 一款面向區塊鏈可信數據存儲的技術
一款面向區塊鏈可信數據存儲的技術
作者 | 螞蟻鏈 LETUS 技術負責人 田世坤
寫在前面 文字產生以前,結繩記事是人類用來存儲知識和信息的主要方式。此后,從竹簡、紙張的發明,到工業時代的磁盤存儲,再到信息時代的數據庫,存儲方式不斷革新,“存力”不斷提高。
11 月 3 日,在 2022 云棲大會上,螞蟻鏈歷經 4 年技術攻關與測試驗證的區塊鏈存儲引擎 LETUS(Log-structured Efficient Trusted Universal Storage)正式發布。
這一款面向區塊鏈可信數據存儲的技術產品,不僅用來解決當前螞蟻鏈及區塊鏈產業的規模化發展問題,也面向 Web3 時代提供“可信存力”支撐。
我們認為,隨著大量的數據和數字資產在數字化世界里流轉,可信數據的“存力”將如同電力網絡的承載力一樣重要。
本文希望通過對 LETUS 的深入技術解讀,回答讀者們普遍關心的關鍵問題:LETUS 是什么?主要解決哪些問題?為什么堅持用“可驗證結構”?為什么要自研?以及未來要走向何處? 背景是什么?
從 2009 年序號為 0 的創世塊誕生至今已過去十多年,“中本聰”依然神秘,但區塊鏈技術的發展卻因為公鏈、token、開源的推動,沒有絲毫神秘感。
經過幾代技術演進,在比特幣的 UTXO 模型基礎上誕生了應用更為廣泛、支持可編程智能合約的區塊鏈技術:通過密碼學、共識算法、虛擬機、可信存儲等技術,多個參與方執行相同的“指令”,來完成同一個業務邏輯,如賬戶轉賬,或者合約調用,維護不可篡改和不可偽造的業務數據。
簡單講,可將這類賬本數據庫,看作一個去中心化防作惡、防篡改的復制狀態機,所執行的是智能合約描述的業務邏輯,而狀態機通過日志 (區塊數據)產生新的狀態(狀態數據):
區塊數據:包括交易、回執、世界狀態 Root Hash 等信息,和數據庫系統中的日志類似,但是塊之間由 Hash 錨定防篡改,并且不會刪除。(區塊數據記錄的是區塊鏈上發生的每一筆交易,如:Alice 向 Bob 轉賬 xx)
狀態數據:記錄賬戶、資產、業務合約數據等狀態信息,和數據庫系統中表數據類似,需要實現可驗證可追溯。(狀態數據記錄的是區塊鏈上每個賬戶或智能合約的當前狀態,如:Bob 賬戶剩余 xx)
鏈上數據的特點可以總結為以下三個:
持續增長:從創世塊開始,賬本數據隨交易持續增長,保留周期長;
多版本:交易修改狀態數據產生新版本,系統提供歷史版本查詢和驗證功能;
可驗證:交易和賬戶狀態通過 Merkle 根哈希(Merkle Root Hash)錨定在區塊頭,通過 SPV(simple payment verification,簡單支付證明)提供存在性證明;
區塊鏈應用通過可驗證數據結構(Authenticated Data Structure,如 Merkle tree)實現可驗證和可追溯。我們認為,Web3“存力”一個非常重要的要素是可驗證,而今天我們看到的區塊鏈存儲瓶頸大多來源于可驗證結構 ADS(如 Merkle tree)的低效存取和查詢,這正是螞蟻鏈 LETUS 重點攻克的難題。
我們要什么?
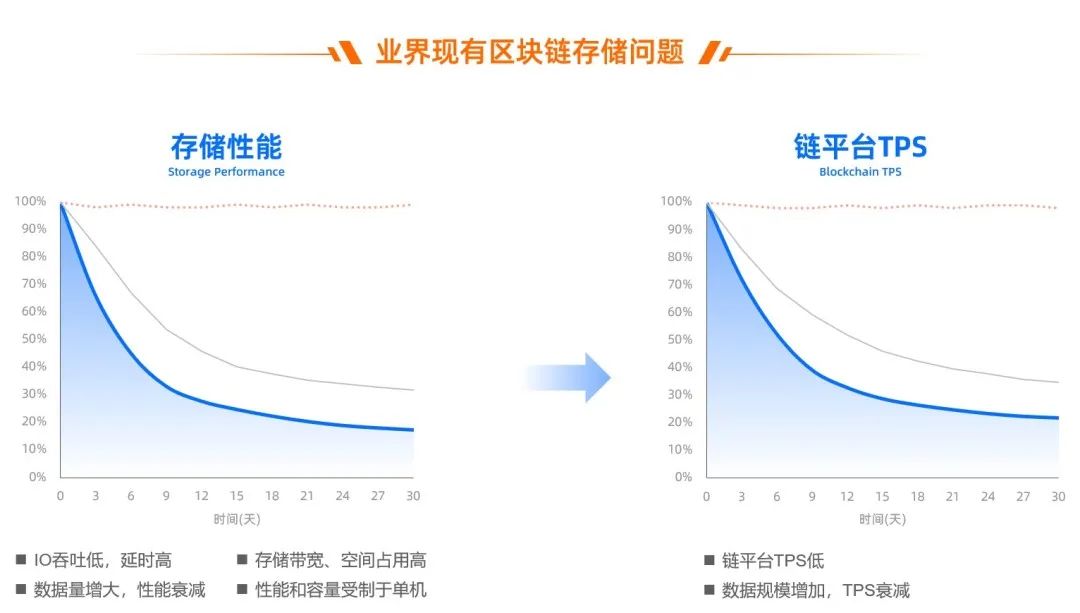
隨著時間推移和鏈上交易的增加,對存儲容量的要求也不斷增長,隨之而來的是區塊數據存儲成本的大幅提升;與此同時,鏈上狀態數據規模也持續增加,可驗證數據結構持續膨脹,導致交易性能隨賬戶規模提升和歷史狀態數據增加而持續下降。
2019 年,螞蟻鏈上線了一個供應鏈金融業務,大家特別興奮。但是,這種興奮并沒有維持多久,隨著程序跑的時間越來越長,問題慢慢暴露出來。
供應鏈金融是面向 ToB 的,不像 ToC 端隨時都有數據,可能會在某個時刻(比如每天晚上)有一筆狀態數據非常大的交易進來,跑了一個星期后發現性能越來越慢。
鏈平臺 TPS 的衰減和存儲直接相關,而與共識、虛擬機都無關,隨著業務合約持續寫入數據,存儲性能大幅衰減。
如果要在技術上長時間支持億級賬戶規模、每天能穩定支撐億級交易量,存儲的規模和性能問題必須要攻克。
期間,團隊也曾試過各種技術方法對他進行優化,得到一些緩解。但多次嘗試之后發現,隨著數量增加而出現的性能衰減,是一個繞不開的瓶頸,需要從本質上解決。
我們需要從問題表象分析背后的原因。
區塊鏈應用通過可驗證數據結構實現可驗證和可追溯,但是可驗證數據結構會帶來讀寫放大(問題 1)和數據局部性(問題 2)。
而存儲系統為了實現數據管理,需要對數據分頁 / 分層、排序,如 KV 數據庫基于 LSM-tree 將數據分層有序存儲,而 MySQL 之類的數據庫將數據分頁,也會基于 B-tree 數據結構來排序索引。
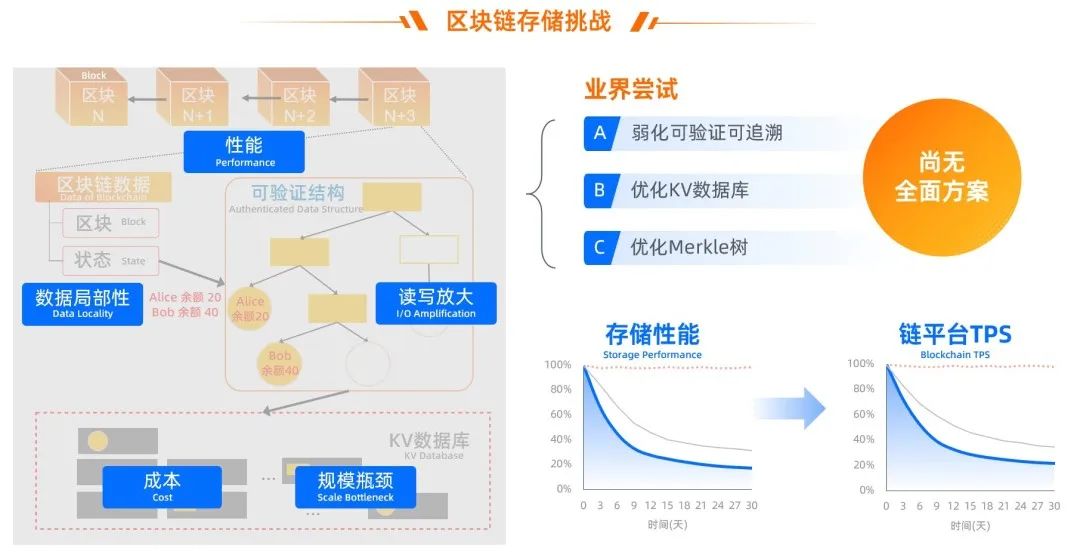
業界現有的實現方式,大多采用基于 LSM 架構的通用 Key-Value 數據庫,在數據庫之上運行一個獨立 Merkle 樹來實現可驗證,如:
以太坊:MPT(Merkle Patricia Tree)+LevelDB
Diem:JMT(Jellyfish Merkle Tree)+RocksDB
背后的核心矛盾為:
01 Merkle 樹每次狀態數據修改,即使只改一個 KV,也需要從葉子節點到根節點,每一層節點都重新編碼后,寫到 KV 數據庫,例如上圖中 Alice 給 Bob 轉賬,需要寫入 Merkle 樹的 2 個葉子節點和 3 個中間節點,最壞情況需要寫入數十個中間節點; 02 Merkle 樹的節點的 key 完全隨機 (如對內容算 hash,再以 hash 為 key),數據局部性(data locality)非常不友好,如 RocksDB 里為了讓 Level 內 sst 文件有序,即使沒有垃圾依然需要層層進行數據壓實(compaction),從而消耗了大部分的磁盤讀寫帶寬; 03 數據規模越大,Merkle 樹本身的層數越多,需要額外寫入的 key-value 越多,DB 里的數據量越多,后臺數據管理的代價越大(如 compaction 流量),消耗大量的磁盤和 CPU 資源。
除此之外,吞吐、延時等存儲性能(問題 3)、持續增長下的存儲成本(問題 4)、單機存儲下的規模瓶頸(問題 5)也都是需要解決的問題。
面臨什么挑戰?
在過去幾年的快速發展中,區塊鏈的業務場景對交易吞吐量和響應時間要求越來越高,很多技術也被推動迭代發展,如 PBFT、HoneyBadger、MyTumbler 等高性能共識算法,BTN 等網絡基礎設施,JIT 加持的 WASM 虛擬機、以及高效的并行執行技術。
但比較而言,存儲的性能對區塊鏈平臺整體性能影響非常大。對面向 2C 場景的數字藏品類業務(如鯨探,需支持秒殺),交易 TPS 與延時要求極為苛刻;而對需要在鏈上保存大量數據的存證類業務,大容量存儲帶來的成本又十分可觀。
要支撐業務的長期可持續發展,我們歸納出區塊鏈存儲面臨的核心挑戰:
規模:業務賬戶規模可達數 10 億,狀態數據和歷史版本規模分別需要支撐到十億、千億級;
性能:轉賬交易需求可達十萬級 TPS、百毫秒級延時,要求性能不能受制于單機瓶頸,數據規模持續增長下性能不衰減;
成本:隨著交易增長,存儲容量持續增加,存儲空間占用、節點間帶寬占用居高不下。業務持續增長要求低成本存儲。
這些問題在行業內很普遍。業界技術路線主要分三條:
路線 A:弱化可驗證可追溯,如 HyperLedger Fabric 1.0 開始不支持可驗證和多版本,保存讀寫集、只持久化最新版本狀態數據;
路線 B:優化 KV 數據庫存儲,如實現鍵值分離、hash 索引的 KV 數據庫等 (BadgerDB、ParityDB),接入通用分布式數據庫 (MySQL) 等;
路線 C:優化 Merkle 樹,交易 ID 作為版本、樹結構稀疏化,如 Diem JMT。
根據公開信息,目前區塊鏈產品中主流的 MPT + LevelDB、JMT + RocksDB、MySQL 等存儲架構,沒有能全部解決上述 5 個問題的方案,難以在支持多版本和可驗證的同時,滿足 10 億級賬戶規模下的高性能、易擴展、低成本的業務要求。
我們做到了什么?
我們自研了一套區塊鏈存儲引擎 LETUS(Log-structured Efficient Trusted Universal Storage),保證完整的可驗證、多版本能力,既滿足區塊數據不可篡改、可追溯、可驗證等要求,也提供對合約數據友好訪問、存儲規模可分片擴展,高性能低成本等特性。同時也滿足通用性,統一管理區塊數據、狀態數據。

4 年前不敢想象的能力現在具備了(以下數據為統一環境下的測試結果)
01 大規模:通過存儲集群擴展支持十億賬戶規模,TPS 超過 12 萬,交易平均時延低于 150ms; 02 高性能:存儲層 IO 吞吐相比以太坊 MPT + LevelDB 等架構提升 10~20 倍,IO 延遲降低 90% 以上。鏈平臺在 7x24 高壓力壓測中,端到端 TPS 不隨數據量增加而衰減;
03 低成本:相比 MPT + LevelDB 架構,磁盤帶寬減少 95%、空間占用減少 60%;相比于 Diem JMT + RocksDB 架構,磁盤帶寬減少約 60%、空間占用降低約 40%; 04 進一步降成本方案,供用戶選用:
a.針對區塊數據容量與成本持續增長,提供智能控溫分層存儲能力,并應用于存證等業務降低約 70% 存儲成本,同時也降低運維成本。
針對狀態數據的歷史版本容量與成本持續增長,提供范圍掃描的批量裁剪能力,實現歷史版本狀態數據的裁剪和后臺空間回收,在十億賬戶規模時,使用鏈原生存儲可以減少近 90% 狀態存儲空間。
但這背后是一個技術架構的跨越,從下圖左邊的可驗證數據結構 +KV 數據庫架構,升級為現在的 LETUS 存儲引擎,架構更簡潔,系統更高效。
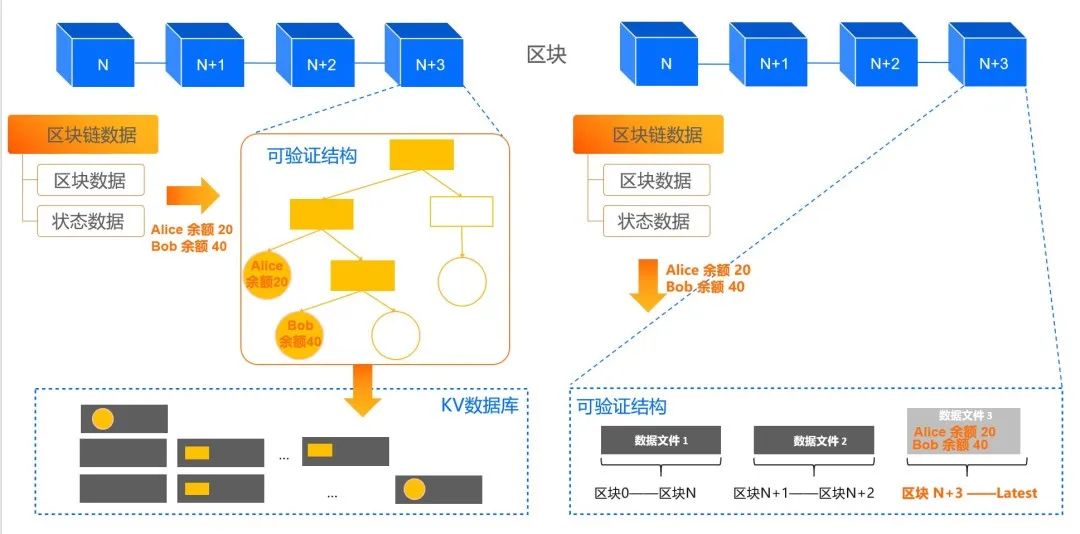
如 Alice 給 Bob 轉賬,只需要寫增量數據,不需要寫入 7 個 Merkle 樹節點,數據局部性更友好,如 Alice 和 Bob 的賬戶數據,按區塊號有序,不再 hash 隨機。
怎么做到的?
圖片回顧這四年,主要經歷的三個大的階段。
階段一:開源思路優化
第一年里,為了滿足業務急迫訴求,我們需要在有限時間內,實現億級賬戶規模和交易 TPS。先從已有系統入手,深度優化了狀態樹,基于開源 MPT 到自研 FDMT,同時調優 RocksDB 數據庫、增加并發、提升介質性能。
一系列優化措施緩解了問題,但依然無法根本解決,例如數據規模增加后,寫放大依然有幾十倍,數據在底層存儲里依然隨機分布。
階段二:自研存儲引擎
為了能徹底解決上述所有問題,我們不得不重新思考存儲引擎的設計。
核心設計
針對讀寫放大(問題 1)、數據局部性(問題 2)和性能(問題 3),我們結合區塊鏈特征,如可驗證數據結構的讀寫行為、鏈上數據的多版本訴求、只追加和不可篡改等,重新設計存儲引擎的架構分層、關鍵組件、索引數據結構:
根據區塊鏈特征,我們根據可驗證數據結構的讀寫行為、鏈上數據的多版本訴求,重新設計存儲引擎的架構分層、關鍵組件、索引數據結構:
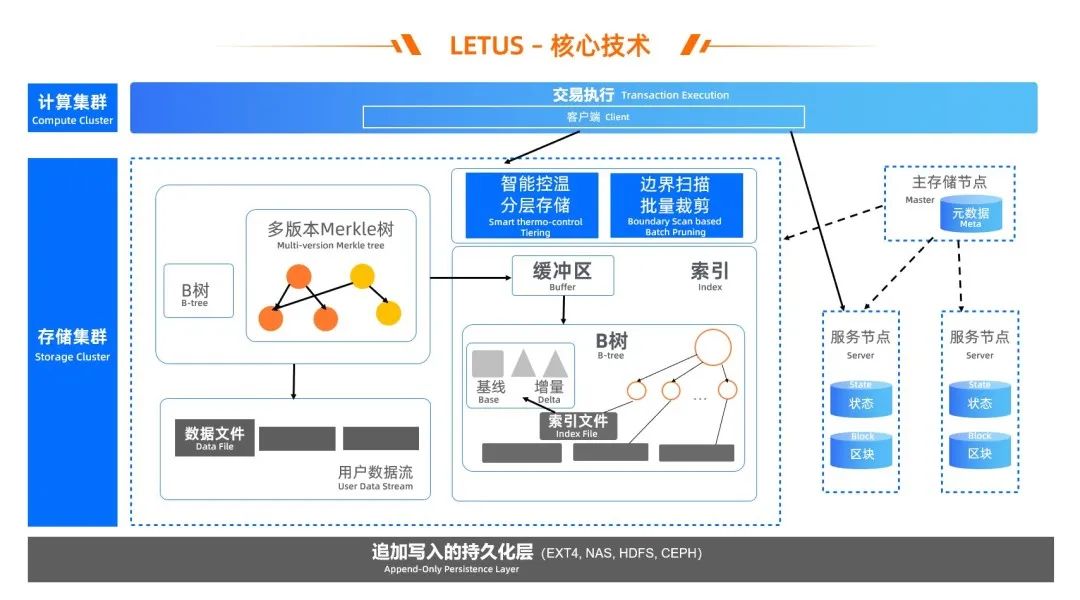
將可驗證特性下推到存儲引擎內部,由內置的 Version-based(區塊號)多版本 Merkle 樹提供可驗證可追溯,并且直接操作文件,從而縮短 IO 路徑;
01 將可驗證特性下推到存儲引擎內部,由內置的 Version-based(區塊號)多版本 Merkle 樹提供可驗證可追溯,并且直接操作文件,從而縮短 IO 路徑; 02 多版本 Merkle 樹的 Node 聚合為 page,提升磁盤友好性,page 存儲采用 Delta-encoding 思想避免 in-place 更新(結合 Bw-tree 思路),狀態數據修改時主要保存增量,定期保存基線,從而減少寫放大,也減少了空間占用; 03 為 page 存儲實現 Version-based 的存儲與檢索,索引 page 都按區塊號有序寫入、在索引文件里有序總局,核心數據結構為 B 樹變種,從而實現有序數據 locality; 04 利用區塊鏈場景數據的追加寫、Immutable 特點,架構上采用 Log-Structured 思想,通過日志文件來組織數據; 05 數據與索引分離,數據按區塊號有序寫入數據文件,通過異步 IO、協程并發等提升系統并發度,索引多模,區塊 & 狀態通用,除 Merkle 樹支持狀態數據,實現有序 B 樹支持區塊數據; 06 當前最新版本 Merkle 樹優先在內存里緩存或者全部緩存,鏈上合約執行時,如果存在則直接讀取,不需要訪問 page 來重放,從而加速合約執行。
基于些核心設計,實現了成本降低的同時性能提升,鏈平臺交易 TPS、延時等性能指標不會隨著數據規模的提升而衰減。
降成本
雖然存儲資源占用大幅降低后,但是鏈上數據依然面臨持續增長帶來的高成本問題(問題 4)。
基于 LETUS 架構的后臺數據治理框架,我們能很方便的擴展實現數據遷移 / 壓縮 / 垃圾回收等治理策略,基于這些策略,為用戶提供進一步降成本能力,并針對自己的業務特點來選擇使用:
(1)智能控溫分層存儲:存儲介質按照性能、成本分層,通過智能控溫調度數據在不同介質的分布量,將冷數據后臺自動遷移到廉價介質(如 NAS),降低存儲整體成本,并實現容量擴展,不受單盤空間限制。
(2)范圍掃描的批量裁剪:對于歷史版本 Merkle 樹和狀態對象,基于版本有序性與內置 Merkle 樹,讓用戶可以指定目標區塊號范圍裁剪,通過 Page 邊界掃描,批量索引與數據裁剪、垃圾回收實現存儲空間釋放,進一步降低狀態數據成本。
規模擴展
針對問題 5,LETUS 采用分布式存儲架構,實現單個共識參與方計算和存儲分離,計算層和存儲層可分別部署獨立集群,通過高性能網絡通訊框架進行數據讀寫訪問。
為了對海量狀態數據進行靈活的數據分片,并且保證各個區塊鏈的參與方 hash 計算的一致性,將數據切片為 256 個最小存儲單元(msu),并將一個或者多個 msu 構成一個狀態數據分片(partition),將所有數據分片調度到多個物理機器。從而實現規模彈性擴展,解決了單機存儲的容量瓶頸和帶寬瓶頸。
階段三:生產落地
為了全面落地鋪開的同時讓業務平穩運行,能夠開著飛機換引擎,在這幾年的研發過程里,我們充分準備、循序漸進的分階段落地:

2021 年 5 月,基于 LETUS 存儲引擎的區塊數據冷熱分層,在版權存證業務灰度上線,存儲成本降低 71%,解決容量瓶頸并降低運維成本。
2021 年 8 月,基于 LETUS 存儲引擎的狀態數據,在數字藏品平臺“鯨探”雙寫灰度上線,并成功支撐秒殺場景;
2022 年 2-6 月,LETUS 引擎的歷史狀態數據裁剪、存儲服務架構升級等生產 ready,在數字藏品和版權存證等業務全面落地,并從灰度雙寫切為單寫;LETUS 單寫意味著對硬件資源要求大幅下降,我們將“鯨探”生產環境的云資源全面降配,降配后鏈平臺性能水位提升 200%,同時存儲成本下降 75%。
總結與展望
螞蟻一直堅持“成熟一個開放一個”的技術戰略。同樣的,LETUS 不只為螞蟻鏈定制,也同樣給其他聯盟鏈、公鏈提供高性能、低成本的支持。
螞蟻鏈堅持技術自研,確保在共識協議、智能合約、網絡傳輸、存儲引擎、跨鏈技術、區塊鏈隱私計算等領域處于全球領先水平。我們始終認為,堅持技術自主研發是建立長期可持續競爭力的關鍵。
在“可信存力”這條賽道上,我們也需要為進一步的技術壁壘提前布局,如合約結構化查詢語言,為鏈上合約實現結構化 + 可驗證的查詢能力, 提升開發者體驗;Fast-Sync 與節點多形態,提升組網效率和節點成本靈活性;以及 Web3 等潛在的技術生態。
編輯:黃飛
-
數據存儲
+關注
關注
5文章
997瀏覽量
51610 -
區塊鏈
+關注
關注
112文章
15565瀏覽量
107904
原文標題:如何破解Web3的「存力」難題?
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
兆芯+圖云創智—可信分布式存儲系統解決方案
設備管理系統新范式:區塊鏈存證+動態權限管理

STM32H753IIT6 一款32位微控制器MCU/MSP430F5325IPNR一款16位MCU
人工智能、云計算、區塊鏈三者區別對比
想選擇一款能夠實現多個通道數據采集的ADC,求推薦
dap協議的基本概念 dap協議在區塊鏈中的應用
YOGO ROBO智能機器人助力區塊鏈行業發展
華為云、上海鈞達數科 發布區塊鏈數據要素聯合解決方案

最近推出了JFE150,這是一款面向低噪聲應用的分立式 N 溝道 JFET
探索無限可能:華為云區塊鏈 +X,創新融合新篇章






 工商網監
工商網監
評論