 import讓Python代碼速度提升百倍
import讓Python代碼速度提升百倍
眾所周知,Python的簡單和易讀性是靠犧牲性能為代價的——
尤其是在計算密集的情況下,比如多重for循環。
不過現在,大佬胡淵鳴說了:
只需import 一個叫做“Taichi”的庫,就可以把代碼速度提升100倍!
不信?
來看三個例子。
計算素數的個數,速度x120
第一個例子非常非常簡單,求所有小于給定正整數N的素數。
標準答案如下:
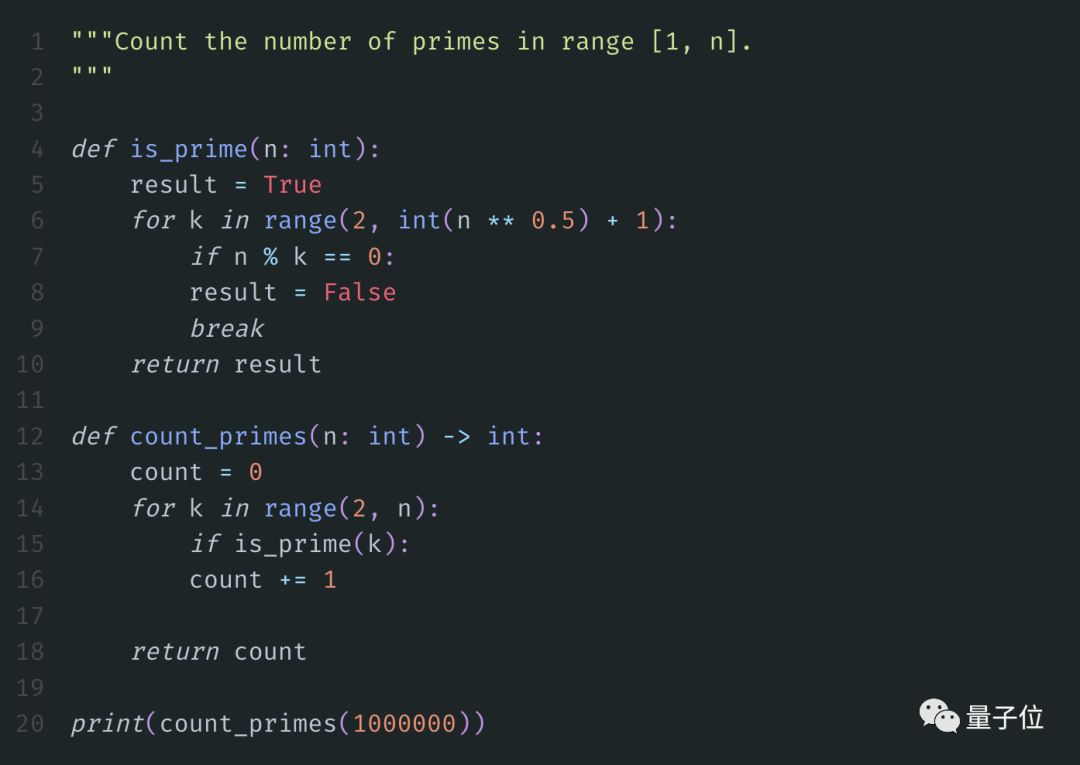
我們將上面的代碼保存,運行。
當N為100萬時,需要2.235s得到結果:

現在,我們開始施魔法。
不用更改任何函數體,import“taichi”庫,然后再加兩個裝飾器:
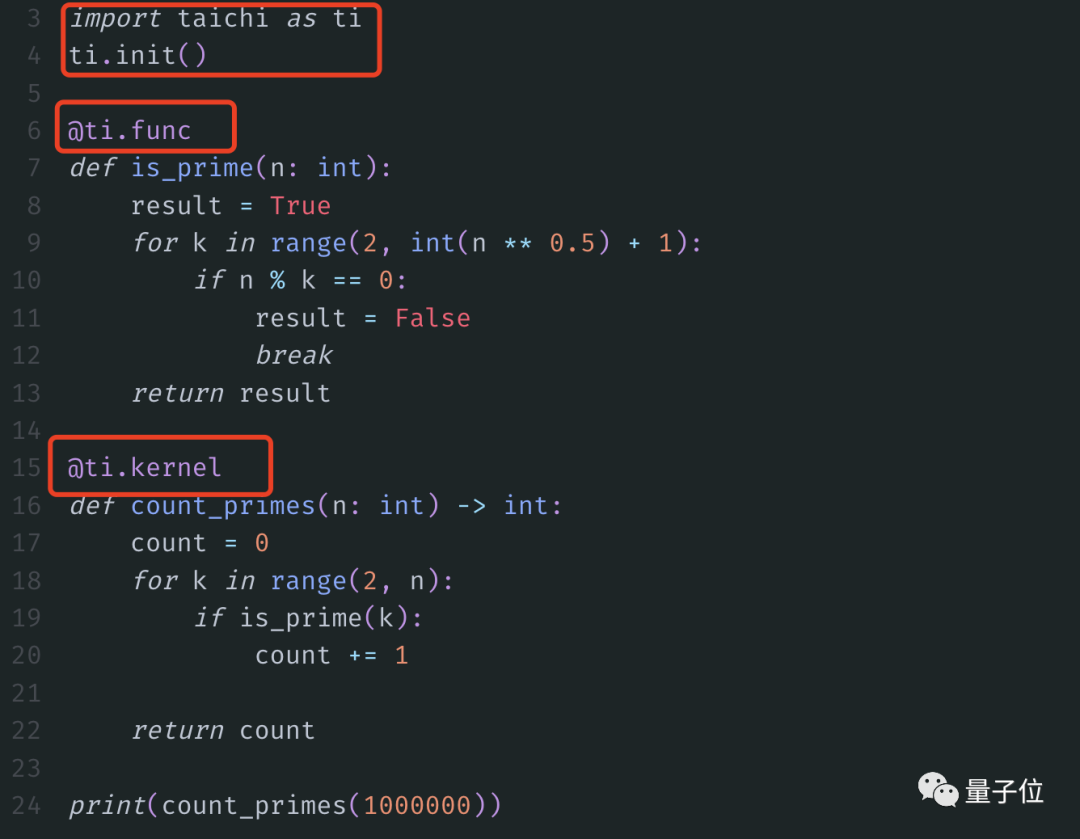
Bingo!同樣的結果只要0.363s,快了將近6倍。

如果N=1000萬,則只要0.8s;要知道,不加它可是55s,一下子又快了70倍!
不止如此,我們還可以在ti.init()中加個參數變為ti.init(arch=ti.gpu) ,讓taich在GPU上進行計算。
那么此時,計算所有小于1000萬的素數就只耗時0.45s了,與原來的Python代碼相比速度就提高了120倍!
厲不厲害?
什么?你覺得這個例子太簡單了,說服力不夠?我們再來看一個稍微復雜一點的。
動態規劃,速度x500
動態規劃不用多說,作為一種優化算法,通過動態存儲中間計算結果來減少計算時間。
我們以經典教材《算法導論》中的經典動態規劃案例“最長公共子序列問題(LCS)”為例。
比如對于序列a = [0, 1, 0, 2, 4, 3, 1, 2, 1]和序列b = [4, 0, 1, 4, 5, 3, 1, 2],它們的LCS就是:
LCS(a, b) = [0, 1, 4, 3, 1, 2]。
用動態規劃的思路計算LCS,就是先求解序列a的前i個元素和序列b的前j個元素的最長公共子序列的長度,然后逐步增加i或j的值,重復過程,得到結果。
我們用f[i, j]來指代這個子序列的長度,即LCS((prefix(a, i), prefix(b, j)。其中prefix(a, i) 表示序列a的前i個元素,即a[0], a[1], …, a[i - 1],得到如下遞歸關系:

完整代碼如下:

現在,我們用Taichi來加速:
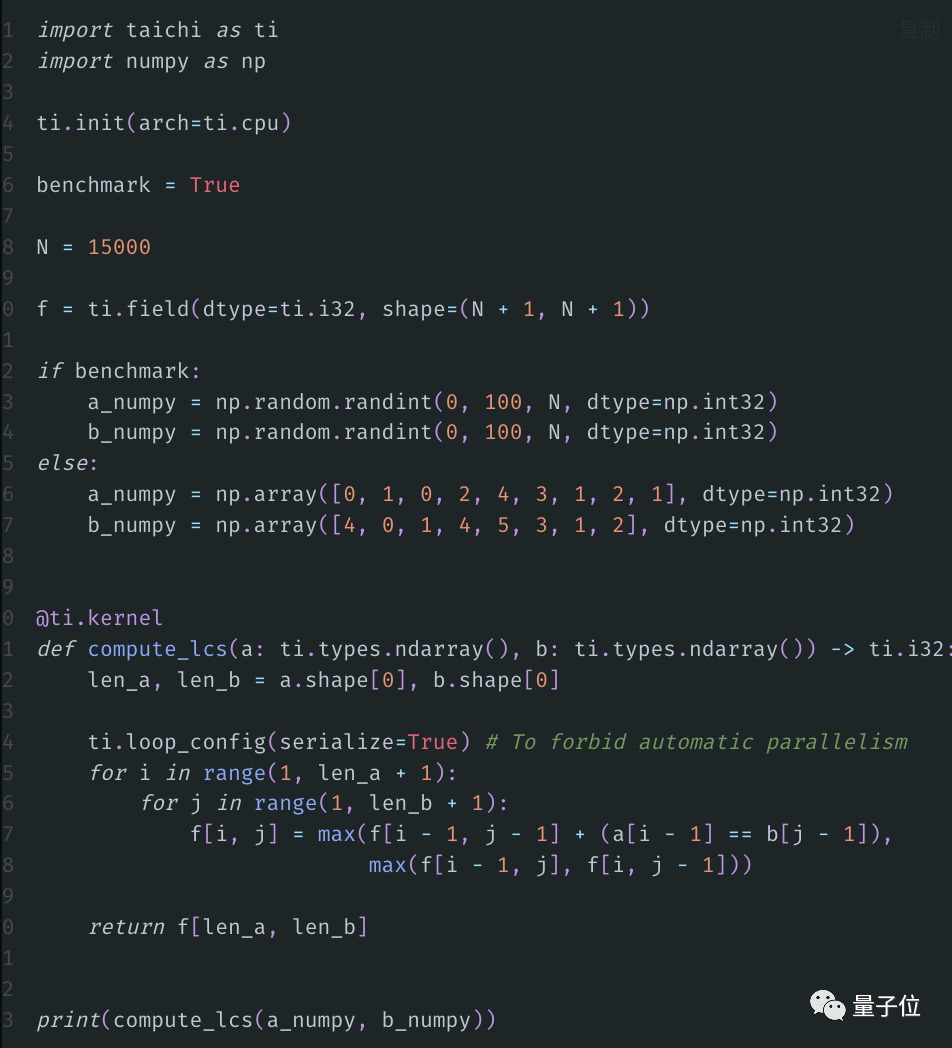
結果如下:

胡淵鳴電腦上的程序最快做到了0.9秒內完成,而換成用NumPy來實現,則需要476秒,差異達到了超500倍!
最后,我們再來一個不一樣的例子。
反應 - 擴散方程,效果驚人
自然界中,總有一些動物身上長著一些看起來無序但實則并非完全隨機的花紋。
圖靈機的發明者艾倫·圖靈是第一個提出模型來描述這種現象的人。
在該模型中,兩種化學物質(U和V)來模擬圖案的生成。這兩者之間的關系類似于獵物和捕食者,它們自行移動并有交互:
-
最初,U和V隨機分布在一個域上;
-
在每個時間步,它們逐漸擴散到鄰近空間;
-
當U和V相遇時,一部分U被V吞噬。因此,V的濃度增加;
-
為了避免U被V根除,我們在每個時間步添加一定百分比 (f) 的U并刪除一定百分比 (k) 的V。
上面這個過程被概述為“反應-擴散方程”:
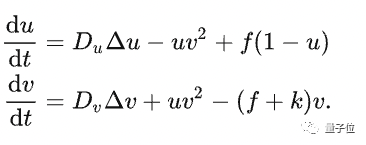
其中有四個關鍵參數:Du(U的擴散速度),Dv(V的擴散速度),f(feed的縮寫,控制U的加入)和k(kill的縮寫,控制V的去除)。
如果Taichi中實現這個方程,首先創建網格來表示域,用vec2表示每個網格中U, V的濃度值。
拉普拉斯算子數值的計算需要訪問相鄰網格。為了避免在同一循環中更新和讀取數據,我們應該創建兩個形狀相同的網格W×H×2。
每次從一個網格訪問數據時,我們將更新的數據寫入另一個網格,然后切換下一個網格。那么數據結構設計就是這樣:

一開始,我們將U在網格中的濃度設置為 1,并將V放置在50個隨機選擇的位置:

那么實際計算就可以用不到10行代碼完成:
@ti.kernel
defcompute(phase:int):
fori,jinti.ndrange(W,H):
cen=uv[phase,i,j]
lapl=uv[phase,i+1,j]+uv[phase,i,j+1]+uv[phase,i-1,j]+uv[phase,i,j-1]-4.0*cen
du=Du*lapl[0]-cen[0]*cen[1]*cen[1]+feed*(1-cen[0])
dv=Dv*lapl[1]+cen[0]*cen[1]*cen[1]-(feed+kill)*cen[1]
val=cen+0.5*tm.vec2(du,dv)
uv[1-phase,i,j]=val
在這里,我們使用整數相位(0或1)來控制我們從哪個網格讀取數據。
最后一步就是根據V的濃度對結果進行染色,就可以得到這樣一個效果驚人的圖案:?
?有趣的是,胡淵鳴介紹,即使V的初始濃度是隨機設置的,但每次都可以得到相似的結果。
而且和只能達到30fps左右的Numba實現比起來,Taichi實現由于可以選擇GPU作為后端,輕松超過了 300fps。
pip install即可安裝
看完上面三個例子,你這下相信了吧?
其實,Taichi就是一個嵌入在Python中的DSL(動態腳本語言),它通過自己的編譯器將被 @ti.kernel 裝飾的函數編譯到各種硬件上,包括CPU和GPU,然后進行高性能計算。
有了它,你無需再羨慕C++/CUDA的性能。
正如其名,Taichi就出自太極圖形胡淵鳴的團隊,現在你只需要用pip install就能安裝這個庫,并與其他Python庫進行交互,包括NumPy、Matplotlib和PyTorch等等。
當然,Taichi用起來和這些庫以及其他加速方法有什么差別,胡淵鳴也給出了詳細的優缺點對比。
審核編輯:湯梓紅
-
代碼
+關注
關注
30文章
4886瀏覽量
70249 -
python
+關注
關注
56文章
4825瀏覽量
86169 -
import
+關注
關注
0文章
15瀏覽量
2051
原文標題:胡淵鳴:import一個“太極”庫,讓Python代碼提速100倍!
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄





 工商網監
工商網監
評論