 文本分類中處理樣本不均衡和提升模型魯棒性的trick
文本分類中處理樣本不均衡和提升模型魯棒性的trick
寫在前面
文本分類是NLP中一個非常重要的任務,也是非常適合入坑NLP的第一個完整項目。
文本分類看似簡單,但實則里面有好多門道。作者水平有限,只能將平時用到的方法和trick在此做個記錄和分享,并且盡可能提供給出簡潔、清晰的代碼實現。希望各位看官都能有所收獲。
本文主要討論文本分類中處理樣本不均衡和提升模型魯棒性的trick。
1. 緩解樣本不均衡
樣本不均衡現象
假如我們要實現一個新聞正負面判斷的文本二分類器,負面新聞的樣本比例較少,可能2W條新聞有100條甚至更少的樣本屬于負例。這種現象就是樣本不均衡。
在樣本不均衡場景下,樣本會呈現一個長尾分布(如圖中所示會出現長長的尾巴),頭部的標簽包含了大量的樣本,而尾部的標簽擁有很少的樣本,這種現象也叫長尾現象。岔開說下,聽過二八定律的人大多知道長尾現象其實很普遍,比如80%的財富掌握在20%的人手中。

樣本不均衡問題
樣本不均衡會帶來很多問題。模型訓練的本質是最小化損失函數,當某個類別的樣本數量非常龐大,損失函數的值大部分被其所影響,導致的結果就是模型分類會傾向于該類別(樣本量較大的類別)。
咱拿上面文本分類的例子來說明。現在有2W條用戶搜索的樣本,其中100條是負面新聞,即負樣本,那么當模型全部將樣本預測為正例,也能得到 99.5% 的準確率。但實際上這個模型跟盲猜沒什么區別,而我們的目的是讓模型能夠正確的區分正例和負例。
1.1 模型層面解決樣本不均衡
在模型層面解決樣本不均衡問題,可以選擇加入 Focal Loss 學習難學樣本,具體原理可以參考文章《何愷明大神的「Focal Loss」,如何更好地理解?》[1]。
1.1.1 Focal Loss pytorch代碼實現
classFocalLoss(nn.Module): """Multi-classFocallossimplementation""" def__init__(self,gamma=2,weight=None,reduction='mean',ignore_index=-100): super(FocalLoss,self).__init__() self.gamma=gamma self.weight=weight self.ignore_index=ignore_index self.reduction=reduction defforward(self,input,target): """ input:[N,C] target:[N,] """ log_pt=torch.log_softmax(input,dim=1) pt=torch.exp(log_pt) log_pt=(1-pt)**self.gamma*log_pt loss=torch.nn.functional.nll_loss(log_pt,target,self.weight,reduction=self.reduction,ignore_index=self.ignore_index) returnloss
代碼鏈接:blog_code/nlp/focal_loss.py[2]
1.2 數據層面解決樣本不均衡
假如我們的正樣本只有100條,而負樣本可能有1W條。如果不采取任何策略,那么我們就是使用這1.01W條樣本去訓練模型。從數據層面解決樣本不均衡的問題核心是通過人為控制正負樣本的比例,分成欠采樣和過采樣兩種。
1.2.1 欠采樣
簡單隨機
欠采樣的基本做法是這樣的,現在我們的正負樣本比例為1:100。如果我們想讓正負樣本比例不超過1:10,那么模型訓練的時候數量比較少的正樣本也就是100條全部使用,而負樣本隨機挑選1000條。
通過這樣人為的方式,我們把樣本的正負比例強行控制在了1:10。需要注意的是,這種方式存在一個問題:為了強行控制樣本比例我們生生的舍去了那9000條負樣本,這對于模型來說是莫大的損失。
迭代預分類
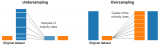
相比于簡單的對負樣本隨機采樣的欠采樣方法,實際工作中更推薦使用迭代預分類的方式來采樣負樣本。具體流程如下圖所示:
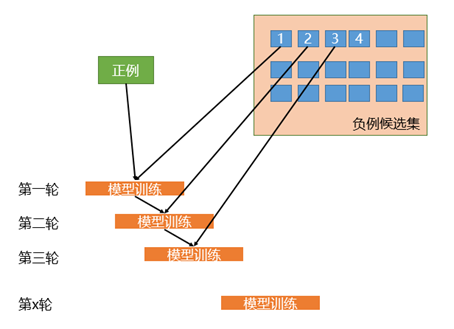
首先我們會使用全部的正樣本和從負例候選集中隨機采樣一部分負樣本(這里假如是100條)去訓練第一輪分類器;
然后用第一輪分類器去預測負例候選集剩余的9900條數據,把9900條負例中預測為正例的樣本(也就是預測錯誤的樣本)再隨機采樣100條和第一輪訓練的數據放到一起去訓練第二輪分類器;
同樣的方法用第二輪分類器去預測負例候選集剩余的9800條數據,直到訓練的第N輪分類器可以全部識別負例候選集,這就是使用迭代預分類的方式進行欠采樣。
相比于隨機欠采樣來說,迭代預分類的欠采樣方式能最大限度地利用負樣本中差異性較大的負樣本,從而在控制正負樣本比例的基礎上采樣出了最有代表意義的負樣本。
欠采樣的方式整體來說或多或少的會損失一些樣本,對于那些需要控制樣本量級的場景下比較合適。如果沒有嚴格控制樣本量級的要求那么下面的過采樣可能會更加適合你。
1.2.2 過采樣
過采樣和欠采樣比較類似,都是人工干預控制樣本的比例,不同的是過采樣不會損失樣本。
還拿上面的例子,現在有正樣本100條,負樣本1W條,最簡單的過采樣方式是我們使用全部的負樣本1W條。但是,為了維持正負樣本比例,我們會從正樣本中有放回的重復采樣,直到獲取了1000條正樣本,也就是說有些正樣本可能會被重復采樣到,這樣就能保持1:10的正負樣本比例了。這是最簡單的過采樣方式,這種方式可能會存在嚴重的過擬合。
實際的場景中會通過樣本增強的技術來增加正樣本。
2. 提升模型魯棒性
提升模型魯棒性的方法有很多,其中對抗訓練、知識蒸餾、防止模型過擬合和多模型融合是常見的穩定提升方式。
2.1 對抗訓練
對抗訓練是一種能有效提高模型魯棒性和泛化能力的訓練手段,其基本原理是通過在原始輸入上增加對抗擾動,得到對抗樣本,再利用對抗樣本進行訓練,從而提高模型的表現。
由于自然語言文本是離散的,一般會把對抗擾動添加到嵌入層上。為了最大化對抗樣本的擾動能力,利用梯度上升的方式生成對抗樣本。為了避免擾動過大,將梯度做了歸一化處理。
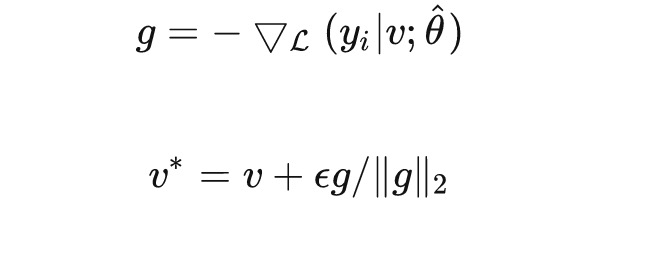
其中, 為嵌入向量。在實際訓練過程中,我們會在訓練完一個batch的原始輸入數據時,保存當前batch對輸入詞向量的梯度,得到對抗樣本后,再使用對抗樣本進行對抗訓練。
2.1.1 對抗訓練pytorch代碼實現
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=1., emb_name='emb'):
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0:
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self, emb_name='emb'):
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
訓練中加入幾行代碼
# 初始化 fgm = FGM(model) for batch_input, batch_label in data: # 正常訓練 loss = model(batch_input, batch_label) loss.backward() # 對抗訓練 fgm.attack() # 修改embedding # optimizer.zero_grad() # 梯度累加,不累加去掉注釋 loss_sum = model(batch_input, batch_label) loss_sum.backward() # 累加對抗訓練的梯度 fgm.restore() # 恢復Embedding的參數 optimizer.step() optimizer.zero_grad()
代碼鏈接:blog_code/nlp/at.py [3]
2.2 知識蒸餾
與對抗訓練類似,知識蒸餾也是一種常用的提高模型泛化能力的訓練方法。
知識蒸餾這個概念最早由Hinton在2015年提出。一開始,知識蒸餾通往往應用在模型壓縮方面,利用訓練好的復雜模型(teacher model)輸出作為監督信號去訓練另一個簡單模型(student model),從而將teacher學習到的知識遷移到student。
Tommaso在18年提出,若student和teacher的模型完全相同,蒸餾后則會對模型的表現有一定程度上的提升。
2.3 防止模型過擬合
2.3.1 正則化
L1和L2正則化
L1正則化可以得到稀疏解,L2正則化可以得到平滑解,原因參考文章《為什么L1稀疏,L2平滑?》[4]。
2.3.2 Dropout
Dropout是指在深度學習網絡的訓練過程中,對于神經網絡單元,按照一定的概率將其暫時從網絡中丟棄。
Dropout為什么能防止過擬合,可以通過以下幾個方面來解釋:
它強迫一個神經單元,和隨機挑選出來的其他神經單元共同工作,達到好的效果。消除減弱了神經元節點間的聯合適應性,增強了泛化能力;
類似于bagging的集成效果;
對于每一個dropout后的網絡,進行訓練時,相當于做了Data Augmentation,因為,總可以找到一個樣本,使得在原始的網絡上也能達到dropout單元后的效果。比如,對于某一層,dropout一些單元后,形成的結果是(1.5,0,2.5,0,1,2,0),其中0是被drop的單元,那么總能找到一個樣本,使得結果也是如此。這樣,每一次dropout其實都相當于增加了樣本。
Dropout在測試時,并不會隨機丟棄神經元,而是使用全部所有的神經元,同時,所有的權重值都乘上1-p,p代表的是隨機失活率。
2.3.3 數據增強
數據增強即需要得到更多的符合要求的數據,即和已有的數據是獨立同分布的,或者近似獨立同分布的。一般有以下方法:
1)從數據源頭采集更多數據;
2)復制原有數據并加上隨機噪聲;
3)重采樣;
4)根據當前數據集估計數據分布參數,使用該分布產生更多數據等。
2.3.4 Early stopping
在模型對訓練數據集迭代收斂之前停止迭代來防止過擬合。因為在初始化網絡的時候一般都是初始為較小的權值,訓練時間越長,部分網絡權值可能越大。如果我們在合適時間停止訓練,就可以將網絡的能力限制在一定范圍內。
2.3.5 交叉驗證
交叉驗證的基本思想就是將原始數據進行分組,一部分做為訓練集來訓練模型,另一部分做為測試集來評價模型。我們常用的交叉驗證方法有簡單交叉驗證、S折交叉驗證和留一交叉驗證。
2.3.6 Batch Normalization
一種非常有用的正則化方法,可以讓大型的卷積網絡訓練速度加快很多倍,同時收斂后分類的準確率也可以大幅度的提高。
BN在訓練某層時,會對每一個mini-batch數據進行標準化(normalization)處理,使輸出規范到 的正態分布,減少了Internal convariate shift(內部神經元分布的改變),傳統的深度神經網絡在訓練是每一層的輸入的分布都在改變,因此訓練困難,只能選擇用一個很小的學習速率,但是每一層用了BN后,可以有效的解決這個問題,學習速率可以增大很多倍。
2.3.7 選擇合適的網絡結構
通過減少網絡層數、神經元個數、全連接層數等降低網絡容量。
3.多模型融合
Baggging &Boosting,將弱分類器融合之后形成一個強分類器,而且融合之后的效果會比最好的弱分類器更好,三個臭皮匠頂一個諸葛亮。
-
模型
+關注
關注
1文章
3486瀏覽量
49990 -
代碼
+關注
關注
30文章
4886瀏覽量
70253 -
nlp
+關注
關注
1文章
490瀏覽量
22482
原文標題:2. 提升模型魯棒性
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
pyhanlp文本分類與情感分析
NLPIR平臺在文本分類方面的技術解析
不均衡數據集上基于子域學習的復合分類模型
結合BERT模型的中文文本分類算法

基于不同神經網絡的文本分類方法研究對比
膠囊網絡在小樣本做文本分類中的應用(下)
基于主題分布優化的模糊文本分類方法
如何解決樣本不均的問題?





 工商網監
工商網監
評論