") 簡述文本與圖像領域的多模態(tài)學習有關問題
簡述文本與圖像領域的多模態(tài)學習有關問題
來自:哈工大SCIR
本期導讀:近年來研究人員在計算機視覺和自然語言處理方向均取得了很大進展,因此融合了二者的多模態(tài)深度學習也越來越受到關注。本期主要討論結(jié)合文本和圖像的多模態(tài)任務,將從多模態(tài)預訓練模型中的幾個分支角度,簡述文本與圖像領域的多模態(tài)學習有關問題。
1. 引言
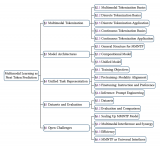
近年來,計算機視覺和自然語言處理方向均取得了很大進展。而融合二者的多模態(tài)深度學習也越來越受到關注,在基于圖像和視頻的字幕生成、視覺問答(VQA)、視覺對話、基于文本的圖像生成等方面研究成果顯著,下圖1展示了有關多模態(tài)深度學習的應用范疇。
在這些任務中,無論是文本還是語音,自然語言都起到了幫助計算機“理解”圖像內(nèi)容的關鍵作用,這里的“理解”指的是對齊語言中蘊含的語義特征與圖像中蘊含的圖像特征。本文主要關注于結(jié)合文本和圖像的多模態(tài)任務,將從多模態(tài)預訓練模型中的幾個分支來分析目前圖像與文本的多模態(tài)信息處理領域的有關問題。
2. 多模態(tài)預訓練模型
學習輸入特征的更好表示是深度學習的核心內(nèi)容。在傳統(tǒng)的NLP單模態(tài)領域,表示學習的發(fā)展已經(jīng)較為完善,而在多模態(tài)領域,由于高質(zhì)量有標注多模態(tài)數(shù)據(jù)較少,因此人們希望能使用少樣本學習甚至零樣本學習。最近兩年出現(xiàn)了基于Transformer結(jié)構的多模態(tài)預訓練模型,通過海量無標注數(shù)據(jù)進行預訓練,然后使用少量有標注數(shù)據(jù)進行微調(diào)即可。
多模態(tài)預訓練模型根據(jù)信息融合的方式可分為兩大類,分別是Cross-Stream類和Single-Stream類。
(1)Cross-Stream類模型是指將不同模態(tài)的輸入分別處理之后進行交叉融合,例如ViLBERT[1]。2019年Lu Jiasen等人將輸入的文本經(jīng)過文本Embedding層后被輸入到Transformer編碼器中提取上下文信息。
使用預訓練Faster R-CNN生成圖片候選區(qū)域提取特征并送入圖像Embedding層,然后將獲取好的文本和圖像表示通過Co-attention-transformer模塊進行交互融合,得到最后的表征。
(2)Single-Stream類模型將圖片、文本等不同模態(tài)的輸入一視同仁,在同一個模型進行融合,例如VL-BERT[2]。2020年,Su Weijie等人提出了VL-BERT,它采用transformer作為主干,將視覺和語言嵌入特征同時輸入模型。
3. 統(tǒng)一多模態(tài)模型
在之前的模型中,單模態(tài)數(shù)據(jù)集上訓練的模型只能做各自領域的任務,否則它們的表現(xiàn)會大幅下降。要想學習多模態(tài)模型必須圖文結(jié)合才行。這種多模態(tài)圖文對數(shù)據(jù)數(shù)據(jù)量少,獲取成本高。2021年,百度的Li Wei等人[3]提出的UNIMO模型,統(tǒng)一了單模態(tài)、多模態(tài)模型的訓練方式,既可以利用海量的單模態(tài)數(shù)據(jù),又能將多模態(tài)信號統(tǒng)一在一個語義空間內(nèi)促進理解。
UNIMO的核心網(wǎng)絡是Transformer,同時為圖像和文本輸入學習統(tǒng)一的語義表示。圖像和文本數(shù)據(jù)分別通過預訓練的Faster R-CNN和Bert進行特征提取和表示,多模態(tài)圖文對數(shù)據(jù)被轉(zhuǎn)換為圖像表示序列和文本表示序列的拼接。
這三種類型數(shù)據(jù)共享模型參數(shù),經(jīng)過多層注意力機制后得到圖像文本信息統(tǒng)一的語義表示,UNIMO結(jié)構如圖4所示。其訓練方式類似Bert, 此外論文還提出了一種跨模態(tài)對比學習的新預訓練方法。
在多模態(tài)任務上, UNIMO超過了諸如ViLBERT、VLP、UNITER、Oscar、Villa等最新的多模預訓練模型。而且在單模態(tài)任務上也取得了不錯的效果,如圖5(b)所示。
4. 視覺物體錨點模型
前面的幾個模型只是將圖像區(qū)域特征和文本特征連接起來作為輸入,并不參考任何對齊線索,利用Transformer的self-attention機制,讓模型自動學習整張圖像和文本的語義對齊方式。Oscar的作者[4]提出把物體用作圖像和文本語義層面上的錨點(Anchor Point),以簡化圖像和文本之間的語義對齊的學習任務。
使用Faster R-CNN等預訓練物體檢測器 ,將圖像表示為一組圖像區(qū)域特征,每個圖像區(qū)域特征分配一個物體標簽,同時使用預訓練后的BERT得到物體標簽的詞嵌入表示。
該模型在共享空間中顯式地將圖像和文本關聯(lián)在一起,物體則扮演圖像、文本語義對齊中錨點的角色。在此例中,由于視覺重疊區(qū)域,“狗”和“沙發(fā)”在圖像區(qū)域特征空間中相似,在單詞嵌入空間中有所差異。
經(jīng)過實驗測試,該模型的性能在多個任務上已經(jīng)超過SOTA模型。下表中 SoTAS、 SoTAB、和SoTAL分別表示小規(guī)模模型、與Bert-base和Bert-large規(guī)模相近的VLP模型。OscarB和OscarL分別是基于Bert-base和Bert-large訓練的Oscar模型。
5. 總結(jié)
目前多模態(tài)研究已經(jīng)取得了較大進展,但如果以構建能感知多模態(tài)信息并利用多模態(tài)信息跨越語義鴻溝的智能系統(tǒng)為目標,那么現(xiàn)在的研究仍處于初級階段,既面臨著挑戰(zhàn),也存在著機遇。在未來,多模態(tài)表示學習、多模態(tài)情感分析以及任務導向的大規(guī)模多模態(tài)人機交互系統(tǒng)等方向的發(fā)展值得我們關注。
Reference
[1] Lu J , Batra D , Parikh D , et al. ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks[J]。 2019.
[2] Su W , Zhu X , Y Cao, et al. VL-BERT: Pre-training of Generic Visual-Linguistic Representations[J]。 2019.
[3] Li W , Gao C , Niu G , et al. UNIMO: Towards Unified-Modal Understanding and Generation via Cross-Modal Contrastive Learning[J]。 2020.
[4] Li X , Yin X , Li C , et al. Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks[M]。 2020.
原文:李曉辰
編輯:jq
-
圖像
+關注
關注
2文章
1092瀏覽量
40982 -
計算機視覺
+關注
關注
9文章
1705瀏覽量
46532 -
深度學習
+關注
關注
73文章
5554瀏覽量
122410 -
自然語言處理
+關注
關注
1文章
626瀏覽量
13983
原文標題:多模態(tài)預訓練模型簡述
文章出處:【微信號:NLP_lover,微信公眾號:自然語言處理愛好者】歡迎添加關注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
移遠通信智能模組全面接入多模態(tài)AI大模型,重塑智能交互新體驗

移遠通信智能模組全面接入多模態(tài)AI大模型,重塑智能交互新體驗

?多模態(tài)交互技術解析
階躍星辰開源多模態(tài)模型,天數(shù)智芯迅速適配

2025年Next Token Prediction范式會統(tǒng)一多模態(tài)嗎

商湯日日新多模態(tài)大模型權威評測第一
一文理解多模態(tài)大語言模型——上






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論