") 基于用于自然語(yǔ)言生成的“語(yǔ)境調(diào)優(yōu)”技術(shù)
基于用于自然語(yǔ)言生成的“語(yǔ)境調(diào)優(yōu)”技術(shù)
一、引言
自然語(yǔ)言生成(又稱為文本生成)旨在基于輸入數(shù)據(jù)用人類語(yǔ)言生成合理且可讀的文本。隨著預(yù)訓(xùn)練語(yǔ)言模型的發(fā)展,GPT-3,BART等模型逐漸成為了生成任務(wù)的主流模型。近年來(lái),為了利用預(yù)訓(xùn)練階段編碼的豐富知識(shí),提示學(xué)習(xí)成為了一個(gè)簡(jiǎn)單而強(qiáng)大的方法。
這篇工作主要聚焦于開(kāi)放式文本生成,例如故事生成和評(píng)論生成。在這種場(chǎng)景下,輸入僅包含有限的信息,而任務(wù)目標(biāo)是要生成富含信息量且與主題相關(guān)的長(zhǎng)文本。例如下表中的例子,我們需要寫(xiě)一段關(guān)于“l(fā)ive-action”和“animation”的評(píng)論,這需要對(duì)這兩個(gè)主題的背景信息有深入的了解。現(xiàn)有的提示學(xué)習(xí)方法,會(huì)在輸入前加上人工的離散提示(例如表中的“Write a story about:”),或者在輸入前加上可學(xué)習(xí)的連續(xù)型提示。但是這些提示是靜態(tài)的,更多是包含任務(wù)相關(guān)的信息,但與輸入無(wú)關(guān),很難依靠他們?nèi)ド筛缓畔⒘康奈谋尽?/p>

同時(shí)在長(zhǎng)文本生成中,一個(gè)常見(jiàn)的問(wèn)題是“跑題”,即生成的文本逐漸和主題無(wú)關(guān)。為了解決以上兩個(gè)問(wèn)題,我們分別提出了語(yǔ)境提示(contextualized prompts)和連續(xù)反向提示(continuous inverse prompting),來(lái)增強(qiáng)生成文本的信息量和相關(guān)性。
二、語(yǔ)境調(diào)優(yōu)(Context-Tuning)
本文提出了一種創(chuàng)新的連續(xù)提示方法,稱語(yǔ)境調(diào)優(yōu),用于微調(diào)預(yù)訓(xùn)練模型來(lái)進(jìn)行自然語(yǔ)言生成,我們的核心貢獻(xiàn)有三點(diǎn):①我們首次提出了輸入相關(guān)的提示——語(yǔ)境提示,抽取預(yù)訓(xùn)練模型中的知識(shí)作為提示來(lái)豐富生成文本的信息量。②我們使用了連續(xù)反向提示,最大化基于輸出生成輸入的概率,來(lái)增強(qiáng)生成文本的相關(guān)性。③我們使用了一種輕量化的語(yǔ)境調(diào)優(yōu)方法,在只微調(diào)0.12%參數(shù)的情況下保持98%的性能。
1.語(yǔ)境提示(contextualized prompts)
語(yǔ)境提示是基于輸入文本生成的提示,我們使用BERT作為提示生成器來(lái)抽取模型中有關(guān)輸入的知識(shí),以此達(dá)到豐富信息量的目的。 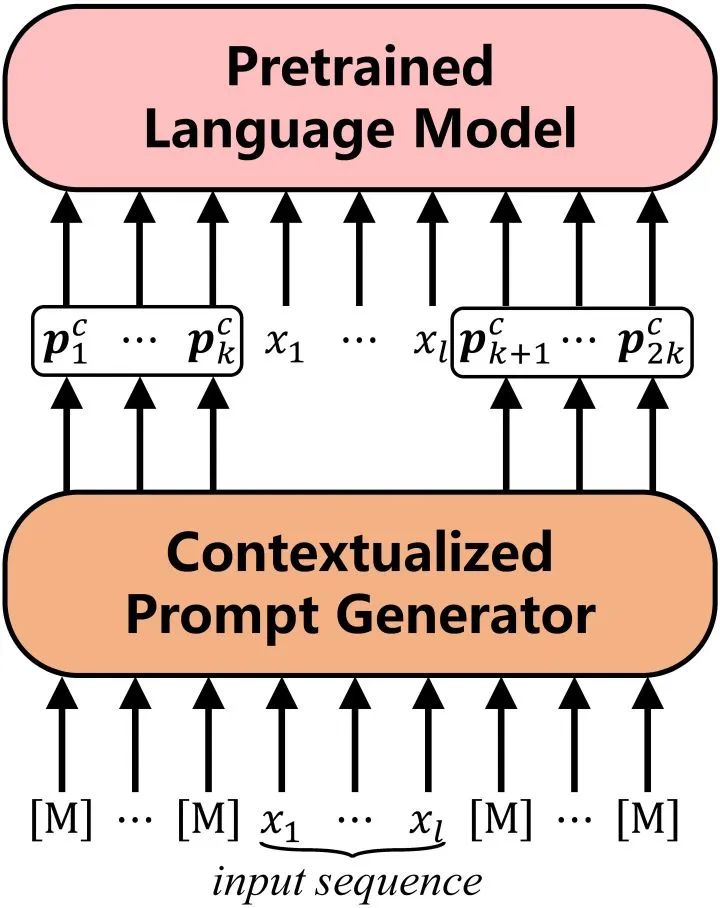 ? 具體的,我們?cè)??兩端各放置??個(gè)??得到BERT的輸入: ?? 經(jīng)過(guò)BERT的編碼,我們得到這些??的頂層表示,作為初始提示: ?? 然后我們使用一種“語(yǔ)義對(duì)齊”操作,將這些隱提示對(duì)應(yīng)到真實(shí)詞表空間,得到我們的語(yǔ)境提示??: ?? 其中??是BERT的詞表矩陣,??是BERT預(yù)測(cè)??的映射矩陣。直覺(jué)地,我們可以將語(yǔ)義對(duì)齊操作看做是預(yù)測(cè)??的概率分布,然后將相應(yīng)的詞向量加權(quán)平均。 ? 最后我們將語(yǔ)境提示加在輸入兩端,使用BART作為我們的生成模型,建模輸入??到輸出??的概率: ?? 2.連續(xù)反向提示(continuous inverse prompting) 連續(xù)反向提示通過(guò)建模從輸出到輸入的反向過(guò)程,改進(jìn)自然語(yǔ)言生成,使生成文本與輸入的相關(guān)性更強(qiáng)。
? 具體的,我們?cè)??兩端各放置??個(gè)??得到BERT的輸入: ?? 經(jīng)過(guò)BERT的編碼,我們得到這些??的頂層表示,作為初始提示: ?? 然后我們使用一種“語(yǔ)義對(duì)齊”操作,將這些隱提示對(duì)應(yīng)到真實(shí)詞表空間,得到我們的語(yǔ)境提示??: ?? 其中??是BERT的詞表矩陣,??是BERT預(yù)測(cè)??的映射矩陣。直覺(jué)地,我們可以將語(yǔ)義對(duì)齊操作看做是預(yù)測(cè)??的概率分布,然后將相應(yīng)的詞向量加權(quán)平均。 ? 最后我們將語(yǔ)境提示加在輸入兩端,使用BART作為我們的生成模型,建模輸入??到輸出??的概率: ?? 2.連續(xù)反向提示(continuous inverse prompting) 連續(xù)反向提示通過(guò)建模從輸出到輸入的反向過(guò)程,改進(jìn)自然語(yǔ)言生成,使生成文本與輸入的相關(guān)性更強(qiáng)。 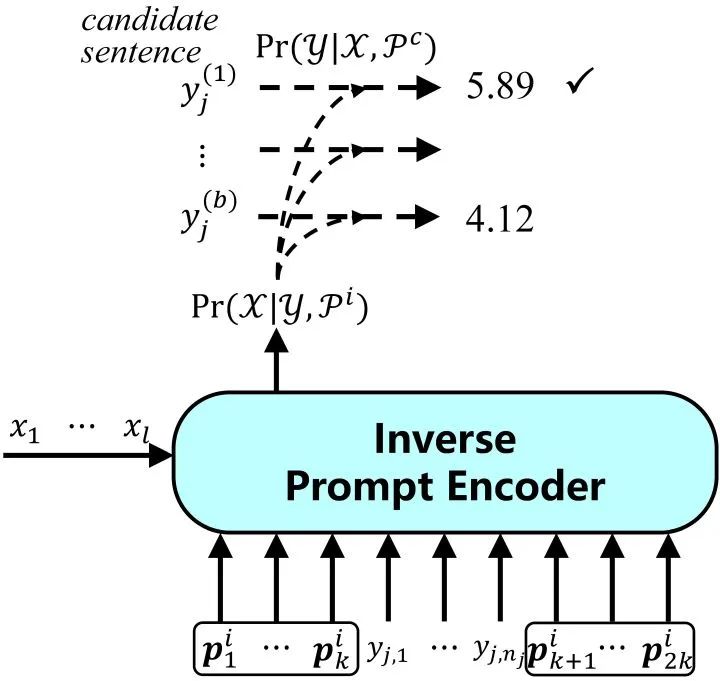 ? 我們有這樣一個(gè)假設(shè),如果我們可以從輸出恢復(fù)輸入,我們便認(rèn)為輸出與輸入相關(guān)。但在一些生成場(chǎng)景下,這從輸出恢復(fù)輸入并不自然,因此我們使用連續(xù)反向提示來(lái)緩解這一現(xiàn)象。我們?cè)谳敵鰞啥颂砑舆B續(xù)反向提示??,并建模輸出到輸入的概率: ?? 我們期望反向提示可以更好地反映輸出到輸入的關(guān)系,這更多取決于任務(wù)本身,因此這里的反向提示是靜態(tài)的。 ? 最后,我們結(jié)合語(yǔ)境提示和連續(xù)反向提示,選擇聯(lián)合概率最大的生成文本: ?? 3.輕量化語(yǔ)境調(diào)優(yōu) 考慮到我們的語(yǔ)境提示引入了兩個(gè)預(yù)訓(xùn)練模型,我們使用了一種輕量化微調(diào)方法BifFit,即僅微調(diào)每個(gè)參數(shù)的bias項(xiàng),最終我們僅需要微調(diào)全量模型0.12%的參數(shù)。因此,我們?cè)趯?shí)驗(yàn)中考慮了全量微調(diào)和輕量化微調(diào)兩種場(chǎng)景。 三、實(shí)驗(yàn) 為了驗(yàn)證語(yǔ)境調(diào)優(yōu)的有效性,我們?cè)谒膫€(gè)開(kāi)放式文本數(shù)據(jù)集上進(jìn)行了測(cè)試:WritingPrompts,ROCStories,ChangeMyReivew和WikiPlots。 我們考慮了六個(gè)基線方法(其中前四個(gè)用于全量微調(diào),后兩個(gè)用于輕量化微調(diào)):
? 我們有這樣一個(gè)假設(shè),如果我們可以從輸出恢復(fù)輸入,我們便認(rèn)為輸出與輸入相關(guān)。但在一些生成場(chǎng)景下,這從輸出恢復(fù)輸入并不自然,因此我們使用連續(xù)反向提示來(lái)緩解這一現(xiàn)象。我們?cè)谳敵鰞啥颂砑舆B續(xù)反向提示??,并建模輸出到輸入的概率: ?? 我們期望反向提示可以更好地反映輸出到輸入的關(guān)系,這更多取決于任務(wù)本身,因此這里的反向提示是靜態(tài)的。 ? 最后,我們結(jié)合語(yǔ)境提示和連續(xù)反向提示,選擇聯(lián)合概率最大的生成文本: ?? 3.輕量化語(yǔ)境調(diào)優(yōu) 考慮到我們的語(yǔ)境提示引入了兩個(gè)預(yù)訓(xùn)練模型,我們使用了一種輕量化微調(diào)方法BifFit,即僅微調(diào)每個(gè)參數(shù)的bias項(xiàng),最終我們僅需要微調(diào)全量模型0.12%的參數(shù)。因此,我們?cè)趯?shí)驗(yàn)中考慮了全量微調(diào)和輕量化微調(diào)兩種場(chǎng)景。 三、實(shí)驗(yàn) 為了驗(yàn)證語(yǔ)境調(diào)優(yōu)的有效性,我們?cè)谒膫€(gè)開(kāi)放式文本數(shù)據(jù)集上進(jìn)行了測(cè)試:WritingPrompts,ROCStories,ChangeMyReivew和WikiPlots。 我們考慮了六個(gè)基線方法(其中前四個(gè)用于全量微調(diào),后兩個(gè)用于輕量化微調(diào)):
通用文本生成模型:BART,GPT-2和T5;
專為故事生成設(shè)計(jì)的方法:HINT;
輕量化方法:Prefix-tuning和Prompt tuning
同時(shí),我們使用BLEU來(lái)衡量生成文本的質(zhì)量,用Distinct來(lái)評(píng)價(jià)生成文本的多樣性。 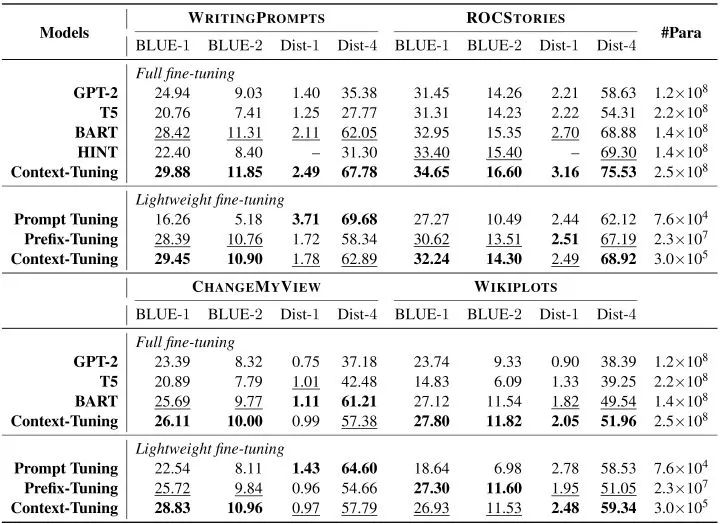 ? 實(shí)驗(yàn)結(jié)果表明我們?cè)?strong>全量微調(diào)和輕量化微調(diào)兩種場(chǎng)景下均優(yōu)于基線模型,其中輕量化模型在僅微調(diào)0.12%參數(shù)的情況下可以達(dá)到全量微調(diào)98%的表現(xiàn)。
? 實(shí)驗(yàn)結(jié)果表明我們?cè)?strong>全量微調(diào)和輕量化微調(diào)兩種場(chǎng)景下均優(yōu)于基線模型,其中輕量化模型在僅微調(diào)0.12%參數(shù)的情況下可以達(dá)到全量微調(diào)98%的表現(xiàn)。 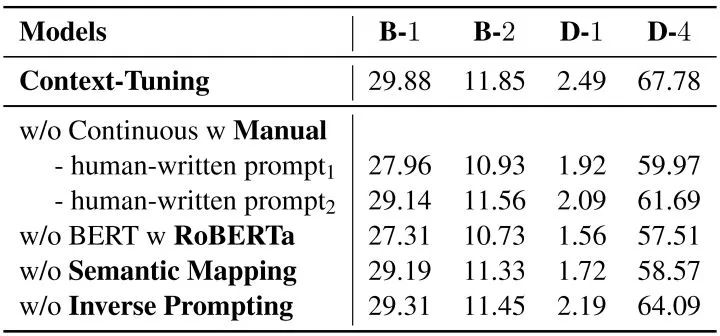 ? 消融實(shí)驗(yàn)中,我們嘗試替換語(yǔ)境提示、刪除語(yǔ)義對(duì)齊或反向提示,生成結(jié)果均有下降,這驗(yàn)證了我們語(yǔ)境提示和連續(xù)反向提示的有效性。 ?
? 消融實(shí)驗(yàn)中,我們嘗試替換語(yǔ)境提示、刪除語(yǔ)義對(duì)齊或反向提示,生成結(jié)果均有下降,這驗(yàn)證了我們語(yǔ)境提示和連續(xù)反向提示的有效性。 ? 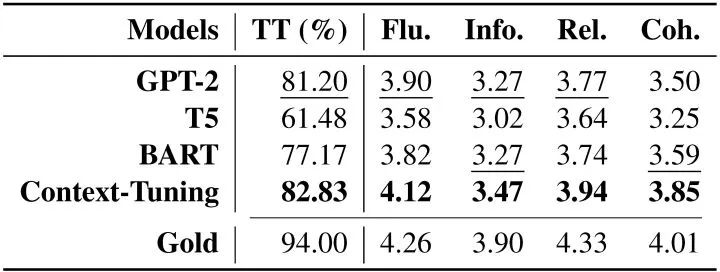 ? 人工評(píng)價(jià)表明,使用語(yǔ)境調(diào)優(yōu)生成的文本在流暢性、信息量、相關(guān)性和一致性上均優(yōu)于基線模型,且有82.83%的生成文本被認(rèn)為是人所寫(xiě)的。 ?
? 人工評(píng)價(jià)表明,使用語(yǔ)境調(diào)優(yōu)生成的文本在流暢性、信息量、相關(guān)性和一致性上均優(yōu)于基線模型,且有82.83%的生成文本被認(rèn)為是人所寫(xiě)的。 ? 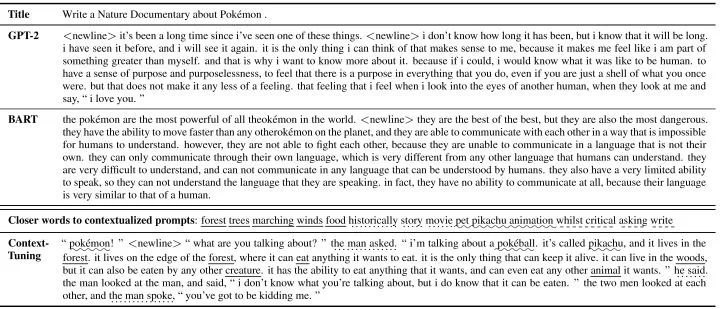 ? 四、總結(jié)
? 四、總結(jié)  ? 本文提出了用于自然語(yǔ)言生成的“語(yǔ)境調(diào)優(yōu)”技術(shù): ?
? 本文提出了用于自然語(yǔ)言生成的“語(yǔ)境調(diào)優(yōu)”技術(shù): ?
我們提出“語(yǔ)境提示”,增強(qiáng)生成文本的信息量;
我們使用“連續(xù)反向提示”,增強(qiáng)生成文本的相關(guān)性;
我們提出輕量化微調(diào)語(yǔ)境調(diào)優(yōu),僅微調(diào)0.12%的參數(shù)卻能保持98%的性能。
-
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7239瀏覽量
90990 -
模型
+關(guān)注
關(guān)注
1文章
3483瀏覽量
49987 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5554瀏覽量
122474 -
自然語(yǔ)言
+關(guān)注
關(guān)注
1文章
291瀏覽量
13604
原文標(biāo)題:COLING'22 | 如何增強(qiáng)文本生成的信息量和相關(guān)性?基于語(yǔ)境提示的生成方法Context-Tuning
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論