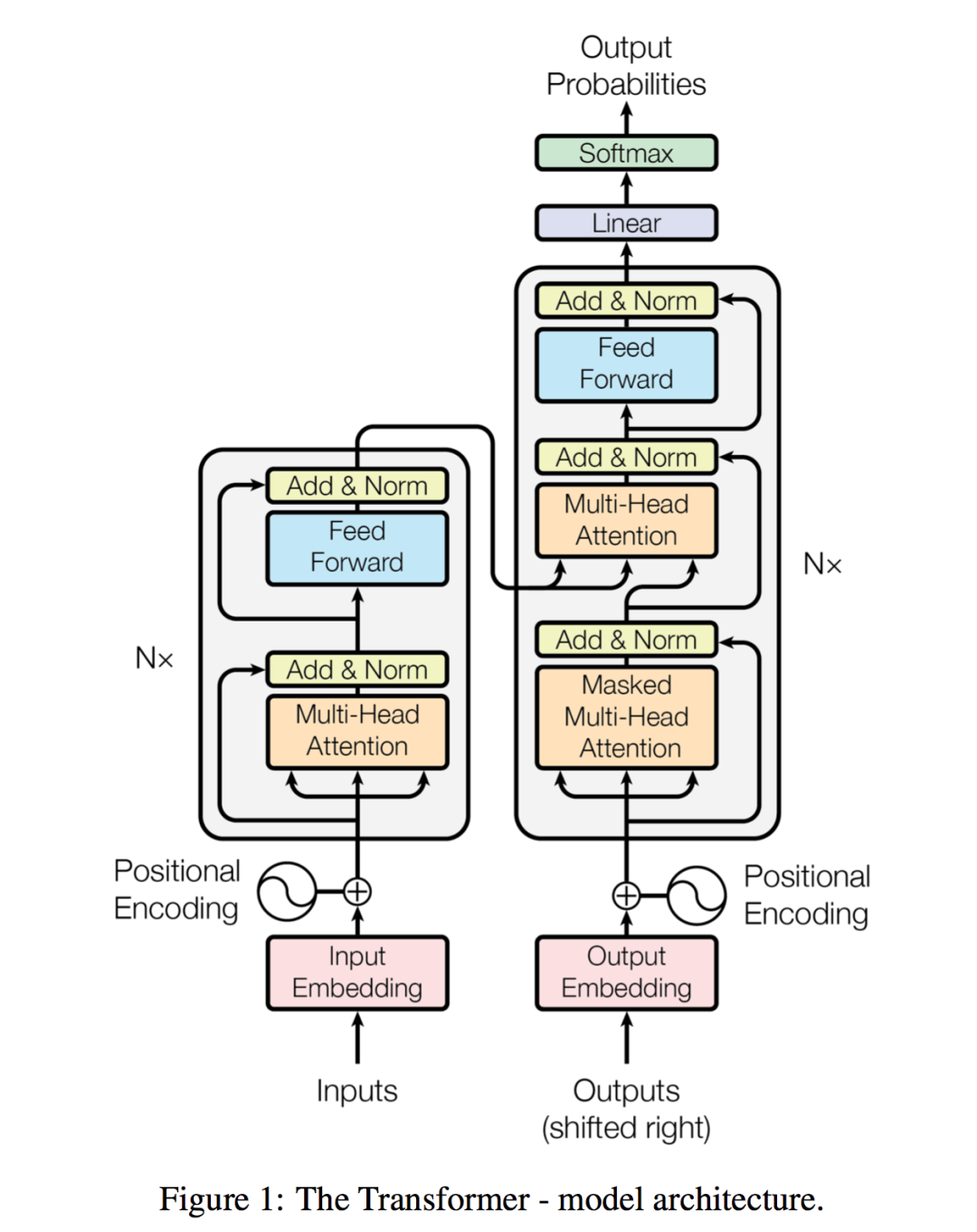
整篇文章就是圍繞這張圖來進行解釋的,由于篇幅所限,我們聚焦在一條主線上:1.文章想解決主要問題是什么 2.如何解決的 3.從文章提出的解決方案作為一個案例來引發(fā)整體思考,因此我們將內容簡化,主要關注核心部分。
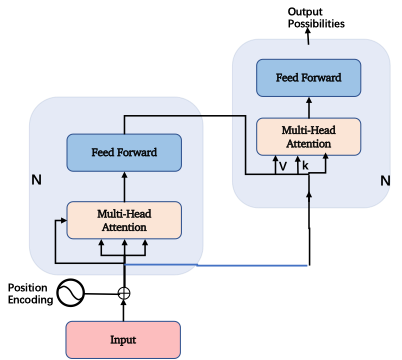
這張圖表達的內容如果理解了,那基本上你掌握了這篇論文85%的內容,也是最關鍵的部分。
《Attention is all your need》在編寫時主要是為了考慮NLP任務,是由幾個Google的科研人員一起完成的,其中一個背景是Google也在推廣自己的并行計算芯片以及AI TensorFlow開發(fā)平臺。平臺主要功能特點是并行計算,這篇文章的算法也是在最大限度的實現并行計算。我們就以一個簡單的例子來把這個算法串一遍。
核心內容
需求是我們需要訓練一個模型,進行中文到英文翻譯。
背景知識:這個需求要把“翻譯:我愛你 to I love you”轉置成一個y=f(x)問題,x代表中文,y是英文,我們要通過訓練得到f(),一旦訓練成功f(),就可以實現翻譯。大家拼的就是誰的訓練方法更準確,更高效,誰的f()更好用。
之前自然語言處理主要的算法叫RNN(循環(huán)神經網絡),它主要的實現邏輯是每個“字”計算之后將結果繼承給第二個字。算法的弊病是需要大量的串行計算,效率低。而且當遇到比較長的句子時,前面信息很有可能會被稀釋掉,造成模型不準確,也就是對于長句子效果會衰減。這是這篇文章致力于要解決的問題,也就是說這篇文章有訓練處更好的f()的方法。聯想一下ChatGPT可以做論文,感受一下。
在Transformer里,作者提出了將每個字與句子中所有單詞進行計算,算出這個詞與每個單詞的相關度,從而確定這個詞在這個句子里的更準確意義。
在此處,要開始進入一些技術細節(jié),在開始之前,我們有必要再熟悉一下機器學習領域最核心的一個概念——“向量”。在數字化時代,數學運算最小單位往往是自然數字。但在AI時代,這個最小單元變成了向量。這是數字化時代計算和智能化時代最重要的差別之一。
舉個例子,比如,在銀行,判斷一個人的信用額度,我們用一個向量來表示
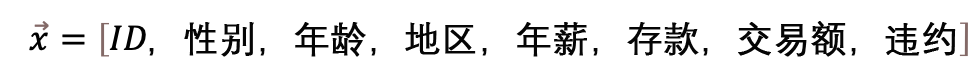
向量是一組數據的集合,也可以想象成在一個超高維度空間里的一個點。一個具體的信用額度向量,就是在8個特征組成的高維空間的一個點。數據在高維空間將展現更多的數學性質比如線性可分,容易讓我們抓住更多隱藏的規(guī)律。
向量的加減乘除是計算機在進行樣本訓練是最主要的計算邏輯。
Transformer模型的主要意義就是找到了一個算法,分成三步把一個詞逐步定位到了一個高維空間,在這個過程中賦予這個單詞比其它算法更優(yōu)的信息。很多情況下這個高維空間有著不同的意義,一旦這個向量賦予的信息更準確更接近真實情況,后面的機器學習工作就很容易展開。還拿剛才信用額度向量舉例子

這兩個向量存在于兩個不同的向量空間,主要的區(qū)別就是前者多了一個向量特征:“年薪”。可以思考一下如果判斷一個人的信用額度,“年薪”是不是一個很重要的影響因子?
以上例子還是很簡單的,只是增加了一個特征值,在transformer里就復雜很多,它是要把多個向量信息通過矩陣加減乘除綜合計算,從而賦予一個向量新的含義。
好,理解了向量的重要性,我們看回transformer的三步走,這三步走分別是:1.編碼(Embedding)2. 定位(Positional encoding)3. 自注意力機制(Self-Attention)。
舉個例子,比如,翻譯句子Smart John is singing到中文。
首先,要對句子每個詞進行向量化。
我們先看“John”這個詞,需要先把“John”這個字母排列的表達轉換成一個512維度的向量John,這樣計算機可以開始認識它。說明John是在這個512維空間的一個點,這是第一步:編碼(Embedding)。
再次,第二步:定位(Positional encoding),利用以下公式(這是這篇論文的創(chuàng)新)
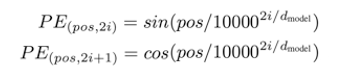
微調一個新的高維空間,生成一個新的向量。

我們不用太擔心這個公式,它核心意義是:1.在這個新的向量里面每一位由原來的0和1表示,分別取代成由sin和cos表示,這個目的是可以通過sin和cos的定律,讓這個新向量不僅表示John這個單詞的意義,還可以表示John在Smart John is singing這個句子的位置信息。如果不理解,可以直接忽略,只要記住第二步是用來在“表達John這個詞的向量”中,加入了John在句子中的位置信息。John已經不是一個孤立的詞,而是一個具體句子中的一個詞,雖然還不知道句子中其他詞是什么含義。
如果第一步計算機理解了什么是John,第二步計算機理解了“* John**”。
最后,第三步:自注意力機制(Self-Attention),通過一個Attention(Q,K,V)算法,再次把John放到一個新的空間信息里,我們設為

在這個新向量里,不僅包含了John的含義,John在句子中位置信息,更包含了John和句子中每個單子含義之間的關系和價值信息。我們可以理解,John作為一個詞是一個泛指,但Smart John就具體了很多,singing的Smart John就又近了一步。而且Attention (Q,K,V)算法,不是對一個單詞周圍做計算,是讓這個單詞跟句子里所有單詞做計算。通過計算調整這個單詞在空間里的位置。
這種方法,可以在一個超長句子中發(fā)揮優(yōu)勢,而且最關鍵的是一舉突破了時序序列的屏障,以前對于圖像和NLP算法的劃分,很大程度上是由于NLP有很明顯的時序特征,即每個單詞和下一個以及在下一個有比較明顯的時序關系。但Transformer這種算法打破了這種束縛,它更在意一個單詞跟句子中每個單詞的價值權重。這是Transformer可以用到everywhere的主要原因。
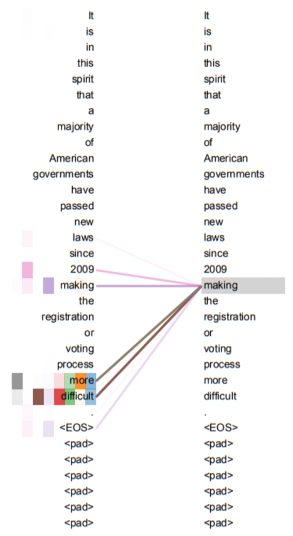
計算過程
具體的計算過程,用翻譯句子“我愛你”到“I love you”舉例(這句更簡單一些)。首先進行向量化并吸收句子位置信息,得到一個句子的初始向量組。
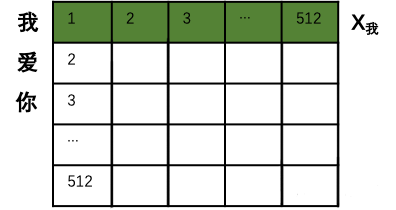
(由于樣本每個句子長短不同,所以每個句子都會是一個512*512的矩陣,如果長度不夠就用0來代替。這樣在訓練時,無論多長的句子,都可以用一個同樣規(guī)模的矩陣來表示。當然512是超參,可以在訓練前調整大小。)
接著,用每個字的初始向量分別乘以三個隨機初始的矩陣WQ,Wk,Wv分別得到三個量Qx,Kx,Vx。下圖以“我”舉例。
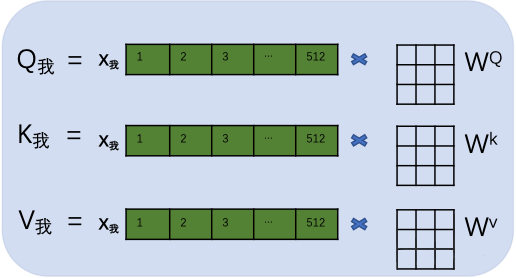
然后,計算每個單詞的attention數值,比如“我”字的attention值就是用“我”字的Q我分別乘以句子中其他單詞的K值,兩個矩陣相乘的數學含義就是衡量兩個矩陣的相似度。然后通過一個SoftMax轉換(大家不用擔心如何計算),計算出它跟每個單詞的權重,這個權重比例所有加在一起要等于1。再用每個權重乘以相對應的V值。所有乘積相加得到這個Attention值。
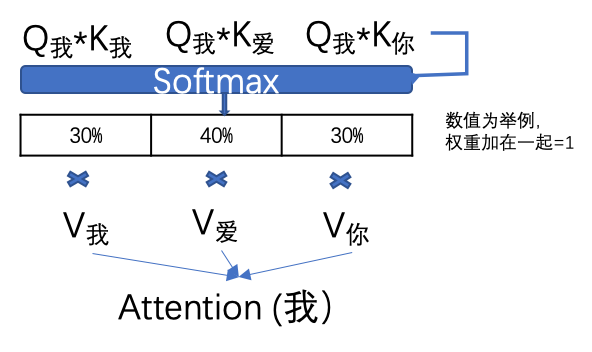
這個attention數值就是除了“我”字自有信息和位置信息以外,成功的得到了這個句子中每個單詞的相關度信息。
大家可以發(fā)現,在所有注意力系數的計算邏輯中其實只有每個字的初始矩陣WQ,Wk,Wv是未知數(這三個矩陣是所有文字共享的)。那么我們可以把這個transformer簡化成一個關于輸入,輸出和這個W矩陣的方程:其中X是輸入文字信息,Y是翻譯信息。

這里有必要再介紹一下機器學習的基礎知識:Transformer算法本質上是一個前饋神經網絡模型,它的計算基礎邏輯,不去管復雜的隱藏層,就是假設Y=f(x)=wx,(目標還是要算出一個f())然后隨機設置一個w0,開始計算這個y=w0x的成本函數,然后再把w0變成w1,計算y=w1x的成本函數,以此類推計算出無數w(不是無數,也會收斂),然后比較哪個w的成本函數最小,就是我們訓練出來的f()。那么在transformer里,這三個初始矩陣就是那個w0。
再回到transformer,在計算Attention之后,每個單詞根據語義關系被打入了新的高維空間這就是Self-attention(自注意力機制)。
但在transformer里,并不是代入了一個空間,而是代入了多個高維空間,叫做多頭注意力機制,(文章中沒有給出更清晰的理論支持,為什么是多頭)。
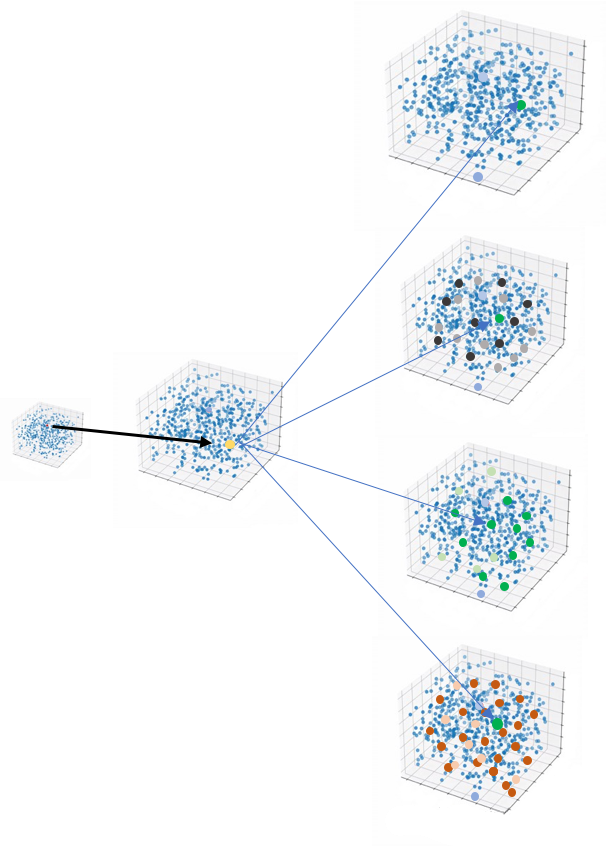
主要原因是在訓練時效果很好。這也是AI科研論文的一個特點,常常憑借非常高的科研素養(yǎng)和敏感性,發(fā)現一些方向,并且通過測試確實有效,但不一定可以給出很完美的理論支撐。這往往也給后續(xù)研究者一些可以進一步完善的空間。
事實證明,如何提升Attention(Q,K,V)效率是transformer領域迭代最快的部分。之后的Bert算法提出預訓練機制成為了主流,后面會做進一步介紹。
當然,事后我們可以理解是把這個句子中的邏輯關系放到不同的高維空間去訓練,目的就是希望抓取更多的信息,這一部分可以更加深刻理解科研人員對空間的應用。
除了以上內容,還有一些技術點比如Mask機制、layer norm、神經網絡激函數飽和區(qū)控制等,由于篇幅關系以及屬于技術細節(jié)就不一一介紹了。
如果大家理解了多頭自注意力機制,基本已經85%掌握了這篇論文的重要內容,也對還在快速擴展影響力的transformer模型有了一個比較直觀的認識。
03啟發(fā)收獲
從理論科研進步的角度看
一、Transformer打破了時序計算的邏輯,開始快速出圈,多個AI原本比較獨立的領域開始在技術上融合。再往里看,Transformer能打破時序很重要一點是并行計算的算力模式給更復雜的計算帶來了性價比上的可能性。算力的進一步提高,必將在AI各細分領域帶來融合,更基礎設施級別的模型,算法仍將不斷推出。AI領域在圖像,NLP;感知認知領域的專業(yè)分工也會慢慢變模糊。
二、AI科研確實具有一些實驗性質。除了核心思想,確實還有很多技術點的解決方向已經明確,但還有很大的提升空間,可以預見圍繞transformer周邊的微創(chuàng)新會持續(xù)加速繁榮。
三、《Attention is all your need》在業(yè)內大名鼎鼎,但你要是細看,會發(fā)現很多內容也是拿來主義,比如最重要的Attention(Q,K,V)中Query,Key,Value是互聯網推薦系統(tǒng)的標配方法論;整個Transformer算法也是一個大的神經網絡,算法是在前人基礎上一步一步迭代發(fā)展,只是這個迭代速度明顯在加快。
從理論、算法、架構、工程的角度看
四、AI算法科研領域正經歷算法、開源代碼、工程、算力的增長飛輪。
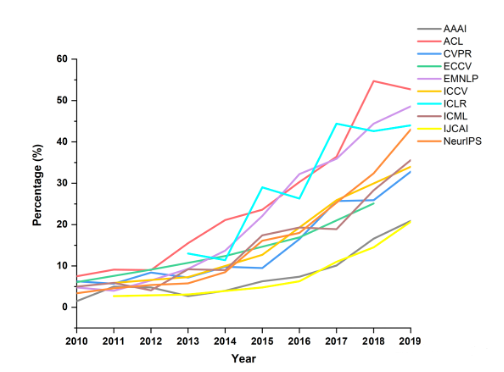
下圖是頂級刊物上的學術論文中,開放源代碼的論文比例,這個數據在這幾年以更快的速度在增長。科研過程與工程過程產生越來越大的交集。開源社區(qū)和開源文化本身也在推動算法和工程的快速發(fā)展。
更多人參與,更多領域的人參與進來,進入門檻隨著算力成本、AI基礎架構和代碼、知識分享的開源逐漸降低,科研與工程的邊界也變得模糊,這個就像足球運動的規(guī)律,除了足球人口增多,天才球員梅西出現的概率也會增大。
從數據和后續(xù)發(fā)展的角度看
五、ChatGPT的成功同大量的數據訓練功不可沒,但除了簡單對話互動或者翻譯,大篇幅回答甚至論文級別的答案還是極其缺乏樣本數據(算法訓練需要的樣本數據需要清晰度X和Y)。而且Transformer的算法相比其他算法需要更大的數據量,原因在于它需要起始階段隨機產生三個矩陣,一步一步進行優(yōu)化。除了Transformer以外,另一個技術Bert也是技術發(fā)展非常重要的現象級算法。其核心是一個簡化的Transformer,Bert不去做從A翻譯到B,它隨機遮住X里面的一些單詞或句子讓算法優(yōu)化對遮住部分的預測。這種思路使得Bert成為了Transformer預訓練最好的搭檔。
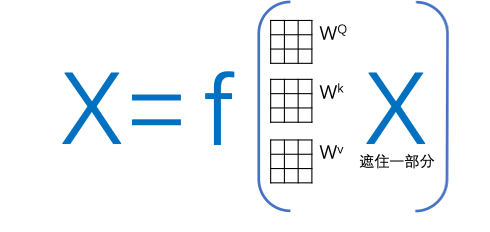
如果通過Bert進行預訓練,相當于給矩陣加入了先驗知識(之前訓練邏輯沒有給機器任何提示,規(guī)則后者基礎知識),提高了正式訓練時初始矩陣的準確度,極大地提升了之后transformer的計算效率和對數據量的要求。在現實中,舉例來說,如果我想訓練國家圖書館圖書,之前需要每本書的信息和對這本書的解釋,或者中文書對應的英文書。但現在我們可以大量只是訓練內容,不需要打標簽,之后只需要通過transformer對樣本數據進行微調。這就給ChatGPT很大的進步空間,而且可以預見,更多這類大模型會雨后春筍一般快速出現。
六、由于transformer是更高級的神經網絡深度學習算法,對數據量有很高要求,這也催生了從小數據如何快速產生大數據的算法,比如GAN對抗網絡等。這是AIGC領域的核心技術。解決數據量不足問題,除了更高效率抽象小數據的信息,也多了把小數據補足成大數據的方法,而且這些方法在快速成熟。
七、我們發(fā)現在機器學習算法中有大量的超級參數,比如在transformer里多頭機制需要幾頭N,文字變成向量是512還是更多,學習速率等都需要在訓練之前提前設置。由于訓練時間長,參數復雜,要想遍歷更優(yōu)秀的計算效果需要非常長的摸索時間。這就催生出AutoML,拿Transformer舉例,就要很多個路線進行自動化機器學習;比如貝葉斯計算(找到更優(yōu)參數配置概率);強化學習思路(貪婪算法在環(huán)境不明朗情況下迅速逼近最優(yōu));另外還有尋求全新訓練網絡的方法(transformer,RNN,MLP等聯合使用排列組合)等。
科研發(fā)展強調參數化,工業(yè)發(fā)展強調自動化,這兩者看似統(tǒng)一,但在現實實操過程中往往是相當痛苦矛盾的。這也是開篇說的產品化和科研流動性相平衡的一個重要領域。
審核編輯 :李倩
-
機器學習
+關注
關注
66文章
8490瀏覽量
134077 -
ai技術
+關注
關注
1文章
1307瀏覽量
24999 -
ChatGPT
+關注
關注
29文章
1587瀏覽量
8794
原文標題:ChatGPT背后的核心技術報告(附下載)
文章出處:【微信號:WUKOOAI,微信公眾號:悟空智能科技】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
RFID系統(tǒng):驅動智能管理的核心技術架構與應用實踐
北京君正穿戴式ISP芯片的核心技術
小米AR眼鏡背后有多少技術難點
淺談DeepSeek核心技術與應用場景
深入探討DeepSeek大模型的核心技術

入河排污口流量自動監(jiān)測系統(tǒng)方案核心技術與優(yōu)勢

從MCU到SoC:汽車芯片核心技術的深度剖析

晶沛自主研發(fā)氣液集成滑環(huán)關鍵核心技術分析

ChatGPT背后的AI背景、技術門道和商業(yè)應用

新能源汽車小三電的核心技術





 工商網監(jiān)
工商網監(jiān)
評論