") StreetLearn利用谷歌街景構建的互動環(huán)境介紹
StreetLearn利用谷歌街景構建的互動環(huán)境介紹

導航是一個內容豐富、基礎扎實的問題領域,它推動了許多不同領域的研究進展:尤其是感知、計劃、記憶、探索和優(yōu)化。從歷史上看,這些挑戰(zhàn)都是單獨考慮的,并且建立的解決方案依賴于固定的數(shù)據(jù)集——例如,通過環(huán)境的記錄軌跡。然而,這些數(shù)據(jù)集不能用于決策和強化學習,總的來說,導航作為一項交互式的學習任務,其中學習agent的行動和行為是與感知和規(guī)劃同時學習的,這一觀點相對來說沒有得到支持。因此,現(xiàn)有的導航基準測試通常依賴于靜態(tài)數(shù)據(jù)集(Geiger等人,2013;Kendall等人,2015)或模擬器(Beattie等人,2016;Shah等人,2018年)。為了支持和驗證端到端導航的研究,我們提出了StreetLearn:一個交互式的、第一人稱的、部分觀察的視覺環(huán)境,使用谷歌街景的照片內容和廣泛的覆蓋范圍,并給出了一個具有挑戰(zhàn)性的目標驅動的導航任務的性能基線。
I.簡介
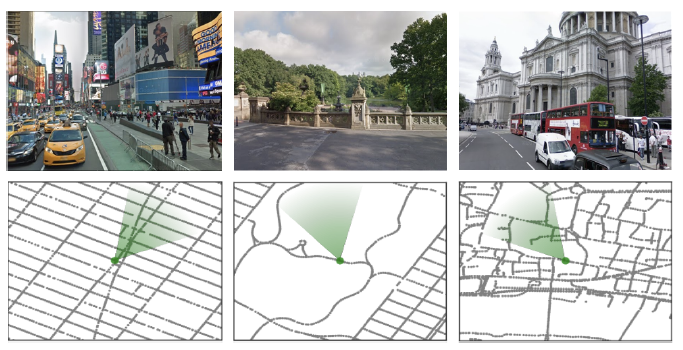
圖1 l 我們的環(huán)境是由來自StreetView的真實世界的地方建立的。圖中顯示了紐約市(時代廣場、中央公園)和倫敦(圣保羅大教堂)的不同景觀和相應的本地地圖。綠色的圓錐體代表agent的位置和方向。
導航這一課題對各種研究學科和技術領域都具有吸引力,是希望破解網(wǎng)格和位置細胞密碼的神經(jīng)科學家的研究課題(Banino等人,2018;Cueva和Wei, 2018), 同時也是機器人研究的一個基本方面,希望建造可以到達給定目的地的移動機器人。大多數(shù)導航算法涉及在探索階段建立一個明確的地圖,然后通過該表征進行規(guī)劃和行動。 最近,研究人員試圖通過探索和與環(huán)境的互動來直接學習導航策略,例如使用端到端的深度強化學習(Lample和Chaplot,2017;Mirowski等人,2017;Wu等人,2018;Zhu等人,2017)。 為了支持這項研究,我們設計了一個名為StreetLearn的互動環(huán)境,使用谷歌街景的圖像和基礎連接信息(見圖1),包括匹茲堡和紐約市的兩個大區(qū)域。該環(huán)境以高分辨率的攝影圖片為特色,展示了多樣化的城市環(huán)境,并以真實的街道連接圖跨越了城市規(guī)模的區(qū)域。 在這個環(huán)境中,我們開發(fā)了幾個穿越任務,要求agent從一個目標到另一個目標進行長距離的導航。
其中一項任務在現(xiàn)實世界中類似于一個在特定城市工作的速遞員,他從一個被稱為 "A "的任意地點開始,然后被指示去一個用絕對坐標定義的特定地點"B",但他從來沒有被告知這些地點的地圖或從A到B的路徑,或被告知自己的位置。 另一項任務是模仿谷歌地圖,遵循由自然語言導航指示和圖像縮略圖組成的一步一步的指示。額外的導航任務可以在StreetLearn環(huán)境中開發(fā)。 我們在第2節(jié)中描述了數(shù)據(jù)集、環(huán)境和任務,在第3節(jié)中解釋了環(huán)境代碼,在第4節(jié)中描述了已實施的方法和基線方法,在第5節(jié)中描述了結果,在第6節(jié)中詳細介紹了相關工作。 II.環(huán)境
本節(jié)介紹了StreetLearn,一個利用谷歌街景構建的互動環(huán)境。由于街景數(shù)據(jù)是在全球范圍內收集的,并且包括高分辨率圖像和圖表連接,因此它是研究導航的寶貴資源。
街景提供了一組地理定位的360°全景圖像,這些圖像構成了一個無向圖的節(jié)點(我們交替使用節(jié)點和全景這一術語)。我們選擇了紐約市和匹茲堡的一些地區(qū)。紐約市可供下載的地區(qū)是曼哈頓第81街以南的地區(qū)。
這包括在一個由(40.695,-74.028)和(40.788,-73.940)定義的長/寬邊界框內的近似56K全景圖像。請注意,布魯克林、皇后區(qū)、羅斯福島以及曼哈頓的橋梁和隧道都不包括在內,我們只包括曼哈頓海濱和第79/81街的多邊形內的全景圖,覆蓋面積為31.6平方公里。匹茲堡數(shù)據(jù)集包括58K張圖像,由(40.425, -80.035)和(40.460, -79.930)之間的經(jīng)度/緯度邊界框來定義,覆蓋8.9公里乘3.9公里的區(qū)域。
此外,我們在每個城市確定了三個區(qū)域,可以單獨用于訓練或轉移學習實驗。表1給出了每個地區(qū)的統(tǒng)計數(shù)據(jù)。
無向圖的邊描述了節(jié)點與其他節(jié)點的接近性和可及性。我們不減少或簡化基礎的連接性,而是使用完整的圖;因此,有許多節(jié)點的擁擠地區(qū),復雜的閉塞交叉口,隧道和人行道,以及其他偶發(fā)事件。
平均節(jié)點間距為10米,在交叉口的密度更高。雖然圖形被用來構建環(huán)境,但agent從未觀察到底層圖形--只觀察到RGB圖像(公共街景產(chǎn)品中可見的疊加信息,如箭頭,也不被agent看到)。
圖1中顯示了RGB圖像和圖表的例子。 在我們的數(shù)據(jù)集中,每個全景圖都被存儲為一個協(xié)議緩沖區(qū)(Google,2008)對象,包含一個高質量的壓縮JPEG格式的字符串,對等角圖像進行編碼,并以下列屬性加以裝飾:一個獨特的字符串標識符,全景相機的位置(經(jīng)度/緯度坐標和高度,以米為單位)和方向(俯仰、滾動和偏航角度),圖像的采集日期,以及直接連接的相鄰對象列表。 2.1.界定數(shù)據(jù)集內的區(qū)域 在StreetLearn數(shù)據(jù)集中,整個曼哈頓和匹茲堡的環(huán)境包含了大的城市區(qū)域,每個區(qū)域代表了超過56000張街景全景圖,從一個極端到另一個極端,穿越這些區(qū)域可能需要經(jīng)過街景圖中接近1千的節(jié)點。 為了使學習具有可操作性,也為了確定訓練和轉移的不同區(qū)域,我們可以將環(huán)境切割成更小的區(qū)域。例如,圖3顯示了將曼哈頓和匹茲堡切割成6個區(qū)域("華爾街"、"聯(lián)合廣場"、"哈德遜"、"CMU"、"阿勒格尼 "和"南岸")的情況,這在我們第5節(jié)的實驗中使用。 在街道圖上劃分區(qū)域有許多可能性:最明顯的是用經(jīng)緯度邊界框來切割圖形,其缺點是會產(chǎn)生不相連的部分。第二種是用多邊形來切割圖形,但必須指定該多邊形的所有頂點,依靠凸面體來選擇包含在多邊形內的節(jié)點,這很不方便。 我們選擇了第三種方法來確定我們的區(qū)域,通過廣度優(yōu)先搜索(BFS)(Moore, 1959; Zuse, 1972)從一個給定的節(jié)點開始增長圖形區(qū)域,這只需要選擇一個中心全景圖和一個圖形深度,并確保產(chǎn)生的圖形是連接的。我們在表1中列出了這些區(qū)域的大小(以節(jié)點、邊和區(qū)域覆蓋率計)、高度變化和描述,包括中央全景圖的ID和BFS圖的深度。 2.2.agent界面和速遞任務
RL環(huán)境需要指定agent的觀察和行動空間,并定義任務。StreetLearn環(huán)境在每個時間點提供可視化觀察xt。視覺輸入是為了模擬第一人稱,部分觀察到的環(huán)境,因此xt是一個裁剪過的、60°正方形的RGB圖像,被縮放為84×84像素(即不是整個全景圖)。
動作空間由五種離散的動作組成。"緩慢 "向左或向右旋轉(±22.5°),"快速"向左或向右旋轉(±67.5°),或向前移動(如果從當前agent的姿勢來看,沒有一個邊緣,這個動作就會成為一個noop)。
如果在agent的視錐中有多個邊,那么就選擇最中心的一個。
StreetLearn提供了一個額外的觀察,即目標描述符gt,它向agent傳達了任務目標--去哪里領取下一個收獲。
如何指定目標有很多選擇:例如,圖像是一個自然的選擇(如(Zhu等人,2017)),但在城市范圍內很快就變得模糊不清;可以使用基于語言的指示或街道地址(如(Chen等人,2018)),盡管這將把重點放在語言基礎而不是導航上;和地標可用于以可擴展的、無坐標的方式對目標位置進行編碼(Mirowski等人,2018)。
對于這項快遞任務,我們采取最簡單的路線,并將目標地點直接定為連續(xù)值坐標 (Lattg, Longtg)。注意目標描述是絕對的;它與agent的位置無關,只在繪制新目標時發(fā)生變化(無論是在成功獲得目標時還是在任務事件開始時)。
在快遞任務中,可以概括為導航到城市中一系列隨機地點的問題,agent從StreetLearn圖中隨機抽樣的位置和方向開始每一個任務。從圖中隨機抽出一個目標位置,計算出目標描述符g0并輸入給agent。如果agent到達一個接近目標的節(jié)點(100米,或大約一個城市街區(qū)),agent就會得到獎勵,并隨機選擇下一個目標并輸入給agent。
每一個任務在1000個agent步驟后結束。agent在到達目標時獲得的獎勵與目標和agent首次分配目標時的位置之間的最短路徑成正比;很像速遞服務,agent在較長的旅程中獲得較高的獎勵。
直觀地說,為了解決速遞任務,agent需要學會將目標編碼與在目標位置觀察到的圖像相關聯(lián),以及將在當前位置觀察到的圖像與到達不同目標位置的策略相關聯(lián)。
2.3.課程
課程學習通過選擇更多更難的例子來呈現(xiàn)給學習算法,逐漸增加學習任務的復雜性(Bengio等人,2009;Graves等人,2017;Zaremba和Sutskever,2014)。我們發(fā)現(xiàn),對于目的地較遠的速遞任務,課程可能很重要。與其他RL問題(如Montezuma’s Revenge)類似,速遞員任務的獎勵非常稀少;與該游戲不同,我們能夠制定一個自然的課程計劃。我們首先對agent位置500米范圍內的新目標進行采樣(第1階段)。在第二階段,我們逐步擴大允許目標的最大范圍,以覆蓋整個圖形。
注意,雖然本文主要關注速遞任務,但正如下面第3節(jié)所述,該環(huán)境已經(jīng)豐富了,通過一步步的(圖像、自然語言指令)和目標圖像指定方向的可能性。
III.編碼
3.1.編碼結構
我們在https://github.com/deepmind/streetlearn提供了環(huán)境和agent的編碼。該編碼庫包含以下組件:
? 我們的C++ StreetLearn引擎用于加載、緩存和提供谷歌街景全景圖,并根據(jù)城市街道圖和agent的當前位置和方向處理導航(從一個全景圖移動到另一個)。每個全景圖都從其等矩形(Wikipedia, 2005)表示投影到第一人稱視圖,可以指定偏航、俯仰和視場角度。
? 用于存儲全景圖和街道圖的消息協(xié)議緩沖區(qū)(Google, 2008)。
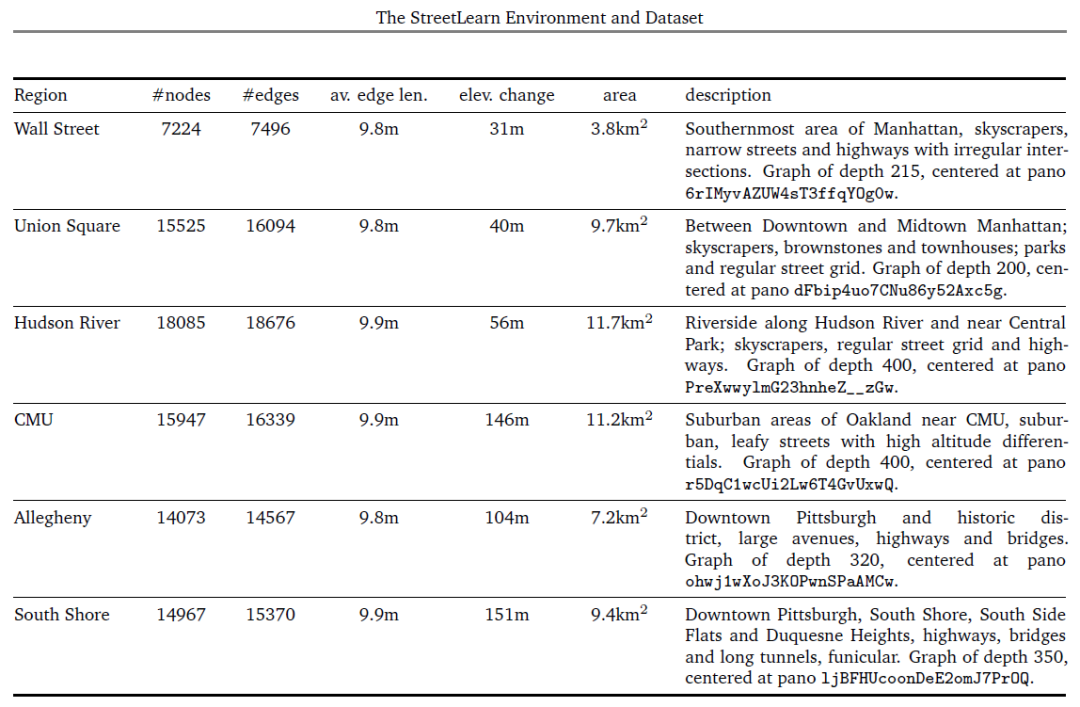
表1 l 紐約的三個地區(qū)(華爾街、聯(lián)合廣場和哈德遜河)和匹茲堡的三個地區(qū)(CMU、阿勒格尼和南岸)的相關信息。
? 一個基于Python的接口,用于調用具有自定義動作空間的StreetLearn環(huán)境。
? 在Python StreetLearn界面中,幾個游戲被定義在單獨的文件中,文件名以game.py結尾。
? 一個簡單的人類agent,使用Pygame在Python中實現(xiàn),在所要求的地圖上實例化StreetLearn環(huán)境,并使用戶能夠玩速遞或跟隨指令的游戲
? Oracleagent,類似于人類agent,自動導航到指定的目標,并報告Oracle在速遞或指令遵循游戲中的表現(xiàn)。
?agent的TensorFlow實施。
3.2.編碼界面
我們的Python StreetLearn環(huán)境遵循OpenAI Gym2(Brockman等人,2016)的規(guī)范。
在實例化了一個特定的游戲和環(huán)境后,可以通過調用函數(shù)reset()來初始化環(huán)境。注意,如果在構建時將auto_reset的flag設置為True,那么每當一個情節(jié)結束時,reset()將被自動調用。
如清單4所示,agent在環(huán)境中通過迭代生成一個動作,將其發(fā)送到(逐步通過)環(huán)境,并處理環(huán)境返回的觀察結果和獎勵。對函數(shù)step(動作)的調用返回:
? 觀察(構造時要求的觀察數(shù)組和標量的元組),
?獎勵(一個帶有agent當前獎勵的浮動標度數(shù)),
?done(布爾值,表示一個游戲情節(jié)是否已經(jīng)結束并被重置),
?以及info(環(huán)境狀態(tài)變量字典,用于調試agent行為或訪問特權環(huán)境信息以進行可視化和分析)。
3.3.行動和觀察
我們向agent提供了四個行動:
? 在全景圖中向左或向右旋轉一個指定的角度(改變agent的偏航)。 ? 在全景圖中按指定的角度向上或向下旋轉(改變agent的間距)。 ? 如果agent從A到B的當前方位在30度的公差角度內,則從當前全景圖A向前移動到另一個全景圖B。 ? 在全景圖中放大和縮小。 因此,agent行動通過step(action)作為4個標量數(shù)字的圖組被發(fā)送到環(huán)境中。 然而,對于通過強化學習訓練離散策略agent,行動空間被離散為整數(shù)。例如,我們在(Mirowski等人,2018)中使用了5個動作:(向前移動,左轉22.5度,左轉67.5度,右轉22.5度,右轉67.5度)。目前可以要求從環(huán)境中獲得以下觀察結果:?view_image:從環(huán)境中返回并由agent看到的第一人稱視角圖像的RGB圖像; ?graph_image:自上而下的街道圖圖像的RGB圖像,通常不被agent看到; ?pitch:agent的俯仰角的標量值,單位是度(零對應于水平); ?yaw:agent的偏航角度的標量值,單位是度(零對應于北); ?yaw_label:agent偏航的整數(shù)離散值,使用16個bin; ?metadata:具有當前全景圖元數(shù)據(jù)的Pano類型的消息協(xié)議緩沖區(qū); ?target_metadata:具有目的/目標全景圖元數(shù)據(jù)的Pano類型的消息協(xié)議緩沖區(qū); ?latlng:agent當前位置的緯度/經(jīng)度標量值的元組; ?latlng:當前agent位置的整數(shù)離散值,使用1024個bins(32個bins為緯度,32個bins為經(jīng)度); ?target_latlng:目的/目標位置的緯度/經(jīng)度度標量值的元組; ?target_latlng:目標位置的整數(shù)離散值,使用1024個bins (32個bins 為緯度,32個bins 為經(jīng)度); ?thumbnails:從環(huán)境中返回的第一人稱視角圖像的n+1個RGB圖像集,當用n個指令進行指令追蹤游戲時,agent應該在特定的航點和目標位置看到這些圖像; ?instructions:當用n個指令進行指令追蹤游戲時,在特定的航點和目標地點為agent提供n個指令集; ?neighbors:agent周圍的近鄰以自我為中心的可穿越性網(wǎng)格的矢量,agent周圍的方向有16個bin,bin 0對應于agent正前方的可穿越性; ?ground_truth_direction:為了遵循最短路徑到達下一個目標或航點,agent要采取的相對地面真實方向的標量值。這種觀察應該只對使用模仿學習訓練的agent提出要求。
3.4.游戲
以下游戲可在StreetLearn環(huán)境中使用:
3.4.1.硬幣_游戲在硬幣游戲中,獎勵包括散落在地圖上的無形硬幣,每個硬幣的獎勵為1。一旦被撿到,這些獎勵在劇情結束前不會再出現(xiàn)。3.4.2.速遞_游戲在速遞游戲中,agent被賦予了一個目標目的地,以經(jīng)/緯度對的形式加以說明。一旦達到目標(有100米的容許偏差),就會對新的目標進行采樣,直到情節(jié)結束。 在一個目標上的獎勵與agent得到新的目標分配時從其位置到該目標位置的最短路徑上的全景圖數(shù)量成正比。額外的獎勵形成包括當agent到達距離目標200米范圍內時的早期獎勵。 額外的硬幣也可以分散在整個環(huán)境中。硬幣的比例、目標半徑和早期獎勵半徑是可參數(shù)化的。課程_速遞游戲與速遞游戲類似,但在任務的難度上有一個課程(分配任務時,從agent的位置到目標的最大直線距離)。3.4.3.指令游戲目標指令游戲及其變體--遞增指令游戲和逐步指令游戲使用導航指令來引導agent到達目標。agent被提供了一個指令清單以及縮略圖,引導agent從其起始位置到目標位置。 在逐步游戲中,agent每次提供一個指令和兩個縮略圖,在其他游戲變體中,整個列表在整個游戲中都可以使用。到達目標地點(所有變體),以及擊中單個航點(僅增量和逐步)時,均可獲得獎勵。 在訓練過程中,有各種課程策略可供agent使用,并且可以采用獎勵塑造法,當agent進入到距離一個航點或目標50米的范圍內時,提供零星的獎勵。
IV.方法
本節(jié)簡要介紹了在速遞任務中被評估的一系列方法。
4.1.Goal-dependent Actor-Critic 強化學習 我們將學習問題形式化為馬爾科夫決策過程,有狀態(tài)空間s,行動空間A,環(huán)境s,以及一組可能的目標g。 獎勵函數(shù)取決于當前的目標和狀態(tài):R : s ×g ×A → R. 通常的強化學習目標是找到使預期收益最大化的政策,該策略被定義為從狀態(tài)s0開始的折現(xiàn)獎勵之和,折現(xiàn)率為γ。 I在這個導航任務中,一個狀態(tài)st的預期回報也取決于一系列的采樣目標{gk}k。策略是:給定當前狀態(tài)st和目標gt下,在動作上的分布:π(als, g) = Pr(at = alst= s, gt = g)。我們將值函數(shù)定義為代理的期望返回值,該代理從狀態(tài)st的策略π中采樣動作,目標gt: 我們假設agent應該從兩種類型的學習中獲益:第一,學習一般的、與位置無關的表征和探索行為;第二,學習本地特定的結構和特征。一個導航代理不僅需要一個通用的內部表征,以支持認知過程,如場景理解,而且還需要組織和記憶一個地方特有的特征和結構。因此,為了支持這兩種類型的學習,我們專注于具有多種途徑的神經(jīng)架構。 我們在表1中描述的六個區(qū)域評估了兩個agent。我們在此對該方法進行總結,因為這些agent的全部架構細節(jié)之前已經(jīng)描述過(Mirowski等人,2018)。 策略和價值函數(shù)都由一個神經(jīng)網(wǎng)絡設定參數(shù),該網(wǎng)絡共享除最終線性輸出以外的所有層。 該agent對原始像素圖像xt進行操作,這些圖像通過卷積網(wǎng)絡,如(Mnih等人,2016)。長短期記憶(LSTM)(Hochreiter和Schmidhuber,1997)接收對話編碼器的輸出,以及過去的獎勵rt+1和以前的行動at+1。這兩種不同的結構描述如下。

圖4 l 與環(huán)境互動的主要循環(huán)。
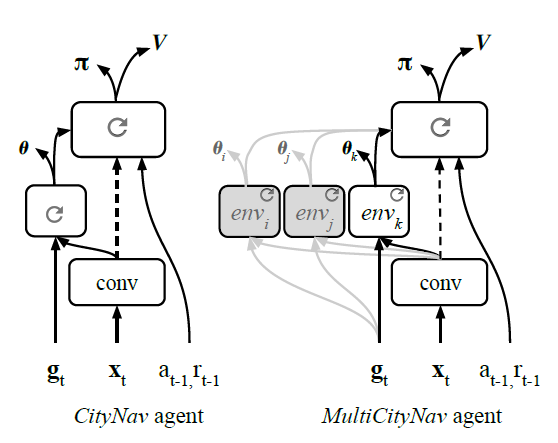
圖5l 架構的比較。左圖:City-Nav是一個具有策略LSTM、獨立目標LSTM和操作輔助航向(θ)的單一城市導航架構。右圖:多城市導航是一個多城市架構,每個城市都有獨立的目標LSTM路徑。
CityNav架構(圖5b)有一個卷積編碼器和兩個LSTM層,它們被指定為策略LSTM和目標LSTM。目標描述gt與之前的動作和獎勵以及卷積編碼器的視覺特征一起被輸入到目標LSTM。CityNav agent還在目標LSTM的輸出上增加了一個輔助的航向(θ)預測任務。
多城市導航架構(圖5c)擴展了CityNav agent,以便在不同城市學習。 目標LSTM的職責是編碼和封裝當?shù)靥囟ǖ奶卣骱屯負浣Y構,這樣就可以添加多個路徑,每個城市或地區(qū)一個。此外,在對一些城市進行訓練后,我們證明卷積編碼器和政策LSTM變得足夠通用,只需要為新的城市訓練一個新的目標LSTM。
為了訓練agent,我們使用IMPALA(Espeholt等人,2018),這是一個actor-critic的實現(xiàn),將行動和學習分離開來。在我們的實驗中,IMPALA的性能與A3C(Mnih等人,2016)相似。我們對CityNav使用256個行為體,對MultiCityNav使用512個行為體,批次大小分別為256或512,序列長度為50。
我們注意到,這些計算資源并不是所有人都能得到的,所以我們驗證了只用16個行動者和1個學習者,在一臺帶有圖形處理單元(GPU)的臺式電腦上運行,就能獲得類似的結果。
我們使用的臺式機有很大的內存(192GB),用于實例化16個StreetLearn環(huán)境(每個環(huán)境都需要一個大的緩存內存來緩存全景圖),但更小的內存也可以使用,但要權衡一下更頻繁的磁盤訪問。
CityNav和基線架構的TensorFlow實現(xiàn)(Mirowski等人,2018)可在https://github.com/deepmind/streetlearn的代碼回收庫中獲得。
訓練器代碼是對(Espeholt等人,2018)的直接修改,來自https://github.com/deepmind/scalable_ agent,可單獨提供。
4.2.Oracle
我們還通過使用廣度優(yōu)先搜索計算從所有全景位置到指定目標位置的最短路徑來計算所有任務的上限(Moore, 1959;Zuse, 1972)的全景連通性圖。這使我們能夠計算agent應該去的下一個全景圖是哪一個,以及agent為了向前移動到那個全景圖應該對齊的方向,重復這個過程直到到達目的地。
這個ground_truth_position可以作為一個觀察值被請求(對于模仿學習代理),或者從環(huán)境返回的信息字典中提取。清單6顯示了如何實現(xiàn) oracle agent,以提供一個有價值的衡量標準來衡量任務。
V.速遞任務的結構
為了評估所描述的方法,我們給出了每個區(qū)域的單獨性能,以及多個區(qū)域的聯(lián)合訓練結果。我們還展示了該方法的概括能力,即通過評估保留區(qū)域的目標,以及只對一個全新的區(qū)域進行agent訓練。 表2給出了在圖3和表1中定義的紐約市和匹茲堡市的六個不同地區(qū),不同的代理在每1000步事件中取得的平均總獎勵。盡管代理人接受了獎勵塑造的訓練(即,當他們在目標的小半徑范圍內時,他們會得到部分獎勵),這里給出的每集回報只包括達到目標時給予的全部獎勵。實驗都是用5個不同的種子重復進行的。 在表2中,Oracle的結果是直接在圖上進行廣度搜索的結果,因此它們反映了完美的性能。單一結果顯示了使用CityNav架構為每個區(qū)域單獨訓練的agent的性能。訓練有素的agent在紐約市表現(xiàn)良好,實現(xiàn)了85%至97%的oracle收益,而在匹茲堡表現(xiàn)較差,尤其是在南岸地區(qū),agent完全失敗。 這可能是由于該地區(qū)具有挑戰(zhàn)性的海拔變化,即使在附近的節(jié)點之間也會產(chǎn)生錯綜復雜的路線,這也是我們指定課程任務的一個偽命題(基于從agent位置到目標的最大歐氏距離,不考慮實際旅行時間)。 特別是,當 agent在南岸的杜肯山頂時,在河對岸的目標地點,如果乘坐飛機500米遠,公路距離可能會有數(shù)公里。 聯(lián)合結果顯示了在五個地區(qū)聯(lián)合訓練的多城市導航agent在每個地區(qū)的表現(xiàn)(不包括南岸)。盡管現(xiàn)在在更大的范圍內進行了訓練:兩個城市和五個地區(qū),但所產(chǎn)生的agent 在性能上只下降了一點。 最后,轉移給出了一個agent的表現(xiàn),該agent在四個地區(qū)接受訓練(用斜體字給出),然后轉移到第五個地區(qū)(華爾街)。在這種轉移中,只有目標LSTM被修改;架構的其他兩個部分(卷積編碼器或策略LSTM)沒有梯度更新。
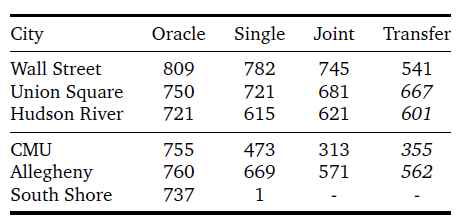
表2 l Oracle的每個城市目標獎勵,單一訓練的CityNav和多個CityNav agent在5個城市(華爾街、曼哈頓的聯(lián)合廣場和哈德遜河、匹茲堡的CMU和阿勒格尼)聯(lián)合訓練或在4個城市(聯(lián)合廣場、哈德遜河、CMU和阿勒格尼)聯(lián)合訓練。

圖6 l Oracle的實施,使用地面真實方向/方位到下一個全景圖。
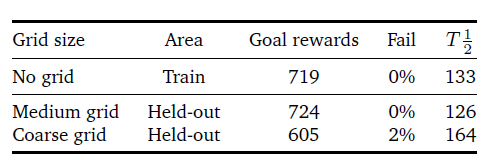
表3 l CityNav agent在一組目標地點(中等和粗略的網(wǎng)格)上的概括表現(xiàn)(獎勵和失敗指標)。我們還計算了半程時間(T1/2),即到達目標的一半。
為了研究受過訓練的agent的概括能力,我們掩蓋了25%的可能目標,并對剩余的目標進行訓練(見圖5(Mirowski等人,2018)的說明)。在測試時,我們只對agent在封閉區(qū)域達到目標的能力進行評估。注意,agent仍然能夠穿越這些區(qū)域,只是它從未在那里采樣過目標。更確切地說,封閉的區(qū)域是經(jīng)緯度為0.01°(粗網(wǎng)格)或0.005°(中網(wǎng)格)的方塊(分別大約為1平方公里和0.5平方公里)。
在實驗中,我們對CityNavagent進行了1B步的訓練,接下來凍結了agent的權重,并對其在100M步的封閉區(qū)域的表現(xiàn)進行了評估。表3顯示,隨著封閉區(qū)面積的增加,agent的性能有所下降。為了進一步理解,除了測試獎勵指標,我們還使用了未完成目標(Fail)和半行程時間(T1/2)指標。
錯過目標的指標衡量的是沒有達到目標的百分比。半程時間衡量的是完成agent與目標之間的一半距離所需的agent步驟數(shù)量。
我們還在表4中比較了使用(經(jīng)緯度)目標描述符與之前提出的地標描述符(Mirowski等人,2018)時取得的性能。雖然地標方案有一些優(yōu)勢,比如避免了固定的坐標框架,但(緯度,緯度)描述符的表現(xiàn)要優(yōu)于紐約聯(lián)合廣場地區(qū)的地標。
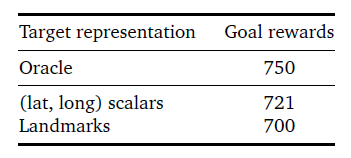
表4 lCityNav代理在聯(lián)合廣場上使用不同類型的目標表示時的表現(xiàn):(緯度,長度)標量與地標。
VI.相關工作
StreetLearn環(huán)境與近年來出現(xiàn)的許多其他模擬器和數(shù)據(jù)集相關,這些模擬器和數(shù)據(jù)集是為了響應增強學習和更普遍地通過交互學習導航的更大興趣而出現(xiàn)的。
我們重點列舉了這些相關的數(shù)據(jù)集和環(huán)境,請讀者參考Mirowski等人(2018)對相關方法的更完整討論。
許多基于RL的導航方法依賴于模擬器,這些模擬器具有程序化生成的變化等特點,但在視覺上往往是簡單和不真實的,包括合成的3D環(huán)境,如VizDoom(Kempka等人,2016)、HoME(Brodeur等人,2017)、House 3D(Wu等人,2018)、Chalet(Yan等人)等。2016)、DeepMind Lab(Beattie等人,2016)、HoME(Brodeur等人,2017)、House 3D(Wu等人,2018)、Chalet(Yan等人,2018),或AI2-THOR(Kolve等人,2017)。
為了彌補模擬和真實之間的差距,研究人員開發(fā)了更真實、更高保真度的模擬環(huán)境(Dosovit- skiy等人,2017;Kolve等,2017;沙阿等人,2018;吳等人,2018)。然而,盡管模擬環(huán)境越來越具有照片真實感,但其固有的問題在于環(huán)境的有限多樣性和觀察結果的清潔性。
我們的真實世界數(shù)據(jù)集是多樣化和視覺逼真的,包括行人、汽車、公共汽車或卡車、不同的天氣條件和植被的場景,覆蓋了很大的地理區(qū)域。然而,我們注意到我們的環(huán)境有明顯的局限性:它不包含動態(tài)元素,行動空間必然是離散的,因為它必須在全景圖之間跳躍,而且街道拓撲結構不能被任意改變或再生。
最近引入了更多視覺逼真的環(huán)境,如MatterportRoom-to-Room (Chang等人,2017)、AdobeIndoorNav(Mo等人,2018)、Stanford 2D- 3D-S(Armeni等人,2016)、ScanNet (Dai等人,2017)、Gibson環(huán)境(Xia等人,2018)和MI- NOS (Savva等人,2017)來表示室內場景,其中一些還添加了導航指令。
deVries等人(2018)使用紐約的圖像,但依靠對附近地標的分類注釋,而不是視覺觀察,并且只使用了500張全景圖的數(shù)據(jù)集(我們的數(shù)據(jù)集要大兩個數(shù)量級)。最近,Cirik等人(2018),特別是Chen等人(2018)也提出了以街景圖像為基礎的較大的駕駛指令數(shù)據(jù)集。
VII.總結
導航是一項重要的認知任務,它使人類和動物能夠在沒有地圖的情況下穿越一個復雜的世界。為了幫助理解這種認知技能,它的出現(xiàn)和穩(wěn)健性,以及它在現(xiàn)實世界中的應用,我們公開了一個數(shù)據(jù)集和一個基于谷歌街景的互動環(huán)境。
我們精心策劃的數(shù)據(jù)集是由經(jīng)過人工審查和隱私審查的攝影圖片構成的--我們采取了這些額外的預防措施,以確保所有的人臉和車牌都被適當?shù)啬:恕?/p>
該數(shù)據(jù)集可獲得,并根據(jù)要求進行分發(fā);在個人要求刪除或模糊谷歌街景網(wǎng)站上的特定全景圖的情況下,我們將其要求傳播給StreetLearn數(shù)據(jù)集的用戶,并向用戶提供符合刪除要求的最新版本。
我們的環(huán)境使agent的訓練能夠純粹基于視覺觀察和絕對目標位置表征來導航到不同的目標位置。我們還用文字說明擴展了該數(shù)據(jù)集,以實現(xiàn)基于獎勵的任務,重點是遵循相對方向來達到目標。我們將依靠這個數(shù)據(jù)集和環(huán)境來解決接地的、長距離的、目標驅動的導航的基本問題。
審核編輯:郭婷
-
谷歌
+關注
關注
27文章
6231瀏覽量
108119 -
數(shù)據(jù)集
+關注
關注
4文章
1224瀏覽量
25445
原文標題:自動駕駛“環(huán)境和數(shù)據(jù)集”
文章出處:【微信號:阿寶1990,微信公眾號:阿寶1990】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
谷歌地圖GPS定位
利用NVIDIA技術構建從數(shù)據(jù)中心到邊緣的智慧醫(yī)院解決方案
參考STM32 MPU生態(tài)資源利用Yocto構建STM32MP2芯片鏡像運行docker
智慧教室互動平板:賦能未來教育的新利器


HBird SDK設置構建環(huán)境時,顯示找不到riscv-nuclei-elf-gcc,為什么?
DLP6500想調用API進行自主二次開發(fā),怎么構建開發(fā)環(huán)境?
利用OpenVINO和LlamaIndex工具構建多模態(tài)RAG應用

在Mac上使用Docker構建noVNC環(huán)境并運行MyCobot





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論