") 多模態(tài)圖像合成與編輯方法
多模態(tài)圖像合成與編輯方法
本篇綜述通過(guò)對(duì)現(xiàn)有的多模態(tài)圖像合成與編輯方法的歸納總結(jié),對(duì)該領(lǐng)域目前的挑戰(zhàn)和未來(lái)方向進(jìn)行了探討和分析。
近期 OpenAI 發(fā)布的 DALLE-2 和谷歌發(fā)布的 Imagen 等實(shí)現(xiàn)了令人驚嘆的文字到圖像的生成效果,引發(fā)了廣泛關(guān)注并且衍生出了很多有趣的應(yīng)用。而文字到圖像的生成屬于多模態(tài)圖像合成與編輯領(lǐng)域的一個(gè)典型任務(wù)。 近日,來(lái)自馬普所和南洋理工等機(jī)構(gòu)的研究人員對(duì)多模態(tài)圖像合成與編輯這一大領(lǐng)域的研究現(xiàn)狀和未來(lái)發(fā)展做了詳細(xì)的調(diào)查和分析。

論文地址:https://arxiv.org/pdf/2112.13592.pdf
項(xiàng)目地址:https://github.com/fnzhan/MISE

在第一章節(jié),該綜述描述了多模態(tài)圖像合成與編輯任務(wù)的意義和整體發(fā)展,以及本論文的貢獻(xiàn)與總體結(jié)構(gòu)。 在第二章節(jié),根據(jù)引導(dǎo)圖片合成與編輯的數(shù)據(jù)模態(tài),該綜述論文介紹了比較常用的視覺(jué)引導(dǎo)(比如 語(yǔ)義圖,關(guān)鍵點(diǎn)圖,邊緣圖),文字引導(dǎo),語(yǔ)音引導(dǎo),場(chǎng)景圖(scene graph)引導(dǎo)和相應(yīng)模態(tài)數(shù)據(jù)的處理方法以及統(tǒng)一的表示框架。 在第三章節(jié),根據(jù)圖像合成與編輯的模型框架,該論文對(duì)目前的各種方法進(jìn)行了分類,包括基于 GAN 的方法,自回歸方法,擴(kuò)散模型方法,和神經(jīng)輻射場(chǎng)(NeRF)方法。
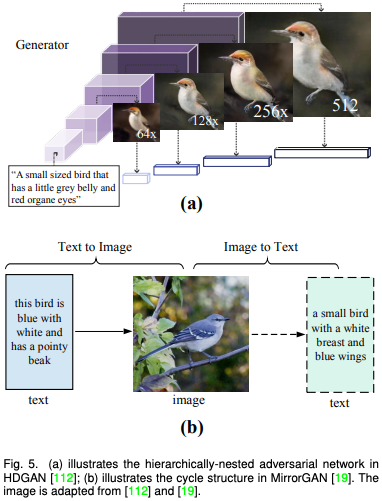
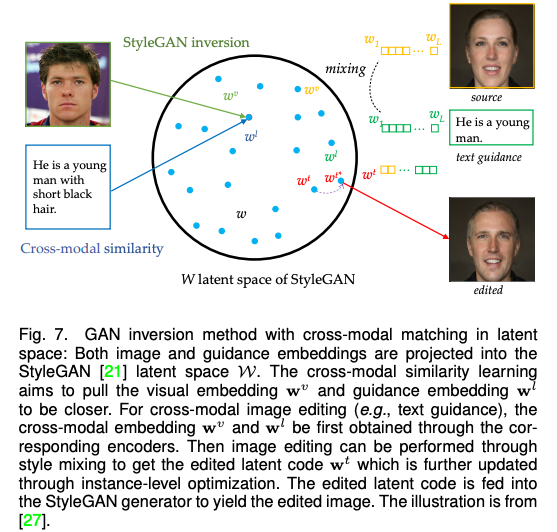
由于基于 GAN 的方法一般使用條件 GAN 和 無(wú)條件 GAN 反演,因此該論文將這一類別進(jìn)一步分為模態(tài)內(nèi)條件(例如語(yǔ)義圖,邊緣圖),跨模態(tài)條件(例如文字和語(yǔ)音),和 GAN 反演(統(tǒng)一模態(tài))并進(jìn)行了詳細(xì)描述。
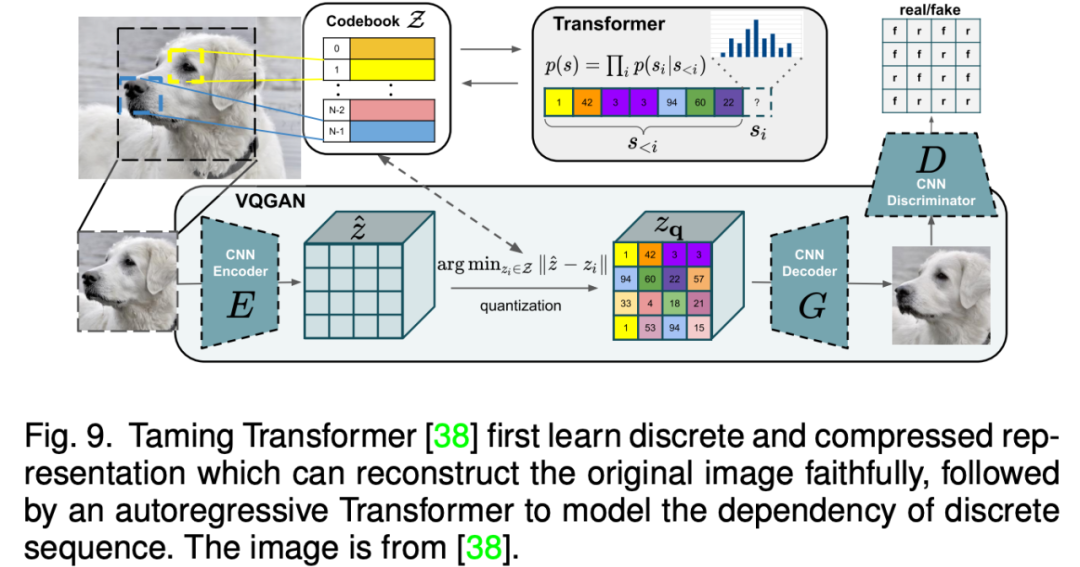
相比于基于 GAN 的方法,自回歸模型方法能夠更加自然的處理多模態(tài)數(shù)據(jù),以及利用目前流行的 Transformer 模型。自回歸方法一般先學(xué)習(xí)一個(gè)向量量化編碼器將圖片離散地表示為 token 序列,然后自回歸式地建模 token 的分布。由于文本和語(yǔ)音等數(shù)據(jù)都能表示為 token 并作為自回歸建模的條件,因此各種多模態(tài)圖片合成與編輯任務(wù)都能統(tǒng)一到一個(gè)框架當(dāng)中。
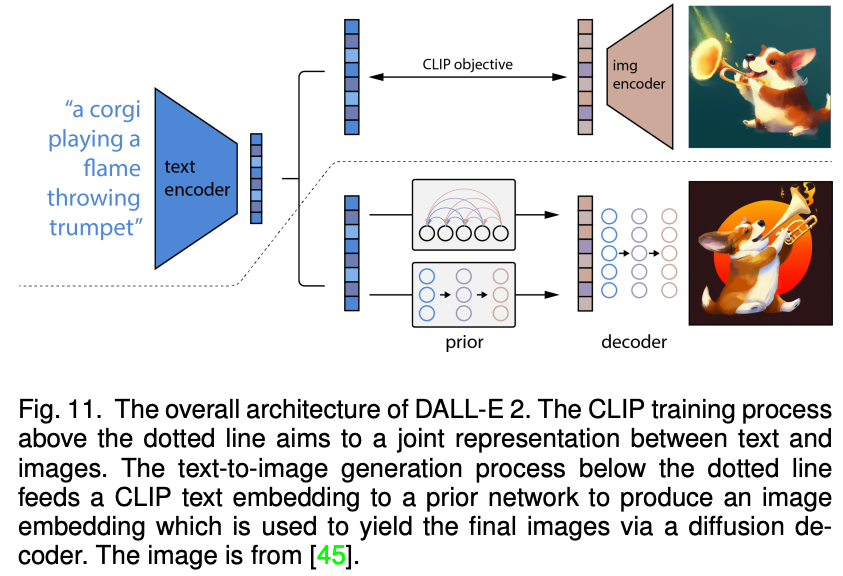
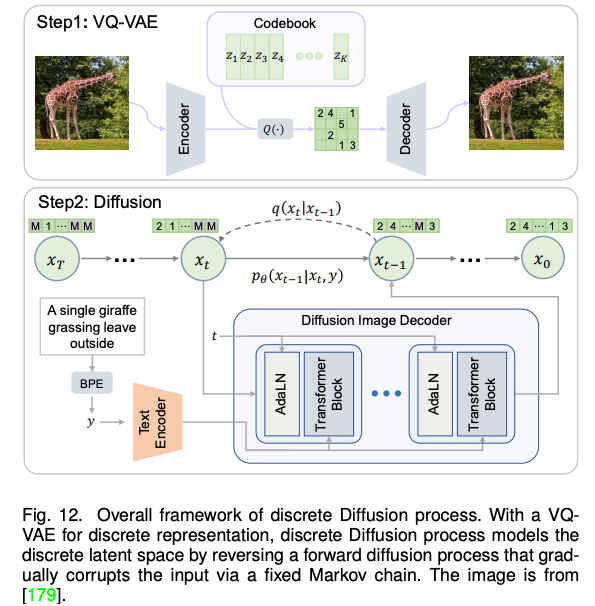
近期,火熱的擴(kuò)散模型也被廣泛應(yīng)用于多模態(tài)合成與編輯任務(wù)。例如效果驚人的 DALLE-2 和 Imagen 都是基于擴(kuò)散模型實(shí)現(xiàn)的。相比于 GAN,擴(kuò)散式生成模型擁有一些良好的性質(zhì),比如靜態(tài)的訓(xùn)練目標(biāo)和易擴(kuò)展性。該論文依據(jù)條件擴(kuò)散模型和預(yù)訓(xùn)練擴(kuò)散模型對(duì)現(xiàn)有方法進(jìn)行了分類與詳細(xì)分析。
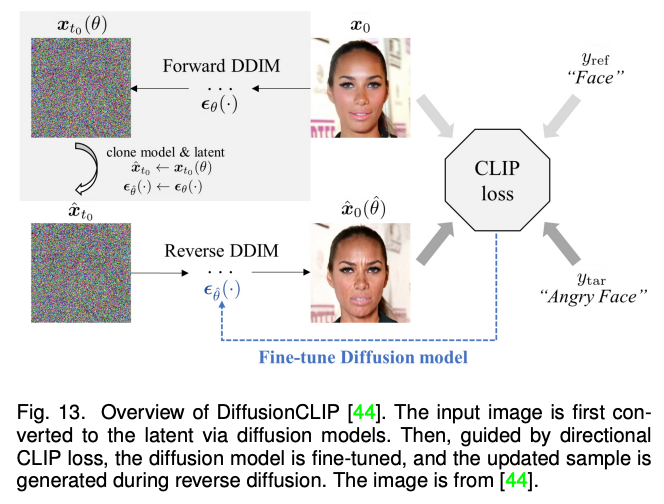
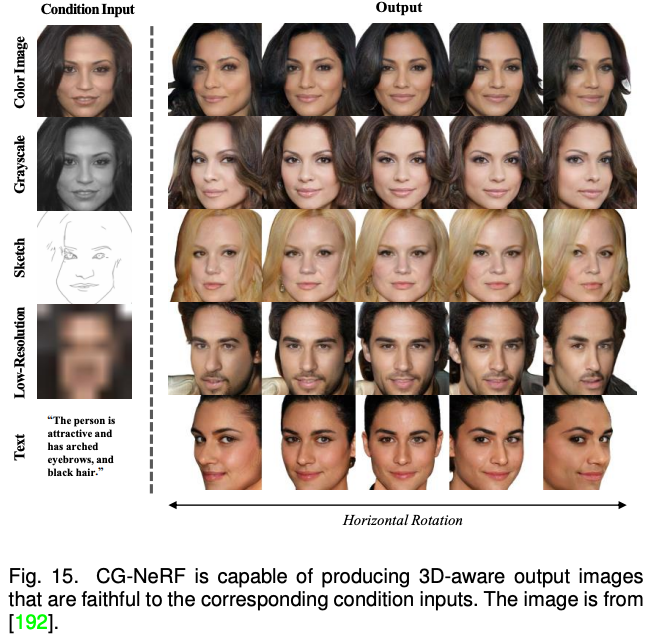
以上方法主要聚焦于 2D 圖像的多模態(tài)合成與編輯。近期隨著神經(jīng)輻射場(chǎng)(NeRF)的迅速發(fā)展,3D 感知的多模態(tài)合成與編輯也吸引了越來(lái)越多的關(guān)注。由于需要考慮多視角一致性,3D 感知的多模態(tài)合成與編輯是更具挑戰(zhàn)性的任務(wù)。本文針對(duì)單場(chǎng)景優(yōu)化 NeRF,生成式 NeRF 和 NeRF 反演的三種方法對(duì)現(xiàn)有工作進(jìn)行了分類與總結(jié)。 隨后,該綜述對(duì)以上四種模型方法的進(jìn)行了比較和討論。總體而言,相比于 GAN,目前最先進(jìn)的模型更加偏愛(ài)自回歸模型和擴(kuò)散模型。而 NeRF 在多模態(tài)合成與編輯任務(wù)的應(yīng)用為這個(gè)領(lǐng)域的研究打開(kāi)了一扇新的窗戶。
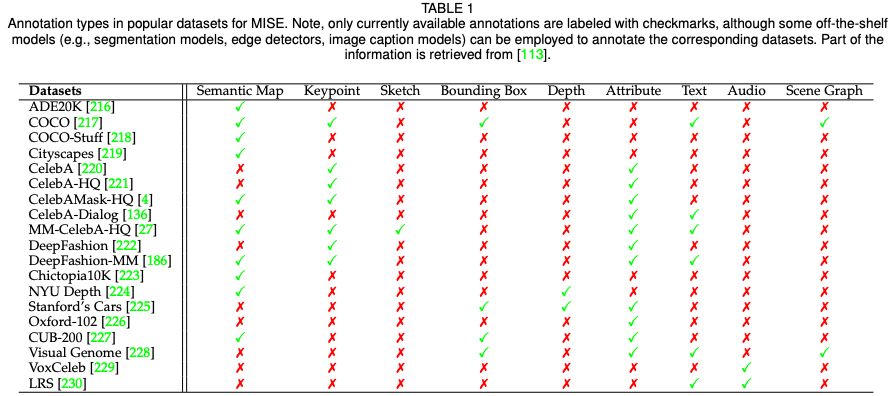
在第四章節(jié),該綜述匯集了多模態(tài)合成與編輯領(lǐng)域流行的數(shù)據(jù)集以及相應(yīng)的模態(tài)標(biāo)注,并且針對(duì)各模態(tài)典型任務(wù)(語(yǔ)義圖像合成,文字到圖像合成,語(yǔ)音引導(dǎo)圖像編輯)對(duì)當(dāng)前方法進(jìn)行了定量的比較。 在第五章節(jié),該綜述對(duì)此領(lǐng)域目前的挑戰(zhàn)和未來(lái)方向進(jìn)行了探討和分析,包括大規(guī)模的多模態(tài)數(shù)據(jù)集,準(zhǔn)確可靠的評(píng)估指標(biāo),高效的網(wǎng)絡(luò)架構(gòu),以及 3D 感知的發(fā)展方向。 在第六和第七章節(jié),該綜述分別闡述了此領(lǐng)域潛在的社會(huì)影響和總結(jié)了文章的內(nèi)容與貢獻(xiàn)。
-
谷歌
+關(guān)注
關(guān)注
27文章
6223瀏覽量
107569 -
數(shù)據(jù)
+關(guān)注
關(guān)注
8文章
7242瀏覽量
91042 -
圖像
+關(guān)注
關(guān)注
2文章
1092瀏覽量
41038
原文標(biāo)題:多模態(tài)圖像合成與編輯這么火,馬普所、南洋理工等出了份詳細(xì)綜述
文章出處:【微信號(hào):CVSCHOOL,微信公眾號(hào):OpenCV學(xué)堂】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄

基于多通道分類合成的SAR圖像分類研究
高分辨率合成孔徑雷達(dá)圖像的直線特征多尺度提取方法
基于超圖的多模態(tài)關(guān)聯(lián)特征處理方法
基于雙殘差超密集網(wǎng)絡(luò)的多模態(tài)醫(yī)學(xué)圖像融合方法

基于聯(lián)合壓縮感知的多模態(tài)目標(biāo)統(tǒng)一跟蹤方法

簡(jiǎn)述文本與圖像領(lǐng)域的多模態(tài)學(xué)習(xí)有關(guān)問(wèn)題
ImageBind:跨模態(tài)之王,將6種模態(tài)全部綁定!

用圖像對(duì)齊所有模態(tài),Meta開(kāi)源多感官AI基礎(chǔ)模型,實(shí)現(xiàn)大一統(tǒng)

VisCPM:邁向多語(yǔ)言多模態(tài)大模型時(shí)代

多模態(tài)大模型最全綜述來(lái)了!

探究編輯多模態(tài)大語(yǔ)言模型的可行性
大模型+多模態(tài)的3種實(shí)現(xiàn)方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論