") 在 NVIDIA NGC 上搞定模型自動(dòng)壓縮,YOLOv7 部署加速比 5.90,BERT 部署加速比 6.22
在 NVIDIA NGC 上搞定模型自動(dòng)壓縮,YOLOv7 部署加速比 5.90,BERT 部署加速比 6.22
PaddleSlim 發(fā)布 AI 模型自動(dòng)壓縮的工具,帶來(lái)全新升級(jí) AI 模型一鍵自動(dòng)壓縮體驗(yàn)。歡迎廣大開(kāi)發(fā)者使用 NVIDIA 與飛槳聯(lián)合深度適配的 NGC 飛槳容器在 NVIDIA GPU 上體驗(yàn)!
PaddleSlim 自動(dòng)壓縮工具,
30+CV、NLP 模型實(shí)戰(zhàn)
眾所周知,計(jì)算機(jī)視覺(jué)技術(shù)(CV)是企業(yè)人工智能應(yīng)用比重最高的領(lǐng)域之一。為降低企業(yè)成本,工程師們一直在探索各類(lèi)模型壓縮技術(shù),來(lái)產(chǎn)出“更準(zhǔn)、更小、更快”的 AI 模型部署落地。而在自然語(yǔ)言處理領(lǐng)域(NLP)中,隨著模型精度的不斷提升,模型的規(guī)模也越來(lái)越大,例如以 BERT、GPT 為代表的預(yù)訓(xùn)練模型等,這成為企業(yè) NLP 模型部署落地的攔路虎。
針對(duì)企業(yè)落地模型壓縮迫切的需求,PaddleSlim 團(tuán)隊(duì)開(kāi)發(fā)了一個(gè)低成本、高收益的 AI 模型自動(dòng)壓縮工具(ACT, Auto Compression Toolkit),無(wú)需修改訓(xùn)練源代碼,通過(guò)幾十分鐘量化訓(xùn)練,保證模型精度的同時(shí),極大的減小模型體積,降低顯存占用,提升模型推理速度,助力 AI 模型的快速落地!
使用 ACT 中的基于知識(shí)蒸餾的量化訓(xùn)練方法訓(xùn)練 YOLOv7 模型,與原始的 FP32 模型相比,INT8 量化后的模型減小 75%,在 NVIDIA GPU 上推理加速 5.90 倍。
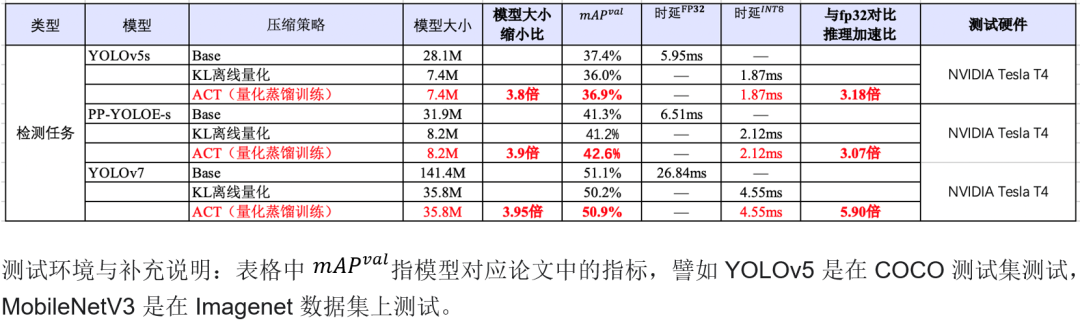 ?表1 自動(dòng)壓縮工具在 CV 模型上的壓縮效果和推理加速
?表1 自動(dòng)壓縮工具在 CV 模型上的壓縮效果和推理加速使用 ACT 中的結(jié)構(gòu)化稀疏和蒸餾量化方法訓(xùn)練 ERNIE3.0 模型,與原始的 FP32 對(duì)比,INT8 量化后的模型減小 185%,在 NVIDIA GPU 上推理加速 6.37 倍。

表2 自動(dòng)壓縮工具在 NLP 模型上的壓縮效果和推理加速
支持如此強(qiáng)大功能的核心技術(shù)是來(lái)源于 PaddleSlim 團(tuán)隊(duì)自研的自動(dòng)壓縮工具。自動(dòng)壓縮相比于傳統(tǒng)手工壓縮,自動(dòng)化壓縮的“自動(dòng)”主要體現(xiàn)在 4 個(gè)方面:解耦訓(xùn)練代碼、離線量化超參搜索、算法自動(dòng)組合和硬件感知。
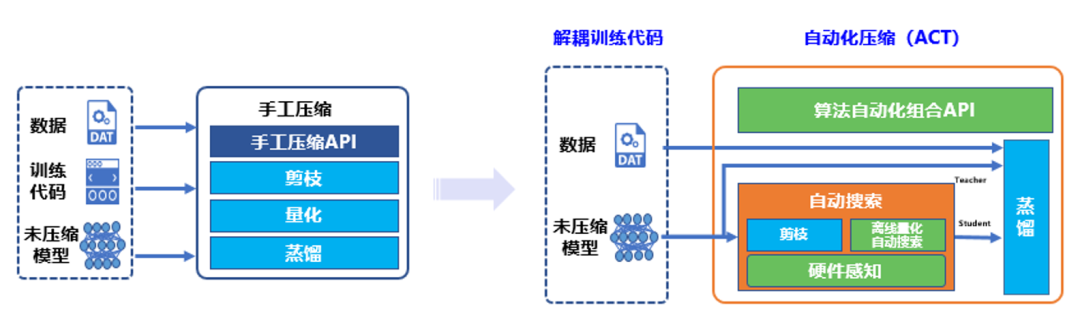
圖1 傳統(tǒng)手工壓縮與自動(dòng)化壓縮工具對(duì)比
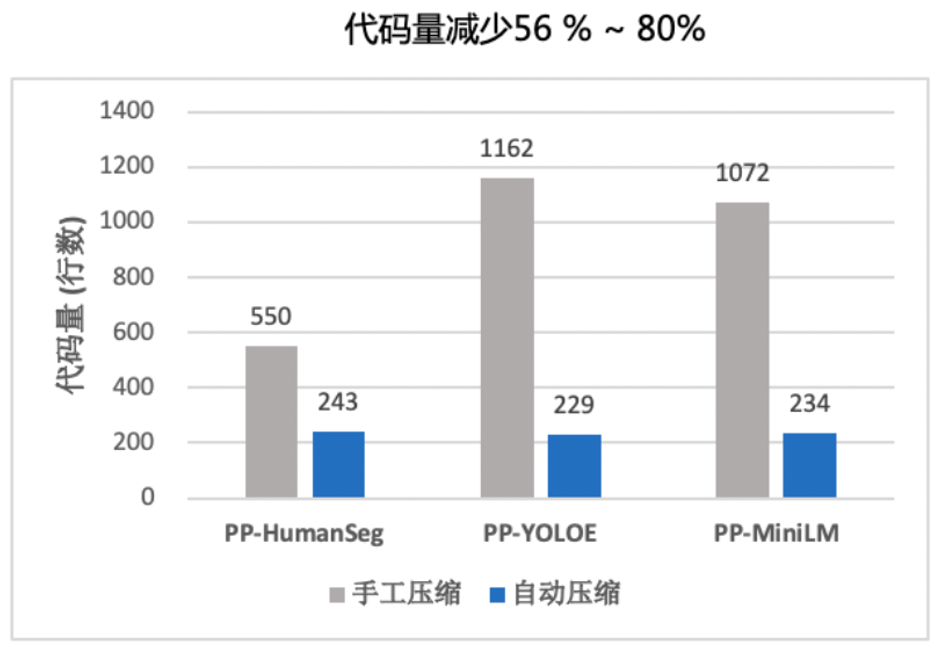
圖2 傳統(tǒng)手工壓縮與自動(dòng)化壓縮工具代碼量對(duì)比
更多詳細(xì)文檔,請(qǐng)參考:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression
PaddleSlim 研發(fā)團(tuán)隊(duì)詳解自動(dòng)壓縮工具 CV 模型和NLP模型兩日課回放,可以掃描下方二維碼,加入自動(dòng)壓縮技術(shù)官方交流群獲取。除此之外,入群福利還包括:深度學(xué)習(xí)學(xué)習(xí)資料、歷屆頂會(huì)壓縮論文、百度架構(gòu)師詳解自動(dòng)壓縮等。

NGC 飛槳容器介紹
如果您希望體驗(yàn)自動(dòng)壓縮工具的新特性,歡迎使用 NGC 飛槳容器。NVIDIA 與百度飛槳聯(lián)合開(kāi)發(fā)了 NGC 飛槳容器,將最新版本的飛槳與最新的 NVIDIA 的軟件棧(如 CUDA)進(jìn)行了無(wú)縫的集成與性能優(yōu)化,最大程度的釋放飛槳框架在 NVIDIA 最新硬件上的計(jì)算能力。這樣,用戶(hù)不僅可以快速開(kāi)啟 AI 應(yīng)用,專(zhuān)注于創(chuàng)新和應(yīng)用本身,還能夠在 AI 訓(xùn)練和推理任務(wù)上獲得飛槳+NVIDIA 帶來(lái)的飛速體驗(yàn)。
最佳的開(kāi)發(fā)環(huán)境搭建工具 - 容器技術(shù)。
-
容器其實(shí)是一個(gè)開(kāi)箱即用的服務(wù)器。極大降低了深度學(xué)習(xí)開(kāi)發(fā)環(huán)境的搭建難度。例如你的開(kāi)發(fā)環(huán)境中包含其他依賴(lài)進(jìn)程(redis,MySQL,Ngnix,selenium-hub 等等),或者你需要進(jìn)行跨操作系統(tǒng)級(jí)別的遷移。
-
容器鏡像方便了開(kāi)發(fā)者的版本化管理
-
容器鏡像是一種易于復(fù)現(xiàn)的開(kāi)發(fā)環(huán)境載體
-
容器技術(shù)支持多容器同時(shí)運(yùn)行
最好的 PaddlePaddle 容器
NGC 飛槳容器針對(duì) NVIDIA GPU 加速進(jìn)行了優(yōu)化,并包含一組經(jīng)過(guò)驗(yàn)證的庫(kù),可啟用和優(yōu)化 NVIDIA GPU 性能。此容器還可能包含對(duì) PaddlePaddle 源代碼的修改,以最大限度地提高性能和兼容性。此容器還包含用于加速 ETL(DALI,RAPIDS)、訓(xùn)練(cuDNN,NCCL)和推理(TensorRT)工作負(fù)載的軟件。
PaddlePaddle 容器具有以下優(yōu)點(diǎn):
-
適配最新版本的 NVIDIA 軟件棧(例如最新版本 CUDA),更多功能,更高性能。
-
更新的 Ubuntu 操作系統(tǒng),更好的軟件兼容性
-
按月更新
-
滿(mǎn)足 NVIDIA NGC 開(kāi)發(fā)及驗(yàn)證規(guī)范,質(zhì)量管理
通過(guò)飛槳官網(wǎng)快速獲取
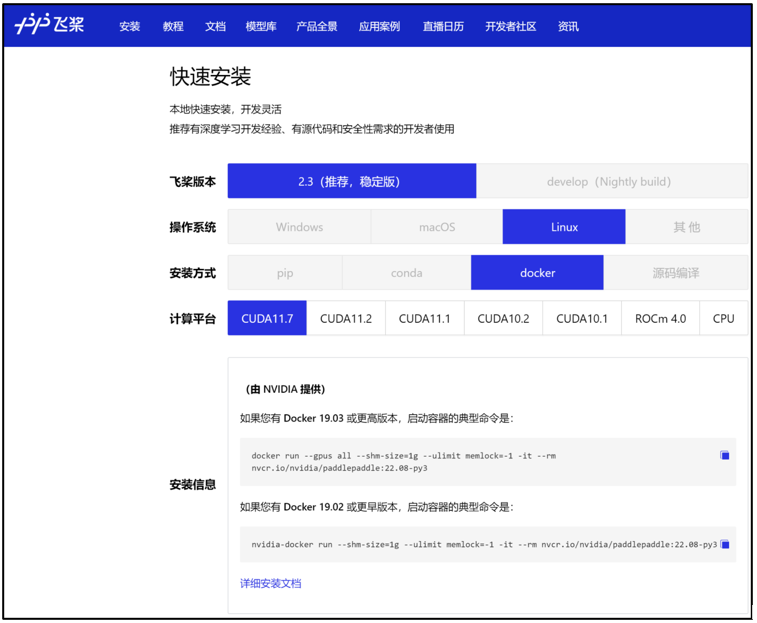
環(huán)境準(zhǔn)備
使用 NGC 飛槳容器需要主機(jī)系統(tǒng)(Linux)安裝以下內(nèi)容:
-
Docker 引擎
-
NVIDIA GPU 驅(qū)動(dòng)程序
-
NVIDIA 容器工具包
有關(guān)支持的版本,請(qǐng)參閱 NVIDIA 框架容器支持矩陣和 NVIDIA 容器工具包文檔。
不需要其他安裝、編譯或依賴(lài)管理。無(wú)需安裝 NVIDIA CUDA Toolkit。
NGC 飛槳容器正式安裝:
要運(yùn)行容器,請(qǐng)按照 NVIDIA Containers For Deep Learning Frameworks User’s Guide 中 Running A Container 一章中的說(shuō)明發(fā)出適當(dāng)?shù)拿睿⒅付ㄗ?cè)表、存儲(chǔ)庫(kù)和標(biāo)簽。有關(guān)使用 NGC 的更多信息,請(qǐng)參閱 NGC 容器用戶(hù)指南。如果您有 Docker 19.03 或更高版本,啟動(dòng)容器的典型命令是:

*詳細(xì)安裝介紹 《NGC 飛槳容器安裝指南》
https://www.paddlepaddle.org.cn/documentation/docs/zh/install/install_NGC_PaddlePaddle_ch.html
*詳細(xì)產(chǎn)品介紹視頻
【飛槳開(kāi)發(fā)者說(shuō)|NGC 飛槳容器全新上線 NVIDIA 產(chǎn)品專(zhuān)家全面解讀】
https://www.bilibili.com/video/BV16B4y1V7ue?share_source=copy_web&vd_source=266ac44430b3656de0c2f4e58b4daf82
原文標(biāo)題:在 NVIDIA NGC 上搞定模型自動(dòng)壓縮,YOLOv7 部署加速比 5.90,BERT 部署加速比 6.22
文章出處:【微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3926瀏覽量
93190
原文標(biāo)題:在 NVIDIA NGC 上搞定模型自動(dòng)壓縮,YOLOv7 部署加速比 5.90,BERT 部署加速比 6.22
文章出處:【微信號(hào):NVIDIA_China,微信公眾號(hào):NVIDIA英偉達(dá)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Cognizant將與NVIDIA合作部署神經(jīng)人工智能平臺(tái),加速企業(yè)人工智能應(yīng)用

請(qǐng)問(wèn)如何在imx8mplus上部署和運(yùn)行YOLOv5訓(xùn)練的模型?
英偉達(dá)GTC2025亮點(diǎn):NVIDIA認(rèn)證計(jì)劃擴(kuò)展至企業(yè)存儲(chǔ)領(lǐng)域,加速AI工廠部署
K230D部署模型失敗的原因?
yolov5轉(zhuǎn)onnx在cubeAI進(jìn)行部署,部署失敗的原因?
添越智創(chuàng)基于 RK3588 開(kāi)發(fā)板部署測(cè)試 DeepSeek 模型全攻略
【ELF 2學(xué)習(xí)板試用】ELF2開(kāi)發(fā)板(飛凌嵌入式)搭建深度學(xué)習(xí)環(huán)境部署(RKNN環(huán)境部署)
在樹(shù)莓派上部署YOLOv5進(jìn)行動(dòng)物目標(biāo)檢測(cè)的完整流程
YOLOv6在LabVIEW中的推理部署(含源碼)

NVIDIA NIM助力企業(yè)高效部署生成式AI模型
快速部署Tensorflow和TFLITE模型在Jacinto7 Soc

Yuan2.0千億大模型在通用服務(wù)器NF8260G7上的推理部署

用OpenVINO C# API在intel平臺(tái)部署YOLOv10目標(biāo)檢測(cè)模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論