 淺談數據系統架構核心組件及存儲組件選型
淺談數據系統架構核心組件及存儲組件選型
任何應用系統都離不開對數據的處理,數據也是驅動業務創新以及向智能化發展最核心的東西。這也是為何目前大多數企業都在構建數據中臺的原因,數據處理的技術已經是核心競爭力。在一個完備的技術架構中,通常也會由應用系統以及數據系統構成。應用系統負責處理業務邏輯,而數據系統負責處理數據。
傳統的數據系統就是所謂的『大數據』技術,這是一個被創造出來的名詞,代表著新的技術門檻。近幾年得益于產業的發展、業務的創新、數據的爆發式增長以及開源技術的廣泛應用,經歷多年的磨煉以及在廣大開發者的共建下,大數據的核心組件和技術架構日趨成熟。特別是隨著云的發展,讓『大數據』技術的使用門檻進一步降低,越來越多的業務創新會由數據來驅動完成。
『大數據』技術會逐步向輕量化和智能化方向發展,最終也會成為一個研發工程師的必備技能之一,而這個過程必須是由云計算技術來驅動以及在云平臺之上才能完成。應用系統和數據系統也會逐漸融合,數據系統不再隱藏在應用系統之后,而是也會貫穿在整個業務交互邏輯。傳統的應用系統,重點在于交互。而現代的應用系統,在與你交互的同時,會慢慢的熟悉你。數據系統的發展驅動了業務系統的發展,從業務化到規模化,再到智能化。
業務化:完成最基本的業務交互邏輯。
規模化:分布式和大數據技術的應用,滿足業務規模增長的需求以及數據的積累。
智能化:人工智能技術的應用,挖掘數據的價值,驅動業務的創新。
向規模化和智能化的發展,仍然存在一定的技術門檻。成熟的開源技術的應用能讓一個大數據系統的搭建變得簡單,同時大數據架構也變得很普遍,例如廣為人知的Lambda架構,一定程度上降低了技術的入門門檻。但是對數據系統的后續維護,例如對大數據組件的規模化應用、運維管控和成本優化,需要掌握大數據、分布式技術及復雜環境下定位問題的能力,仍然具備很高的技術門檻。
數據系統的核心組件包含數據管道、分布式存儲和分布式計算,數據系統架構的搭建會是使用這些組件的組合拼裝。每個組件各司其職,組件與組件之間進行上下游的數據交換,而不同模塊的選擇和組合是架構師面臨的最大的挑戰。
本篇文章主要面向數據系統的研發工程師和架構師,我們會首先對數據系統核心組件進行拆解,介紹每個組件下對應的開源組件以及云上產品。之后會深入剖析數據系統中結構化數據的存儲技術,介紹阿里云Tablestore選擇哪種設計理念來更好的滿足數據系統中對結構化數據存儲的需求。
數據系統架構
核心組件
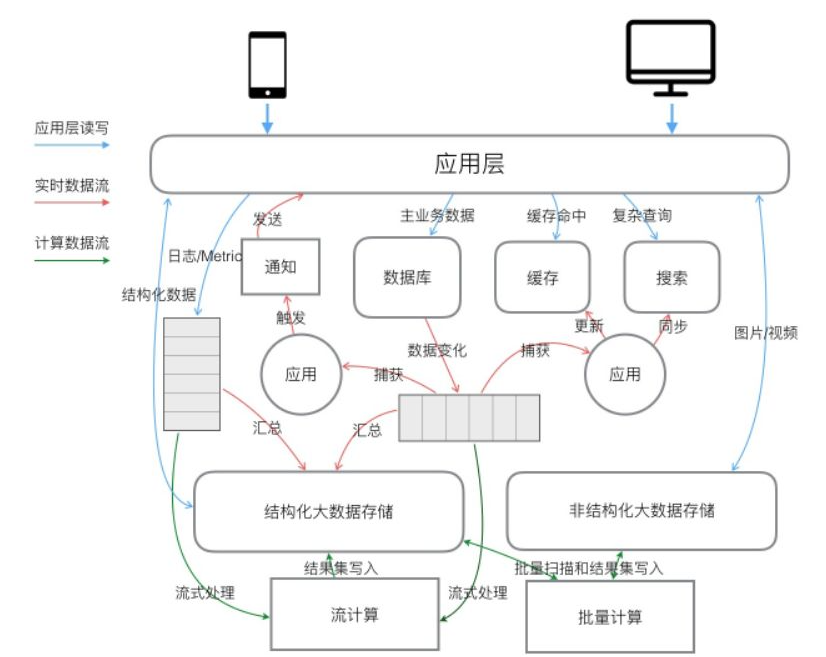
上圖是一個比較典型的技術架構,包含應用系統和數據系統。這個架構與具體業務無關聯,主要用于體現一個數據應用系統中會包含的幾大核心組件,以及組件間的數據流關系。應用系統主要實現了應用的主要業務邏輯,處理業務數據或應用元數據等。數據系統主要對業務數據及其他數據進行匯總和處理,對接BI、推薦或風控等系統。整個系統架構中,會包含以下比較常見的幾大核心組件:
關系數據庫:用于主業務數據存儲,提供事務型數據處理,是應用系統的核心數據存儲。
高速緩存:對復雜或操作代價昂貴的結果進行緩存,加速訪問。
搜索引擎:提供復雜條件查詢和全文檢索。
隊列:用于將數據處理流程異步化,銜接上下游對數據進行實時交換。異構數據存儲之間進行上下游對接的核心組件,例如數據庫系統與緩存系統或搜索系統間的數據對接。也用于數據的實時提取,在線存儲到離線存儲的實時歸檔。
非結構化大數據存儲:用于海量圖片或視頻等非結構化數據的存儲,同時支持在線查詢或離線計算的數據訪問需求。
結構化大數據存儲:在線數據庫也可作為結構化數據存儲,但這里提到的結構化數據存儲模塊,更偏在線到離線的銜接,特征是能支持高吞吐數據寫入以及大規模數據存儲,存儲和查詢性能可線性擴展。可存儲面向在線查詢的非關系型數據,或者是用于關系數據庫的歷史數據歸檔,滿足大規模和線性擴展的需求,也可存儲面向離線分析的實時寫入數據。
批量計算:對非結構化數據和結構化數據進行數據分析,批量計算中又分為交互式分析和離線計算兩類,離線計算需要滿足對大規模數據集進行復雜分析的能力,交互式分析需要滿足對中等規模數據集實時分析的能力。
流計算:對非結構化數據和結構化數據進行流式數據分析,低延遲產出實時視圖。
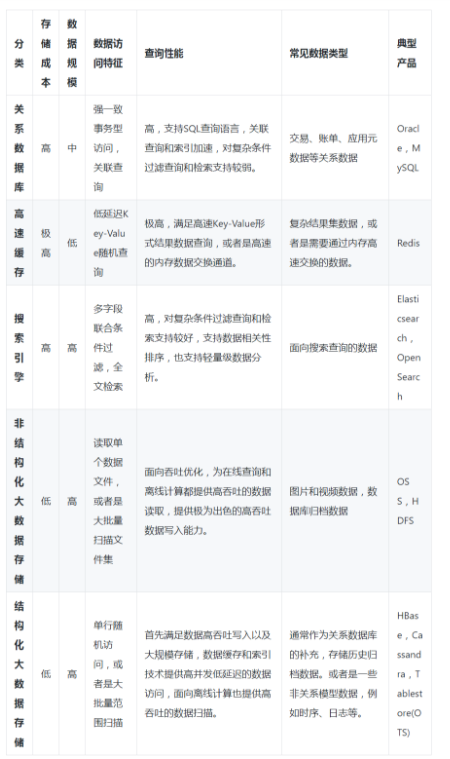
對于數據存儲組件我們再進一步分析,當前各類數據存儲組件的設計是為滿足不同場景下數據存儲的需求,提供不同的數據模型抽象,以及面向在線和離線的不同的優化偏向。我們來看下下面這張詳細對比表:
派生數據體系
在數據系統架構中,我們可以看到會存在多套存儲組件。對于這些存儲組件中的數據,有些是來自應用的直寫,有些是來自其他存儲組件的數據復制。例如業務關系數據庫的數據通常是來自業務,而高速緩存和搜索引擎的數據,通常是來自業務數據庫的數據同步與復制。不同用途的存儲組件有不同類型的上下游數據鏈路,我們可以大概將其歸類為主存儲和輔存儲兩類,這兩類存儲有不同的設計目標,主要特征為:
主存儲:數據產生自業務或者是計算,通常為數據首先落地的存儲。ACID等事務特性可能是強需求,提供在線應用所需的低延遲業務數據查詢。
輔存儲:數據主要來自主存儲的數據同步與復制,輔存儲是主存儲的某個視圖,通常面向數據查詢、檢索和分析做優化。
為何會有主存儲和輔存儲的存在?能不能統一存儲統一讀寫,滿足所有場景的需求呢?目前看還沒有,存儲引擎的實現技術有多種,選擇行存還是列存,選擇B+tree還是LSM-tree,存儲的是不可變數據、頻繁更新數據還是時間分區數據,是為高速隨機查詢還是高吞吐掃描設計等等。數據庫產品目前也是分兩類,TP和AP,雖然在往HTAP方向走,但實現方式仍然是底層存儲分為行存和列存。
再來看主輔存儲在實際架構中的例子,例如關系數據庫中主表和二級索引表也可以看做是主與輔的關系,索引表數據會隨著主表數據而變化,強一致同步并且為某些特定條件組合查詢而優化。關系數據庫與高速緩存和搜索引擎也是主與輔的關系,采用滿足最終一致的數據同步方式,提供高速查詢和檢索。在線數據庫與數倉也是主與輔的關系,在線數據庫內數據集中復制到數倉來提供高效的BI分析。
這種主與輔的存儲組件相輔相成的架構設計,我們稱之為『派生數據體系』。在這個體系下,最大的技術挑戰是數據如何在主與輔之間進行同步與復制。
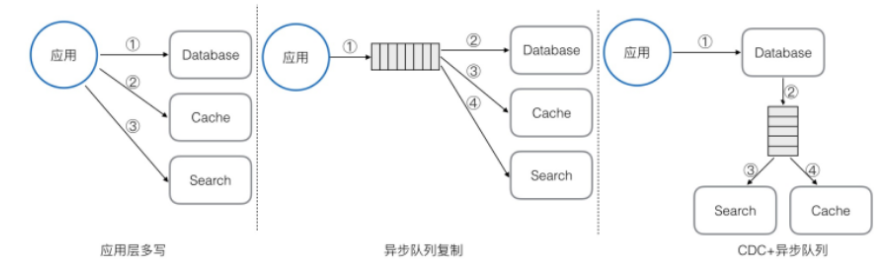
上圖我們可以看到幾個常見的數據復制方式:
應用層多寫:這是實現最簡單、依賴最少的一種實現方式,通常采取的方式是在應用代碼中先向主存儲寫數據,后向輔存儲寫數據。這種方式不是很嚴謹,通常用在對數據可靠性要求不是很高的場景。因為存在的問題有很多,一是很難保證主與輔之間的數據一致性,無法處理數據寫入失效問題;二是數據寫入的消耗堆積在應用層,加重應用層的代碼復雜度和計算負擔,不是一種解耦很好的架構;三是擴展性較差,數據同步邏輯固化在代碼中,比較難靈活添加輔存儲。
異步隊列復制:這是目前被應用比較廣的架構,應用層將派生數據的寫入通過隊列來異步化和解耦。這種架構下可將主存儲和輔存儲的數據寫入都異步化,也可僅將輔存儲的數據寫入異步化。第一種方式必須接受主存儲可異步寫入,否則只能采取第二種方式。而如果采用第二種方式的話,也會遇到和上一種『應用層多寫』方案類似的問題,應用層也是多寫,只不過是寫主存儲與隊列,隊列來解決多個輔存儲的寫入和擴展性問題。
CDC(Change Data Capture)技術:這種架構下數據寫入主存儲后會由主存儲再向輔存儲進行同步,對應用層是最友好的,只需要與主存儲打交道。主存儲到輔存儲的數據同步,則可以再利用異步隊列復制技術來做。不過這種方案對主存儲的能力有很高的要求,必須要求主存儲能支持CDC技術。一個典型的例子就是MySQL+Elasticsearch的組合架構,Elasticsearch的數據通過MySQL的binlog來同步,binlog就是MySQL的CDC技術。
『派生數據體系』是一個比較重要的技術架構設計理念,其中CDC技術是更好的驅動數據流動的關鍵手段。具備CDC技術的存儲組件,才能更好的支撐數據派生體系,從而能讓整個數據系統架構更加靈活,降低了數據一致性設計的復雜度,從而來面向高速迭代設計。可惜的是大多數存儲組件不具備CDC技術,例如HBase。而阿里云Tablestore具備非常成熟的CDC技術,CDC技術的應用也推動了架構的創新,這個在下面的章節會詳細介紹。
一個好的產品,在產品內部會采用派生數據架構來不斷擴充產品的能力,能將派生的過程透明化,內部解決數據同步、一致性及資源配比問題。而現實中大多數技術架構采用產品組合的派生架構,需要自己去管理數據同步與復制等問題,例如常見的MySQL+Elasticsearch,或HBase+Solr等。這種組合通常被忽視的最大問題是,在解決CDC技術來實時復制數據后,如何解決數據一致性問題?如何追蹤數據同步延遲?如何保證輔存儲與主存儲具備相同的數據寫入能力?
存儲組件的選型
架構師在做架構設計時,最大的挑戰是如何對計算組件和存儲組件進行選型和組合,同類的計算引擎的差異化相對不大,通常會優先選擇成熟和生態健全的計算引擎,例如批量計算引擎Spark和流計算引擎Flink。而對于存儲組件的選型是一件非常有挑戰的事,存儲組件包含數據庫(又分為SQL和NoSQL兩類,NoSQL下又根據各類數據模型細分為多類)、對象存儲、文件存儲和高速緩存等不同類別。帶來存儲選型復雜度的主要原因是架構師需要綜合考慮數據分層、成本優化以及面向在線和離線的查詢優化偏向等各種因素,且當前的技術發展還是多樣化的發展趨勢,不存在一個存儲產品能滿足所有場景下的數據寫入、存儲、查詢和分析等需求。有一些經驗可以分享給大家:
數據模型和查詢語言仍然是不同數據庫最顯著的區別,關系模型和文檔模型是相對抽象的模型,而類似時序模型、圖模型和鍵值模型等其他非關系模型是相對具象的抽象,如果場景能匹配到具象模型,那選擇范圍能縮小點。
存儲組件通常會劃分到不同的數據分層,選擇面向規模、成本、查詢和分析性能等不同維度的優化偏向,選型時需要考慮清楚對這部分數據存儲所要求的核心指標。
區分主存儲還是輔存儲,對數據復制關系要有明確的梳理。(主存儲和輔存儲是什么在下一節介紹)
建立靈活的數據交換通道,滿足快速的數據搬遷和存儲組件間的切換能力,構建快速迭代能力比應對未知需求的擴展性更重要。
另外關于數據存儲架構,我認為最終的趨勢是:
數據一定需要分層
數據最終的歸屬地一定是OSS
會由一個統一的分析引擎來統一分析的入口,并提供統一的查詢語言
結構化大數據存儲
定位
結構化大數據存儲在數據系統中是一個非常關鍵的組件,它起的一個很大的作用是連接『在線』和『離線』。作為數據中臺中的結構化數據匯總存儲,用于在線數據庫中數據的匯總來對接離線數據分析,也用于離線數據分析的結果集存儲來直接支持在線查詢或者是數據派生。根據這樣的定位,我們總結下對結構化大數據存儲的幾個關鍵需求。
關鍵需求
大規模數據存儲
結構化大數據存儲的定位是集中式的存儲,作為在線數據庫的匯總(大寬表模式),或者是離線計算的輸入和輸出,必須要能支撐PB級規模數據存儲。
高吞吐寫入能力
數據從在線存儲到離線存儲的轉換,通常是通過ETL工具,T+1式的同步或者是實時同步。結構化大數據存儲需要能支撐多個在線數據庫內數據的導入,也要能承受大數據計算引擎的海量結果數據集導出。所以必須能支撐高吞吐的數據寫入,通常會采用一個為寫入而優化的存儲引擎。
豐富的數據查詢能力
結構化大數據存儲作為派生數據體系下的輔存儲,需要為支撐高效在線查詢做優化。常見的查詢優化包括高速緩存、高并發低延遲的隨機查詢、復雜的任意字段條件組合查詢以及數據檢索。這些查詢優化的技術手段就是緩存和索引,其中索引的支持是多元化的,面向不同的查詢場景提供不同類型的索引。例如面向固定組合查詢的基于B+tree的二級索引,面向地理位置查詢的基于R-tree或BKD-tree的空間索引或者是面向多條件組合查詢和全文檢索的倒排索引。
存儲和計算成本分離
存儲計算分離是目前一個比較熱的架構實現,對于一般應用來說比較難體會到這個架構的優勢。在云上的大數據系統下,存儲計算分離才能完全發揮優勢。存儲計算分離在分布式架構中,最大的優勢是能提供更靈活的存儲和計算資源管理手段,大大提高了存儲和計算的擴展性。對成本管理來說,只有基于存儲計算分離架構實現的產品,才能做到存儲和計算成本的分離。
存儲和計算成本的分離的優勢,在大數據系統下會更加明顯。舉一個簡單的例子,結構化大數據存儲的存儲量會隨著數據的積累越來越大,但是數據寫入量是相對平穩的。所以存儲需要不斷的擴大,但是為了支撐數據寫入或臨時的數據分析而所需的計算資源,則相對來說比較固定,是按需的。
數據派生能力
一個完整的數據系統架構下,需要有多個存儲組件并存。并且根據對查詢和分析能力的不同要求,需要在數據派生體系下對輔存儲進行動態擴展。所以對于結構化大數據存儲來說,也需要有能擴展輔存儲的派生能力,來擴展數據處理能力。而判斷一個存儲組件是否具備更好的數據派生能力,就看是否具備成熟的CDC技術。
計算生態
數據的價值需要靠計算來挖掘,目前計算主要劃為批量計算和流計算。對于結構化大數據存儲的要求,一是需要能夠對接主流的計算引擎,例如Spark、Flink等,作為輸入或者是輸出;二是需要有數據派生的能力,將自身數據轉換為面向分析的列存格式存儲至數據湖系統;三是自身提供交互式分析能力,更快挖掘數據價值。
滿足第一個條件是最基本要求,滿足第二和第三個條件才是加分項。
開源產品
目前開源界比較知名的結構化大數據存儲是HBase和Cassandra,Cassandra是WideColumn模型NoSQL類別下排名Top-1的產品,在國外應用比較廣泛。但這里我們重點提下HBase,因為在國內的話相比Cassandra會更流行一點。
HBase是基于HDFS的存儲計算分離架構的WideColumn模型數據庫,擁有非常好的擴展性,能支撐大規模數據存儲,它的優點為:
存儲計算分離架構:底層基于HDFS,分離的架構可帶來存儲和計算各自彈性擴展的優勢,與計算引擎例如Spark可共享計算資源,降低成本。
LSM存儲引擎:為寫入優化設計,能提供高吞吐的數據寫入。
開發者生態成熟,接入主流計算引擎:作為發展多年的開源產品,在國內也有比較多的應用,開發者社區很成熟,對接幾大主流的計算引擎。
HBase有其突出的優點,但也有幾大不可忽視的缺陷:
查詢能力弱:提供高效的單行隨機查詢以及范圍掃描,復雜的組合條件查詢必須使用Scan+Filter的方式,稍不注意就是全表掃描,效率極低。HBase的Phoenix提供了二級索引來優化查詢,但和MySQL的二級索引一樣,只有符合最左匹配的查詢條件才能做索引優化,可被優化的查詢條件非常有限。
數據派生能力弱:前面章節提到CDC技術是支撐數據派生體系的核心技術,HBase不具備CDC技術。HBase Replication具備CDC的能力,但是僅為HBase內部主備間的數據同步機制。有一些開源組件利用其內置Replication能力來嘗試擴展HBase的CDC技術,例如用于和Solr同步的Lily Indexer,但是比較可惜的是這類組件從理論和機制上分析就沒法做到CDC技術所要求的數據保序、最終一致性保證等核心需求。
成本高:前面提到結構化大數據存儲的關鍵需求之一是存儲與計算的成本分離,HBase的成本取決于計算所需CPU核數成本以及磁盤的存儲成本,基于固定配比物理資源的部署模式下CPU和存儲永遠會有一個無法降低的最小比例關系。即隨著存儲空間的增大,CPU核數成本也會相應變大,而不是按實際所需計算資源來計算成本。要達到完全的存儲與計算成本分離,只有云上的Serverless服務模式才能做到。
運維復雜:HBase是標準的Hadoop組件,最核心依賴是Zookeeper和HDFS,沒有專業的運維團隊幾乎無法運維。
熱點處理能力差:HBase的表的分區是Range Partition的方式,相比Hash Partition的模式最大的缺陷就是會存在嚴重的熱點問題。HBase提供了大量的最佳實踐文檔來指引開發者在做表的Rowkey設計的時候避免熱點,例如采用hash key,或者是salted-table的方式。但這兩種方式下能保證數據的分散均勻,但是無法保證數據訪問的熱度均勻。訪問熱度取決于業務,需要一種能根據熱度來對Region進行Split或Move等負載均衡的自動化機制。
國內的高級玩家大多會基于HBase做二次開發,基本都是在做各種方案來彌補HBase查詢能力弱的問題,根據自身業務查詢特色研發自己的索引方案,例如自研二級索引方案、對接Solr做全文索引或者是針對區分度小的數據集的bitmap索引方案等等。總的來說,HBase是一個優秀的開源產品,有很多優秀的設計思路值得借鑒。
Tablestore
Tablestore是阿里云自研的結構化大數據存儲產品,具體產品介紹可以參考官網以及權威指南。Tablestore的設計理念很大程度上顧及了數據系統內對結構化大數據存儲的需求,并且基于派生數據體系這個設計理念專門設計和實現了一些特色的功能。
設計理念
Tablestore的設計理念一方面吸收了優秀開源產品的設計思路,另一方面也是結合實際業務需求演化出了一些特色設計方向,簡單概括下Tablestore的技術理念:
存儲計算分離架構:采用存儲計算分離架構,底層基于飛天盤古分布式文件系統,這是實現存儲計算成本分離的基礎。
LSM存儲引擎:LSM和B+tree是主流的兩個存儲引擎實現,其中LSM專為高吞吐數據寫入優化,也能更好的支持數據冷熱分層。
Serverless產品形態:基于存儲計算分離架構來實現成本分離的最關鍵因素是Serverless服務化,只有Serverless服務才能做到存儲計算成本分離。大數據系統下,結構化大數據存儲通常會需要定期的大規模數據導入,來自在線數據庫或者是來自離線計算引擎,在此時需要有足夠的計算能力能接納高吞吐的寫入,而平時可能僅需要比較小的計算能力,計算資源要足夠的彈性。另外在派生數據體系下,主存儲和輔存儲通常是異構引擎,在讀寫能力上均有差異,有些場景下需要靈活調整主輔存儲的配比,此時也需要存儲和計算資源彈性可調。
多元化索引,提供豐富的查詢能力:LSM引擎特性決定了查詢能力的短板,需要索引來優化查詢。而不同的查詢場景需要不同類型的索引,所以Tablestore提供多元化的索引來滿足不同類型場景下的數據查詢需求。
CDC技術:Tablestore的CDC技術名為Tunnel Service,支持全量和增量的實時數據訂閱,并且能無縫對接Flink流計算引擎來實現表內數據的實時流計算。
擁抱開源計算生態:除了比較好的支持阿里云自研計算引擎如MaxCompute和Data Lake Analytics的計算對接,也能支持Flink和Spark這兩個主流計算引擎的計算需求,無需數據搬遷。
流批計算一體:能支持Spark對表內全量數據進行批計算,也能通過CDC技術對接Flink來對表內新增數據進行流計算,真正實現批流計算結合。
特色功能
多元化索引
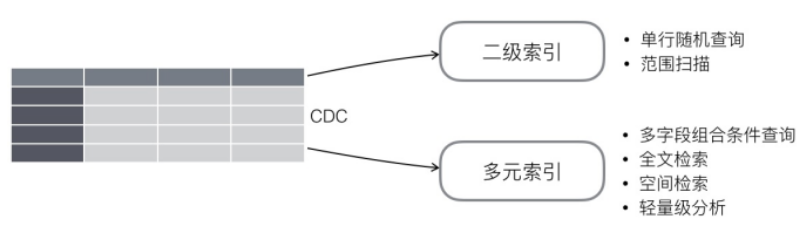
Tablestore提供多種索引類型可選擇,包含全局二級索引和多元索引。全局二級索引類似于傳統關系數據庫的二級索引,能為滿足最左匹配原則的條件查詢做優化,提供低成本存儲和高效的隨機查詢和范圍掃描。多元索引能提供更豐富的查詢功能,包含任意列的組合條件查詢、全文搜索和空間查詢,也能支持輕量級數據分析,提供基本的統計聚合函數,兩種索引的對比和選型可參考這篇文章。
通道服務
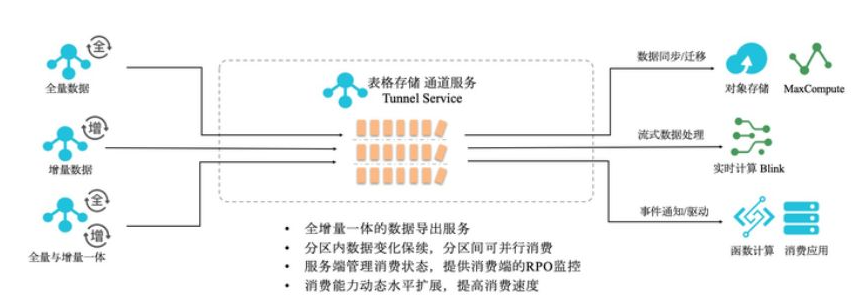
通道服務是Tablestore的CDC技術,是支撐數據派生體系的核心功能,具體能力可參考這篇文章。能夠被利用在異構存儲間的數據同步、事件驅動編程、表增量數據實時訂閱以及流計算場景。目前在云上Tablestore與Blink能無縫對接,也是唯一一個能直接作為Blink的stream source的結構化大數據存儲。
大數據處理架構
大數據處理架構是數據系統架構的一部分,其架構發展演進了多年,有一些基本的核心架構設計思路產出,例如影響最深遠的Lambda架構。Lambda架構比較基礎,有一些缺陷,所以在其基礎上又逐漸演進出了Kappa、Kappa+等新架構來部分解決Lambda架構中存在的一些問題,詳情介紹可以看下這篇文章的介紹。Tablestore基于CDC技術來與計算引擎相結合,基于Lambda架構設計了一個全新的Lambda plus架構。
Lambda plus架構
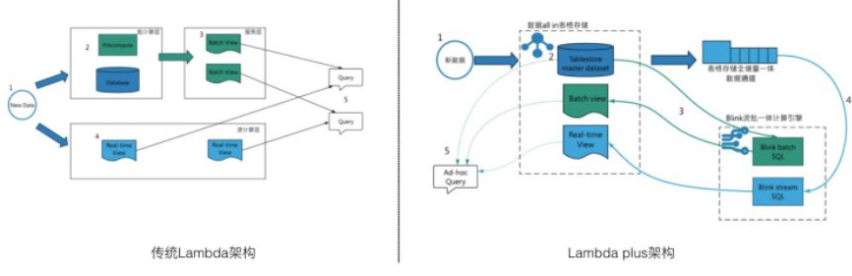
Lambda架構的核心思想是將不可變的數據以追加的方式并行寫到批和流處理系統內,隨后將相同的計算邏輯分別在流和批系統中實現,并且在查詢階段合并流和批的計算視圖并展示給用戶。基于Tablestore CDC技術我們將Tablestore與Blink進行了完整對接,可作為Blink的stream source、dim和sink,推出了Lambda plus架構:
Lambda plus架構中數據只需要寫入Tablestore,Blink流計算框架通過通道服務API直讀表內的實時更新數據,不需要用戶雙寫隊列或者自己實現數據同步。
存儲上,Lambda plus直接使用Tablestore作為master dataset,Tablestore支持用戶在線系統低延遲讀寫更新,同時也提供了索引功能進行高效數據查詢和檢索,數據利用率高。
計算上,Lambda plus利用Blink流批一體計算引擎,統一流批代碼。
展示層,Tablestore提供了多元化索引,用戶可自由組合多類索引來滿足不同場景下查詢的需求。
總結
本篇文章我們談了數據系統架構下的核心組件以及關于存儲組件的選型,介紹了派生數據體系這一設計理念。在派生數據體系下我們能更好的理清存儲組件間的數據流關系,也基于此我們對結構化大數據存儲這一組件提了幾個關鍵需求。阿里云Tablestore正是基于這一理念設計,并推出了一些特色功能,希望能通過本篇文章對我們有一個更深刻的了解。
在未來,我們會繼續秉承這一理念,為Tablestore內的結構化大數據派生更多的便于分析的能力。會與開源計算生態做更多整合,接入更多主流計算引擎。
作者 木洛,阿里云存儲高級技術專家
-
大數據
+關注
關注
64文章
8950瀏覽量
139465 -
大數據存儲
+關注
關注
0文章
8瀏覽量
4360
發布評論請先 登錄
SoC芯片設計系列-ARM CPU子系統組件介紹
什么是RFID通訊組件?有哪些應用?
ARM Cortex-A710核心技術參考手冊
HarmonyOS系統中基礎UI組件

媒體組件的播放和錄制功能實現教程







 工商網監
工商網監
評論