") 給一個(gè)文本提示就能生成3D模型!
給一個(gè)文本提示就能生成3D模型!
【導(dǎo)讀】給一個(gè)文本提示就能生成3D模型!
自從文本引導(dǎo)的圖像生成模型火了以后,畫家群體迅速擴(kuò)張,不會(huì)用畫筆的人也能發(fā)揮想象力進(jìn)行藝術(shù)創(chuàng)作。
但目前的模型,如DALL-E 2, Imagen等仍然停留在二維創(chuàng)作(即圖片),無法生成360度無死角的3D模型。
想要直接訓(xùn)練一個(gè)text-to-3D的模型非常困難,因?yàn)镈ALL-E 2等模型的訓(xùn)練需要吞噬數(shù)十億個(gè)圖像-文本對(duì),但三維合成并不存在如此大規(guī)模的標(biāo)注數(shù)據(jù),也沒有一個(gè)高效的模型架構(gòu)對(duì)3D數(shù)據(jù)進(jìn)行降噪。

最近Google研究員另辟蹊徑,提出一個(gè)新模型DreamFusion,先使用一個(gè)預(yù)訓(xùn)練2D擴(kuò)散模型基于文本提示生成一張二維圖像,然后引入一個(gè)基于概率密度蒸餾的損失函數(shù),通過梯度下降法優(yōu)化一個(gè)隨機(jī)初始化的神經(jīng)輻射場NeRF模型。

論文鏈接:https://arxiv.org/abs/2209.14988
訓(xùn)練后的模型可以在任意角度、任意光照條件、任意三維環(huán)境中基于給定的文本提示生成模型,整個(gè)過程既不需要3D訓(xùn)練數(shù)據(jù),也無需修改圖像擴(kuò)散模型,完全依賴預(yù)訓(xùn)練擴(kuò)散模型作為先驗(yàn)。
從文本到3D模型
以文本為條件的生成性圖像模型現(xiàn)在支持高保真、多樣化和可控的圖像合成,高質(zhì)量來源于大量對(duì)齊的圖像-文本數(shù)據(jù)集和可擴(kuò)展的生成模型架構(gòu),如擴(kuò)散模型。
雖然二維圖像生成的應(yīng)用場景十分廣泛,但諸如游戲、電影等數(shù)字媒體仍然需要成千上萬的詳細(xì)的三維資產(chǎn)來填充豐富的互動(dòng)環(huán)境。
目前,3D資產(chǎn)的獲取方式主要由Blender和Maya3D等建模軟件手工設(shè)計(jì),這個(gè)過程需要耗費(fèi)大量的時(shí)間和專業(yè)知識(shí)。
2020年,神經(jīng)輻射場(NeRF)模型發(fā)布,其中體積光線追蹤器與從空間坐標(biāo)到顏色和體積密度的神經(jīng)映射相結(jié)合,使得NeRF已經(jīng)成為神經(jīng)逆向渲染的一個(gè)重要工具。
最初,NeRF被發(fā)現(xiàn)可以很好地用于「經(jīng)典」的三維重建任務(wù):一個(gè)場景下的不同角度圖像提供給一個(gè)模型作為輸入,然后優(yōu)化NeRF以恢復(fù)該特定場景的幾何形狀,能夠從未觀察到的角度合成該場景的新視圖。
很多三維生成方法都是基于NeRF模型,比如2022年提出的Dream Fields使用預(yù)訓(xùn)練的CLIP模型和基于優(yōu)化的方法來訓(xùn)練NeRF,直接從文本中生成3D模型,但這種方式生成的三維物體往往缺乏真實(shí)性和準(zhǔn)確性。

DreamFusion采用了與Dream Field類似的方法,但模型中的損失函數(shù)基于概率密度蒸餾,最小化基于擴(kuò)散的前向過程的共享的高斯分布族與預(yù)訓(xùn)練的擴(kuò)散模型所學(xué)習(xí)的分?jǐn)?shù)函數(shù)之間的KL散度。
擴(kuò)散模型是一個(gè)隱變量生成模型,學(xué)習(xí)如何逐步將一個(gè)樣本從簡單的噪聲分布轉(zhuǎn)換到數(shù)據(jù)分布。
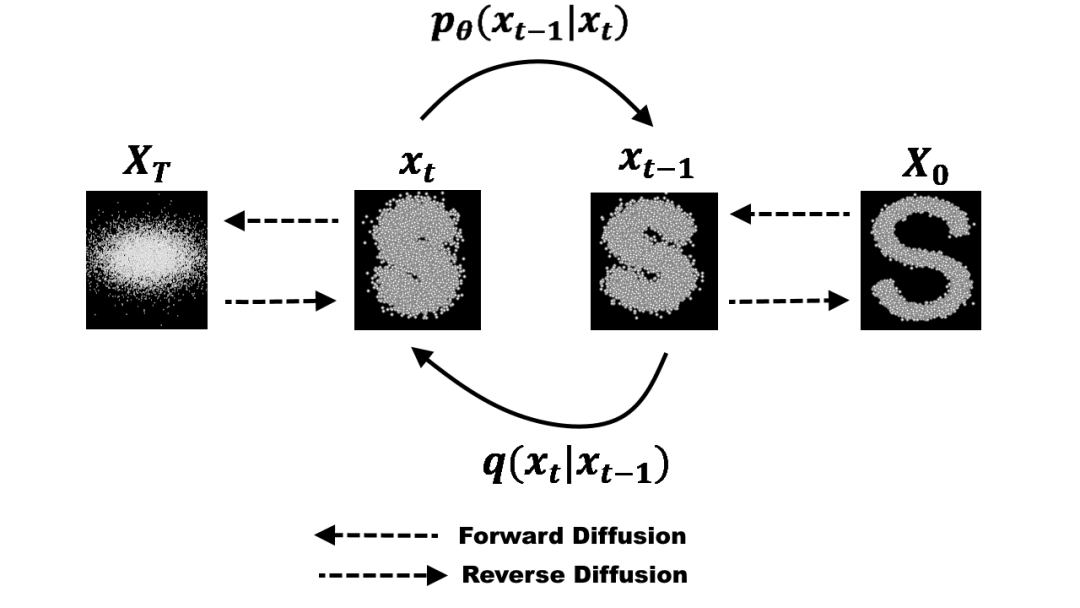
擴(kuò)散模型的包括一個(gè)前向過程(forward process),緩慢地從數(shù)據(jù)中添加噪聲并移除結(jié)構(gòu),兩個(gè)時(shí)間步之間的過渡通常服從高斯分布,并在反向過程(reverse process)或生成式模型中在噪聲上逐漸添加結(jié)構(gòu)。
現(xiàn)有的擴(kuò)散模型采樣方法產(chǎn)生的樣本與模型訓(xùn)練的觀測數(shù)據(jù)類型和維度相同,盡管有條件的擴(kuò)散采樣能夠?qū)崿F(xiàn)相當(dāng)大的靈活性,但在像素上訓(xùn)練的擴(kuò)散模型傳統(tǒng)上只用來對(duì)像素進(jìn)行采樣。
但像素采樣并不重要,研究人員只希望創(chuàng)建的三維模型在從隨機(jī)角度渲染時(shí),看起來像是一張好的圖像。
可微分圖像參數(shù)化(DIP)允許模型表達(dá)約束條件,在更緊湊的空間中進(jìn)行優(yōu)化(例如任意分辨率的基于坐標(biāo)的MLPs),或利用更強(qiáng)大的優(yōu)化算法來遍歷像素空間。
對(duì)于三維來說,參數(shù)θ是三維體積的參數(shù),可微生成器g是體積渲染器,為了學(xué)習(xí)這些參數(shù),需要一個(gè)可以應(yīng)用于擴(kuò)散模型的損失函數(shù)。
文中采用的方法是利用擴(kuò)散模型的結(jié)構(gòu),通過優(yōu)化實(shí)現(xiàn)可操作的取樣,當(dāng)損失函數(shù)最小化時(shí)生成一個(gè)樣本,然后對(duì)參數(shù)θ進(jìn)行優(yōu)化,使x=g(θ)看起來像凍結(jié)擴(kuò)散模型的樣本。
為了進(jìn)行這種優(yōu)化,還需要一個(gè)可微的損失函數(shù),其中可信的圖像具有較低的損失,而不可信的圖像有高的損失,與DeepDream的過程類似。
在實(shí)踐中,研究人員發(fā)現(xiàn)即使是在使用一個(gè)相同的DIP時(shí),損失函數(shù)也無法生成現(xiàn)實(shí)的樣本。但同期的一項(xiàng)工作表明,這種方法可以通過精心選擇的時(shí)間步長來實(shí)現(xiàn),但這個(gè)目標(biāo)很脆弱,其時(shí)間步長的調(diào)整也很困難。
通過觀察和分解梯度可以發(fā)現(xiàn),U-Net Jacobian項(xiàng)的計(jì)算成本很高(需要通過擴(kuò)散模型U-Net進(jìn)行反向傳播),而且對(duì)于小的噪聲水平來說條件很差,因?yàn)樗挠?xùn)練目標(biāo)為近似于邊際密度的縮放Hessian
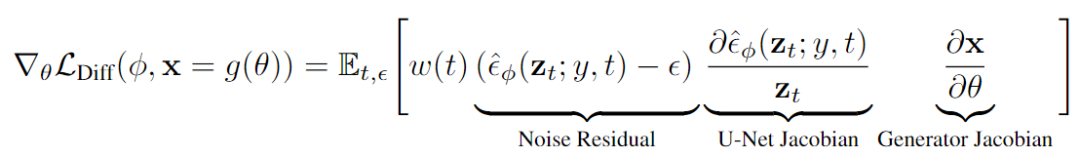
通過實(shí)驗(yàn),研究人員發(fā)現(xiàn)省略U-Net的Jacobian項(xiàng)可以帶來一個(gè)有效的梯度結(jié)果,能夠用于優(yōu)化帶有擴(kuò)散模型的DIPs
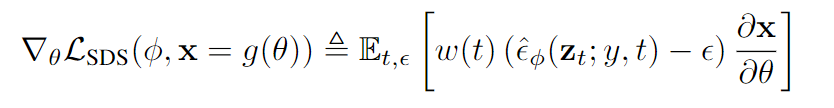
直觀來看,這個(gè)損失用對(duì)應(yīng)于時(shí)間步長的隨機(jī)數(shù)量的噪聲來擾動(dòng)輸入數(shù)據(jù),并估計(jì)出一個(gè)更新方向,該方向遵循擴(kuò)散模型的得分函數(shù),以移動(dòng)到一個(gè)更高密度的區(qū)域。
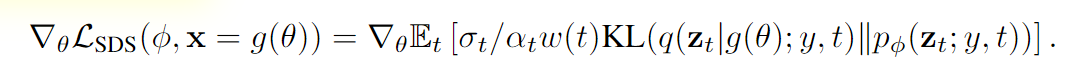
雖然這種用擴(kuò)散模型學(xué)習(xí)DIP的梯度可能看起來很特別,但實(shí)驗(yàn)結(jié)果表明更新方向確實(shí)是從擴(kuò)散模型學(xué)到的得分函數(shù)中得到的加權(quán)概率密度蒸餾損失的梯度。
研究人員將該采樣方法命名為得分蒸餾采樣(Score Distillation Sampling, SDS),因?yàn)樵撨^程與蒸餾有關(guān),但使用的是得分函數(shù)而不是密度。

下一步就是通過將SDS與為該3D生成任務(wù)定制的NeRF變體相結(jié)合,DreamFusion可以為一組不同的用戶提供的文本提示生成了高保真的連貫的3D物體和場景。
文章中采用的預(yù)訓(xùn)練擴(kuò)散模型為Imagen,并且只使用分辨率為64×64的基礎(chǔ)模型,并按原樣使用這個(gè)預(yù)訓(xùn)練的模型,不做任何修改。
然后用隨機(jī)權(quán)重初始化一個(gè)類似于NeRF的模型,從隨機(jī)的相機(jī)位置和角度反復(fù)渲染該NeRF的視圖,用這些渲染結(jié)果作為環(huán)繞Imagen的分?jǐn)?shù)蒸餾損失函數(shù)的輸入。
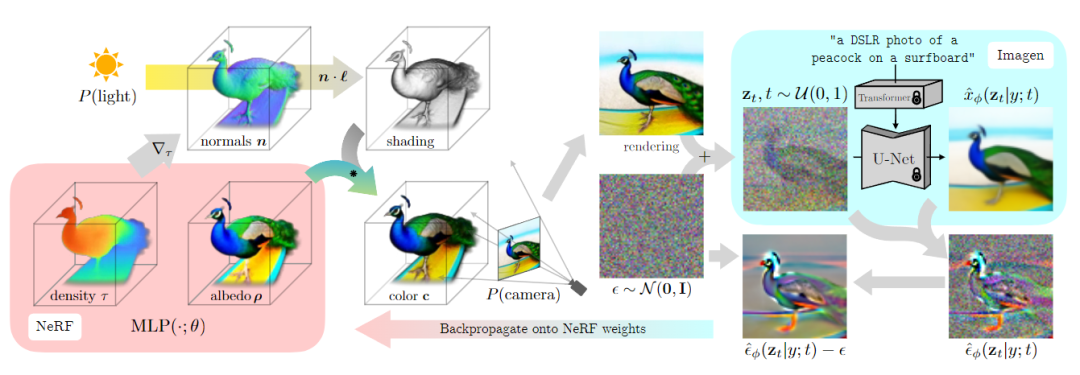
給出一個(gè)預(yù)訓(xùn)練好的文本到圖像的擴(kuò)散模型,一個(gè)以NeRF形式存在的可w微分的圖像參數(shù)化DIP,以及一個(gè)損失函數(shù)(最小值代表好樣本),這樣無三維數(shù)據(jù)的文本到三維合成所需的所有組件就齊活了。
對(duì)于每個(gè)文本提示,都從頭開始訓(xùn)練一個(gè)隨機(jī)初始化的NeRF。
DreamFusion優(yōu)化的每次迭代都包含四步:
1、隨機(jī)采樣一個(gè)相機(jī)和燈光
在每次迭代中,相機(jī)位置在球面坐標(biāo)中被隨機(jī)采樣,仰角范圍從-10°到90°,方位角從0°到360°,與原點(diǎn)的距離為1到1.5
同時(shí)還在原點(diǎn)周圍取樣一個(gè)看(look-at)的點(diǎn)和一個(gè)向上(up)的矢量,并將這些與攝像機(jī)的位置結(jié)合起來,創(chuàng)建一個(gè)攝像機(jī)的姿勢矩陣。同時(shí)對(duì)焦距乘數(shù)服從U(0.7, 1.35)進(jìn)行采樣,點(diǎn)光位置是從以相機(jī)位置為中心的分布中采樣的。
使用廣泛的相機(jī)位置對(duì)合成連貫的三維場景至關(guān)重要,寬泛的相機(jī)距離也有助于提高學(xué)習(xí)場景的分辨率。
2、從該相機(jī)和燈光下渲染NeRF的圖像
考慮到相機(jī)的姿勢和光線的位置,以64×64的分辨率渲染陰影NeRF模型。在照明的彩色渲染、無紋理渲染和沒有任何陰影的反照率渲染之間隨機(jī)選擇。
3、計(jì)算SDS損失相對(duì)于NeRF參數(shù)的梯度
通常情況下,文本prompt描述的都是一個(gè)物體的典型視圖,在對(duì)不同的視圖進(jìn)行采樣時(shí),這些視圖并不是最優(yōu)描述。根據(jù)隨機(jī)采樣的相機(jī)的位置,在提供的輸入文本中附加與視圖有關(guān)的文本是有益的。
對(duì)于大于60°的高仰角,在文本中添加俯視(overhead view),對(duì)于不大于60°的仰角,使用文本embedding的加權(quán)組合來添加前視圖、側(cè)視圖 或 后視圖,具體取決于方位角的值。
4、使用優(yōu)化器更新NeRF參數(shù)
3D場景在一臺(tái)有4個(gè)芯片的TPUv4機(jī)器上進(jìn)行了優(yōu)化,每個(gè)芯片渲染一個(gè)單獨(dú)的視圖并評(píng)估擴(kuò)散U-Net,每個(gè)設(shè)備的batch size為1。優(yōu)化了15,000次迭代,大約需要1.5小時(shí)。

實(shí)驗(yàn)部分評(píng)估了DreamFusion從各種文本提示中生成連貫的3D場景的能力。
與現(xiàn)有的zero-shot文本到3D生成模型進(jìn)行比較后可以發(fā)現(xiàn),DreamFusion模型中能夠?qū)崿F(xiàn)精確3D幾何的關(guān)鍵組件。

通過對(duì)比DreamFusion和幾個(gè)基線的R-精度,包括Dream Fields、CLIP-Mesh和一個(gè)評(píng)估MS-COCO中原始字幕圖像的oracle,可以發(fā)現(xiàn)DreamFusion在彩色圖像上的表現(xiàn)超過了這兩個(gè)基線,并接近于ground-truth圖像的性能。
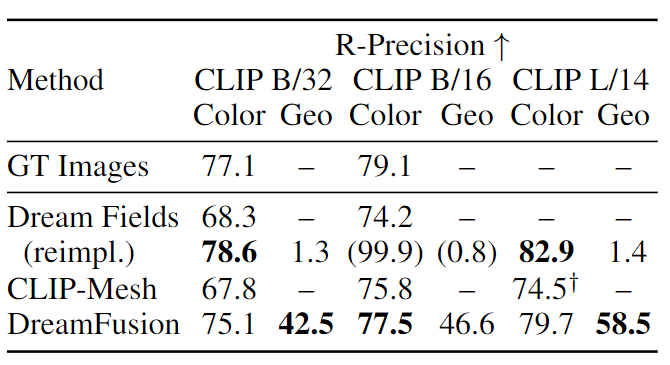
雖然Dream Fields的實(shí)現(xiàn)在用無紋理渲染評(píng)估幾何圖形(Geo)時(shí)表現(xiàn)得很好,但DreamFusion在58.5%的情況里與標(biāo)準(zhǔn)一致。

審核編輯 :李倩
-
圖像
+關(guān)注
關(guān)注
2文章
1092瀏覽量
41016 -
3D模型
+關(guān)注
關(guān)注
1文章
72瀏覽量
16311
原文標(biāo)題:3D版DALL-E來了!谷歌發(fā)布文本3D生成模型DreamFusion,給一個(gè)文本提示就能生成3D模型!
文章出處:【微信號(hào):CVer,微信公眾號(hào):CVer】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
NVIDIA助力影眸科技3D生成工具Rodin升級(jí)
一種以圖像為中心的3D感知模型BIP3D
使用海爾曼太通/HellermannTyton 3D CAD 模型進(jìn)行快速高效的設(shè)計(jì)
3D打印可以打印那種柔韌性好,能隨意變形的模型嗎?
對(duì)于結(jié)構(gòu)光測量、3D視覺的應(yīng)用,使用100%offset的lightcrafter是否能用于點(diǎn)云生成的應(yīng)用?
騰訊混元3D AI創(chuàng)作引擎正式發(fā)布
騰訊混元3D AI創(chuàng)作引擎正式上線
借助谷歌Gemini和Imagen模型生成高質(zhì)量圖像

Google DeepMind發(fā)布Genie 2:打造交互式3D虛擬世界
如何使用 Llama 3 進(jìn)行文本生成
安寶特產(chǎn)品 安寶特3D Analyzer:智能的3D CAD高級(jí)分析工具
歡創(chuàng)播報(bào) 騰訊元寶首發(fā)3D生成應(yīng)用






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論