") 使用NVIDIA Merlin庫(kù)構(gòu)建基于會(huì)話(huà)的建議
使用NVIDIA Merlin庫(kù)構(gòu)建基于會(huì)話(huà)的建議

推薦系統(tǒng)可以幫助您發(fā)現(xiàn)新產(chǎn)品并做出明智的決策。然而,在許多依賴(lài)于推薦的領(lǐng)域,如電子商務(wù)、新聞和流媒體服務(wù),用戶(hù)可能無(wú)法跟蹤,或者根據(jù)當(dāng)時(shí)的需求,用戶(hù)的口味可能會(huì)迅速變化。
基于會(huì)話(huà)的推薦系統(tǒng)是順序推薦的一個(gè)子領(lǐng)域,最近很受歡迎,因?yàn)樗鼈兛梢栽谌魏谓o定的時(shí)間點(diǎn)根據(jù)用戶(hù)的情況和偏好推薦項(xiàng)目。在這些領(lǐng)域中,捕捉用戶(hù)對(duì)項(xiàng)目的短期或上下文偏好很有幫助。
在本文中,我們將介紹基于會(huì)話(huà)的推薦任務(wù),該任務(wù)由 NVIDIA Merlin 平臺(tái)的 Transformers4Rec 庫(kù)支持。然后,我們展示了使用 Transformers4Rec 在幾行代碼中創(chuàng)建基于會(huì)話(huà)的推薦模型是多么容易,最后,我們展示了使用 NVIDIA Merlin 庫(kù)的端到端基于會(huì)話(huà)的推薦管道。
Transformers4Rec 庫(kù)功能
NVIDIA Merlin 團(tuán)隊(duì)于 ACM RecSys’21 發(fā)布,通過(guò)利用最先進(jìn)的 Transformers 體系結(jié)構(gòu),為順序和基于會(huì)話(huà)的推薦任務(wù)設(shè)計(jì)并公開(kāi)了 NVIDIA Merlin Transformers4Rec 庫(kù)。該庫(kù)可由研究人員擴(kuò)展,對(duì)從業(yè)者來(lái)說(shuō)很簡(jiǎn)單,在工業(yè)部署中又快速又可靠。
它利用了 擁抱面( HF )變壓器 庫(kù)中的 SOTA NLP 體系結(jié)構(gòu),可以在 RecSys 域中快速試驗(yàn)許多不同的 transformer 體系結(jié)構(gòu)和預(yù)訓(xùn)練方法。
Transformers4Rec 還幫助數(shù)據(jù)科學(xué)家、行業(yè)從業(yè)者和院士構(gòu)建推薦系統(tǒng),該系統(tǒng)可以利用同一會(huì)話(huà)中過(guò)去用戶(hù)交互的短序列,然后動(dòng)態(tài)建議用戶(hù)可能感興趣的下一個(gè)項(xiàng)目。
以下是 Transformers4Rec 庫(kù)的一些亮點(diǎn):
靈活性和效率: 構(gòu)建塊模塊化,與 vanilla PyTorc h 模塊和 TF Keras 層兼容。您可以創(chuàng)建自定義體系結(jié)構(gòu),例如,使用多個(gè)塔、多個(gè)頭/任務(wù)和損耗。 Transformers4Rec 支持多個(gè)輸入功能,并提供可配置的構(gòu)建塊,這些構(gòu)建塊可以輕松組合用于定制體系結(jié)構(gòu)。
與集成 HuggingFace Transformers : 使用最前沿的 NLP 研究,并為 RecSys 社區(qū)提供最先進(jìn)的 transformer 體系結(jié)構(gòu),用于順序和基于會(huì)話(huà)的推薦任務(wù)。
支持多種輸入功能: Transformers4Rec 支持使用任何類(lèi)型的順序表格數(shù)據(jù)的高頻變壓器。
與無(wú)縫集成 NVTabular 用于預(yù)處理和特征工程。
Production-ready: 導(dǎo)出經(jīng)過(guò)培訓(xùn)的模型以用于 NVIDIA Triton 推理服務(wù)器 在單個(gè)管道中進(jìn)行在線(xiàn)特征預(yù)處理和模型推理。
開(kāi)發(fā)您自己的基于會(huì)話(huà)的推薦模型
只需幾行代碼,就可以基于 SOTA transformer 體系結(jié)構(gòu)構(gòu)建基于會(huì)話(huà)的模型。下面的示例顯示了如何將強(qiáng)大的 XLNet transformer 體系結(jié)構(gòu)用于下一個(gè)項(xiàng)目預(yù)測(cè)任務(wù)。
正如您可能注意到的,使用 PyTorch 和 TensorFlow 構(gòu)建基于會(huì)話(huà)的模型的代碼非常相似,只有幾個(gè)不同之處。下面的代碼示例使用 Transformers4Rec API 使用 PyTorch 和 TensorFlow 構(gòu)建基于 XLNET 的推薦模型:
#from transformers4rec import torch as tr
from transformers4rec import tf as tr
from merlin_standard_lib import Schema schema = Schema().from_proto_text("")
max_sequence_length, d_model = 20, 320
# Define input module to process tabular input-features and to prepare masked inputs
input_module = tr.TabularSequenceFeatures.from_schema( schema, max_sequence_length=max_sequence_length, continuous_projection=64, aggregation="concat", d_output=d_model, masking="clm",
) # Define Next item prediction-task prediction_task = tr.NextItemPredictionTask(hf_format=True,weight_tying=True) # Define the config of the XLNet architecture
transformer_config = tr.XLNetConfig.build( d_model=d_model, n_head=8, n_layer=2,total_seq_length=max_sequence_length
)
# Get the PyT model
model = transformer_config.to_torch_model(input_module, prediction_task)
# Get the TF model
#model = transformer_config.to_tf_model(input_module, prediction_task)
為了證明該庫(kù)的實(shí)用性和 transformer 體系結(jié)構(gòu)在用戶(hù)會(huì)話(huà)的下一次點(diǎn)擊預(yù)測(cè)中的適用性, NVIDIA Merlin 團(tuán)隊(duì)使用 Transformers4Rec 贏得了兩次基于會(huì)話(huà)的推薦比賽:
2021 WSDM WebTour 研討會(huì)挑戰(zhàn)賽 通過(guò)預(yù)訂。 com ( NVIDIA solution )
Coveo 2021 SIGIR 電子商務(wù)研討會(huì)數(shù)據(jù)挑戰(zhàn)賽 ( NVIDIA solution )
使用 NVIDIA Merlin 構(gòu)建端到端、基于會(huì)話(huà)的推薦管道的步驟
圖 3 顯示了使用 NVIDIA Merlin Transformers4Rec 的基于會(huì)話(huà)的推薦管道的端到端管道。
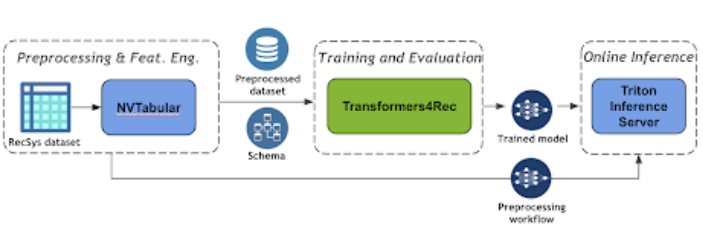
圖 3 :基于端到端會(huì)話(huà)的推薦管道
NVTabular 是一個(gè)用于表格數(shù)據(jù)的功能工程和預(yù)處理庫(kù),旨在快速、輕松地操作用于培訓(xùn)大規(guī)模推薦系統(tǒng)的 TB 級(jí)數(shù)據(jù)集。它提供了一個(gè)高級(jí)抽象,以簡(jiǎn)化代碼,并使用 RAPIDS cuDF library。
NVTabular 支持深度學(xué)習(xí) (DL) 模型所需的不同特征工程轉(zhuǎn)換,例如分類(lèi)編碼和數(shù)值特征歸一化。它還支持特征工程和生成順序特征。有關(guān)支持的功能的更多信息,請(qǐng)參見(jiàn)此處。
在下面的代碼示例中,您可以很容易地看到如何創(chuàng)建一個(gè) NVTabular 預(yù)處理工作流,以便在會(huì)話(huà)級(jí)別對(duì)交互進(jìn)行分組,并按時(shí)間對(duì)交互進(jìn)行排序。最后,您將獲得一個(gè)已處理的數(shù)據(jù)集,其中每一行表示一個(gè)用戶(hù)會(huì)話(huà)以及該會(huì)話(huà)的相應(yīng)順序特征。
import nvtabular as nvt
# Define Groupby Operator
features = ['session_id', 'item_id', 'timestamp', 'category']
groupby_features = features >> nvt.ops.Groupby( groupby_cols=["session_id"], sort_cols=["timestamp"], aggs={ 'item_id': ["list", "count"], 'category': ["list"], 'timestamp': ["first"], }, name_sep="-") # create dataset object
dataset = nvt.Dataset(interactions_df)
workflow = nvt.Workflow(groupby_features)
# Apply the preprocessing workflow on the dataset sessions_gdf = workflow.transform(dataset).compute()
使用 Triton 推理服務(wù)器 簡(jiǎn)化人工智能模型在生產(chǎn)中的大規(guī)模部署。 Triton 推理服務(wù)器使您能夠部署和服務(wù)您的模型進(jìn)行推理。它支持許多不同的機(jī)器學(xué)習(xí)框架,例如 TensorFlow 和 Pytork 。
機(jī)器學(xué)習(xí)( ML )管道的最后一步是將 ETL 工作流和經(jīng)過(guò)訓(xùn)練的模型部署到產(chǎn)品中進(jìn)行推理。在生產(chǎn)設(shè)置中,您希望像在培訓(xùn)( ETL )期間那樣轉(zhuǎn)換輸入數(shù)據(jù)。例如,在使用 ML / DL 模型進(jìn)行預(yù)測(cè)之前,應(yīng)該對(duì)連續(xù)特征使用相同的規(guī)范化統(tǒng)計(jì)信息,并使用相同的映射將類(lèi)別編碼為連續(xù) ID 。
幸運(yùn)的是, NVIDIA Merlin 框架有一個(gè)集成機(jī)制,可以將預(yù)處理工作流(用 NVTABLAR 建模)和 PyTorch 或 TensorFlow 模型作為 NVIDIA Triton 推理的集成模型進(jìn)行部署。集成模型保證對(duì)原始輸入應(yīng)用相同的轉(zhuǎn)換。
下面的代碼示例展示了使用 NVIDIA Merlin 推理 API 函數(shù)創(chuàng)建集成配置文件,然后將模型提供給 TIS 是多么容易。
import tritonhttpclient
import nvtabular as nvt workflow = nvt.Workflow.load("") from nvtabular.inference.triton import export_tensorflow_ensemble as export_ensemble
#from nvtabular.inference.triton import export_pytorch_ensemble as export_ensemble
export_ensemble( model, workflow, name="", model_path="", label_columns=["
只需幾行代碼,就可以為 NVIDIA PyTorch 推理服務(wù)器提供 NVTabular 工作流、經(jīng)過(guò)培訓(xùn)的 Triton 或 TensorFlow 模型以及集成模型,以便執(zhí)行端到端的模型部署。 使用 NVIDIA Merlin 推理 API ,您可以將原始數(shù)據(jù)集作為請(qǐng)求(查詢(xún))發(fā)送到服務(wù)器,然后從服務(wù)器獲取預(yù)測(cè)結(jié)果。
本質(zhì)上, NVIDIA Merlin 推理 API 使用 NVIDIA Triton ensembling 特性創(chuàng)建模型管道。 NVIDIA Triton ensemble 表示一個(gè)或多個(gè)模型的管道以及這些模型之間輸入和輸出張量的連接。
結(jié)論
在這篇文章中,我們向您介紹了 NVIDIA Merlin Transformers4Rec ,這是一個(gè)用于順序和基于會(huì)話(huà)的推薦任務(wù)的庫(kù),它與 NVIDIA NVTabular 和 NVIDIA Triton 推理服務(wù)器無(wú)縫集成,為此類(lèi)任務(wù)構(gòu)建端到端的 ML 管道。
關(guān)于作者
Ronay Ak 是 NVIDIA RAPIDS 團(tuán)隊(duì)的數(shù)據(jù)科學(xué)家。
GabrielMoreira 是 NVIDIA ( NVIDIA ) Merlin 團(tuán)隊(duì)的高級(jí)研究員,致力于推薦系統(tǒng)的深度學(xué)習(xí),這是他的博士學(xué)位的重點(diǎn)。他曾擔(dān)任首席數(shù)據(jù)科學(xué)家和軟件工程師多年。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5304瀏覽量
106323 -
API
+關(guān)注
關(guān)注
2文章
1605瀏覽量
63988
發(fā)布評(píng)論請(qǐng)先 登錄
NVIDIA AI技術(shù)助力歐洲醫(yī)療健康行業(yè)發(fā)展
自己寫(xiě)庫(kù):構(gòu)建庫(kù)函數(shù)雛形

借助NVIDIA技術(shù)加速半導(dǎo)體芯片制造
NVIDIA推出NVLink Fusion技術(shù)
利用NVIDIA技術(shù)構(gòu)建從數(shù)據(jù)中心到邊緣的智慧醫(yī)院解決方案
ServiceNow攜手NVIDIA構(gòu)建150億參數(shù)超級(jí)助手
企業(yè)使用NVIDIA NeMo微服務(wù)構(gòu)建AI智能體平臺(tái)
ZXUN xGW會(huì)話(huà)數(shù)不均衡的故障分析
MCUXpresso_24.12.148/FRDM-K22F調(diào)試會(huì)話(huà)啟動(dòng)速度非常慢,怎么解決?
如何使用flex-builder構(gòu)建aruco庫(kù)?
NVIDIA Omniverse Kit 107的安裝部署步驟

HarmonyOS NEXT 原生應(yīng)用/元服務(wù)-DevEco Profiler會(huì)話(huà)區(qū)
簡(jiǎn)述NVIDIA Isaac的重要更新

常用PCB天線(xiàn)庫(kù),天線(xiàn)布局,天線(xiàn)選型建議和天線(xiàn)匹配初始值建議
使用NVIDIA JetPack 6.0和YOLOv8構(gòu)建智能交通應(yīng)用





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論