") 無需權(quán)重更新、微調(diào),Transformer在試錯(cuò)中自主改進(jìn)!
無需權(quán)重更新、微調(diào),Transformer在試錯(cuò)中自主改進(jìn)!
DeepMind 表示,他們提出的算法蒸餾(AD)是首個(gè)通過對(duì)具有模仿?lián)p失的離線數(shù)據(jù)進(jìn)行順序建模以展示上下文強(qiáng)化學(xué)習(xí)的方法。同時(shí)基于觀察結(jié)果開啟了一種可能,即任何 RL 算法都可以通過模仿學(xué)習(xí)蒸餾成足夠強(qiáng)大的序列模型如 transformer,并將這些模型轉(zhuǎn)換為上下文 RL 算法。
目前,Transformers 已經(jīng)成為序列建模的強(qiáng)大神經(jīng)網(wǎng)絡(luò)架構(gòu)。預(yù)訓(xùn)練 transformer 的一個(gè)顯著特性是它們有能力通過提示 conditioning 或上下文學(xué)習(xí)來適應(yīng)下游任務(wù)。經(jīng)過大型離線數(shù)據(jù)集上的預(yù)訓(xùn)練之后,大規(guī)模 transformers 已被證明可以高效地泛化到文本補(bǔ)全、語言理解和圖像生成方面的下游任務(wù)。
最近的工作表明,transformers 還可以通過將離線強(qiáng)化學(xué)習(xí)(RL)視作順序預(yù)測問題,進(jìn)而從離線數(shù)據(jù)中學(xué)習(xí)策略。Chen et al. (2021)的工作表明,transformers 可以通過模仿學(xué)習(xí)從離線 RL 數(shù)據(jù)中學(xué)習(xí)單任務(wù)策略,隨后的工作表明 transformers 可以在同領(lǐng)域和跨領(lǐng)域設(shè)置中提取多任務(wù)策略。這些工作都展示了提取通用多任務(wù)策略的范式,即首先收集大規(guī)模和多樣化的環(huán)境交互數(shù)據(jù)集,然后通過順序建模從數(shù)據(jù)中提取策略。這類通過模仿學(xué)習(xí)從離線 RL 數(shù)據(jù)中學(xué)習(xí)策略的方法被稱為離線策略蒸餾(Offline Policy Distillation)或策略蒸餾(Policy Distillation, PD)。
PD 具有簡單性和可擴(kuò)展性,但它的一大缺點(diǎn)是生成的策略不會(huì)在與環(huán)境的額外交互中逐步改進(jìn)。舉例而言,谷歌的通才智能體 Multi-Game Decision Transformers 學(xué)習(xí)了一個(gè)可以玩很多 Atari 游戲的返回條件式(return-conditioned)策略,而 DeepMind 的通才智能體 Gato 通過上下文任務(wù)推理來學(xué)習(xí)一個(gè)解決多樣化環(huán)境中任務(wù)的策略。遺憾的是,這兩個(gè)智能體都不能通過試錯(cuò)來提升上下文中的策略。因此 PD 方法學(xué)習(xí)的是策略而不是強(qiáng)化學(xué)習(xí)算法。
在近日 DeepMind 的一篇論文中,研究者假設(shè) PD 沒能通過試錯(cuò)得到改進(jìn)的原因是它訓(xùn)練用的數(shù)據(jù)無法顯示學(xué)習(xí)進(jìn)度。當(dāng)前方法要么從不含學(xué)習(xí)的數(shù)據(jù)中學(xué)習(xí)策略(例如通過蒸餾固定專家策略),要么從包含學(xué)習(xí)的數(shù)據(jù)中學(xué)習(xí)策略(例如 RL 智能體的重放緩沖區(qū)),但后者的上下文大小(太小)無法捕獲策略改進(jìn)。

論文地址:https://arxiv.org/pdf/2210.14215.pdf
研究者的主要觀察結(jié)果是,RL 算法訓(xùn)練中學(xué)習(xí)的順序性在原則上可以將強(qiáng)化學(xué)習(xí)本身建模為一個(gè)因果序列預(yù)測問題。具體地,如果一個(gè) transformer 的上下文足夠長,包含了由學(xué)習(xí)更新帶來的策略改進(jìn),那么它不僅應(yīng)該可以表示一個(gè)固定策略,而且能夠通過關(guān)注之前 episodes 的狀態(tài)、動(dòng)作和獎(jiǎng)勵(lì)來表示一個(gè)策略改進(jìn)算子。這樣開啟了一種可能性,即任何 RL 算法都可以通過模仿學(xué)習(xí)蒸餾成足夠強(qiáng)大的序列模型如 transformer,并將這些模型轉(zhuǎn)換為上下文 RL 算法。
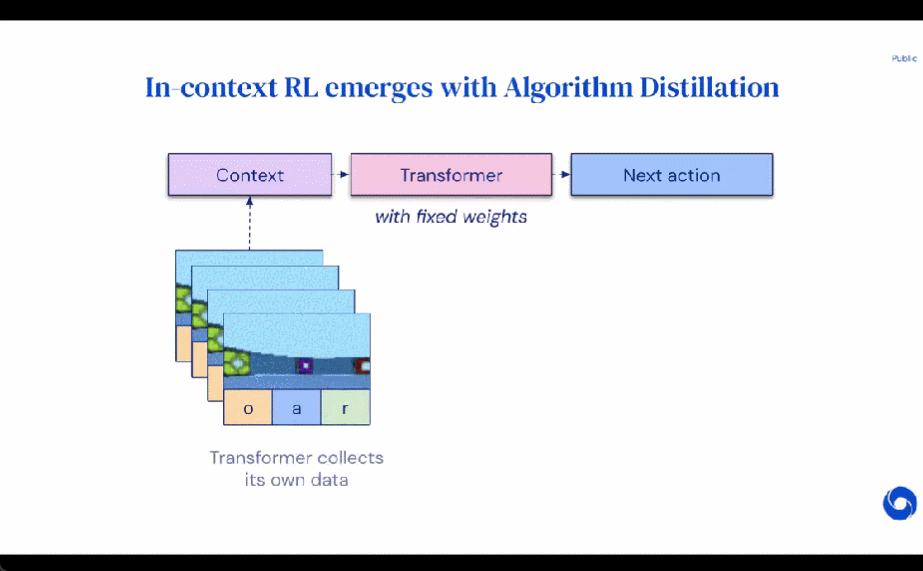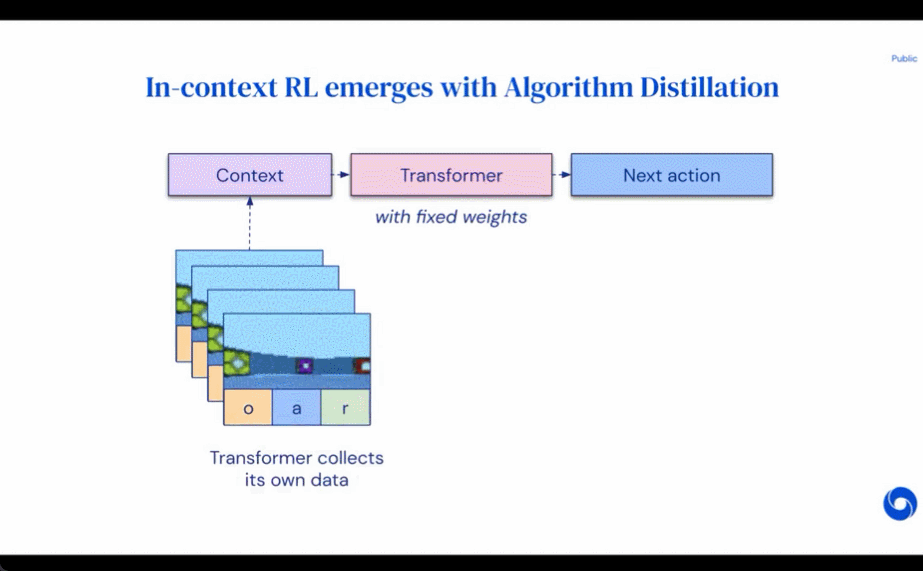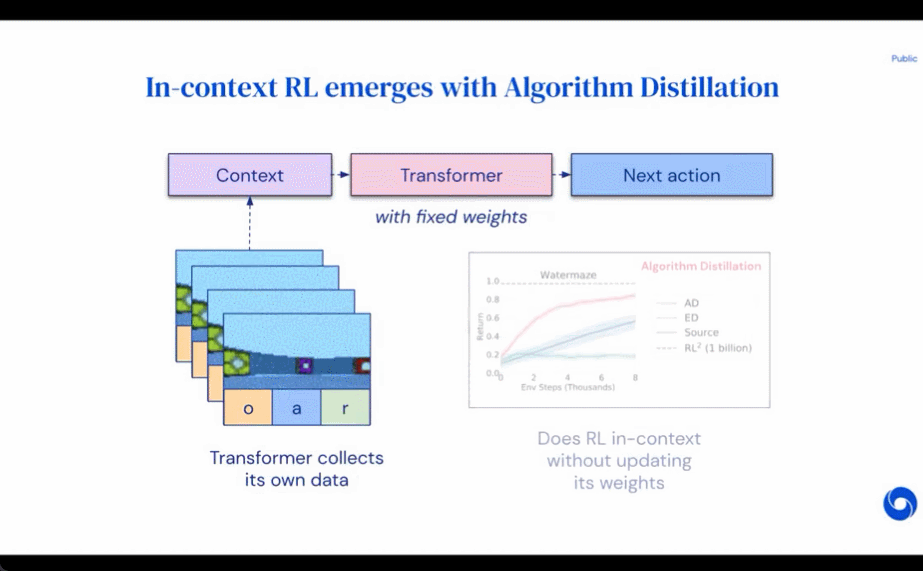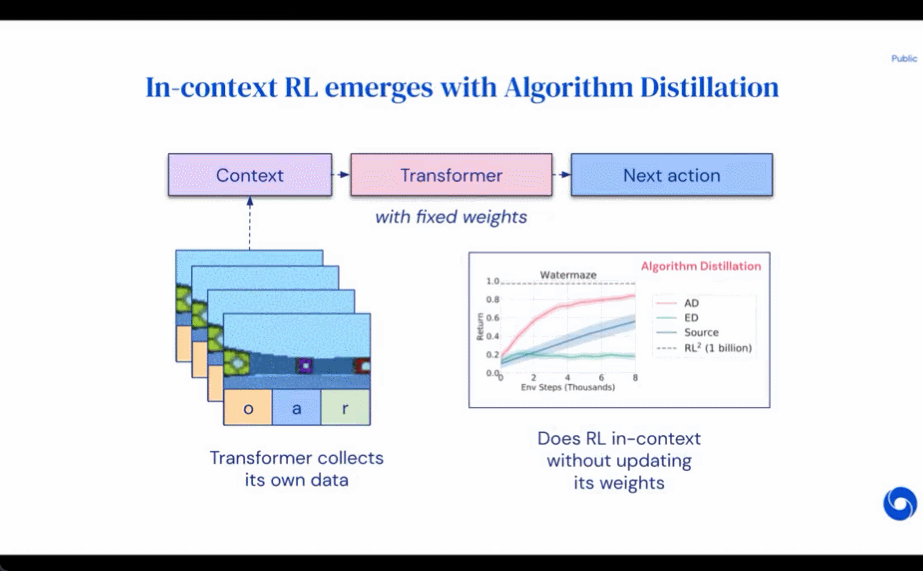
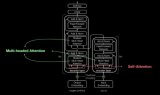
研究者提出了算法蒸餾(Algorithm Distillation, AD),這是一種通過優(yōu)化 RL 算法學(xué)習(xí)歷史中因果序列預(yù)測損失來學(xué)習(xí)上下文策略改進(jìn)算子的方法。如下圖 1 所示,AD 由兩部分組成。首先通過保存 RL 算法在大量單獨(dú)任務(wù)上的訓(xùn)練歷史來生成大型多任務(wù)數(shù)據(jù)集,然后 transformer 模型通過將前面的學(xué)習(xí)歷史用作其上下文來對(duì)動(dòng)作進(jìn)行因果建模。由于策略在源 RL 算法的訓(xùn)練過程中持續(xù)改進(jìn),因此 AD 不得不學(xué)習(xí)改進(jìn)算子以便準(zhǔn)確地建模訓(xùn)練歷史中任何給定點(diǎn)的動(dòng)作。至關(guān)重要的一點(diǎn)是,transformer 上下文必須足夠大(即 across-episodic)才能捕獲訓(xùn)練數(shù)據(jù)的改進(jìn)。
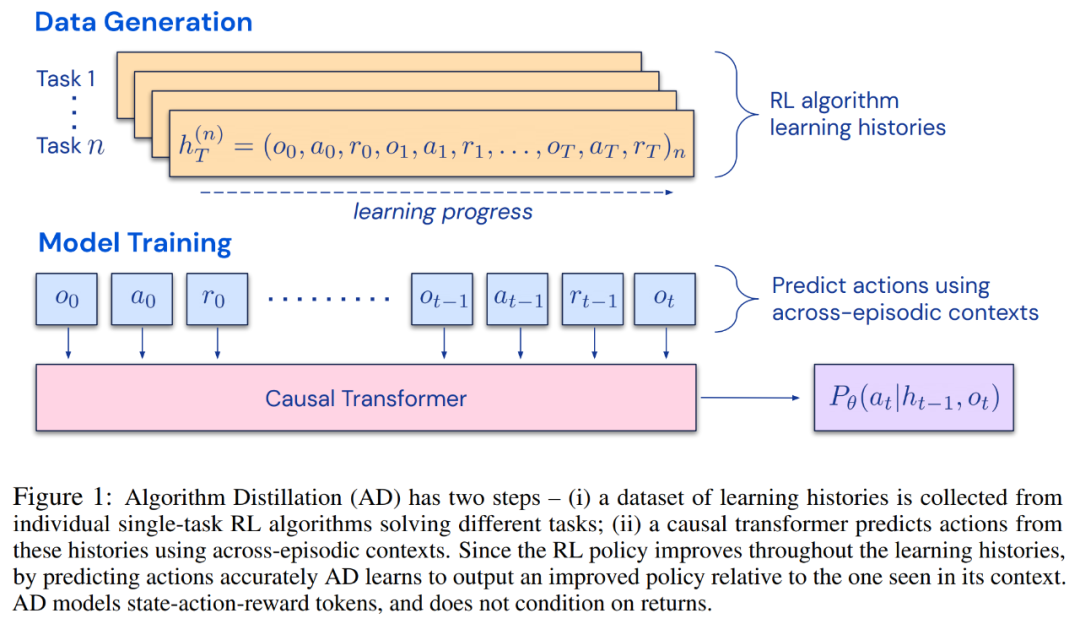
研究者表示,通過使用足夠大上下文的因果 transformer 來模仿基于梯度的 RL 算法,AD 完全可以在上下文中強(qiáng)化新任務(wù)學(xué)習(xí)。研究者在很多需要探索的部分可觀察環(huán)境中評(píng)估了 AD,包括來自 DMLab 的基于像素的 Watermaze,結(jié)果表明 AD 能夠進(jìn)行上下文探索、時(shí)序信度分配和泛化。此外,AD 學(xué)習(xí)到的算法比生成 transformer 訓(xùn)練源數(shù)據(jù)的算法更加高效。
最后值得關(guān)注的是,AD 是首個(gè)通過對(duì)具有模仿?lián)p失的離線數(shù)據(jù)進(jìn)行順序建模以展示上下文強(qiáng)化學(xué)習(xí)的方法。
方法
在生命周期內(nèi),強(qiáng)化學(xué)習(xí)智能體需要在執(zhí)行復(fù)雜的動(dòng)作方面表現(xiàn)良好。對(duì)智能體而言,不管它所處的環(huán)境、內(nèi)部結(jié)構(gòu)和執(zhí)行情況如何,都可以被視為是在過去經(jīng)驗(yàn)的基礎(chǔ)上完成的。可用如下形式表示:
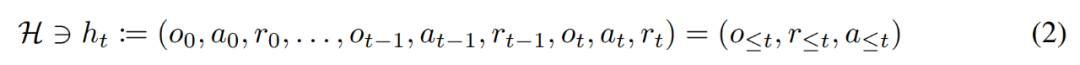
研究者同時(shí)將「長期歷史條件, long history-conditioned」策略看作一種算法,得出:

其中?(A)表示動(dòng)作空間 A 上的概率分布空間。公式 (3) 表明,該算法可以在環(huán)境中展開,以生成觀察、獎(jiǎng)勵(lì)和動(dòng)作序列。為了簡單起見,該研究將算法用 P 表示,將環(huán)境(即任務(wù))用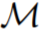 的學(xué)習(xí)歷史都是由算法表示,這樣對(duì)于任何給定任務(wù)
的學(xué)習(xí)歷史都是由算法表示,這樣對(duì)于任何給定任務(wù) 生成的。可以得到
生成的。可以得到
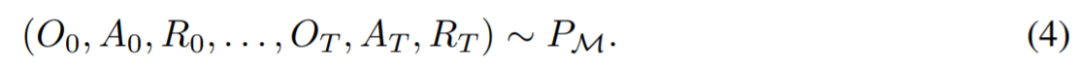
研究者用大寫拉丁字母表示隨機(jī)變量,例如 O、A、R 及其對(duì)應(yīng)的小寫形式 o,α,r。通過將算法視為長期歷史條件策略,他們假設(shè)任何生成學(xué)習(xí)歷史的算法都可以通過對(duì)動(dòng)作執(zhí)行行為克隆來轉(zhuǎn)換成神經(jīng)網(wǎng)絡(luò)。接下來,該研究提出了一種方法,該方法提供了智能體在生命周期內(nèi)學(xué)習(xí)具有行為克隆的序列模型,以將長期歷史映射到動(dòng)作分布。
實(shí)際執(zhí)行
在實(shí)踐中,該研究將算法蒸餾過程 ( algorithm distillation ,AD)實(shí)現(xiàn)為一個(gè)兩步過程。首先,通過在許多不同的任務(wù)上運(yùn)行單獨(dú)的基于梯度的 RL 算法來收集學(xué)習(xí)歷史數(shù)據(jù)集。接下來,訓(xùn)練具有多情節(jié)上下文的序列模型來預(yù)測歷史中的動(dòng)作。具體算法如下所示:

實(shí)驗(yàn)
實(shí)驗(yàn)要求所使用的環(huán)境都支持許多任務(wù),而這些任務(wù)不能從觀察中輕易的進(jìn)行推斷,并且情節(jié)(episodes)足夠短,可以有效地訓(xùn)練跨情節(jié)因果 transformers。這項(xiàng)工作的主要目的是調(diào)查相對(duì)于先前工作,AD 強(qiáng)化在多大程度上是在上下文中學(xué)習(xí)的。實(shí)驗(yàn)將 AD、 ED( Expert Distillation) 、RL^2 等進(jìn)行了比較。
評(píng)估 AD、ED、 RL^2 結(jié)果如圖 3 所示。該研究發(fā)現(xiàn) AD 和 RL^2 都可以在上下文中學(xué)習(xí)從訓(xùn)練分布中采樣的任務(wù),而 ED 則不能,盡管 ED 在分布內(nèi)評(píng)估時(shí)確實(shí)比隨機(jī)猜測做得更好。
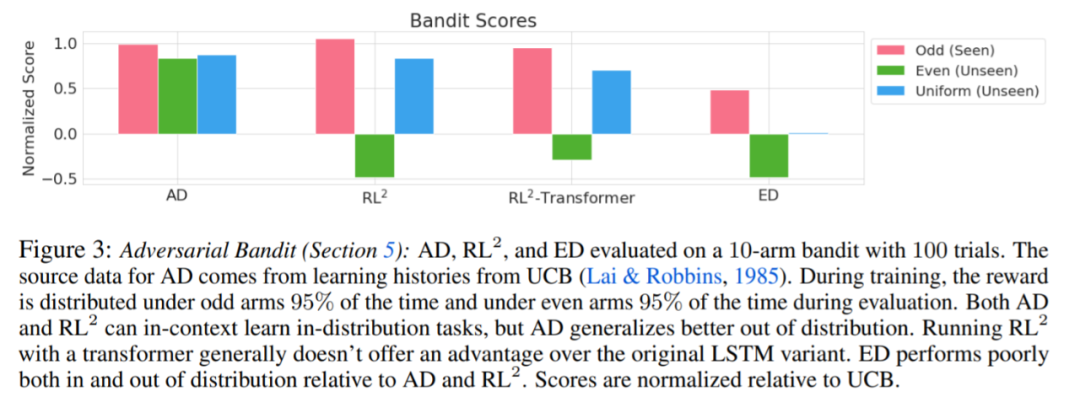
圍繞下圖 4,研究者回答了一系列問題。AD 是否表現(xiàn)出上下文強(qiáng)化學(xué)習(xí)?結(jié)果表明 AD 上下文強(qiáng)化學(xué)習(xí)在所有環(huán)境中都能學(xué)習(xí),相比之下,ED 在大多數(shù)情況下都無法在上下文中探索和學(xué)習(xí)。
AD 能從基于像素的觀察中學(xué)習(xí)嗎?結(jié)果表明 AD 通過上下文 RL 最大化了情景回歸,而 ED 則不能學(xué)習(xí)。
AD 是否可以學(xué)習(xí)一種比生成源數(shù)據(jù)的算法更有效的 RL 算法?結(jié)果表明 AD 的數(shù)據(jù)效率明顯高于源算法(A3C 和 DQN)。
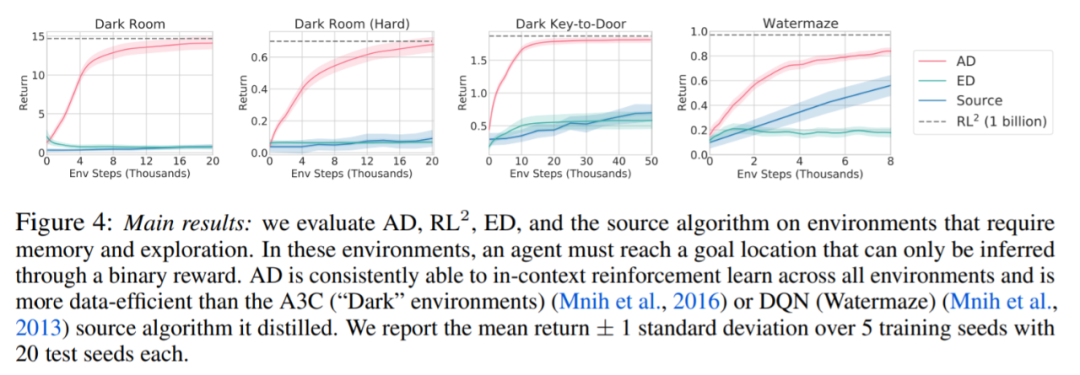
是否可以通過演示來加速 AD?為了回答這個(gè)問題,該研究保留測試集數(shù)據(jù)中沿源算法歷史的不同點(diǎn)采樣策略,然后,使用此策略數(shù)據(jù)預(yù)先填充 AD 和 ED 的上下文,并在 Dark Room 的環(huán)境中運(yùn)行這兩種方法,將結(jié)果繪制在圖 5 中。雖然 ED 保持了輸入策略的性能,AD 在上下文中改進(jìn)每個(gè)策略,直到它接近最優(yōu)。重要的是,輸入策略越優(yōu)化,AD 改進(jìn)它的速度就越快,直到達(dá)到最優(yōu)。
審核編輯 :李倩
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4806瀏覽量
102688 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1222瀏覽量
25264 -
DeepMind
+關(guān)注
關(guān)注
0文章
131瀏覽量
11343
原文標(biāo)題:DeepMind新作!無需權(quán)重更新、微調(diào),Transformer在試錯(cuò)中自主改進(jìn)!
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
如何使用MATLAB構(gòu)建Transformer模型

【「基于大模型的RAG應(yīng)用開發(fā)與優(yōu)化」閱讀體驗(yàn)】+大模型微調(diào)技術(shù)解讀
transformer專用ASIC芯片Sohu說明

Transformer模型的具體應(yīng)用

自動(dòng)駕駛中一直說的BEV+Transformer到底是個(gè)啥?

在高速ADC中通過校準(zhǔn)改進(jìn)SFDR






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論