") 基于RoBERTa的語義理解模型的構(gòu)建
基于RoBERTa的語義理解模型的構(gòu)建
美團技術(shù)團隊 近日,美團搜索與NLP部NLP中心語義理解團隊的小樣本學習模型FSL++在中文小樣本語言理解權(quán)威評測基準FewCLUE榜單登頂,在自然語言推理(OCNLI)單任務中取得第一,并在極少數(shù)樣本(一個類別僅100余個)的條件下,在新聞分類(TNEWS)、科學文獻學科分類(CSLDCP)任務上超過了人類識別精確度。
1 概述
2 方法介紹
2.1 增強預訓練
2.2 模型結(jié)構(gòu)
2.3 數(shù)據(jù)增強
2.4 集成學習&自訓練
3 實驗結(jié)果
3.1 數(shù)據(jù)集介紹
3.2 實驗對比
4 小樣本學習策略在美團場景的應用
5 總結(jié)
1 概述
CLUE(Chinese Language Understanding Evaluation)[1]是中文語言理解權(quán)威測評榜單,包含了文本分類、句間關(guān)系、閱讀理解等眾多語義分析和語義理解類子任務,對學術(shù)界和工業(yè)界都產(chǎn)生了較大的影響。
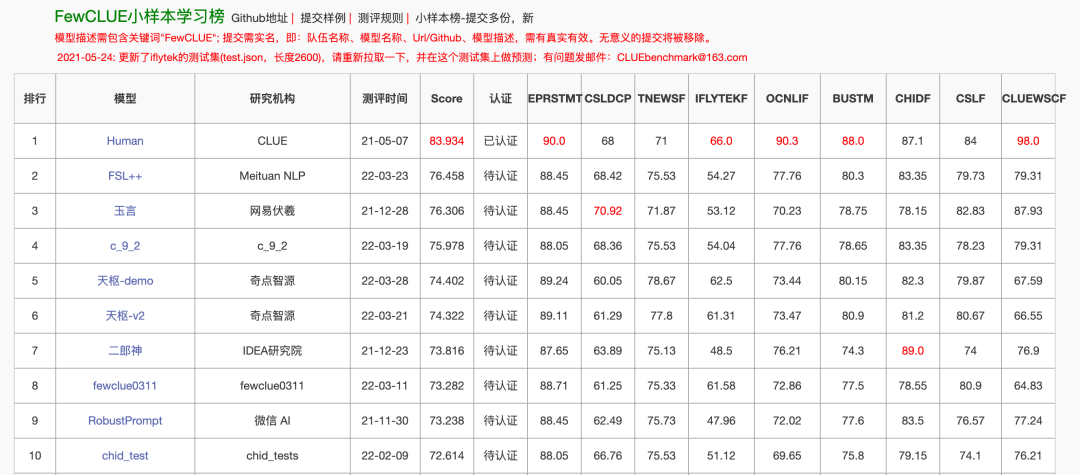
圖1 FewCLUE榜單(截止到2022-04-18)
FewCLUE[2,3]是CLUE中專門用于中文小樣本學習評測的一個子榜,旨在結(jié)合預訓練語言模型通用和強大的泛化能力,探索小樣本學習最佳模型和在中文上的實踐。FewCLUE的部分數(shù)據(jù)集只有一百多條有標簽樣本,可以衡量模型在極少有標簽樣本下的泛化性能,發(fā)布后吸引了包括網(wǎng)易、微信AI、阿里巴巴、IDEA研究院、浪潮人工智能研究院等多家企業(yè)與研究院的參與。不久前,美團平臺搜索與NLP部NLP中心語義理解團隊的小樣本學習模型FSL++以優(yōu)越的性能在FewCLUE榜單上取得第一名,達到SOTA水平。
2 方法介紹
大規(guī)模預訓練模型雖然在各大任務里面取得非常好的效果,但是在特定的任務上,還是需要許多標注數(shù)據(jù)。美團的各個業(yè)務中,有著豐富的NLP場景,往往需要較高的人工標注成本。在業(yè)務發(fā)展早期或者新的業(yè)務需求需要快速上線時,往往會出現(xiàn)標注樣本不足的現(xiàn)象,使用傳統(tǒng)Pretrain(預訓練)+ Fine-Tune(微調(diào))的深度學習訓練方法往往達不到理想的指標要求,因此研究小樣本場景的模型訓練問題就變得非常必要。
本文提出了一套大模型 + 小樣本的聯(lián)合訓練方案FSL++,綜合了模型結(jié)構(gòu)優(yōu)選、大規(guī)模預訓練、樣本增強、集成學習以及自訓練等模型優(yōu)化策略,最終在中文語言理解權(quán)威評測基準下的FewCLUE榜單取得了優(yōu)異的成績,并且在部分任務上性能超過了人類水平,而在部分任務上(如CLUEWSC)還有一定的提升空間。
FewCLUE發(fā)布后,網(wǎng)易伏羲使用自研的EET模型[4],并通過二次訓練增強模型的語義理解能力,再加入模版進行多任務學習;IDEA研究院的二郎神模型[5]在BERT模型的基礎上使用更先進的預訓練技術(shù)訓練大模型,在下游任務微調(diào)的過程中用加入動態(tài)Mask策略的Masked Language Model(MLM)作為輔助任務。這些方法都使用Prompt Learning作為基本的任務架構(gòu),跟這些自研的大模型相比,我們的方法主要在Prompt Learning框架的基礎上加入了樣本增強、集成學習以及自學習等模型優(yōu)化策略,極大地提高模型的任務表現(xiàn)和魯棒性,同時這套方法可以適用于各種預訓練模型,更加靈活便捷。
FSL++整體模型結(jié)構(gòu)如下圖2所示。FewCLUE數(shù)據(jù)集為每個任務提供160條有標簽數(shù)據(jù)以及接近兩萬條無標簽數(shù)據(jù)。本次FewCLUE實踐中,我們先在Fine-Tune階段構(gòu)造多模板Prompt Learning,并對有標簽數(shù)據(jù)采用對抗訓練、對比學習、Mixup等增強策略。由于這些數(shù)據(jù)增強策略采用不同的增強原理,可以認為這些模型之間差異性比較顯著,經(jīng)過集成學習之后會有比較好的效果。所以在采用數(shù)據(jù)增強策略進行訓練以后,我們擁有了多個弱監(jiān)督模型,并且用這些弱監(jiān)督模型在無標簽數(shù)據(jù)上進行預測,得到無標簽數(shù)據(jù)的偽標簽分布。之后,我們將多個經(jīng)過不同的數(shù)據(jù)增強模型預測得到的無標簽數(shù)據(jù)的偽標簽分布整合起來,得到一份總的無標簽數(shù)據(jù)的偽標簽分布,接著重新構(gòu)造多模板Prompt Learning,并再次使用數(shù)據(jù)增強策略,選擇最優(yōu)策略。目前,我們的實驗只進行一輪迭代,也可以嘗試多輪迭代,不過隨著迭代次數(shù)增加,提升也不再明顯。
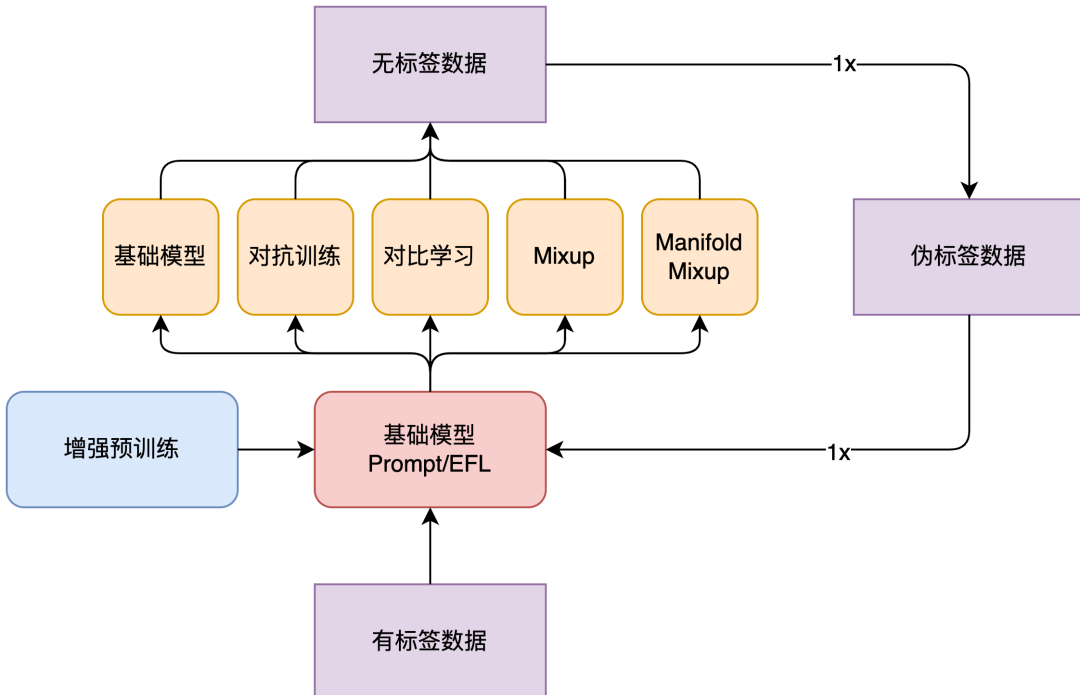
圖2 FSL++模型框架
2.1 增強預訓練
預訓練語言模型是在龐大的無標簽語料庫上進行訓練的。例如,RoBERTa[6]在160GB以上的文本進行訓練,包括百科全書、新聞文章、文學作品和Web內(nèi)容。通過這些模型學習到的表示,在包含多種來源的各種大小的數(shù)據(jù)集的任務中實現(xiàn)出色的性能。
FSL++模型使用RoBERTa-large模型作為基礎模型,并且采用融入領(lǐng)域知識的Domain-Adaptive Pretraining (DAPT)[7]預訓練方法和融入任務知識的Task-Adaptive Pretraining (TAPT)[7]。DAPT旨在預訓練模型的基礎上,增加大量領(lǐng)域內(nèi)無標簽文本繼續(xù)訓練語言模型,之后再在指定任務的數(shù)據(jù)集上進行微調(diào)。
對目標文本領(lǐng)域進行繼續(xù)預訓練,可以提高語言模型的性能,尤其是在與目標文本領(lǐng)域相關(guān)的下游任務上的性能。并且,預訓練文本與任務領(lǐng)域的相關(guān)度越高,帶來的提升越大。在本次實踐中,我們最終使用了在100G包含娛樂節(jié)目、體育、健康、國際事務、電影、名人等各個領(lǐng)域的語料的CLUE Vocab[8]上預訓練得到的RoBERTa Large模型。TAPT指在預訓練模型的基礎上,增加數(shù)量較少但與任務直接相關(guān)的無標簽語料進行預訓練。針對TAPT任務,我們選擇使用的預訓練數(shù)據(jù)是FewCLUE榜單為每個任務提供的無標簽數(shù)據(jù)。
除此之外,在針對句間關(guān)系任務,如中文自然語言推理任務OCNLI、中文對話短文本匹配任務BUSTM的實踐中,我們使用在其他句間關(guān)系任務如中文自然語言推理數(shù)據(jù)集CMNLI、中文短文本相似度數(shù)據(jù)集LCQMC上進行預訓練的模型參數(shù)作為初始參數(shù),相比直接用原始模型完成任務,也能提升一定的效果。
2.2 模型結(jié)構(gòu)
FewCLUE包含多種任務形式,我們?yōu)槊糠N任務選擇了合適的模型結(jié)構(gòu)。文本分類任務和機器閱讀理解(MRC)任務本身的類別詞就攜帶了信息,因此更適合建模為Masked Language Model(MLM)形式;而句間關(guān)系任務判斷兩個句子的相關(guān)性,更類似于Next Sentence Prediction(NSP)[9]任務形式。因此,我們?yōu)榉诸惾蝿蘸烷喿x理解任務選擇PET[10]模型,為句間關(guān)系任務選擇EFL[11]模型,EFL方法可以通過全局采樣構(gòu)造負樣本,學習到更魯棒的分類器。
2.2.1 Prompt Learning
Prompt Learning的主要目標是盡可能減小預訓練目標與下游微調(diào)目標的差距。通常現(xiàn)有的預訓練任務均包含MLM損失函數(shù),但是下游的任務則并未采用MLM,而是引入新的分類器,使得預訓練任務和下游任務出現(xiàn)了不一致。Prompt Learning不引入額外的分類器或其他參數(shù),而是通過拼接模板(Template,即為輸入數(shù)據(jù)拼接語言片段,從而改造任務為MLM形式)和標簽詞映射(Verbalizer,即為每個標簽在詞表中找到對應的詞,從而為MLM任務設定預測目標),使得模型可以在少量樣本的條件下在下游任務中使用。
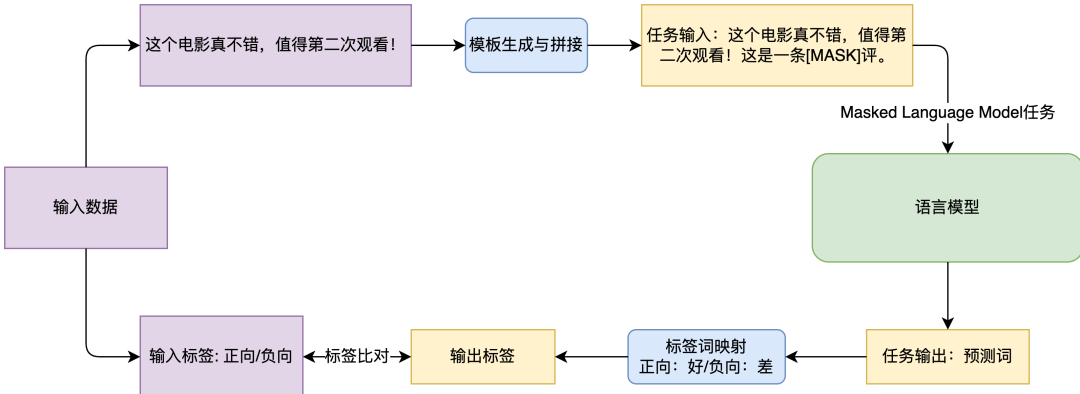
圖3 Prompt Learning方法完成情感分析任務的流程圖
以圖3展示的電商評價情感分析任務EPRSTMT為例。給定文本“這個電影真不錯,值得第二次觀看!”,傳統(tǒng)的文本分類則是在CLS部分的Embedding接上分類器,并映射到0-1分類上(0:負向,1:正向)。這種方法在小樣本場景下需要訓練新的分類器,比較難獲得好的效果。而基于Prompt Learning的方法則是創(chuàng)建模板“這是一條 [MASK] 評。”,再將模板與原文進行拼接,訓練時通過語言模型預測[MASK]位置的詞,再將其映射到對應的類別上(好:正向, 差:負向)。
由于缺乏足夠數(shù)據(jù),有時很難確定表現(xiàn)最好的模板和標簽詞映射。因此,也可以采用多模板與多標簽詞映射的設計。通過設計多個模板,最終的結(jié)果采用多個模板的結(jié)果的整合,或設計一對多的標簽詞映射,讓一個標簽對應多個詞。同上述例子,可以設計如下模板組合(左:同一個句子的多模板,右:多標簽映射)。

圖4 PET多模板與多標簽映射圖
任務樣例

表1 FewCLUE數(shù)據(jù)集中PET模板構(gòu)建
2.2.2 EFL
EFL模型將兩個句子拼接在一起,用輸出層的[CLS]位置處的Embedding后接一個分類器完成預測。EFL的訓練過程中,除了訓練集的樣本,還會進行負樣本構(gòu)造,訓練過程中,在每個Batch里隨機選擇其他數(shù)據(jù)中的句子作為負樣本,通過構(gòu)造負樣本進行數(shù)據(jù)增強。雖然EFL模型需要訓練新的分類器,但目前有很多公開的文本蘊含/句間關(guān)系數(shù)據(jù)集,如CMNLI、LCQMC等,可以通過在這些樣本上進行持續(xù)學習(continue-train),再將學習到的參數(shù)遷移到小樣本場景中,用FewCLUE的任務數(shù)據(jù)集進行進一步微調(diào)。
任務樣例

表2 FewCLUE數(shù)據(jù)集中EFL模板構(gòu)建
2.3 數(shù)據(jù)增強
數(shù)據(jù)增強方法主要有樣本增強和Embedding增強。NLP領(lǐng)域中,數(shù)據(jù)增強的目的是在不改變語義的前提下擴充文本數(shù)據(jù)。主要的方法包括簡單文本替換、使用語言模型生成相似句子等,我們嘗試過EDA等擴充文本數(shù)據(jù)的方法,但是一個詞的變化就可能導致整個句子的意思發(fā)生翻轉(zhuǎn),經(jīng)過替換的文本攜帶大量噪音,所以很難用簡單的規(guī)則樣本變化產(chǎn)生足夠的增強數(shù)據(jù)。而Embedding增強,則不再對輸入進行操作,轉(zhuǎn)而在Embedding層面進行操作,可以通過對Embedding增加擾動或者插值等方式提升模型的魯棒性。
因此,本次實踐中我們主要進行Embedding增強。我們用的數(shù)據(jù)增強策略分別有Mixup[12]、Manifold-Mixup[13]、對抗訓練(Adversarial training, AT) [14]和對比學習R-drop[15]。數(shù)據(jù)增強策略的詳細介紹見之前的技術(shù)博客小樣本學習及其在美團場景中的應用。

表3 數(shù)據(jù)增強策略簡述
Mixup通過對輸入數(shù)據(jù)進行簡單的線性變換,構(gòu)造新的組合樣本和組合標簽,可以增強模型的泛化能力。在各種有監(jiān)督任務或者半監(jiān)督任務上,使用Mixup都能極大提高模型的泛化能力。Mixup方法可以視為正則化操作,它要求模型在特征層面生成的組合特征滿足線性約束,并且利用這種約束對模型施加正則化。直觀來看,當模型的輸入為另外兩個輸入的線性組合時,其輸出也是這兩個數(shù)據(jù)單獨輸入模型后所得輸出的線性組合,其實就是要求模型近似為一個線性系統(tǒng)。
Manifold Mixup將上述的Mixup操作泛化到特征上。因為特征具有更高階的語義信息,所以在其維度上插值可能會產(chǎn)生更有意義的樣本。在類似于BERT[9]、RoBERTa[6]的模型中,隨機選擇層數(shù)k,對該層的特征表示進行Mixup插值。普通的Mixup的插值發(fā)生在輸出層Embedding部分,而Manifold Mixup相當于把這一系列插值操作加入到語言模型內(nèi)部的Transformers結(jié)構(gòu)的隨機某層中。
對抗訓練通過在輸入樣本上增加微小的擾動來顯著提高模型Loss。對抗訓練就是訓練一個能有效識別原始樣本和對抗樣本的模型。基本原理就是通過添加擾動構(gòu)造一些對抗樣本,交給模型去訓練,提高模型在遇到對抗樣本時的魯棒性,同時也能提高模型的表現(xiàn)和泛化能力。對抗樣本需要具有兩個特點,分別是:
相對于原始輸入,所添加的擾動是微小的。
能使模型犯錯。對抗訓練有兩個作用,分別是提高模型對惡意攻擊的魯棒性和提高模型的泛化能力。
R-Drop對同一個句子做兩次Dropout,并且強制由Dropout生成的不同子模型的輸出概率保持一致。Dropout的引入雖然效果很好,但是它會導致訓練和推理過程的不一致性問題。為緩解這種訓練推理過程的不一致性,R-Drop對Dropout進行正則化處理,在兩個子模型產(chǎn)生的輸出中增加對輸出數(shù)據(jù)分布的限制,引入數(shù)據(jù)分布度量的KL散度損失,使得Batch內(nèi)同一個樣本生成的兩個數(shù)據(jù)分布盡量接近,具有分布一致性。具體來說,對于每個訓練樣本,R-Drop最小化了由不同Dropout生成的子模型的輸出概率之間的KL 散度。R-Drop作為一種訓練思想,可以用到大部分有監(jiān)督或半監(jiān)督的訓練中,通用性強。
我們使用的三種數(shù)據(jù)增強策略,Mixup是在語言模型的輸出層Embedding和語言模型的內(nèi)部隨機某層Transformers的輸出層中做兩個樣本的線性變化,對抗訓練是在樣本上增加微小的擾動,而對比學習是對同一個句子做兩次Dropout形成正樣本對,再用KL散度限制兩個子模型保持一致。三種策略都是通過在Embedding完成一些操作來增強模型的泛化性,經(jīng)過不同策略得到的模型分別都具有不同的偏好,這就為下一步的集成學習提供了條件。
2.4 集成學習&自訓練
集成學習可以組合多個弱監(jiān)督模型,以期得到一個更好更全面的強監(jiān)督模型。集成學習潛在的思想是即便某一個弱分類器得到了錯誤的預測,其他的弱分類器也可以將錯誤糾正回來。如果待組合的各個模型之間差異性比較顯著,那么集成學習之后通常會有一個較好的結(jié)果。
自訓練使用少量的標記數(shù)據(jù)和大量的未標記數(shù)據(jù)對模型進行聯(lián)合訓練,首先使用經(jīng)過訓練的分類器來預測所有未標記數(shù)據(jù)的標簽,然后選擇置信度較高的標簽作為偽標簽數(shù)據(jù),將偽標記數(shù)據(jù)與人工標記的訓練數(shù)據(jù)聯(lián)合起來重新訓練分類器。
集成學習+自訓練是一套可以利用多個模型以及無標簽數(shù)據(jù)的方案。這其中,集成學習的一般步驟為:訓練多個不同的弱監(jiān)督模型,分別用每個模型預測無標簽數(shù)據(jù)的標簽概率分布,計算標簽概率分布的加權(quán)和,得到無標簽數(shù)據(jù)的偽標簽概率分布。自訓練指訓練一個模型用于組合其他各個模型,其一般步驟為:訓練多個Teacher模型,Student模型學習偽標簽概率分布中高置信度樣本的Soft Prediction,Student模型作為最后的強學習器。
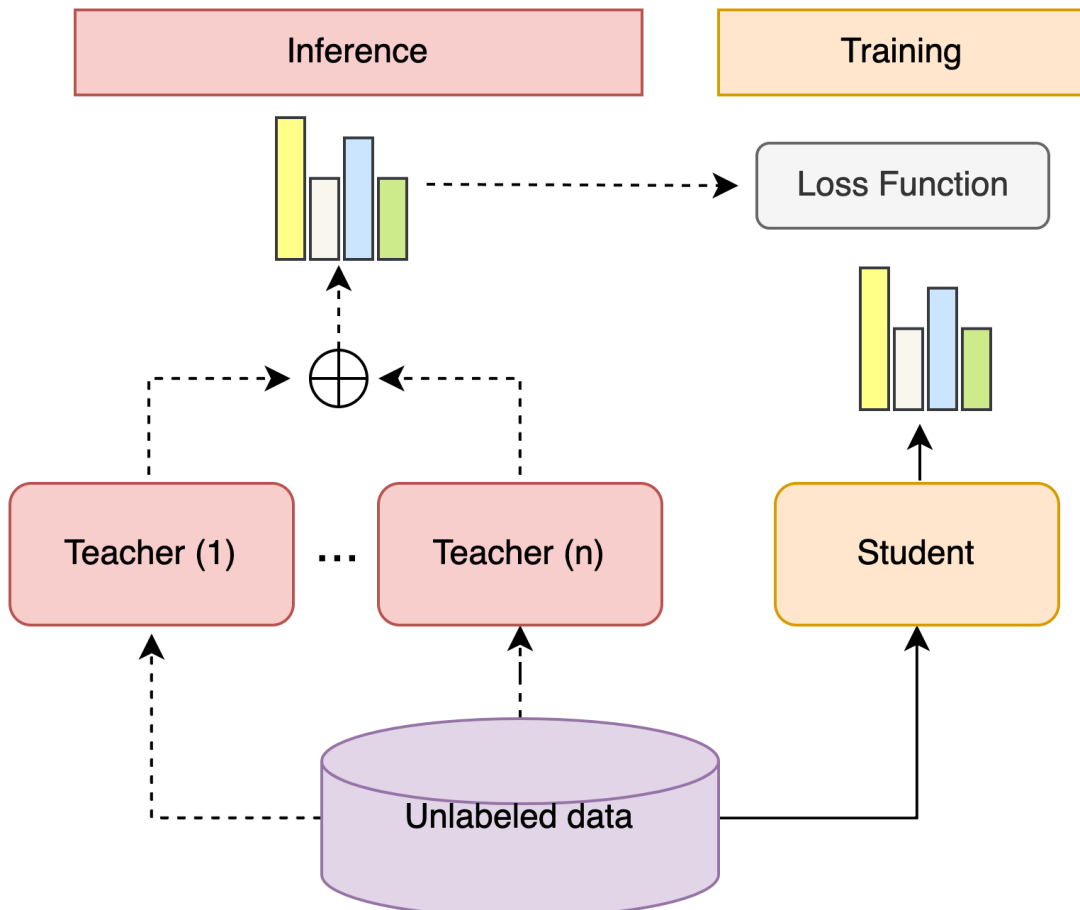
圖5 集成學習+自訓練結(jié)構(gòu)
在本次FewCLUE實踐中,我們先在Fine-Tune階段構(gòu)造多模板Prompt Learning,并對有標注數(shù)據(jù)采用對抗訓練、對比學習、Mixup等增強策略。由于這些數(shù)據(jù)增強策略采用不同的增強原理,可以認為這些模型之間差異性比較顯著,經(jīng)過集成學習之后會有比較好的效果。
在采用數(shù)據(jù)增強策略進行訓練以后,我們擁有了多個弱監(jiān)督模型,并且用這些弱監(jiān)督模型在無標簽數(shù)據(jù)上進行預測,得到無標簽數(shù)據(jù)的偽標簽分布。之后,我們將多個經(jīng)過不同的數(shù)據(jù)增強模型預測得到的無標簽數(shù)據(jù)的偽標簽分布整合起來,得到一份總的無標簽數(shù)據(jù)的偽標簽分布。篩選偽標簽數(shù)據(jù)的過程中,我們不一定會選擇置信度最高的樣本,因為如果每個數(shù)據(jù)增強模型給出的置信度都很高,說明這個樣本可能是容易學習的樣本,不一定有很大價值。
我們綜合多個數(shù)據(jù)增強模型給出的置信度,盡量選擇置信度較高,但是又不容易學習的樣本(比如多個模型預測不全部一致)。接著用標注數(shù)據(jù)和偽標注數(shù)據(jù)的集合重新構(gòu)造多模板Prompt Learning,再次使用數(shù)據(jù)增強策略,并選擇最好的策略。目前,我們的實驗目前只進行一輪迭代,也可以嘗試多輪迭代,不過隨著迭代次數(shù)增加,提升也會減少,不再顯著。
3 實驗結(jié)果
3.1 數(shù)據(jù)集介紹
FewCLUE榜單提供了9個任務,其中分別為4個文本分類任務,2個句間關(guān)系任務和3個閱讀理解任務。文本分類任務有電商評價情感分析、科學文獻分類、新聞分類和App應用描述主題分類任務。主要歸類為短文本二分類、短文本多分類和長文本多分類。其中有的任務類別眾多,超過100類,并且出現(xiàn)了類別不均衡問題。句間關(guān)系任務有自然語言推理和短文本匹配任務。閱讀理解任務則有成語閱讀理解選擇填空,摘要判斷關(guān)鍵詞判別和代詞消歧任務。每個任務大體提供了160條有標簽數(shù)據(jù)和兩萬條左右的無標簽數(shù)據(jù)。因為長文本分類任務類別眾多,過于困難,也提供了更多的有標簽數(shù)據(jù)。詳細的任務數(shù)據(jù)情況如表4所示:
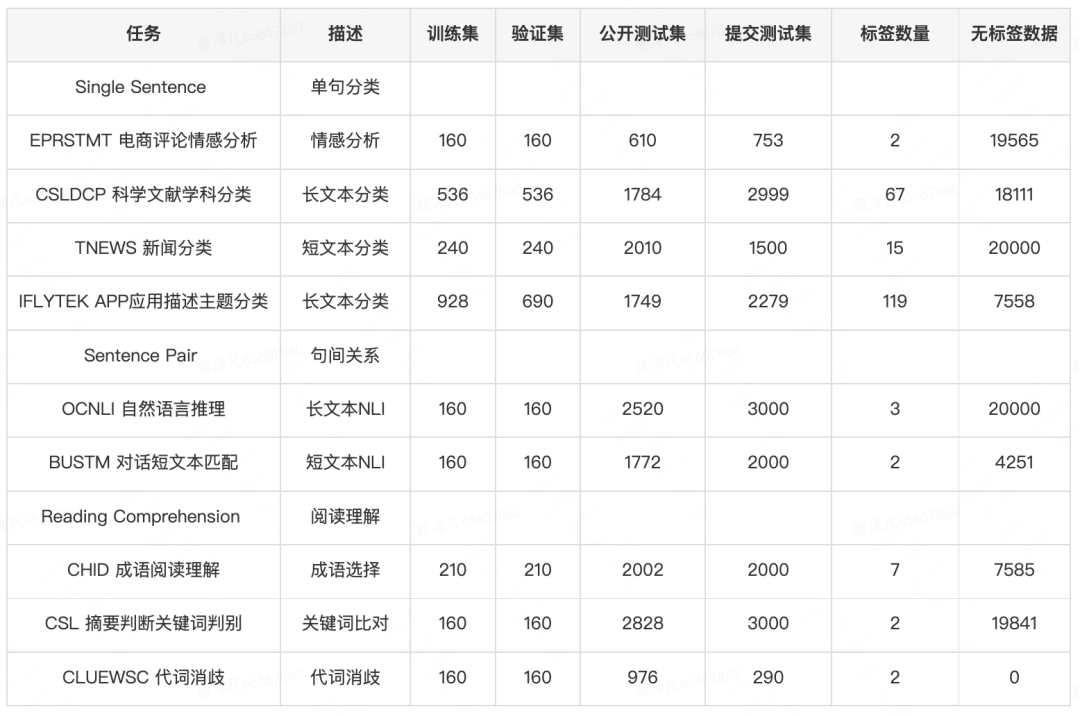
表4 FewCLUE數(shù)據(jù)集任務介紹
3.2 實驗對比
表5展示了不同模型和參數(shù)量的實驗結(jié)果的對比。在RoBERTa Base實驗中,使用PET/EFL模型會超過傳統(tǒng)的直接Fine-Tune模型結(jié)果2-28PP。以PET/EFL模型為基礎,為了探索大模型在小樣本場景中的效果,我們在RoBERTa Large上進行了實驗,相對于RoBERTa Base,大模型可以提升模型0.5-13PP;為了更好地利用領(lǐng)域知識,我們進一步在經(jīng)過CLUE數(shù)據(jù)集上增強預訓練的RoBERTa Large Clue模型上進行實驗,融入了領(lǐng)域知識的大模型進一步提升結(jié)果0.1-9pp。基于此,在之后的實驗中,我們都在RoBERTa Large Clue上進行實驗。
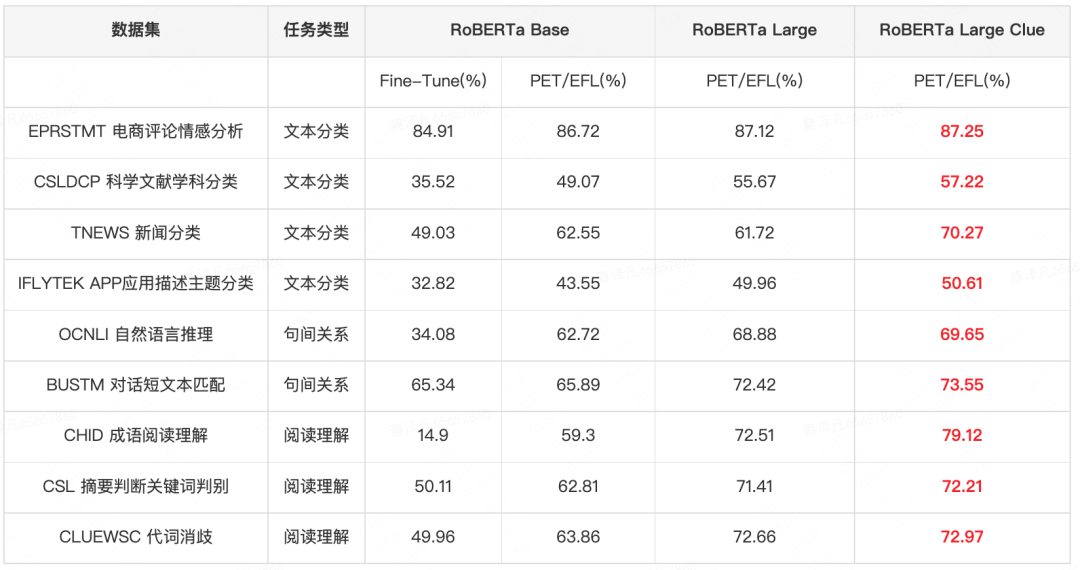
表5 不同模型和參數(shù)量的實驗結(jié)果對比 (加粗紅色字體表示最好的結(jié)果)
表6展示了在PET/EFL模型上進行數(shù)據(jù)增強和集成學習實驗結(jié)果, 可以發(fā)現(xiàn)即使是在大模型上使用數(shù)據(jù)增強策略,模型也能帶來0.8-9PP的提升,而進一步進行集成學習&自訓練以后,模型表現(xiàn)會繼續(xù)提升0.4-4PP。
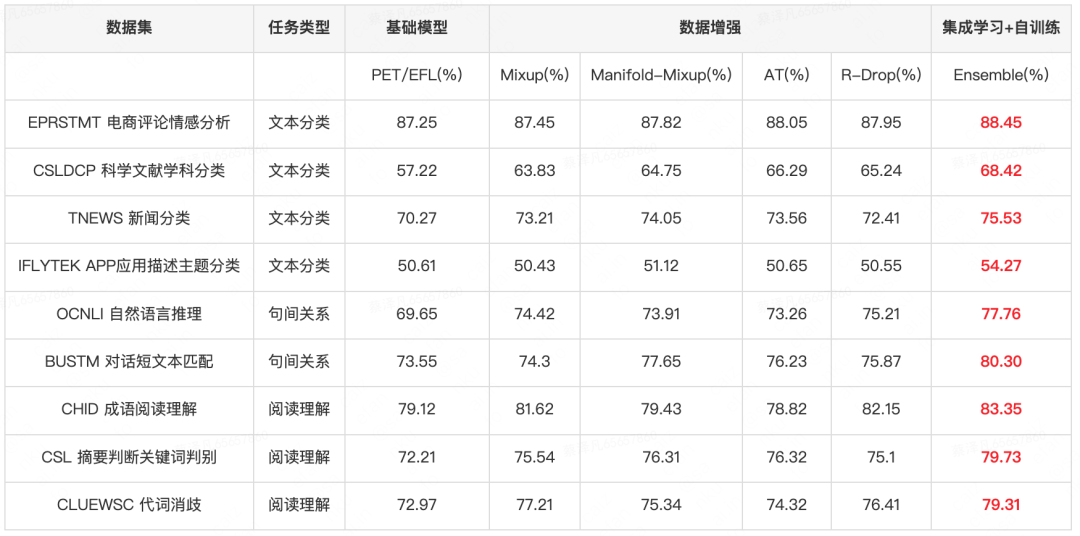
表6 基礎模型+數(shù)據(jù)增強+集成學習實驗效果 (加粗紅色字體表示最好的結(jié)果)
其中集成學習+自訓練步驟中,我們嘗試了幾種篩選策略:
選擇置信度最高的樣本,這種策略帶來的提升在1PP以內(nèi),置信度最高的偽標簽樣本中很多是多個模型預測一致且置信度都比較高的樣本,這部分樣本比較容易學習,融入這部分樣本帶來的收益有限。
選擇置信度高且具有爭議性的樣本(存在至少一個模型和其他模型預測結(jié)果不一致,但多個模型總體置信度超過閾值1),這種策略規(guī)避了特別容易學習的樣本,又通過設置閾值避免帶來過多臟數(shù)據(jù),可以帶來0-3PP的提升;
融合上面的兩種策略,若多個模型對于一個樣本的預測結(jié)果是一致的,我們選擇置信度小于閾值2的樣本;對于存在至少一個模型和其他模型預測結(jié)果不一致的,我們選擇置信度大于閾值3的樣本。這種方式同時選擇了置信度較高的樣本保證輸出的可信度,又選擇了較有爭議的樣本保證篩選出來的偽標簽樣本具有較大學習難度,可以帶來0.4-4PP的提升。
4 小樣本學習策略在美團場景的應用
在美團的各個業(yè)務中,有著豐富的NLP場景,部分任務可以歸類為文本分類任務和句間關(guān)系任務,以上提到的小樣本學習策略已經(jīng)應用于美團點評的各種場景,期望在數(shù)據(jù)資源稀少的情況下訓練出比較好的模型。此外,小樣本學習策略已經(jīng)廣泛應用于美團內(nèi)部自然語言處理(NLP)平臺的各個NLP算法能力中,在眾多業(yè)務場景下落地并取得顯著收益,美團內(nèi)部的工程師可通過該平臺來體驗NLP中心相關(guān)的能力。
文本分類任務
醫(yī)美題材分類:對美團和點評的筆記內(nèi)容按題材分為8類:獵奇、探店、測評、真人案例、治療過程、避坑、效果對比、科普。用戶點擊某一種題材時,返回對應的筆記內(nèi)容,上線至美團和點評App醫(yī)療美容頻道的百科頁、方案頁經(jīng)驗分享,小樣本學習利用2,989條訓練數(shù)據(jù)準確率提升1.8PP,達到了89.24%。
攻略識別:從UGC和筆記中挖掘旅游攻略,提供旅游攻略的內(nèi)容供給,應用于景點精搜下的攻略模塊,召回內(nèi)容為描述旅游攻略的筆記,小樣本學習利用384條訓練數(shù)據(jù)準確率提升2PP,達到了87%。
學城文本分類:學城(美團內(nèi)部知識庫)有大量的用戶文本,經(jīng)歸納將文本分為17種類別,已有模型在700條數(shù)據(jù)上訓練,通過小樣本學習,在已有模型上提升模型精度2.5PP,達到84%。
項目篩選:LE生活服務/麗人等業(yè)務目前的評價列表頁混排評價的方式不便讓用戶快速找到?jīng)Q策信息,因此需要更有結(jié)構(gòu)化的分類標簽來滿足用戶的需求,小樣本學習在這兩個業(yè)務上利用300-500條數(shù)據(jù)上準確率均達到95%+(多個數(shù)據(jù)集分別提升1.5-4PP)。
句間關(guān)系任務
醫(yī)美功效打標:對美團和大眾點評的筆記內(nèi)容按功效進行召回,功效的類型有:補水、美白、瘦臉、除皺等,上線至醫(yī)美頻道頁,有110種功效類型需要打標,小樣本學習僅用2909條訓練數(shù)據(jù)準確率達到了91.88%(提升2.8PP)。
醫(yī)美品牌打標:品牌上游企業(yè)有針對旗下產(chǎn)品進行品牌宣傳和營銷的訴求,而內(nèi)容營銷是當前主流、有效的營銷方式之一。品牌打標就是為每種品牌如“伊膚泉”、“術(shù)唯可”召回詳細介紹該品牌的筆記內(nèi)容,共有103種品牌,已上線至醫(yī)美品牌館,小樣本學習僅用1676條訓練數(shù)據(jù)準確率達到了88.59%(提升2.9PP)。
5 總結(jié)
在本次榜單提交中,我們構(gòu)建了一種基于RoBERTa的語義理解模型,并通過增強預訓練、PET/EFL模型、數(shù)據(jù)增強和集成學習&自訓練來提升模型的效果。該模型能完成文本分類、句間關(guān)系推理任務和幾種閱讀理解任務。
通過參加本次測評任務,我們對小樣本場景下的自然語言理解領(lǐng)域的算法和研究有了更深的認識,也借此對前沿算法的中文落地能力進行了摸底測試,為后續(xù)進一步算法研究、算法落地打下了基礎。此外,本次數(shù)據(jù)集中的任務場景與美團搜索與NLP部的業(yè)務場景存在很大相似性,該模型的很多策略也直接應用在實際業(yè)務中,直接為業(yè)務賦能。
審核編輯:郭婷
-
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1222瀏覽量
25273 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22477
原文標題:美團獲得小樣本學習榜單FewCLUE第一!Prompt Learning+自訓練實戰(zhàn)
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
基于MindSpeed MM玩轉(zhuǎn)Qwen2.5VL多模態(tài)理解模型

當AI學會“秒回”……看利爾達RTC SDK AI大模型接入方案怎么做

破解透明物體抓取難題,地瓜機器人 CASIA 推出幾何和語義融合的單目抓取方案|ICRA 2025
一種基于正交與縮放變換的大模型量化方法

【「基于大模型的RAG應用開發(fā)與優(yōu)化」閱讀體驗】+Embedding技術(shù)解讀
利用VLM和MLLMs實現(xiàn)SLAM語義增強

一文理解多模態(tài)大語言模型——下

如何使用Python構(gòu)建LSTM神經(jīng)網(wǎng)絡模型
如何設定機器人語義地圖的細粒度級別
AI大模型在自然語言處理中的應用
摩爾線程正式開源音頻理解大模型MooER
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
PyTorch神經(jīng)網(wǎng)絡模型構(gòu)建過程
圖像分割與語義分割中的CNN模型綜述
大語言模型(LLM)快速理解






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論