 單個CNN就能夠在多個數據集上實現SOTA
單個CNN就能夠在多個數據集上實現SOTA
在 VGG、U-Net、TCN 網絡中... CNN 雖然功能強大,但必須針對特定問題、數據類型、長度和分辨率進行定制,才能發揮其作用。我們不禁會問,可以設計出一個在所有這些網絡中都運行良好的單一 CNN 嗎? 本文中,來自阿姆斯特丹自由大學、阿姆斯特丹大學、斯坦福大學的研究者提出了 CCNN,單個 CNN 就能夠在多個數據集(例如 LRA)上實現 SOTA !

- 論文地址:https://arxiv.org/pdf/2206.03398.pdf
- 代碼地址:https://github.com/david-knigge/ccnn
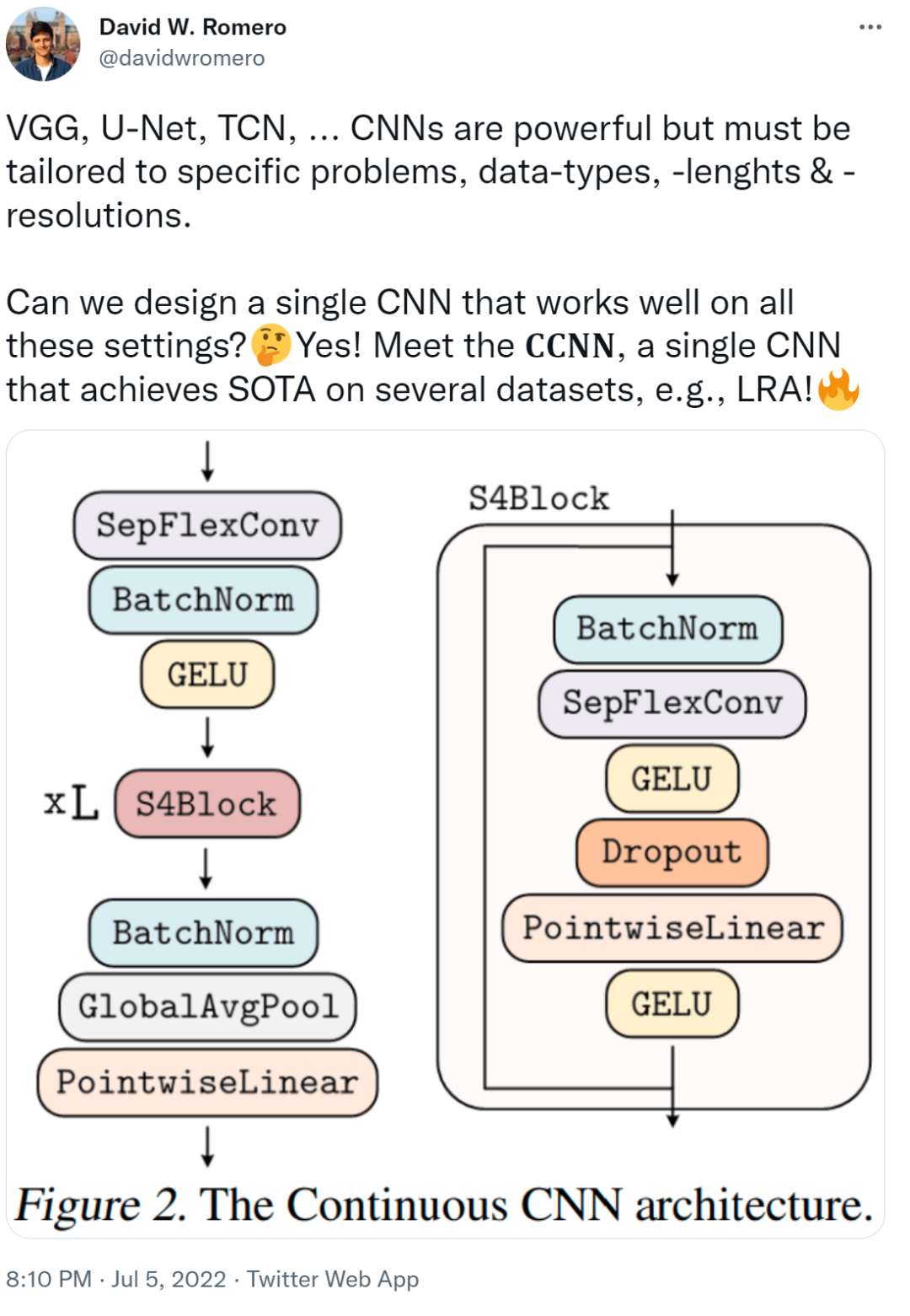
- 該研究提出 Continuous CNN(CCNN):一個簡單、通用的 CNN,可以跨數據分辨率和維度使用,而不需要結構修改。CCNN 在序列 (1D)、視覺 (2D) 任務、以及不規則采樣數據和測試時間分辨率變化的任務上超過 SOTA;
- 該研究對現有的 CCNN 方法提供了幾種改進,使它們能夠匹配當前 SOTA 方法,例如 S4。主要改進包括核生成器網絡的初始化、卷積層修改以及 CNN 的整體結構。
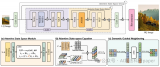
 作為核生成器網絡,同時將卷積核參數化為連續函數。該網絡將坐標
作為核生成器網絡,同時將卷積核參數化為連續函數。該網絡將坐標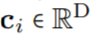 映射到該位置的卷積核值:
映射到該位置的卷積核值: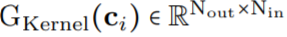 (圖 1a)。通過將 K 個坐標
(圖 1a)。通過將 K 個坐標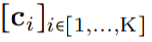 的向量通過 G_Kernel,可以構造一個大小相等的卷積核 K,即
的向量通過 G_Kernel,可以構造一個大小相等的卷積核 K,即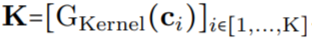 。隨后,在輸入信號
。隨后,在輸入信號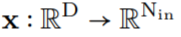 和生成的卷積核
和生成的卷積核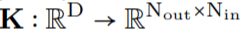 之間進行卷積運算,以構造輸出特征表示
之間進行卷積運算,以構造輸出特征表示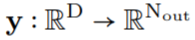 ,即
,即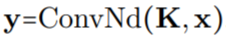 。
。
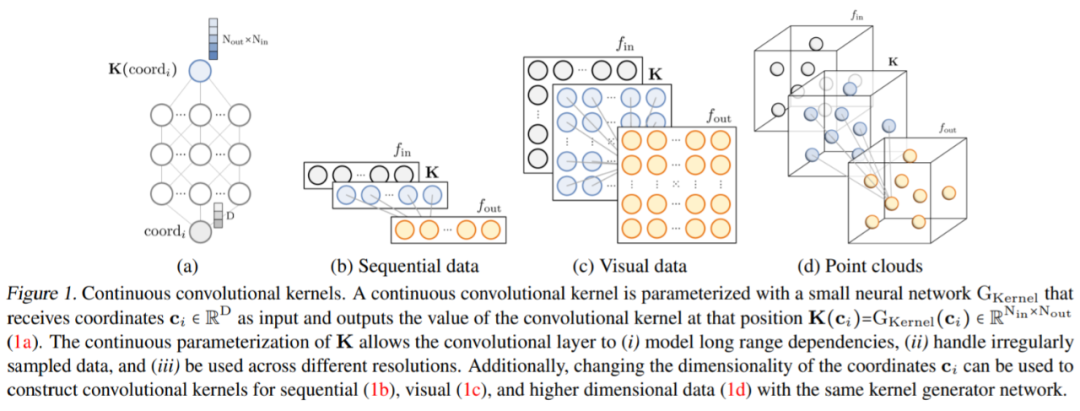
任意數據維度的一般操作。通過改變輸入坐標 c_i 的維數 D,核生成器網絡 G_Kernel 可用于構造任意維數的卷積核。因此可以使用相同的操作來處理序列 D=1、視覺 D=2 和更高維數據 D≥3。 不同輸入分辨率的等效響應。如果輸入信號 x 有分辨率變化,例如最初在 8KHz 觀察到的音頻現在在 16KHz 觀察到,則與離散卷積核進行卷積以產生不同的響應,因為核將在每個分辨率下覆蓋不同的輸入子集。另一方面,連續核是分辨率無關的,因此無論輸入的分辨率如何,它都能夠識別輸入。 當以不同的分辨率(例如更高的分辨率)呈現輸入時,通過核生成器網絡傳遞更精細的坐標網格就足夠了,以便以相應的分辨率構造相同的核。對于以分辨率 r (1) 和 r (2) 采樣的信號 x 和連續卷積核 K,兩種分辨率下的卷積大約等于與分辨率變化成比例的因子:
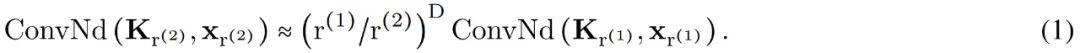
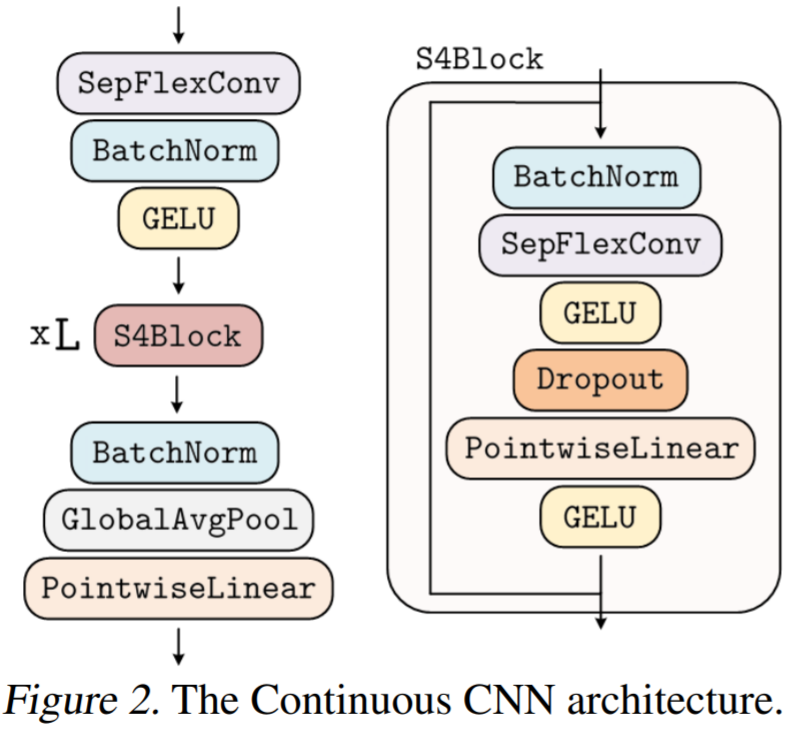
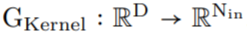 生成的核計算的,之后是從 N_in 到 N_out 進行逐點卷積。這種變化允許構建更廣泛的 CCNN—— 從 30 到 110 個隱藏通道,而不會增加網絡參數或計算復雜度。
生成的核計算的,之后是從 N_in 到 N_out 進行逐點卷積。這種變化允許構建更廣泛的 CCNN—— 從 30 到 110 個隱藏通道,而不會增加網絡參數或計算復雜度。正確初始化核生成器網絡 G_Kernel。該研究觀察到,在以前的研究中核生成器網絡沒有正確初始化。在初始化前,人們希望卷積層的輸入和輸出的方差保持相等,以避免梯度爆炸和消失,即 Var (x)=Var (y)。因此,卷積核被初始化為具有方差 Var (K)=gain^2 /(in channels ? kernel size) 的形式,其增益取決于所使用的非線性。 然而,神經網絡的初始化使輸入的 unitary 方差保留在輸出。因此,當用作核生成器網絡時,標準初始化方法導致核具有 unitary 方差,即 Var (K)=1。結果,使用神經網絡作為核生成器網絡的 CNN 經歷了與通道?內核大小成比例的特征表示方差的逐層增長。例如,研究者觀察到 CKCNNs 和 FlexNets 在初始化時的 logits 大約為 1e^19。這是不可取的,這可能導致訓練不穩定和需要低學習率。 為了解決這個問題,該研究要求 G_Kernel 輸出方差等于 gain^2 /(in_channels?kernel_size)而不是 1。他們通過、
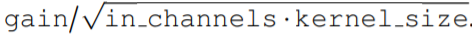 重新加權核生成器網絡的最后一層。因此,核生成器網絡輸出的方差遵循傳統卷積核的初始化,而 CCNN 的 logits 在初始化時呈現單一方差。
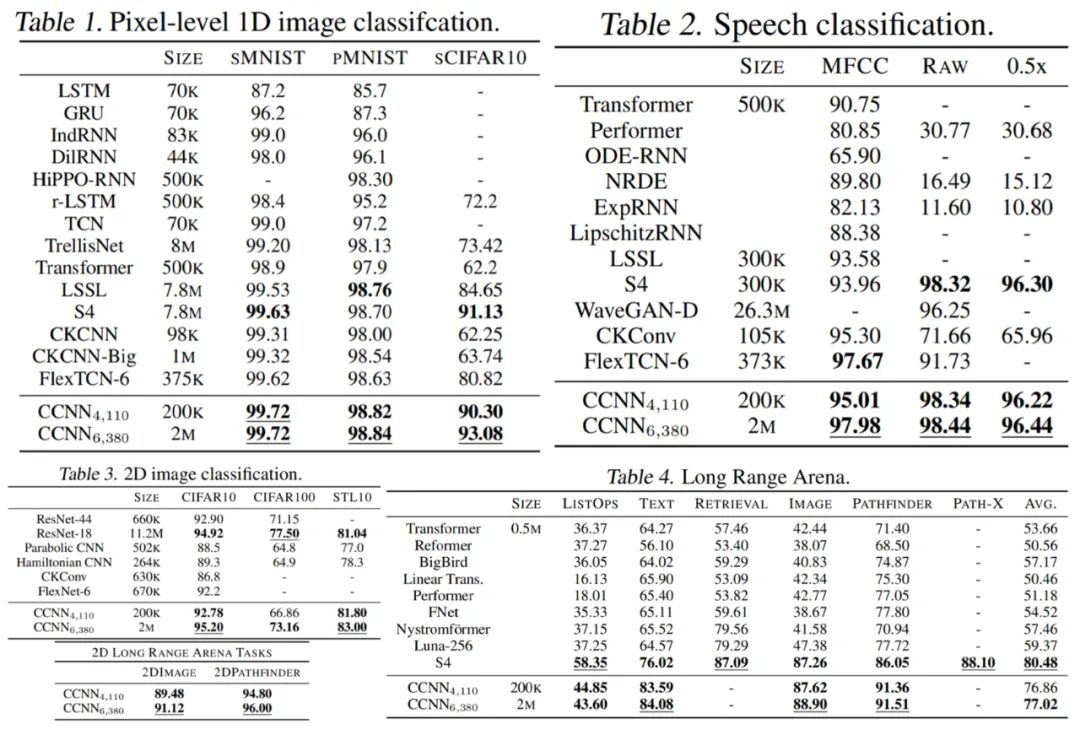
重新加權核生成器網絡的最后一層。因此,核生成器網絡輸出的方差遵循傳統卷積核的初始化,而 CCNN 的 logits 在初始化時呈現單一方差。實驗結果 如下表 1-4 所示,CCNN 模型在所有任務中都表現良好。 首先是 1D 圖像分類 CCNN 在多個連續基準上獲得 SOTA,例如 Long Range Arena、語音識別、1D 圖像分類,所有這些都在單一架構中實現的。CCNN 通常比其他方法模型更小架構更簡單。 然后是 2D 圖像分類:通過單一架構,CCNN 可以匹配并超越更深的 CNN。
聲明:本文內容及配圖由入駐作者撰寫或者入駐合作網站授權轉載。文章觀點僅代表作者本人,不代表電子發燒友網立場。文章及其配圖僅供工程師學習之用,如有內容侵權或者其他違規問題,請聯系本站處理。
舉報投訴
-
架構
+關注
關注
1文章
527瀏覽量
25850 -
深度學習
+關注
關注
73文章
5554瀏覽量
122474 -
cnn
+關注
關注
3文章
354瀏覽量
22627
原文標題:解決CNN固有缺陷, CCNN憑借單一架構,實現多項SOTA
文章出處:【微信號:CVSCHOOL,微信公眾號:OpenCV學堂】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
熱點推薦
想選擇一款能夠實現多個通道數據采集的ADC,求推薦
各位專家好!這邊想選擇一款能夠實現多個通道數據采集的ADC,由于對通道間的幅度和相位一致性要求較高,最好可以嚴格控制各通道之間的同步,要求單個
發表于 01-24 08:28
Mamba入局圖像復原,達成新SOTA
MambaIRv2,更高性能、更高效率!另外還有ACM MM 2024上的Freqmamba方法,在圖像去雨任務中取得了SOTA性能! 顯然,這種基于Mamba的方法在圖像復原領域,比
ADS131A04如果想實現多個設備的同步觸發采樣,應該如何實現呢?
在ADS131A04的使用上,異步模式,目前正常的數據采集都沒問題,但是我們希望對多個使用ADS131A04的設備進行同步觸發采樣,在收到一個觸發信號之后,
發表于 12-04 07:13
在單個C2000?MCU上使用FCL和SFRA進行雙軸電機控制
電子發燒友網站提供《在單個C2000?MCU上使用FCL和SFRA進行雙軸電機控制.pdf》資料免費下載
發表于 09-14 09:40
?0次下載

CISC(復雜指令集)與RISC(精簡指令集)的區別
的例子如果要在RISC架構上實現,將ADDRA, ADDRB中的數據讀入寄
存器,相乘和將結果寫回內存的操作都必須由軟件來實現,比如:MOV A, ADDRA; MOV B, ADDR
發表于 07-30 17:21
請問如何使用AT CIPSEND或AT CIPSENDBUF發送多個數據包?
我可以使用 AT CIPSEND 發送單個數據包。但是我必須發送一系列二進制數據包。如何使用AT CISEND或AT CIPSENDBUF發送多個數據包,什么是正確的算法?
到目前為止,我嘗試
發表于 07-15 07:37
20個數據可以訓練神經網絡嗎
當然可以,20個數據點對于訓練一個神經網絡來說可能非常有限,但這并不意味著它們不能用于訓練。實際上,神經網絡可以訓練在非常小的數據集
CNN在多個領域中的應用
,通過多層次的非線性變換,能夠捕捉到數據中的隱藏特征;而卷積神經網絡(CNN),作為神經網絡的一種特殊形式,更是在圖像識別、視頻處理等領域展現出了卓越的性能。本文旨在深入探究深度學習、
CNN的定義和優勢
CNN是模型還是算法的問題,實際上它兼具了兩者的特性,但更側重于作為一種模型存在。本文將從CNN的定義、結構、原理、應用等多個方面進行深入探討,旨在全面解析
如何利用CNN實現圖像識別
卷積神經網絡(CNN)是深度學習領域中一種特別適用于圖像識別任務的神經網絡結構。它通過模擬人類視覺系統的處理方式,利用卷積、池化等操作,自動提取圖像中的特征,進而實現高效的圖像識別。本文將從CNN的基本原理、構建過程、訓練策略以
cnn卷積神經網絡三大特點是什么
(Local Connectivity) 局部連接是CNN的核心特點之一,它允許網絡在處理圖像時只關注局部區域的特征。與傳統的全連接神經網絡不同,CNN的卷積層只對輸入數據的局部區域進
卷積神經網絡cnn模型有哪些
(Convolutional Layer) 卷積層是CNN的核心,用于提取圖像的局部特征。卷積操作通過滑動窗口(濾波器或卷積核)在輸入數據上進行計算,生成特征圖(Feature Map)。卷積核的權重在訓練





 工商網監
工商網監
評論