") 通過移動圖形處理單元可以提高性能
通過移動圖形處理單元可以提高性能
如果實施得當,移動系統(tǒng)中的 GPU 可以提高性能。但這是一個很大的“如果”。
移動 GPU 或圖形處理單元是專用的協(xié)處理器,旨在加速智能手機、平板電腦、可穿戴設備和 IoT 設備上的圖形應用程序、用戶界面和 3D 內容。逼真的 3D 游戲和“實時”圖形用戶界面 (GUI) 是專為 GPU 設計的工作負載示例。
幾年前,GPU 是一個很好的功能,設計用于需要最新技術來保持其旗艦地位的高端消費移動產品。現(xiàn)在,隨著圖形顯示無處不在并用于各種連接設備,GPU 已成為所有移動應用處理器和中/高端 MCU/MPU 產品規(guī)格的必要組成部分。GPU 還有助于產品差異化,因此公司可以為其目標應用程序創(chuàng)建引人注目的、以視覺為中心的解決方案。
GPU 設計為單指令多數(shù)據(jù) (SIMD) 處理引擎,專為大規(guī)模并行工作負載而構建。3D 圖形是高吞吐量并行處理的最佳示例之一,因為 GPU 每秒可以處理數(shù)十億個像素/頂點或浮點運算 (GFLOPS)。GPU 的核心是一個或多個著色器(SIMD 單元),它們處理獨立的頂點、圖元和片段(像素)。著色器是按頂點、按像素或其他基元執(zhí)行 3D 圖形程序的計算元素。
頂點著色器程序修改對象屬性以實現(xiàn)對位置、移動、頂點光照和顏色的控制。像素或片段著色器程序計算最終的像素顏色、陰影、對象紋理、照明,并且可以通過編程為場景添加特殊效果,例如模糊、邊緣增強或過濾。還有更新類型的著色器程序,包括幾何、曲面細分和計算著色器。
像 OpenGL ES 3.1 中的計算著色器對于高級圖形渲染非常有用,您可以在其中混合 3D 和 GPU 計算 (GPGPU) 上下文以添加真實效果,如物理處理(游戲中的自然波浪和風運動或生動的爆炸)和全局照明(通過涉及直接和間接光源/光線的計算獲得更好的照明和陰影)。GPU 還可以從一個著色器單元有效地擴展到數(shù)千個互連的分組著色器單元,以根據(jù)從物聯(lián)網(wǎng)和移動到高性能計算 (HPC) 科學計算的目標應用程序提高性能和并行性。高性能著色器設計可以運行在 1.2 GHz 以上,每個周期執(zhí)行數(shù)十億條指令,以處理圖形、OpenCL、OpenVX(視覺處理)等。
圖 1 顯示了 CPU 和 GPU 架構之間的一些主要區(qū)別。每種設計都有其優(yōu)勢,必須協(xié)同工作以實現(xiàn)最優(yōu)化的解決方案(功率、帶寬、資源共享等)。最好的設計使用異構系統(tǒng)架構,根據(jù)其優(yōu)勢將工作負載拆分/分配給每個處理核心。隨著行業(yè)向平臺級優(yōu)化發(fā)展,GPU 也正在成為系統(tǒng)的重要組成部分,其中 GPU 用于圖形以外的計算密集型應用程序。請注意,在當今的混合設計中,還有其他計算模塊,包括 DSP、FPGA 和其他可以與 CPU-GPU 組合一起使用的任務特定內核。

圖1
GPU流水線介紹
較新的 GPU 使用“統(tǒng)一”著色器來實現(xiàn)跨不同類型著色器程序的最佳硬件資源管理,以平衡工作負載。統(tǒng)一著色器的第一個版本結合了頂點 (VS) 和像素 (PS) 處理,隨著圖形 API 的發(fā)展,后續(xù)版本增加了對幾何 (GS)、曲面細分 (TS) 和計算 (CS) 著色器的支持。
對于統(tǒng)一著色器,分配給每個著色器的工作負載可以是基于頂點或基于像素的,允許著色器在任一上下文之間即時切換以保持高水平的著色器利用率。如果您有一個頂點或像素重的圖像,這可以最大限度地減少硬件資源瓶頸和停滯。在非統(tǒng)一著色器架構中,有單獨的、固定的 VS 和 PS 著色器。例如,如果圖像的頂點很重,VS 可能會停止 GPU 管道,因為它需要在 GPU 繼續(xù)處理圖像的其余部分之前完成。這會導致管道泡沫和硬件的低效使用。圖 2 顯示了一個單獨的 VS 和 PS 與一個統(tǒng)一的著色器核心的情況。
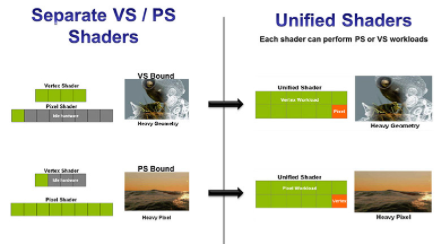
圖 2
多年來,GPU 著色器已經(jīng)超越了圖形,包括通用管道,可配置用于圖形、計算、圖像 (ISP) 協(xié)同處理、嵌入式視覺、視頻(HEVC 和 H.264 前/后處理等) 。),以及其他并行應用程序。這就是為什么您會聽到諸如 GPGPU(通用 GPU)和 GPU 計算之類的術語來描述 GPU 在圖形渲染之外的廣泛使用。
從高層次上看,移動 GPU 管道由多個關鍵塊組成:
主機接口和(安全)MMU
通過 ACE-Lite/AXI/AHB 接口與 CPU 通信。
處理來自 CPU 的命令并從幀緩沖區(qū)或系統(tǒng)內存訪問幾何數(shù)據(jù)。
輸出發(fā)送到下一個階段(頂點著色器)的頂點流。
管理所有 GPU 事務,包括向著色器發(fā)送指令/數(shù)據(jù),分配/取消分配資源,并為安全事務和數(shù)據(jù)壓縮提供安全性。
可編程統(tǒng)一著色器
頂點著色器 (VS) 包括頂點變換、光照和插值,可以從簡單(線性)到復雜(變形效果)。
像素/片段著色器 (PS) 計算考慮到光照、陰影和其他屬性(包括紋理映射)的最終像素值。
幾何著色器 (GS) 采用圖元(線、點或三角形)并修改、創(chuàng)建(或破壞)頂點以增加對象的細節(jié)級別。GS 允許 GPU 管道訪問相鄰的圖元,因此可以將它們作為一個緊密結合的組進行操作,以創(chuàng)建逼真的效果,其中相鄰頂點相互交互以創(chuàng)建具有平滑流動運動(頭發(fā)、衣服等)的效果。GS/VS/PS 組合允許更自主的 GPU 操作在內部處理狀態(tài)變化(最小化 CPU-GPU 交互),方法是添加算術和動態(tài)流控制邏輯來卸載以前在 CPU 上完成的操作。另一個關鍵特性是 Stream Out,其中 VS/GS 可以將數(shù)據(jù)直接輸出到內存,并且可以由著色器單元或任何其他 GPU 塊自動重復訪問數(shù)據(jù),而無需 CPU 干預。
曲面細分著色器 (TS) 在 TS 管道中包括兩個稱為 Hull 和域著色器的固定功能單元。TS 采用曲面(矩形或三角形)并將它們轉換為具有不同數(shù)量的多邊形表示(網(wǎng)格/補丁),可以根據(jù)質量要求進行更改。較高的計數(shù)會創(chuàng)建更多的細節(jié),而較低的計數(shù)會在對象上創(chuàng)建較少的細節(jié)。鑲嵌單元由三部分組成:
外殼著色器 (HS) 是一種可編程著色器,它從基本輸入補丁(四邊形、三角形或線)生成幾何(表面)補丁并計算用于操縱表面的控制點數(shù)據(jù)。HS 還計算傳遞給 tessellator 的自適應 tessellation 因子,因此它知道如何細分表面屬性。
Tessellator 是一個固定(可配置)功能階段,它根據(jù)來自 HS 的 tessellation 因子將補丁細分為更小的對象(三角形、線或點)。
域著色器 (DS) 是一種可編程著色器,它評估表面并為輸出補丁中的每個細分點計算新的頂點位置,并將其發(fā)送到 GS 進行額外處理。
計算著色器 (CS) 將 GPGPU/GPU 計算能力添加到圖形管道中,因此開發(fā)人員可以編寫使用此著色器的 GLSL 應用程序代碼,并且可以在正常渲染管道之外運行。數(shù)據(jù)可以在管道階段和渲染計算上下文之間在內部共享,因此兩者都可以并行執(zhí)行。CS 還可以使用與 OpenGL/OpenGL ES 渲染管道相同的上下文、狀態(tài)、制服、紋理、圖像紋理、原子計數(shù)器等,使其更容易和更直接地編程和與渲染管道輸出一起使用。
可編程光柵化器
將對象從幾何形式轉換為像素形式,并剔除(移除)任何背面或隱藏的表面。有許多級別的剔除機制可確保不處理隱藏像素以節(jié)省計算周期、帶寬和功率。
內存接口
在將像素寫入幀緩沖區(qū)之前,使用 Z 緩沖區(qū)、模板/alpha 測試刪除看不見或隱藏的像素。
在此階段執(zhí)行包括 Z 和顏色緩沖區(qū)的壓縮。
即時模式與延遲渲染 GPU
有兩種常見的 GPU 架構和渲染圖像的方法。兩種方法都使用前面描述的相同的通用管道,但它們用于繪制的機制不同。一種方法稱為基于 Tile 的延遲渲染 (TBDR),另一種稱為即時模式渲染 (IMR)。根據(jù)各自的用例,兩者都有優(yōu)點和缺點。
1995 年(在智能手機/平板電腦出現(xiàn)之前),許多圖形公司在 PC 和游戲機市場支持這兩種方法。TBDR 集團擁有英特爾、微軟(Talisman)、Matrox、PowerVR 和 Oak 等公司。IMR 方面有 SGI、S3、Nvidia、ATi 和 3dfx 等名稱。快進到 2014 年——PC 和游戲機市場還沒有使用 TBDR 架構。所有 PC 和游戲機架構,包括 PS3/PS4、Xbox 360/One 和 Wii,都是基于 IMR。
這種轉變的主要原因是因為 IMR 作為對象渲染架構的內在優(yōu)勢,可以處理非常復雜的動態(tài)游戲(例如,快速運動、FPS 或場景或視點不斷變化的幀到幀的賽車游戲) 。 此外,隨著 3D 內容三角形速率的增加,TBDR 無法跟上,因為它們需要不斷地將緩存內存溢出到幀緩沖內存,因為它們的架構限制。更高的三角形/多邊形數(shù)量允許 GPU 渲染絲般光滑和細致(逼真)的表面,而不是出現(xiàn)在傳統(tǒng)游戲中的塊狀曲面。通過在 IMR 中添加曲面細分著色器,三角形/多邊形進一步細分的表面渲染使 3D 圖形更加接近現(xiàn)實。
今天的移動市場密切反映了 IMR 技術正在取代 TBDR 的 PC 和游戲機市場趨勢。在 TBDR 市場上,有兩家公司,Imagination 和 ARM,盡管 ARM 正試圖轉向 IMR,因為他們看到了在移動設備上運行下一代游戲的主要優(yōu)勢。在 IMR 方面,有高通、Vivante、Nvidia、AMD 和英特爾。
使用 IMR 的一大好處是游戲/應用程序開發(fā)人員可以重用并輕松地將已經(jīng)在復雜 GPU(或游戲控制臺)上運行的現(xiàn)有游戲資產移植到移動設備上。由于移動設備對功率/散熱和芯片面積有嚴格的限制,因此縮小性能差距并最大限度地減少應用程序移植或重大代碼更改的最佳方法是使用與他們開發(fā)的架構類似的架構。除了獲得等效的高質量 PC 質量渲染之外,IMR 還為開發(fā)人員提供了選擇,所有這些都封裝在比 TBDR 解決方案更小的裸片區(qū)域中。隨著行業(yè)超越 OpenGL ES 3.1 和 DirectX 12 應用程序編程接口 (API),IMR 還提高了內部系統(tǒng)和外部內存帶寬。
最后,TBDR 架構針對低三角形/多邊形數(shù)量的 3D 內容和簡單的用戶界面進行了優(yōu)化。IMR 架構在動態(tài)用戶界面和詳細的 3D 內容方面表現(xiàn)出色,可為移動設備帶來與 PC 和游戲機相同的用戶體驗和游戲質量。
多年來的圖形 API
領先的移動設備 3D API 基于 Khronos Group 的 OpenGL ES API,可在大多數(shù)當前智能手機和平板電腦中找到,適用于包括 Android、iOS 和 Windows 在內的各種操作系統(tǒng)。OpenGL ES 基于 OpenGL 的桌面版本,針對移動設備進行了優(yōu)化,包括去除冗余和很少使用的特性以及添加移動友好的數(shù)據(jù)格式。
初始版本 OpenGL ES 1.1 基于固定功能硬件,OpenGL ES 2.0 基于可編程頂點和片段(像素)著色器,同時刪除了 1.1 版的固定功能轉換和片段管道。OpenGL ES 3.0 通過添加基于 OpenGL 3.3/4.x 的功能并減少對擴展的需求,從而通過對支持的功能提出更嚴格的要求并減少實現(xiàn)可變性來簡化編程,從而進一步推動了行業(yè)發(fā)展。一些 GLES 3.0 功能包括遮擋查詢、MRT、紋理/頂點數(shù)組、實例化、變換反饋、更多可編程性、OpenCL 互操作性、更高質量(32 位浮點數(shù)/整數(shù))、NPOT 紋理、3D 紋理等。
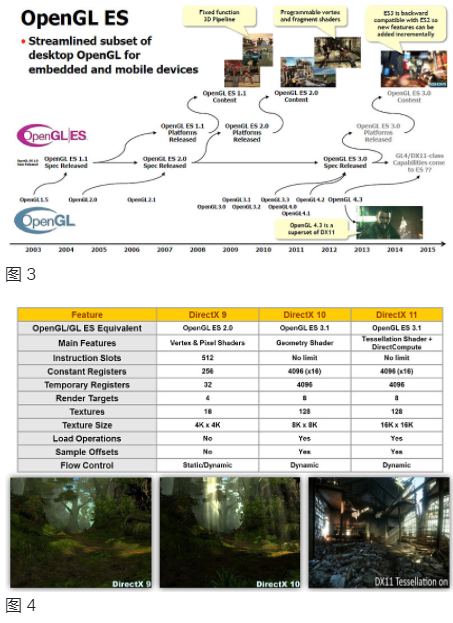
在 2014 年 3 月的游戲開發(fā)者大會上,Khronos 發(fā)布了 OpenGL ES 3.1,其中包含計算著色器 (CS)、單獨的著色器對象、間接繪制命令、增強的紋理和新的 GLSL 語言添加等進步。在 OpenGL ES 3.1 發(fā)布的同時,Google 還發(fā)布了其 Android L 擴展包 (AEP),它需要移動硬件中的幾何 (GS) 和曲面細分 (TS) 著色器功能,以便為 Android 平臺帶來先進的 3D 功能以鏡像 PC 級圖形。圖 3 顯示了 OpenGL 和 OpenGL ES 多年來的進展時間線。Microsoft 的 DirectX (DX) API 的轉換和映射如圖 4 所示。DX9 映射到 OpenGL ES 2.0,DX10/DX11 映射到 OpenGL ES 3.1。
GPU超越了圖形
在過去的幾年里,工業(yè)和大學的研究人員發(fā)現(xiàn),現(xiàn)代 GPU 的計算資源由于其固有的并行架構而適用于某些并行計算。GPU 上顯示的計算速度提升很快得到了認可,并且基于 GPU 的巨大處理能力構建的另一個 HPC 細分市場誕生了。
超越圖形的 GPU 可以稱為 GPU 計算核心或 GPGPU。OpenCL、HSA、OpenVX 和 Microsoft DirectCompute 等不同的行業(yè)標準已經(jīng)實現(xiàn),其中任務和指令并行性現(xiàn)在已經(jīng)過優(yōu)化,以利用不同的處理內核。在不久的將來,移動設備將通過卸載 CPU、DSP 或自定義內核來更好地利用系統(tǒng)資源,并使用 GPU 來實現(xiàn)最高的計算性能、計算密度、時間節(jié)省和整體系統(tǒng)加速。最好的方法是使用混合實現(xiàn),其中 CPU 和 GPU 緊密交錯以達到性能和功耗目標。
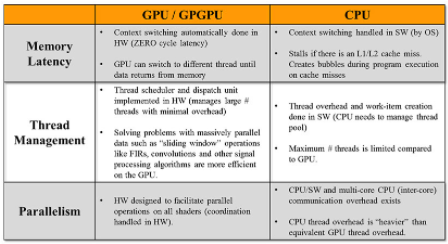
圖 5 | 下表在查看內存延遲、線程管理和執(zhí)行并行性等不同因素時將 CPU 與 GPU 進行了比較。
許多計算問題,如圖像處理、視覺處理、分析、數(shù)學計算和其他并行算法,都很好地映射到 GPU SIMD 架構。您甚至可以對 GPU 進行編程以使用多 GPU 方法,其中計算任務和/或 3D 渲染幀在 GPU 之間拆分以提高性能和吞吐量。GPU 可以在多上下文模式下工作,以同時執(zhí)行 3D 和計算線程。例如,GPU 核心 1 和 2 分配給渲染圖像,核心 3 和 4 專用于 GPGPU 功能,如粒子效果(煙/水/火)、模擬真實世界運動的游戲物理或自然用戶界面(NUI ) 處理手勢支持。采用 GPGPU 的其他市場,尤其是在嵌入式/計算機視覺領域,包括:
增強現(xiàn)實:使用 GPU 生成的數(shù)據(jù)(圖像、數(shù)據(jù)、3D 渲染等)覆蓋現(xiàn)實世界環(huán)境,這些數(shù)據(jù)可以從各種傳感器(如 Google Glass)輸入。AR 可以處理在線(實時和直接)或離線內容流。
特征提取:對許多視覺算法至關重要,因為需要創(chuàng)建圖像“興趣點”和描述符,以便 GPU 知道要處理什么。SURF(加速魯棒特征)和 SIFT 是可以在 GPU 上有效并行化的算法示例。物體識別和符號識別是這種應用的形式。
點云處理:包括特征提取以創(chuàng)建 3D 圖像,以檢測雜亂圖像中的形狀和分割對象。用途可能包括將增強現(xiàn)實添加到街景地圖中。
高級駕駛輔助系統(tǒng) (ADAS):不斷實時計算多種安全功能,包括線路檢測/車道輔助(Hough 變換、Sobel/Canny 算法)、行人檢測(定向梯度直方圖或 HOGS)、圖像去扭曲、盲點檢測等。
安全與監(jiān)控:包括通過人臉地標定位(Haar 特征分類器)、人臉特征提取和分類以及對象識別的人臉識別。
運動處理:自然的用戶界面,如手勢識別,將手與背景分離(如顏色空間轉換為 HSV 顏色空間),然后對手進行結構分析以處理運動。
視頻處理:使用著色器程序和高速整數(shù)/浮點計算的 HEVC 視頻協(xié)同處理。
圖像處理:將 GPGPU 與圖像信號處理器 (ISP) 相結合,以實現(xiàn)流線型的圖像處理管道。
傳感器融合:將視覺處理與其他傳感器數(shù)據(jù)(如激光雷達)相結合,以創(chuàng)建具有深度的 3D 空間地圖。圖形中使用的一個類似概念是光線追蹤,您可以射出一條光線并在圖像中追蹤其路徑,并計算所有光線與對象的交點和反彈以生成逼真的 3D 圖像。
消費者和行業(yè)正在推動移動領域的前沿技術向前發(fā)展。因此,GPU 供應商必須不斷創(chuàng)新并跟上最新趨勢、API 和用例,同時最大限度地提高性能并最大限度地減少高級圖形和計算功能的功耗和芯片面積增量。移動 GPU 設計必須從算法層面進行架構設計,并經(jīng)過深思熟慮,以實現(xiàn)業(yè)界最小的集成設計和硬件占用空間。直接取自 PC GPU 的設計無法有效地按比例縮小以實現(xiàn)移動電源效率。秘訣在于配置引擎蓋下的內容,以使移動應用程序點擊,而不限制功能、穩(wěn)健性或所需的性能。
審核編輯:郭婷
-
傳感器
+關注
關注
2564文章
52668瀏覽量
764267 -
處理器
+關注
關注
68文章
19825瀏覽量
233745 -
gpu
+關注
關注
28文章
4916瀏覽量
130733
發(fā)布評論請先 登錄
Condor使用Cadence托管云服務開發(fā)高性能RISC-V微處理器
如何基于Kahn處理網(wǎng)絡定義AI引擎圖形編程模型





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論