") 神經(jīng)網(wǎng)絡(luò)圖需要圖流處理器
神經(jīng)網(wǎng)絡(luò)圖需要圖流處理器
隨著技術(shù)的發(fā)展,神經(jīng)網(wǎng)絡(luò)處理仍處于起步階段。因此,仍有一些高層次的問題需要回答。例如,“你如何實(shí)際執(zhí)行神經(jīng)網(wǎng)絡(luò)圖?”
有幾種可能的方法,但是神經(jīng)網(wǎng)絡(luò)(都是圖)的出現(xiàn)揭示了傳統(tǒng)處理器架構(gòu)中的一些缺陷,這些缺陷并不是為了執(zhí)行它們而設(shè)計(jì)的。例如,CPU 和 DSP 按順序執(zhí)行工作負(fù)載,這意味著必須將 AI 和機(jī)器學(xué)習(xí)工作負(fù)載重復(fù)寫入不可緩存的中間 DRAM。
這種串行處理方法,其中一個(gè)任務(wù)(或任務(wù)的一部分)必須在下一個(gè)任務(wù)開始之前完成,這會(huì)影響延遲、功耗等。而不是一個(gè)好辦法。圖 1 顯示了如何在這些傳統(tǒng)處理器上執(zhí)行圖形工作負(fù)載。
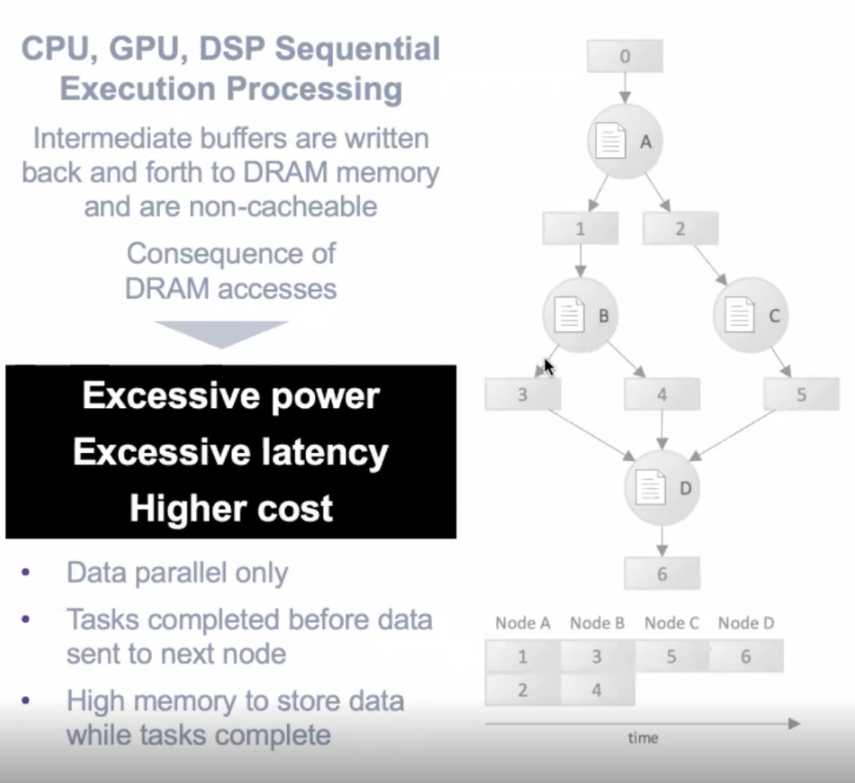
圖 1. 神經(jīng)網(wǎng)絡(luò)圖的串行執(zhí)行導(dǎo)致高功耗、延遲和整體系統(tǒng)成本。
圖中,氣泡節(jié)點(diǎn) A、B、C 和 D 代表功函數(shù),而矩形顯示每個(gè)節(jié)點(diǎn)生成的中間結(jié)果。Blaize(前身為 ThinCi)戰(zhàn)略業(yè)務(wù)發(fā)展副總裁 Richard Terrill 解釋了以這種方式處理神經(jīng)網(wǎng)絡(luò)圖的影響。
“這些中間結(jié)果通常非常龐大,將它們存儲(chǔ)在芯片上可能非常昂貴,”Terrel 解釋說。“你要么做一個(gè)非常大的籌碼。或者,更常見的是,您將其發(fā)送到芯片外,等待它完成。完成后,您可以加載下一個(gè)節(jié)點(diǎn)并運(yùn)行它。
“但是發(fā)生的情況是,必須在 B 加載并運(yùn)行后將結(jié)果帶回芯片上,然后在 C 加載并運(yùn)行后將兩個(gè)結(jié)果帶回芯片上。這里發(fā)生了很多片外、片上、片外、片上交易。”
面向圖表
隨著神經(jīng)網(wǎng)絡(luò)技術(shù)的使用和應(yīng)用的增長,最先進(jìn)的技術(shù)必須改變。Blaize 正在開發(fā)一種圖形流處理器 (GSP) 架構(gòu),它認(rèn)為該架構(gòu)可以與未來的人工智能和機(jī)器學(xué)習(xí)工作負(fù)載一起擴(kuò)展。
該公司的“完全可編程”芯片包含一系列指令可編程處理器、專用數(shù)據(jù)緩存和專有硬件調(diào)度程序,可為神經(jīng)網(wǎng)絡(luò)圖帶來任務(wù)級(jí)并行性。如圖 2 所示,該架構(gòu)有助于減少外部存儲(chǔ)器訪問,而集成 GSP 和專用數(shù)學(xué)處理器的運(yùn)行頻率僅為數(shù)百兆赫以節(jié)省電力。
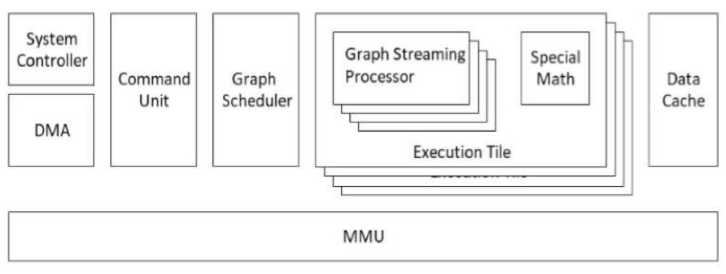
雖然 Blaize 仍然對(duì)其 GSP 架構(gòu)的細(xì)節(jié)保持不變,但從高層次來看,該技術(shù)似乎可以解決當(dāng)今的許多圖形處理挑戰(zhàn)。
“機(jī)器是底層的核心技術(shù),它旨在高效地實(shí)施和運(yùn)行數(shù)據(jù)流圖,”Terrill 說。“這是一種抽象,但它代表了當(dāng)今許多非常有趣的問題,要求你能夠?qū)ζ溥M(jìn)行不同類型的運(yùn)算,不同的計(jì)算、算術(shù)和控制、不同精度的算術(shù)、不同運(yùn)算符的算術(shù)、專用數(shù)學(xué)功能等。
“在里面,如果我們把它打開,我們專有的 SoC 有一系列專有處理器。它們是一個(gè)級(jí)別的一類 CPU,但它們是由我們的編譯器用二進(jìn)制文件編程的,以便在其中運(yùn)行,”他補(bǔ)充道。
圖 3 顯示了如何使用該機(jī)器有效地執(zhí)行圖形流處理。如圖所示,標(biāo)記為 0、1、2、3、4、5 和 6 的矩形表示任務(wù)平行。數(shù)據(jù)從第一個(gè)并行發(fā)送到標(biāo)記為“A”的氣泡節(jié)點(diǎn)。從氣泡中,它通過一個(gè)嚴(yán)重截?cái)嗟闹虚g緩沖區(qū),允許任務(wù)繼續(xù)執(zhí)行而不必離開芯片。
從理論上講,這意味著更低的能耗、更高的性能以及所需內(nèi)存帶寬的大幅減少。所有這些都可以轉(zhuǎn)化為更低的系統(tǒng)成本。
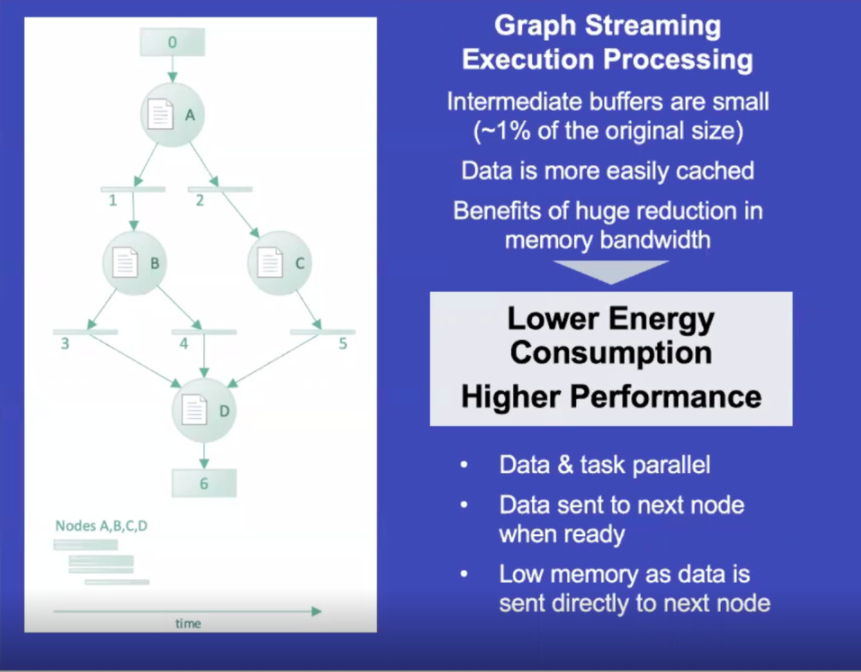
與 Blaize 的 GSP 技術(shù)配合使用的專用硬件調(diào)度程序允許開發(fā)人員利用這種性能,而無需了解目標(biāo)架構(gòu)的低級(jí)細(xì)節(jié),Terrill 指出這是關(guān)鍵,因?yàn)闆]有人可以真正處理這些類型的任務(wù)調(diào)度。工作量。事實(shí)上,調(diào)度程序非常高效,它可以在單個(gè)時(shí)鐘周期內(nèi)基于上下文切換對(duì)內(nèi)核進(jìn)行重新編程。
調(diào)度程序能夠通過與實(shí)際工作負(fù)載執(zhí)行并行運(yùn)行流程圖的映射來實(shí)現(xiàn)這一點(diǎn)
“它可以對(duì)傳入數(shù)據(jù)的單個(gè)周期以及何時(shí)何地運(yùn)行的中間結(jié)果做出決策,”特里爾說。“它不僅是可編程的,它是單周期可重新編程的,并且有很大的不同。您無法使用已修復(fù)的內(nèi)容或使用程序計(jì)數(shù)器來跟蹤正在完成的工作來執(zhí)行此類工作。對(duì) FPGA 重新編程非常困難。這需要半秒鐘,你會(huì)失去所有的狀態(tài)。它永遠(yuǎn)跟不上人們希望完成事情的這種速度。”
該公司的測(cè)試芯片是基于 28 納米工藝技術(shù)開發(fā)的。然而,有趣的是,Blaize 計(jì)劃通過一系列行業(yè)標(biāo)準(zhǔn)模塊、電路板和系統(tǒng)來生產(chǎn)這項(xiàng)技術(shù)。
GSP 的軟件方面
圖形原生處理器架構(gòu)當(dāng)然需要圖形原生軟件開發(fā)工具。在這里,Blaize“畢加索”開發(fā)平臺(tái)允許用戶高效地迭代和改變神經(jīng)網(wǎng)絡(luò);量化、修剪和壓縮它們;如果需要,甚至可以創(chuàng)建自定義網(wǎng)絡(luò)層(圖 4)。
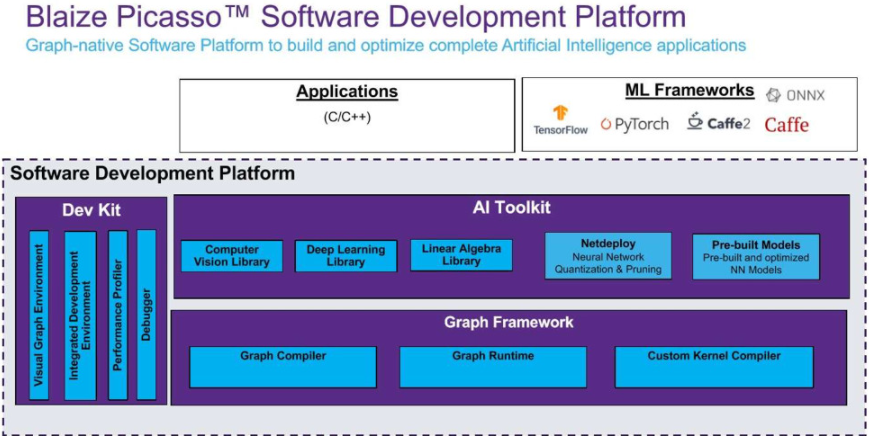
Picaso 支持 ONNX、TensorFlow、PyTorch 和 Caffe 等 ML 框架,基于 OpenVX 并采用類似 C++ 的語言,簡化了將應(yīng)用程序的神經(jīng)網(wǎng)絡(luò)部分集成到軟件堆棧中的其他組件的過程。圖 4 顯示了 Picaso 的主要元素——一個(gè)幫助開發(fā)預(yù)處理和后處理指令的 AI 工具包和一個(gè)處理編譯的圖形框架。
有趣的是,在生成可執(zhí)行文件后,編譯器在運(yùn)行時(shí)一直保留數(shù)據(jù)流圖,這允許硬件調(diào)度程序執(zhí)行上述單周期上下文切換。它還自動(dòng)將工作負(fù)載定位到芯片上最高效的內(nèi)核,以最大限度地提高性能和節(jié)能。
但是在上圖中更仔細(xì)地放大,我們會(huì)遇到“NetDeploy”。這是 Blaize 開發(fā)的一項(xiàng)技術(shù),用于自動(dòng)優(yōu)化現(xiàn)有模型以部署在邊緣設(shè)備中。
在修剪、壓縮和拉出東西的第一遍過程中,它最終成為一個(gè)非常循環(huán)的問題,”特里爾說。“準(zhǔn)確性通常會(huì)下降,它會(huì)回到訓(xùn)練階段說,‘好吧,像這樣訓(xùn)練它,然后這樣做,看看會(huì)發(fā)生什么。’”
“這不是一個(gè)非常確定的過程。這需要很多周期。”
與 OpenVINO 等工具類似,NetDeploy 允許用戶指定所需的精度和準(zhǔn)確度,并在將模型優(yōu)化為將在邊緣運(yùn)行的算法時(shí)保留這些特征。據(jù) Terrill 稱,一位在 GPU 上進(jìn)行培訓(xùn)并在 FPGA 上進(jìn)行部署的客戶使用 NetDeploy 將模型移植時(shí)間從數(shù)周縮短到幾分鐘,同時(shí)保持準(zhǔn)確性并滿足內(nèi)存占用目標(biāo)。
描繪未來
在過去的 24 個(gè)月中,隨著人工智能工作負(fù)載變得越來越普遍,并且縮小硅幾何尺寸的能力停滯不前,我們看到了許多新穎的架構(gòu)出現(xiàn)。
Blaize 通過其圖形流處理 (GSP) 解決方案提供了一種獨(dú)特的方法,該解決方案涵蓋了計(jì)算、人工智能開發(fā)和移植軟件,很快,甚至可以輕松集成到設(shè)計(jì)中的硬件。這可能使公司的技術(shù)比其他新興替代品更快地被采用。
審核編輯:郭婷
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4810瀏覽量
102939 -
gpu
+關(guān)注
關(guān)注
28文章
4916瀏覽量
130744 -
人工智能
+關(guān)注
關(guān)注
1804文章
48788瀏覽量
247000
發(fā)布評(píng)論請(qǐng)先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論