 《基于時間序列數據進行有效報警》的實踐總結
《基于時間序列數據進行有效報警》的實踐總結
本文可以看做是對《SRE》一書第10章《基于時間序列數據進行有效報警》的實踐總結。 Prometheus是一款開源的業務監控軟件,可以看作是Google內部監控系統 Borgmon 的一個(非官方)實現。 本文會介紹我近期使用Prometheus構建的一套完整的,可用于中小規模(小于500節點)的半自動化(少量人工操作)監控系統方案。
主動監控
監控是運維系統的基礎,我們衡量一個公司/部門的運維水平,看他們的監控系統就可以了。 監控手段一般可以分為三種:
主動監控:業務上線前,按照運維制定的標準,預先埋點。具體的實現方式又有多種,可能通過日志、向本地 Agent 上報、提供 REST API 等。
被動監控:通常是對主動監控的補充,從外圍進行黑盒監控,通過主動探測服務的功能可用性來進行監控。比如定期ping業務端口。
旁路監控:主動監控和被動監控,通常還是都在內部進行的監控,內部運行平穩也不能保證用戶的體驗都是正常的(比如用戶網絡出問題),所以仍然需要通過輿情監控、第三方監控工具等的數據來間接的監控真實的服務質量。
主動監控是最理想的方案,后兩種主要用作補充,本文只關注主動監控。 監控實際是一個端到端的體系(基礎設施-服務器-業務-用戶體驗),本文只關注業務級別的主動監控。
Prometheus
為什么選擇Prometheus而不是其它TSDB實現(如InfluxDB)?主要是因為Prometheus的核心功能,查詢語言 PromQL,它更像一種可編程計算器,而不是其那么像 SQL,也意味著 PromQL 可以近乎無限之組合出各種查詢結果。 比如,我們有一個http服務,監控項http_requests_total用于統計請求次數。某一組監控數據可能是這個樣子:
http_requests_total{instance="1.1.1.1:80",job="cluster1",location="/a"} 100http_requests_total{instance="1.1.1.1:80", job="cluster1", location="/b"} 110http_requests_total{instance="1.1.1.2:80", job="cluster2", location="/b"} 100http_requests_total{instance="1.1.1.3:80", job="cluster3", location="/c"} 110 這里有3個標簽,分別對應抓取的實例,所屬的 Job(一般我用集群名),訪問路徑(你可以理解為Nginx的location),Prometheus多維數據模型意味著我們可以在任意一個或多個維度進行計算:
如果你想統計單機qps,sum(rate(http_requests_total[1m])) by (instance)
如果想用統計每個集群每個不同 location 的 path 的 qps,sum(rate(http_requests_total[1m])) by (job, path),PromQL會依據標簽job-path的值聚合出結果。
除了PromQL,豐富的數據類型可以提供更有意義的監控項:
Counter(計數器):標識單調遞增的數據,比如接口訪問次數。
Gauge(刻度):當前瞬時的一個狀態,可能增加,也可能減小,比如CPU使用率,平均延時等等。
Historgram(直方圖):用于統計數據的分布,比如95 percentile latency。
大部分監控項都可以使用Counter來實現,少部分使用Gauge和Histogram,其中Histogram在服務端計算是相當費CPU的,所以也沒要導出太多Histogram數據。 最后,Prometheus采用PULL模型的實時抓取存儲計算,主動去抓取監控實例數據,相比于PUSH模型對業務侵入更低,相比于基于log的離線統計則更實時,而監控實例只需提供一個文本格式的/metrics接口也更容易debug。
服務框架的改造
筆者所在團隊使用統一的服務框架來規范項目開發并有效降低了開發難度。 這里先介紹下我們的服務框架:
類似于 Nginx 的多進程架構(master/worker),但同時也支持多線程的事件循環編程模型
支持多種接入協議(HTTP,Thrift,PB等),但主流是HTTP
業務通過 Module 來加載進框架執行(類似 Nginx 的 module,但更簡單)
提供純異步的下游訪問 API
為了使服務框架可以導出內部監控項,主要涉及幾方面的工作:
提供基礎數據類型
目前并沒有官方的Prometheus Client Library,幾種開源實現也都不太符合框架的需求。目前實現了支持多線程多進程的Counter和Histogram(除了初始化之外,更新操作都是無鎖的),而Gauge由于多進程場景有的情況是無法聚合監控數據的(沒用統一的聚合方法,并不一定都可以相加),所以沒有提供具體實現
基礎數據要有類似注冊表的功能,方便自動導出數據到/metrics接口
在服務框架埋點
要足夠靈活,將容易變化的信息通過標簽來表達。 比如一個web服務可能有echo,date兩個location,如果要統計它們qps,不要定義echo_requests_total,date_requests_total兩個不同名字的 metrics,而應該定義一個名為http_requests_total的 metrics,通過標簽location(分別為echo/date)來區分,這樣再增加/減少接口是不需要改代碼的
理想情況是業務幾乎為各種通信功能自行埋點,所以內置埋點要將常用監控項都要覆蓋到(QPS,Latency,Error Ratio)
數據的抓取與展現
具備導出能力后,就可以通過Prometheus 進行抓取了,但還有幾個小坑: 用戶定義的metrics名字,可能是不符合Prometheus規范的,而遇到一條不合法的數據,Prometheus就會停止抓取,所以導出數據時要先做一遍過濾和改寫 要控制導出數據規模,一些只對單機監控有意義的數據可以不導出(框架有針對單機的監控頁面) 在使用 Prometheus 時,也有幾個地方要注意: Prometheus即是一個CPU密集型(查詢)也是一個IO密集型(數據落地)的,CPU數量是多多益善,內存越大越好(來緩存抓取的數據,所以應該減少不必要的業務數據導出),盡量要使用SSD(這個很關鍵!),因為一旦Prometheus的內存使用量達到閾值會停止抓取數據!這個停止抓取的時間,至少是分鐘級,甚至是無法恢復!所以只要有條件就要用SSD。 Prometheus號稱支持 reload,但目測不是很好用,比如你修改了告警規則文件,重載之后,新舊告警規則似乎會一起計算執行…. Prometheus本身也提供圖形界面,但是很簡陋:
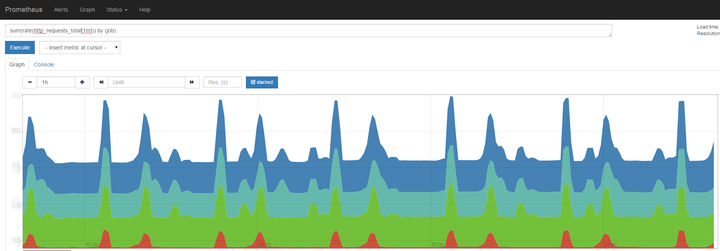
通常還是使用Grafana來展示監控數據。
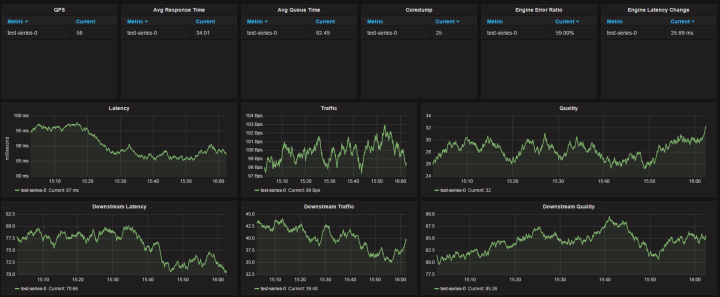
因為是統一的業務框架,統一的監控指標,所以 Grafana 的 Dashboard 很容易統一配置:
我沒有找到將默認模板打包進 Grafana 的方法,只能迂回的創建了一個新的Grafana Plugin,在啟動之后,每個業務實例只需要啟動下這個插件,然后配置一個默認的 Prometheus 數據源,就可以使用統一的監控 Dashboard
Dashboard 分為3行
第一行展示實時的 QPS,平均延時,平均排隊時間,Coredump 數量,下游引擎失敗率,下游引擎延時變化
第二行展示業務的延遲(50%和95%延遲),流量,吞吐(按照不同錯誤碼)
第三行展示下游引擎的延遲(50%和95%延遲),流量,吞吐(按照不同錯誤碼)
能夠展示 Prometheus 強大威力的是,這里面每一個圖表,都可以同時展示所有機房的監控指標,而每一個指標的計算只需要一條 Query 語句。比如第一行第五列,各個機房的各個下游的失敗率統計并排序,只用了一條語句:
topk(5, 100*sum(rate(downstream_responses{error_code!="0"}[5m])) by (job, server)/sum(rate(downstream_responses[5m])) by (job, server)) 注意這里的Range Vector Selector - [5m],意味著我們是基于過去5分鐘的數據來計算rate,這個值取的越小,得到的監控結果波動越大,越大則越平滑,選擇多大的值,取決于你想要什么結果。建議圖表使用5m,而告警規則計算采用1m。如果業務不是很重要,可以適當增大這個值。 這一套監控模板基本覆蓋了業務對可用性監控的需求,同時業務也可以自己定義監控指標并進行監控。
AlertManager
Prometheus 周期性進行抓取數據,完成抓取后會檢查是否有告警規則并進行計算,滿足告警規則就會觸發告警,發送到 alertmanager。基于這個流程,當你在監控圖表看到異常時,告警已經先行觸發了。
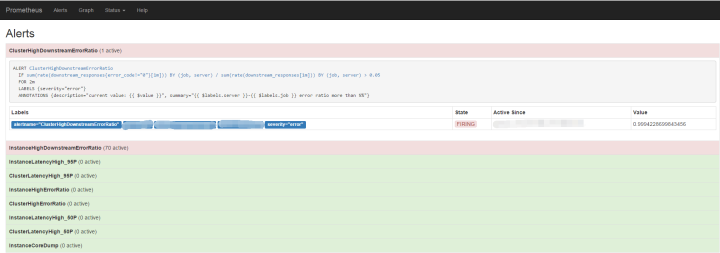
默認情況我們配置了不到10條告警規則,要注意的是周期的選擇,過長的話會產生較大延遲,太短的話一個小的流量波動都會導致大量報警出現。 Prometheus 的設計是產生報警,但報警的匯總、分發、屏蔽則在 AlertManager 服務完成。
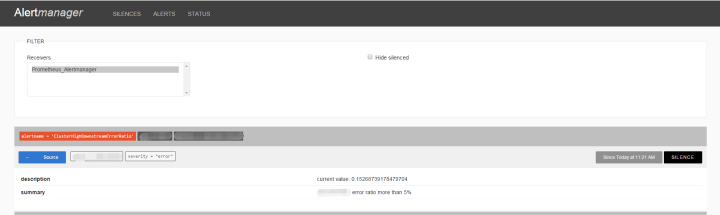
AlertManager 目前還是非常簡單的,但它可以將告警繼續分發到其他接收者:
可以通過webhook機制,發送告警到一個中間服務轉換格式再發送到內部告警接口
如果使用第三方告警管理平臺,如PageDuty、OneAlert,可以直接用內置的 pageduty 支持或 webhook 發送告警過去
如果是一窮二白的團隊,建議配置 email + slack,實現告警歸檔和手機 Push
更復雜告警分級管理,AlertManager 還是有很長的路要走,這個話題也值得今后單獨講下。
Prometheus + Grafana + Mesos
Prometheus + Grafana 的方案,加上統一的服務框架,可以滿足大部分中小團隊的監控需求。我們將這幾個組件打包一起部署在 Mesos 之上,統一的安裝包進一步降低監控系統部署的難度,用戶需要配置一些簡單的參數即可。但還需要注意幾點:
目前并沒有將 Prometheus 和 Grafana 容器化部署,因為這兩者本身就沒有什么特殊依賴;安裝包存儲在 minio 中。
由于 Prometheus 系統的特殊性,我們通常將其指定在一臺固定的機器上執行,且將數據落地到一個固定的目錄,這樣重啟 Prometheus 的影響會非常低
Grafana 是展示給用戶的,需要盡可能的保持固定入口,所以我們通過HAPROXY_CONSUL給其配置了代理

結 論
Prometheus 是相當強大并快速成長的一個監控系統實現,雖然在穩定性、性能、文檔上仍有很大提升空間,但對于中小團隊是一個很棒的選擇,通過定制服務框架,設計完善的埋點,統一的Prometheus/Grafana配置模板,再加上Mesos平臺,可以半自動化的部署實時業務監控系統。
審核編輯 :李倩
-
監控系統
+關注
關注
21文章
4038瀏覽量
181428 -
時間序列
+關注
關注
0文章
31瀏覽量
10552
原文標題:無監控,不運維!Prometheus 在線服務的監控實操指南
文章出處:【微信號:magedu-Linux,微信公眾號:馬哥Linux運維】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
使用BP神經網絡進行時間序列預測
ads1248輸入數據是上升沿有效,輸出數據確是下降沿有效,為什么?
時空引導下的時間序列自監督學習框架






 工商網監
工商網監
評論