") 【AI簡(jiǎn)報(bào)20221028】 vivo公布自研芯片、AR-HUD處于爆發(fā)前夜
【AI簡(jiǎn)報(bào)20221028】 vivo公布自研芯片、AR-HUD處于爆發(fā)前夜
嵌入式 AI
AI 簡(jiǎn)報(bào) 20221028 期
1. vivo公布自研芯片黑科技 AI-ISP讓算力捅破天
原文:
https://app.myzaker.com/news/article.php?pk=63476be18e9f0903ac797c80
在討論一款手機(jī)的實(shí)力時(shí),影像是其中最重要的評(píng)判維度之一。隨著手機(jī)攝影的發(fā)展,許多之前困擾手機(jī)的拍照難題,都迎來(lái)了行之有效的解決方案。其中,自研影像芯片成為移動(dòng)影像迭代的一個(gè)核心方向,讓手機(jī)能夠在暗光和運(yùn)動(dòng)場(chǎng)景等一些高挑戰(zhàn)性場(chǎng)景中拍出好照片。
如今,一聊到自研芯片,很多熟悉數(shù)碼圈的朋友第 一時(shí)間想到的可能就是藍(lán)廠了。2021 年,vivo X70 系列攜vivo自研芯片V1 發(fā)布,實(shí)現(xiàn)更好的夜景成像效果,加之vivo對(duì)影像技術(shù)的大力投入,使得X系列獲得了很高的市場(chǎng)與消費(fèi)者口碑。從X70 系列之后,手機(jī)行業(yè)也正式掀起了自研影像芯片的潮流。

在剛剛結(jié)束的影像戰(zhàn)略發(fā)布會(huì)上,vivo展示了其完善的影像技術(shù)矩陣。作為影像算法升級(jí)的最有力保障,vivo宣布將在下一代自研芯片設(shè)計(jì)中升級(jí)全新的架構(gòu)——從傳統(tǒng)ISP架構(gòu)升級(jí)為AI ISP架構(gòu),進(jìn)一步提升影像效果體驗(yàn)。
那么問(wèn)題來(lái)了,AI-ISP是什么?
傳統(tǒng)ISP架構(gòu)雖然能以極低延時(shí)處理大量的數(shù)據(jù)流水,但只能解決已知的、特定的問(wèn)題,面對(duì)復(fù)雜、隨機(jī)問(wèn)題時(shí)則會(huì)面臨巨大的困難。而AI擅長(zhǎng)處理復(fù)雜的、未知的問(wèn)題。因此,將傳統(tǒng) ISP 低延時(shí)、高能效的特點(diǎn)進(jìn)一步帶入到 AI 實(shí)時(shí)處理運(yùn)算架構(gòu)中,AI-ISP應(yīng)運(yùn)而生。AI-ISP架構(gòu)結(jié)合兩者的優(yōu)勢(shì),相當(dāng)于給傳統(tǒng)ISP芯片加一個(gè)新的AI大腦。
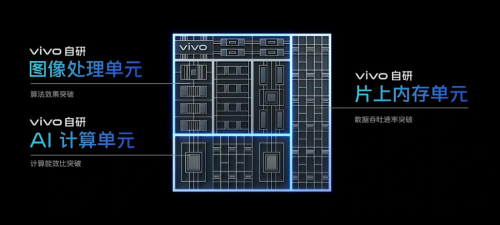
據(jù)vivo介紹,在AI-ISP上集成vivo自研的AI計(jì)算單元,讓數(shù)據(jù)吞吐速率、能效比都有了大幅提升,更適合海量的信息處理,因此能實(shí)現(xiàn)發(fā)散式的信息處理及存儲(chǔ),使得處理與存儲(chǔ)的效率大大提高。在此基礎(chǔ)上AI-NR降噪、HDR影調(diào)融合、MEMC插幀等算法效果可以得到極大的優(yōu)化。
2. 車(chē)載抬頭顯示HUD從“黑科技”走向標(biāo)配,AR-HUD處于爆發(fā)前夜
原文:
https://mp.weixin.qq.com/s/TMhMjFZbw96n4CUkVQ_z1w
在高端乘用車(chē)完成試點(diǎn)以及認(rèn)知普及之后,車(chē)載HUD(抬頭顯示系統(tǒng))終于在2020年開(kāi)始了規(guī)模商用,很多人將這一年定義為車(chē)載HUD的產(chǎn)業(yè)化元年。在智能駕駛汽車(chē)的推動(dòng)下,HUD有望在乘用車(chē)搭載方面更進(jìn)一步,成為系統(tǒng)標(biāo)配,產(chǎn)業(yè)將迎來(lái)爆發(fā)期。
根據(jù)QYResearch的《2022-2028中國(guó)車(chē)載HUD系統(tǒng)市場(chǎng)現(xiàn)狀研究分析與發(fā)展前景預(yù)測(cè)報(bào)告》市場(chǎng)調(diào)研報(bào)道,2022年全球車(chē)載HUD市場(chǎng)規(guī)模有望達(dá)到22億美元,滲透率達(dá)到9.5%;到2025年,車(chē)載HUD滲透率有望達(dá)到45%,2019年-2025年的年復(fù)合增長(zhǎng)率高達(dá)71%。
從C-HUD到AR-HUD
HUD的英文全稱(chēng)是Head Up Display,所以中文譯作抬頭顯示系統(tǒng),最早應(yīng)用于軍用飛機(jī)上,幫助駕駛員減輕認(rèn)知負(fù)荷。發(fā)展至今,車(chē)載HUD已經(jīng)演化出三種形式,也完成了從C-HUD到AR-HUD的蛻變,另外一種是W-HUD。
C-HUD是指Combiner HUD,組合式抬頭顯示系統(tǒng)。C-HUD是將信息投放在儀表盤(pán)上方的樹(shù)脂板上,這是一個(gè)半透明的板子,能夠反射出投射信息的虛像。由于C-HUD需要樹(shù)脂板作為投放介質(zhì),因此往往會(huì)以后裝的方式安裝,這就導(dǎo)致C-HUD存在一些“先天性”的弊病,比如投射范圍小,距離近,且容易引發(fā)車(chē)禍時(shí)的二次傷害。
W-HUD是指Windshield HUD,屬于C-HUD的升級(jí)版,不再需要樹(shù)脂板這樣的輔助器材,如其名稱(chēng)所顯露的,W-HUD直接將信息投放在汽車(chē)前擋風(fēng)玻璃上。由于沒(méi)有介質(zhì)板的限制,W-HUD的投射范圍更大、更遠(yuǎn)。不過(guò),由于汽車(chē)擋風(fēng)玻璃的形狀是弧形、斜向的,增加了光學(xué)信息的投射難度,產(chǎn)品光學(xué)結(jié)構(gòu)相對(duì)復(fù)雜,成本相對(duì)較高。
比W-HUD更進(jìn)一步的便是AR-HUD,全稱(chēng)為Augmented Reality HUD。顧名思義,AR-HUD便是AR技術(shù)在汽車(chē)領(lǐng)域的一次成功的應(yīng)用嘗試。AR-HUD的投放介質(zhì)同樣是汽車(chē)擋風(fēng)玻璃,相較于W-HUD投放信息和道路實(shí)況是脫離的,AR-HUD通過(guò)數(shù)字微鏡原件生成圖像元素,經(jīng)過(guò)反射鏡投射出去的圖片具有層次感,分為近投影和遠(yuǎn)投影。其中近投影所包含的速度和油表信息與W-HUD差別不大,不過(guò)遠(yuǎn)投影能夠?qū)崿F(xiàn)虛擬圖像和現(xiàn)實(shí)路況的融合,增加駕駛員對(duì)道路信息的認(rèn)知,使得駕駛更方便安全。
根據(jù)德州儀器的介紹和演示,如果要實(shí)現(xiàn)AR-HUD,VID>7米,并且FOV>10°。在遠(yuǎn)投影方面,將融入跟車(chē)提醒、行人預(yù)警、車(chē)道偏離指引、變道指引等信息。
目前,在車(chē)載HUD市場(chǎng)上,W-HUD是市場(chǎng)主流,AR-HUD則是未來(lái)的趨勢(shì),已經(jīng)進(jìn)入量產(chǎn)和推廣階段。不過(guò),AR-HUD比W-HUD的光學(xué)系統(tǒng)更復(fù)雜,成本也就更高,因此最先搭載AR-HUD的車(chē)型大都價(jià)格不菲,以中高端車(chē)型為主。
產(chǎn)業(yè)上下游積極布局
無(wú)論是現(xiàn)階段的W-HUD,還是未來(lái)的AR-HUD,都受到了車(chē)廠的推崇,是汽車(chē)智能座艙重要的組成部分,也是汽車(chē)核心賣(mài)點(diǎn)之一。
從產(chǎn)業(yè)鏈分布來(lái)看,車(chē)載HUD的上游主要是原材料供應(yīng)廠商和軟件方案公司,中游是各大車(chē)載HUD品牌商,下游則是整車(chē)廠。車(chē)載HUD所用到的原材料除了擋風(fēng)玻璃和曲面鏡以外,最重要的還是顯示源,也就是光學(xué)系統(tǒng)。
車(chē)載HUD顯示源用到的主要芯片包括控制芯片、ISP芯片、DLP、LCD芯片、LCOS芯片等。供應(yīng)商包括德州儀器、京東方、愛(ài)普生、非寶電子、索尼等企業(yè)。目前,W-HUD用到的主要激光顯示技術(shù)包括四種:DLP、LCD、LCOS以及MEMS激光投影。
在DLP方面,和全球數(shù)字放映機(jī)市場(chǎng)類(lèi)似,TI在車(chē)載DLP芯片方面具有絕對(duì)的領(lǐng)先優(yōu)勢(shì)。該公司自2015年發(fā)布首款應(yīng)用車(chē)載HUD的DLP芯片組之后,此后一直深耕于此,目前基于TI的DLP芯片組已經(jīng)能夠?qū)崿F(xiàn)AR-HUD方案。
LCD液晶投影技術(shù)具有圖像色彩飽和度好,層次豐富,色彩分離好等優(yōu)點(diǎn),主要的核心技術(shù)掌握在索尼和愛(ài)普生手中,不過(guò)國(guó)內(nèi)的京東方、天馬、信利等也在布局這一塊;LCOS是硅基液晶技術(shù),索尼同樣是重要的技術(shù)提供商,此外還有JVC和晶典等。
MEMS激光投影是將RGB三基色激光模組與微機(jī)電系統(tǒng)結(jié)合的投影顯示技術(shù),優(yōu)點(diǎn)是高亮度、體積小、色域廣,不過(guò)成本也相對(duì)較高。相較于其他顯示方案的核心技術(shù)握在國(guó)際廠商手里,MEMS激光投影被認(rèn)為是自主品牌在車(chē)載HUD核心芯片突圍的好機(jī)會(huì)。目前,車(chē)規(guī)級(jí)MEMS激光投影芯片主要供應(yīng)商是Microvision、豐寶電子等。
在品牌方面,目前W-HUD的主要市場(chǎng)份額主要掌握在外資品牌手中,包括電裝、日本精機(jī)、偉世通、德國(guó)大陸等,這些公司占據(jù)著國(guó)內(nèi)外大部分的市場(chǎng)份額,并擁有成熟的前裝供應(yīng)鏈體系,也具備前裝優(yōu)勢(shì)。當(dāng)然,國(guó)內(nèi)的汽車(chē)零部件生產(chǎn)商澤景電子、華陽(yáng)集團(tuán)、均勝電子等也在布局車(chē)載HUD。隨著AR-HUD進(jìn)入量產(chǎn)階段,目前華為、歐菲光等科技企業(yè)以及未來(lái)黑科技、點(diǎn)石創(chuàng)新等初創(chuàng)企業(yè)迎來(lái)市場(chǎng)機(jī)遇。
據(jù)統(tǒng)計(jì),2021年以來(lái)AR-HUD密集上車(chē),長(zhǎng)城摩卡、吉利星越L、大眾ID系列、廣汽傳祺GS8、北汽魔方、飛凡R7等車(chē)型均選擇搭載了AR-HUD,在2021年上半年,AR-HUD在國(guó)內(nèi)的裝配量達(dá)到3.5萬(wàn)輛,并且已經(jīng)在2021年8月份超過(guò)了C-HUD。
對(duì)于國(guó)產(chǎn)廠商而言,想要突圍目前來(lái)看還是任重道遠(yuǎn)。截止到2020年的統(tǒng)計(jì)數(shù)據(jù)顯示,國(guó)內(nèi)車(chē)載HUD市場(chǎng)的前三大廠商均為國(guó)際廠商,分別是精機(jī)、大陸集團(tuán)和電裝,市占比分別為33.3%、27%和20%。
寫(xiě)在最后
目前,車(chē)載HUD正處在W-HUD向AR-HUD過(guò)渡的時(shí)代,國(guó)際Tier 1級(jí)汽車(chē)零部件供應(yīng)商的話語(yǔ)權(quán)在降低,國(guó)產(chǎn)品牌迎來(lái)了機(jī)會(huì),在核心器件和品牌方面都已經(jīng)打入到市場(chǎng)中心區(qū)域。不過(guò),汽車(chē)供應(yīng)鏈一直以來(lái)都較為穩(wěn)定,國(guó)產(chǎn)品牌想要更進(jìn)一步,還需在技術(shù)和產(chǎn)品性能上領(lǐng)先于人。
3. AI傳感器成為趨勢(shì)!功耗更低、效率更高
原文:
https://mp.weixin.qq.com/s/ElDo7m_fsbbp6rRUW99pYw
近日消息,劍橋初創(chuàng)公司InferSens表示,將其低功耗傳感器與復(fù)雜深度學(xué)習(xí)技術(shù)相結(jié)合,研究了用于智能建筑的低功耗邊緣AI傳感器。
InferSens使用具有本地AI模型和創(chuàng)新機(jī)械和系統(tǒng)工程的第三方處理器來(lái)為建筑環(huán)境創(chuàng)建智能傳感器。該公司傳感器技術(shù)的第一個(gè)版本計(jì)劃于2023年第一季度推出。這是一種低成本、電池供電的水流量和溫度傳感器,用于監(jiān)測(cè)和檢測(cè)水系統(tǒng)中的軍團(tuán)菌風(fēng)險(xiǎn)。
意法半導(dǎo)體、索尼等傳統(tǒng)芯片廠商都推出AI傳感器
不久前,意法半導(dǎo)體也推出了內(nèi)置智能傳感器處理單元 (ISPU) 的慣性傳感器ISM330ISN。ISM330ISN內(nèi)置的智能技術(shù)賦能智能設(shè)備在傳感器中執(zhí)行高級(jí)運(yùn)動(dòng)檢測(cè)功能,而無(wú)需與外部微控制器 (MCU)交互,從而降低了系統(tǒng)級(jí)功耗。
意法半導(dǎo)體的方法是直接在傳感器芯片上集成為機(jī)器學(xué)習(xí)應(yīng)用優(yōu)化的專(zhuān)用處理器 ISPU。意法半導(dǎo)體的 ISPU基于數(shù)字信號(hào)處理 (DSP) 架構(gòu),極其緊湊和節(jié)能,具有 40KB 的 RAM內(nèi)存。ISPU 執(zhí)行單精度浮點(diǎn)運(yùn)算,是設(shè)計(jì)機(jī)器學(xué)習(xí)應(yīng)用和二元神經(jīng)網(wǎng)絡(luò)的理想選擇。
這個(gè)智能內(nèi)核占用的芯片面積非常小,因此,ISM330ISN模塊的封裝面積比典型的在封裝內(nèi)整合MCU的傳感器解決方案小50%,功耗低 50%。
意法半導(dǎo)體模擬 MEMS 和傳感器產(chǎn)品部營(yíng)銷(xiāo)總經(jīng)理 Simone Ferri 表示,智能從前是部署在網(wǎng)絡(luò)邊緣的應(yīng)用處理器上,而現(xiàn)在正在轉(zhuǎn)向深度邊緣的傳感器內(nèi)部。ISM330ISN IMU 預(yù)示著新一類(lèi)智能傳感器的來(lái)臨,即開(kāi)始利用嵌入式 AI 處理復(fù)雜任務(wù),比如模式識(shí)別和異常檢測(cè),可以大大提高系統(tǒng)能效和性能。
其實(shí)早在2020年,索尼就宣布推出了兩款A(yù)I圖像傳感器——IMX500和IMX501。AI圖像傳感器兼具運(yùn)算能力和內(nèi)存,能夠在沒(méi)有額外硬件輔助的情況下執(zhí)行機(jī)器學(xué)習(xí)驅(qū)動(dòng)的計(jì)算機(jī)視覺(jué)任務(wù),可以使很多依賴機(jī)器學(xué)習(xí)算法的圖像處理技術(shù)能夠在本地運(yùn)行,更簡(jiǎn)單、高效、安全。
索尼推出的AI圖像傳感器,首批目標(biāo)是零售商和工業(yè)客戶。索尼業(yè)務(wù)與創(chuàng)新副總裁馬克·漢森認(rèn)為,相比將數(shù)據(jù)發(fā)送到云端的解決方案,AI圖像傳感器的應(yīng)用潛力巨大,成本效益更高,尤其是在邊緣計(jì)算領(lǐng)域。
商湯、曠視等新興AI技術(shù)公司也在探索AI傳感器
除了傳統(tǒng)的傳感器廠商之外,商湯、曠視等AI公司也在探索AI傳感器。今年7月,商湯智能產(chǎn)業(yè)研究院發(fā)布《AI傳感器:智能手機(jī)影像新核心》白皮書(shū)。該白皮書(shū)提到,在智能手機(jī)市場(chǎng)緩慢步入瓶頸期的趨勢(shì)下,影像功能成為產(chǎn)業(yè)破局焦點(diǎn),而AI軟件與CMOS圖像傳感器硬件的融合,將是智能手機(jī)影像能力持續(xù)提升的破題之道。
過(guò)去幾年,AI算法讓手機(jī)的影像能力得到了不小的提升。但在這種方案中,圖像傳感和AI算法的運(yùn)行,在不同的硬件上完成,圖像傳感器提供圖像信號(hào),處理器或者AI加速芯片執(zhí)行AI算法。這會(huì)造成能耗資源的浪費(fèi),并且難以處理一些需要及時(shí)響應(yīng)的場(chǎng)景。
白皮書(shū)指出,融入了AI技術(shù)的CMOS圖像傳感器,可以最大化地發(fā)揮原始光信號(hào)的價(jià)值。
在設(shè)備獲取視覺(jué)信號(hào)的伊始,AI傳感器就可以進(jìn)行優(yōu)化和處理,增強(qiáng)真實(shí)世界感知、提高圖像和視頻的質(zhì)量、豐富內(nèi)容細(xì)節(jié),同時(shí)最大限度地降低了設(shè)備功耗,并增強(qiáng)了數(shù)據(jù)安全性。
據(jù)介紹,早在2019年,商湯就與全球領(lǐng)先的圖像傳感器廠商開(kāi)展緊密合作,將AI算法和傳感器硬件直接融合。目前,商湯AI傳感器已完成多款產(chǎn)品,并成功落地多款高端旗艦手機(jī)。
商湯認(rèn)為,面向未來(lái),AI傳感器的價(jià)值不僅在于提升智能手機(jī)的影像能力,它更將成為機(jī)器認(rèn)知世界的基礎(chǔ)設(shè)施,為更多物聯(lián)網(wǎng)終端賦予智能感知與內(nèi)容增強(qiáng)的能力。比如,在智能汽車(chē)領(lǐng)域,AI傳感器將成為車(chē)輛感知世界的核心部件;在智慧城市領(lǐng)域,AI傳感器更將為挖掘視頻信息的價(jià)值發(fā)揮重要作用。
曠視研究員范浩強(qiáng)今年7月也在某個(gè)論壇上談到,隨著AI、視覺(jué)算法等領(lǐng)域的發(fā)展,傳感器將不再單獨(dú)的、直接地提供應(yīng)用價(jià)值,傳感器和應(yīng)用之間需要算法來(lái)作為承上啟下的橋梁。從技術(shù)角度講,這兩者最顯著的結(jié)合點(diǎn)就是計(jì)算攝影。
曠視也已經(jīng)深度參與手機(jī)影像的能力提升中,目前曠視的4K級(jí)別的硬件方案已經(jīng)實(shí)現(xiàn)了量產(chǎn),并積極推動(dòng)8K AI畫(huà)質(zhì)硬件方案的研發(fā)與產(chǎn)品化。
小結(jié)
從傳統(tǒng)芯片廠商及AI公司的表現(xiàn)來(lái)看,AI傳感器似乎成為一種新的趨勢(shì)。在傳感器內(nèi)部增加智能的部分,有諸多好處,之前傳感器和AI算法的運(yùn)行實(shí)在不同的硬件上完成,耗費(fèi)資源,而增加了智能的AI傳感器,可以使得整個(gè)系統(tǒng)更簡(jiǎn)單、更高效、更安全。
4. 掀起一股中國(guó)風(fēng),最強(qiáng)中文AI作畫(huà)大模型文心ERNIE-ViLG 2.0來(lái)了
原文:
https://mp.weixin.qq.com/s/x3dnkBF7BKDMEU_rt8QmDg
據(jù)了解,ERNIE-ViLG 2.0 在文本生成圖像公開(kāi)權(quán)威評(píng)測(cè)集 MS-COCO 和人工盲評(píng)上均超越了 Stable Diffusion、DALL-E 2 等模型,取得了當(dāng)前該領(lǐng)域的世界最好效果,在語(yǔ)義可控性、圖像清晰度、中國(guó)文化理解等方面均展現(xiàn)出了顯著優(yōu)勢(shì)。
論文鏈接:
https://arxiv.org/pdf/2210.15257.pdf
體驗(yàn)鏈接:
https://wenxin.baidu.com/ernie-vilg
AIGC (AI-Generated Content) 是繼 UGC、PGC 之后,利用 AI 技術(shù)自動(dòng)生成內(nèi)容的新型生產(chǎn)方式。AI 作畫(huà)作為 AIGC 重要方向之一,蘊(yùn)含了極大的產(chǎn)業(yè)應(yīng)用價(jià)值。相比于人類(lèi)創(chuàng)作者,AI 作畫(huà)展現(xiàn)出了創(chuàng)作成本低、速度快且易于批量化生產(chǎn)的巨大優(yōu)勢(shì)。
近一年來(lái),該領(lǐng)域迅猛發(fā)展,國(guó)際科技巨頭和初創(chuàng)企業(yè)爭(zhēng)相涌入,國(guó)內(nèi)也出現(xiàn)了眾多 AI 作畫(huà)產(chǎn)品,這些產(chǎn)品背后主要使用基于擴(kuò)散生成算法的 DALL-E 2 和 Stable Diffusion 等國(guó)外模型。目前,這類(lèi)基礎(chǔ)模型在國(guó)內(nèi)尚處空白,ERNIE-ViLG 2.0 是國(guó)內(nèi)首個(gè)在該方向取得突破的工作。
當(dāng)前 AI 作畫(huà)技術(shù)在圖像細(xì)節(jié)紋理的流暢度、清晰度、語(yǔ)義的可控性等方面還存在諸多問(wèn)題。基于此,百度提出了基于知識(shí)增強(qiáng)的混合降噪專(zhuān)家(Mixture-of-Denoising-Experts,MoDE)建模的跨模態(tài)大模型 ERNIE-ViLG 2.0,在訓(xùn)練過(guò)程中,通過(guò)引入視覺(jué)知識(shí)和語(yǔ)言知識(shí),提升模型跨模態(tài)語(yǔ)義理解能力與可控生成能力;在擴(kuò)散降噪過(guò)程中,通過(guò)混合專(zhuān)家網(wǎng)絡(luò)建模,增強(qiáng)模型建模能力,提升圖像的生成質(zhì)量。
我們先來(lái)欣賞下 ERNIE-ViLG 2.0 根據(jù)文本描述生成圖像的一些示例:
ERNIE-ViLG 2.0 可應(yīng)用于工業(yè)設(shè)計(jì)、動(dòng)漫設(shè)計(jì)、游戲制作、攝影藝術(shù)等場(chǎng)景,激發(fā)設(shè)計(jì)者創(chuàng)作靈感,提升內(nèi)容生產(chǎn)的效率。通過(guò)簡(jiǎn)單的描述,模型便可以在短短幾十秒內(nèi)生成設(shè)計(jì)圖,極大地提升了設(shè)計(jì)效率、降低商業(yè)出圖的門(mén)檻。
5. DeepMind新作:無(wú)需權(quán)重更新、提示和微調(diào),transformer在試錯(cuò)中自主改進(jìn)
原文:
https://mp.weixin.qq.com/s/zKQIlXJ1jRKCyGQn_dqjDw
論文地址:
https://arxiv.org/pdf/2210.14215.pdf
目前,Transformers 已經(jīng)成為序列建模的強(qiáng)大神經(jīng)網(wǎng)絡(luò)架構(gòu)。預(yù)訓(xùn)練 transformer 的一個(gè)顯著特性是它們有能力通過(guò)提示 conditioning 或上下文學(xué)習(xí)來(lái)適應(yīng)下游任務(wù)。經(jīng)過(guò)大型離線數(shù)據(jù)集上的預(yù)訓(xùn)練之后,大規(guī)模 transformers 已被證明可以高效地泛化到文本補(bǔ)全、語(yǔ)言理解和圖像生成方面的下游任務(wù)。
最近的工作表明,transformers 還可以通過(guò)將離線強(qiáng)化學(xué)習(xí)(RL)視作順序預(yù)測(cè)問(wèn)題,進(jìn)而從離線數(shù)據(jù)中學(xué)習(xí)策略。Chen et al. (2021)的工作表明,transformers 可以通過(guò)模仿學(xué)習(xí)從離線 RL 數(shù)據(jù)中學(xué)習(xí)單任務(wù)策略,隨后的工作表明 transformers 可以在同領(lǐng)域和跨領(lǐng)域設(shè)置中提取多任務(wù)策略。這些工作都展示了提取通用多任務(wù)策略的范式,即首先收集大規(guī)模和多樣化的環(huán)境交互數(shù)據(jù)集,然后通過(guò)順序建模從數(shù)據(jù)中提取策略。這類(lèi)通過(guò)模仿學(xué)習(xí)從離線 RL 數(shù)據(jù)中學(xué)習(xí)策略的方法被稱(chēng)為離線策略蒸餾(Offline Policy Distillation)或策略蒸餾(Policy Distillation, PD)。
PD 具有簡(jiǎn)單性和可擴(kuò)展性,但它的一大缺點(diǎn)是生成的策略不會(huì)在與環(huán)境的額外交互中逐步改進(jìn)。舉例而言,谷歌的通才智能體 Multi-Game Decision Transformers 學(xué)習(xí)了一個(gè)可以玩很多 Atari 游戲的返回條件式(return-conditioned)策略,而 DeepMind 的通才智能體 Gato 通過(guò)上下文任務(wù)推理來(lái)學(xué)習(xí)一個(gè)解決多樣化環(huán)境中任務(wù)的策略。遺憾的是,這兩個(gè)智能體都不能通過(guò)試錯(cuò)來(lái)提升上下文中的策略。因此 PD 方法學(xué)習(xí)的是策略而不是強(qiáng)化學(xué)習(xí)算法。
在近日 DeepMind 的一篇論文中,研究者假設(shè) PD 沒(méi)能通過(guò)試錯(cuò)得到改進(jìn)的原因是它訓(xùn)練用的數(shù)據(jù)無(wú)法顯示學(xué)習(xí)進(jìn)度。當(dāng)前方法要么從不含學(xué)習(xí)的數(shù)據(jù)中學(xué)習(xí)策略(例如通過(guò)蒸餾固定專(zhuān)家策略),要么從包含學(xué)習(xí)的數(shù)據(jù)中學(xué)習(xí)策略(例如 RL 智能體的重放緩沖區(qū)),但后者的上下文大小(太小)無(wú)法捕獲策略改進(jìn)。

研究者的主要觀察結(jié)果是,RL 算法訓(xùn)練中學(xué)習(xí)的順序性在原則上可以將強(qiáng)化學(xué)習(xí)本身建模為一個(gè)因果序列預(yù)測(cè)問(wèn)題。具體地,如果一個(gè) transformer 的上下文足夠長(zhǎng),包含了由學(xué)習(xí)更新帶來(lái)的策略改進(jìn),那么它不僅應(yīng)該可以表示一個(gè)固定策略,而且能夠通過(guò)關(guān)注之前 episodes 的狀態(tài)、動(dòng)作和獎(jiǎng)勵(lì)來(lái)表示一個(gè)策略改進(jìn)算子。這樣開(kāi)啟了一種可能性,即任何 RL 算法都可以通過(guò)模仿學(xué)習(xí)蒸餾成足夠強(qiáng)大的序列模型如 transformer,并將這些模型轉(zhuǎn)換為上下文 RL 算法。
研究者提出了算法蒸餾(Algorithm Distillation, AD),這是一種通過(guò)優(yōu)化 RL 算法學(xué)習(xí)歷史中因果序列預(yù)測(cè)損失來(lái)學(xué)習(xí)上下文策略改進(jìn)算子的方法。如下圖 1 所示,AD 由兩部分組成。首先通過(guò)保存 RL 算法在大量單獨(dú)任務(wù)上的訓(xùn)練歷史來(lái)生成大型多任務(wù)數(shù)據(jù)集,然后 transformer 模型通過(guò)將前面的學(xué)習(xí)歷史用作其上下文來(lái)對(duì)動(dòng)作進(jìn)行因果建模。由于策略在源 RL 算法的訓(xùn)練過(guò)程中持續(xù)改進(jìn),因此 AD 不得不學(xué)習(xí)改進(jìn)算子以便準(zhǔn)確地建模訓(xùn)練歷史中任何給定點(diǎn)的動(dòng)作。至關(guān)重要的一點(diǎn)是,transformer 上下文必須足夠大(即 across-episodic)才能捕獲訓(xùn)練數(shù)據(jù)的改進(jìn)。
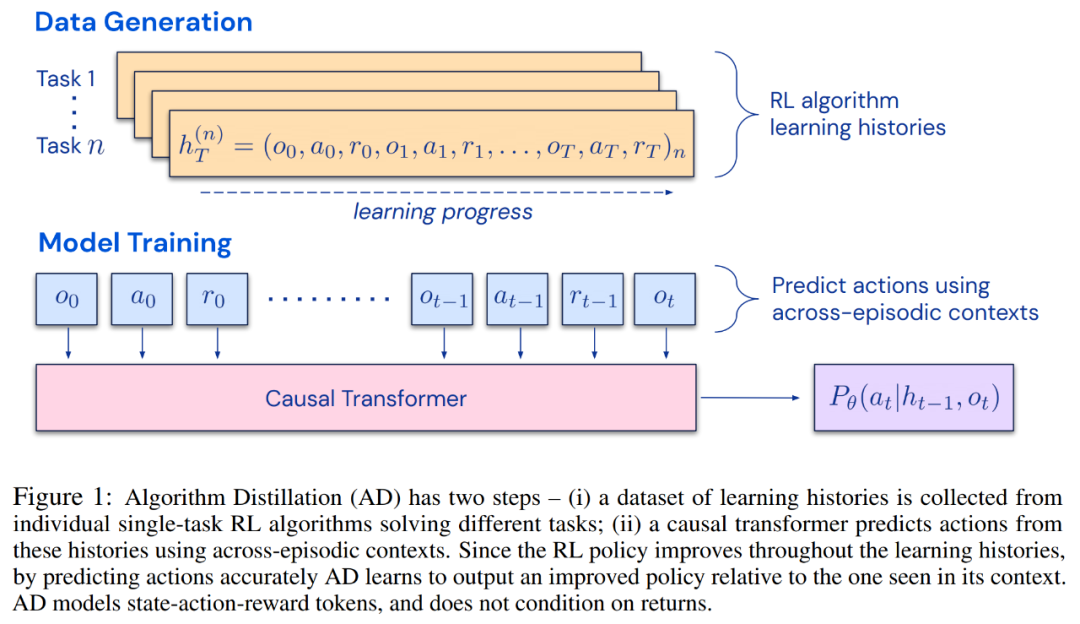
研究者表示,通過(guò)使用足夠大上下文的因果 transformer 來(lái)模仿基于梯度的 RL 算法,AD 完全可以在上下文中強(qiáng)化新任務(wù)學(xué)習(xí)。研究者在很多需要探索的部分可觀察環(huán)境中評(píng)估了 AD,包括來(lái)自 DMLab 的基于像素的 Watermaze,結(jié)果表明 AD 能夠進(jìn)行上下文探索、時(shí)序信度分配和泛化。此外,AD 學(xué)習(xí)到的算法比生成 transformer 訓(xùn)練源數(shù)據(jù)的算法更加高效。
6. AI繪畫(huà)逆著玩火了,敢不敢發(fā)自拍看AI如何用文字形容你?
原文:
https://mp.weixin.qq.com/s/TlzktHflCHHmuXDRy4uPgg
笑不活了家人們,最近突然流行起一個(gè)新玩法:給AI發(fā)自拍,看AI如何描述你。
比如這位勇敢曬出自拍的紐約大學(xué)助理教授,他的笑容在AI看來(lái)居然是“獸人式微笑”。
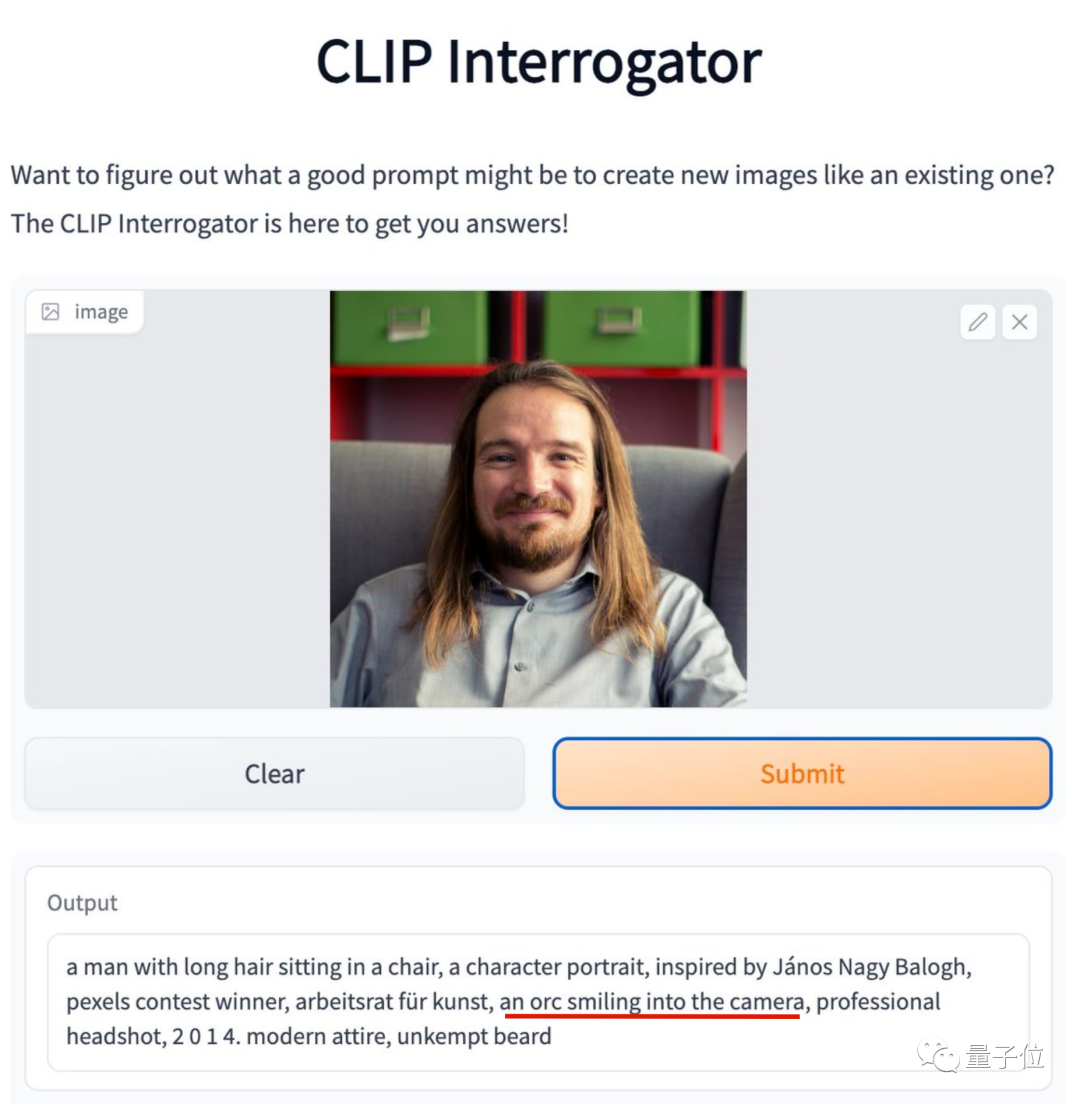
AI還吐槽他胡子沒(méi)有打理,但他表示拍照那天胡子要比平常整齊多了。

在評(píng)論區(qū)里還有一位也被評(píng)價(jià)為獸人微笑的網(wǎng)友現(xiàn)身。兩位“部落勇士”就這樣賽博認(rèn)了個(gè)親。
上面這個(gè)玩法,相當(dāng)于把最近火爆的AI繪畫(huà)逆過(guò)來(lái)玩,輸入圖片輸出文字描述。
負(fù)責(zé)文字描述的正是大名鼎鼎的CLIP,也就是DALL·E、Stable Diffusion等AI繪畫(huà)模型中負(fù)責(zé)理解語(yǔ)言的那部分。
目前這個(gè)CLIP Interrogator(CLIP審問(wèn)官),在HuggingFace上已有現(xiàn)成的Demo可玩。

7. 《YOLOv5全面解析教程》一,網(wǎng)絡(luò)結(jié)構(gòu)逐行代碼解析
原文:
https://mp.weixin.qq.com/s/qR2ODIMidsNR_Eznxry5pg
YOLOv5 網(wǎng)絡(luò)結(jié)構(gòu)解析
引言
YOLOv5針對(duì)不同大小(n, s, m, l, x)的網(wǎng)絡(luò)整體架構(gòu)都是一樣的,只不過(guò)會(huì)在每個(gè)子模塊中采用不同的深度和寬度,
分別應(yīng)對(duì)yaml文件中的depth_multiple和width_multiple參數(shù)。
還需要注意一點(diǎn),官方除了n, s, m, l, x版本外還有n6, s6, m6, l6, x6,區(qū)別在于后者是針對(duì)更大分辨率的圖片比如1280x1280,
當(dāng)然結(jié)構(gòu)上也有些差異,前者只會(huì)下采樣到32倍且采用3個(gè)預(yù)測(cè)特征層 , 而后者會(huì)下采樣64倍,采用4個(gè)預(yù)測(cè)特征層。
本章將以 yolov5s為例 ,從配置文件 models/yolov5s.yaml(https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolov5s.yaml) 到 models/yolo.py(https://github.com/Oneflow-Inc/one-yolov5/blob/main/models/yolo.py) 源碼進(jìn)行解讀。
yolov5s.yaml文件內(nèi)容:
1nc:80#numberofclasses數(shù)據(jù)集中的類(lèi)別數(shù)
2depth_multiple:0.33#modeldepthmultiple模型層數(shù)因子(用來(lái)調(diào)整網(wǎng)絡(luò)的深度)
3width_multiple:0.50#layerchannelmultiple模型通道數(shù)因子(用來(lái)調(diào)整網(wǎng)絡(luò)的寬度)
4#如何理解這個(gè)depth_multiple和width_multiple呢?它決定的是整個(gè)模型中的深度(層數(shù))和寬度(通道數(shù)),具體怎么調(diào)整的結(jié)合后面的backbone代碼解釋。
5
6anchors:#表示作用于當(dāng)前特征圖的Anchor大小為xxx
7#9個(gè)anchor,其中P表示特征圖的層級(jí),P3/8該層特征圖縮放為1/8,是第3層特征
8-[10,13,16,30,33,23]#P3/8,表示[10,13],[16,30],[33,23]3個(gè)anchor
9-[30,61,62,45,59,119]#P4/16
10-[116,90,156,198,373,326]#P5/32
11
12
13#YOLOv5sv6.0backbone
14backbone:
15#[from,number,module,args]
16[[-1,1,Conv,[64,6,2,2]],#0-P1/2
17[-1,1,Conv,[128,3,2]],#1-P2/4
18[-1,3,C3,[128]],
19[-1,1,Conv,[256,3,2]],#3-P3/8
20[-1,6,C3,[256]],
21[-1,1,Conv,[512,3,2]],#5-P4/16
22[-1,9,C3,[512]],
23[-1,1,Conv,[1024,3,2]],#7-P5/32
24[-1,3,C3,[1024]],
25[-1,1,SPPF,[1024,5]],#9
26]
27
28#YOLOv5sv6.0head
29head:
30[[-1,1,Conv,[512,1,1]],
31[-1,1,nn.Upsample,[None,2,'nearest']],
32[[-1,6],1,Concat,[1]],#catbackboneP4
33[-1,3,C3,[512,False]],#13
34
35[-1,1,Conv,[256,1,1]],
36[-1,1,nn.Upsample,[None,2,'nearest']],
37[[-1,4],1,Concat,[1]],#catbackboneP3
38[-1,3,C3,[256,False]],#17(P3/8-small)
39
40[-1,1,Conv,[256,3,2]],
41[[-1,14],1,Concat,[1]],#catheadP4
42[-1,3,C3,[512,False]],#20(P4/16-medium)
43
44[-1,1,Conv,[512,3,2]],
45[[-1,10],1,Concat,[1]],#catheadP5
46[-1,3,C3,[1024,False]],#23(P5/32-large)
47
48[[17,20,23],1,Detect,[nc,anchors]],#Detect(P3,P4,P5)
49]
anchors 解讀
yolov5 初始化了 9 個(gè) anchors,分別在三個(gè)特征圖 (feature map)中使用,每個(gè) feature map 的每個(gè) grid cell 都有三個(gè) anchor 進(jìn)行預(yù)測(cè)。分配規(guī)則:
-
尺度越大的 feature map 越靠前,相對(duì)原圖的下采樣率越小,感受野越小, 所以相對(duì)可以預(yù)測(cè)一些尺度比較小的物體(小目標(biāo)),分配到的 anchors 越小。
-
尺度越小的 feature map 越靠后,相對(duì)原圖的下采樣率越大,感受野越大, 所以可以預(yù)測(cè)一些尺度比較大的物體(大目標(biāo)),所以分配到的 anchors 越大。
-
即在小特征圖(feature map)上檢測(cè)大目標(biāo),中等大小的特征圖上檢測(cè)中等目標(biāo), 在大特征圖上檢測(cè)小目標(biāo)。
backbone & head解讀
[from, number, module, args] 參數(shù)
四個(gè)參數(shù)的意義分別是:
1、第一個(gè)參數(shù) from :從哪一層獲得輸入,-1表示從上一層獲得,[-1, 6]表示從上層和第6層兩層獲得。
2、第二個(gè)參數(shù) number:表示有幾個(gè)相同的模塊,如果為9則表示有9個(gè)相同的模塊。
3、第三個(gè)參數(shù) module:模塊的名稱(chēng),這些模塊寫(xiě)在common.py中。
4、第四個(gè)參數(shù) args:類(lèi)的初始化參數(shù),用于解析作為 moudle 的傳入?yún)?shù)。
下面以第一個(gè)模塊Conv 為例介紹下common.py中的模塊
更多的內(nèi)容請(qǐng)點(diǎn)擊原文查看.
8. LeCun轉(zhuǎn)推,PyTorch GPU內(nèi)存分配有了火焰圖可視化工具
原文:
https://mp.weixin.qq.com/s/_ChQM04s0900BDWhSBtwvg
近日,PyTorch 核心開(kāi)發(fā)者和 FAIR 研究者 Zachary DeVito 創(chuàng)建了一個(gè)新工具(添加實(shí)驗(yàn)性 API),通過(guò)生成和可視化內(nèi)存快照(memory snapshot)來(lái)可視化 GPU 內(nèi)存的分配狀態(tài)。這些內(nèi)存快照記錄了內(nèi)存分配的堆棧跟蹤以及內(nèi)存在緩存分配器狀態(tài)中的位置。
接下來(lái),通過(guò)將這些內(nèi)存快照可視化為火焰圖(flamegraphs),內(nèi)存的使用位置也就能一目了然地看到了。
圖靈獎(jiǎng)得主 Yann Lecun 也轉(zhuǎn)推了這個(gè)工具。

下面我們來(lái)看這個(gè)工具的實(shí)現(xiàn)原理(以第一人稱(chēng)「我們」描述)。
可視化快照
_memory_viz.py 工具也可以生成內(nèi)存的可視化火焰圖。

可視化圖將分配器中所有的字節(jié)(byte)按不同的類(lèi)來(lái)分割成段,如下圖所示(原文為可交互視圖)。
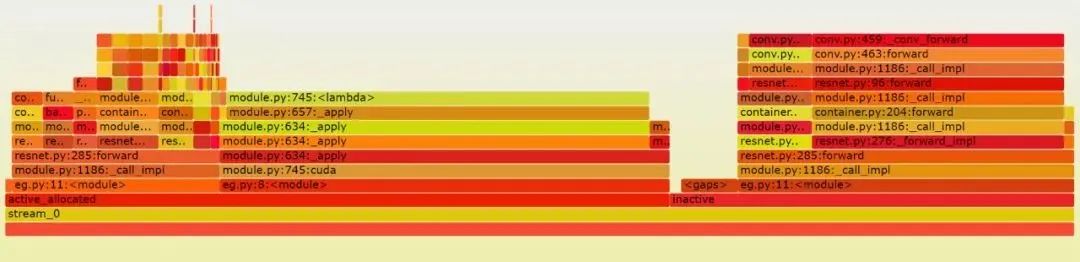
火焰圖可視化是一種將資源(如內(nèi)存)使用劃分為不同類(lèi)的方法,然后可以進(jìn)一步細(xì)分為更細(xì)粒度的類(lèi)別。
memory 視圖很好地展現(xiàn)了內(nèi)存的使用方式。但對(duì)于具體地調(diào)試分配器問(wèn)題,首先將內(nèi)存分類(lèi)為不同的 Segment 對(duì)象是有用的,而這些對(duì)象是分配軌跡的單個(gè) cudaMalloc 段。
更多的使用方法,請(qǐng)參考原文!
END

原文標(biāo)題:【AI簡(jiǎn)報(bào)20221028】 vivo公布自研芯片、AR-HUD處于爆發(fā)前夜
文章出處:【微信公眾號(hào):RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
-
RT-Thread
+關(guān)注
關(guān)注
32文章
1370瀏覽量
41519
原文標(biāo)題:【AI簡(jiǎn)報(bào)20221028】 vivo公布自研芯片、AR-HUD處于爆發(fā)前夜
文章出處:【微信號(hào):RTThread,微信公眾號(hào):RTThread物聯(lián)網(wǎng)操作系統(tǒng)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
華為加持,汽車(chē)AR-HUD跑出“加速度”!哪些供應(yīng)商值得關(guān)注?

深耕AR-HUD賽道!經(jīng)緯恒潤(rùn)市占率躋身前五

?貼片電容微型化對(duì)AR-HUD光學(xué)模組高頻濾波的影響研究
疆程技術(shù)推出LCoS AR-HUD解決方案
AR-HUD軟硬協(xié)同創(chuàng)新獲多家頭部車(chē)企青睞,多維技術(shù)創(chuàng)新定義人機(jī)交互新范式
今日看點(diǎn)丨小鵬自研芯片或5月上車(chē);安森美將在重組期間裁員2400人
傳DeepSeek自研芯片,廠商們要把AI成本打下來(lái)
OpenAI自研AI芯片即將進(jìn)入試生產(chǎn)階段
華陽(yáng)景深式3D AR-HUD首發(fā)CES 2025

AR-HUD再突破!蔚來(lái)ET9首發(fā)搭載“共軸光場(chǎng)”AR-HUD
德賽西威HUD技術(shù)日活動(dòng)圓滿落幕
比亞迪最快于11月實(shí)現(xiàn)自研算法量產(chǎn),推進(jìn)智駕芯片自研進(jìn)程
設(shè)計(jì)仿真 基于VTD的AR-HUD仿真測(cè)試解決方案

經(jīng)緯恒潤(rùn)AR HUD市占率躋身前五!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論