") 使用NVIDIA多個DPU加速HPC集群中的科學應用
使用NVIDIA多個DPU加速HPC集群中的科學應用
高性能計算( HPC )和人工智能已經(jīng)將超級計算機作為主要的數(shù)據(jù)處理引擎,廣泛應用于商業(yè)領域,使研究、科學發(fā)現(xiàn)和產(chǎn)品開發(fā)成為可能。這些系統(tǒng)可以進行復雜的模擬,開啟軟件編寫軟件的人工智能新時代。
超級計算領導力是指科學和創(chuàng)新領導力,它解釋了許多政府、研究機構(gòu)和企業(yè)為構(gòu)建更快、更強大的超級計算平臺而進行的投資。從超級計算系統(tǒng)中提取盡可能高的性能,同時實現(xiàn)高效利用,傳統(tǒng)上與現(xiàn)代云計算的安全、多租戶體系結(jié)構(gòu)不兼容。
一個云本地超級計算平臺首次提供了兩全其美,將峰值性能和集群效率與安全隔離和多租戶的現(xiàn)代零信任模型結(jié)合起來。實現(xiàn)這種架構(gòu)轉(zhuǎn)換的關(guān)鍵元素是 NVIDIA BlueField 數(shù)據(jù)處理單元( DPU )。 DPU 是一個完全集成的片上數(shù)據(jù)中心平臺,為每個超級計算節(jié)點注入了兩種新功能:
基礎設施控制平面處理器 – 保護用戶訪問、存儲訪問、網(wǎng)絡和計算節(jié)點的生命周期編排,減輕主計算處理器的負擔并實現(xiàn)裸機多租戶。
帶硬件加速的隔離線速率數(shù)據(jù)通路 – 實現(xiàn)裸機性能。
HPC 和 AI 通信框架和庫對延遲和帶寬敏感,它們在決定應用程序性能方面起著關(guān)鍵作用。將庫從主機 CPU 或 GPU 卸載到 BlueField DPU 為通信和計算的并行進程創(chuàng)建了最高程度的重疊。它還減少了操作系統(tǒng)抖動的負面影響,顯著提高了應用程序性能。
云本地超級計算機體系結(jié)構(gòu)的開發(fā)基于開放社區(qū)開發(fā),包括商業(yè)公司、學術(shù)組織和政府機構(gòu)。這個不斷增長的社區(qū)對于開發(fā)下一代超級計算至關(guān)重要。
我們在本文中分享的一個例子是 MVAPICH2- DPU 庫,由 X-ScaleSolutions 設計和開發(fā)。 MVAPICH2- DPU 庫包含了消息傳遞接口( MPI )標準的非阻塞集合的卸載。這篇文章概述了這種卸載背后的基本概念,以及最終用戶如何使用 MVAPICH2- DPU MPI 庫來加速科學應用程序的執(zhí)行,特別是使用密集的非阻塞 all-to-all 操作。
BlueField DPU
圖 1 顯示了 BlueField DPU 體系結(jié)構(gòu)及其與主機計算平臺的連接的概述。 DPU 通過 ConnectX-6 適配器具有 InfiniBand 網(wǎng)絡連接。此外,它還有一組 Arm 內(nèi)核。 Bluefield-2 DPU 有一組 8 個 Arm 內(nèi)核,每個內(nèi)核的工作頻率為 2 。 0ghz 。 Arm 內(nèi)核還有 16GB 的共享內(nèi)存。
MVAPICH2- DPU MPI 庫
MVAPICH2- DPU MPI 庫是 MVMPI 庫 的派生。該庫經(jīng)過優(yōu)化,可利用 InfiniBand 網(wǎng)絡充分發(fā)揮 BlueField DPU 的潛力。
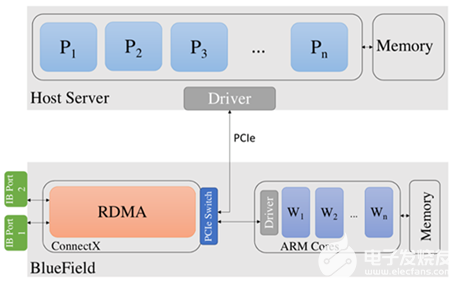
圖 1 BlueField DPU 的體系結(jié)構(gòu)及其與主機平臺的連接
最新的 MVAPICH2- DPU 2021 。 06 版本具有以下功能:
基于 MVAPICH2 2 。 3 。 6 ,符合 MPI 3 。 1 標準
支持 MV2 。 3 。 6 版本 提供的所有功能
將非阻塞集合卸載到 DPU 的新框架
將非阻塞 Alltoall ( MPI \ Ialltoall )卸載到 DPU
所有非阻塞集合的計算重疊率為 100%
使用 MPI Ialltoall 非阻塞集合加速科學應用
MVAPICH2- DPU MPI 庫入門
MVAPICH2- DPU 庫可從 X-ScaleSolutions 獲得:
發(fā)送電子郵件至 contac[email protected]
填寫聯(lián)系人 形式
有關(guān)更多信息,請參閱 MVAPICH2-DPU 產(chǎn)品頁。
OSU 微基準的示例執(zhí)行
OSU MPI 微基準 的副本與 MVAPICH2- DPU MPI 包集成在一起。 OMB 基準套件由非阻塞集體操作的基準組成。這些基準旨在評估非阻塞 MPI 集合使用的計算和通信之間的重疊能力。
可以執(zhí)行 OMB 包中的非阻塞集體基準,以評估以下指標:
重疊功能
啟動非阻塞集合后立即合并計算步驟時的總執(zhí)行時間
在 HPC-AI 咨詢委員會集群上運行了一組 OMB 實驗,其中 32 個節(jié)點與支持 HDR 200Gb / s InfiniBand 連接的 32 個 BlueField DPU s 相連。每個主機節(jié)點都有雙插槽 Intel Xeon 16 核 CPU E5-2697A V4 @ 2 。 60 GHz 。每個 Bluefield-2 DPU 有 8 個 Arm 核@ 2 。 0ghz 和 16gb 內(nèi)存。
圖 2 顯示了分別運行 512 個( 32 個節(jié)點,每個節(jié)點有 16 個進程( PPN ))和 1024 個( 32 個節(jié)點,每個節(jié)點有 32 個 PPN ) MPI 進程的 MPI \ u ialtoall 非阻塞集合基準的性能結(jié)果。隨著消息大小的增加, MVAPICH2- DPU 庫可以顯示計算和 MPI Ialltoall 非阻塞集合之間的峰值( 100% )重疊。相比之下,沒有這種 DPU 卸載功能的 MVAPICH2 默認庫可以在計算和 MPI (所有非阻塞)集合之間提供很少的重疊。
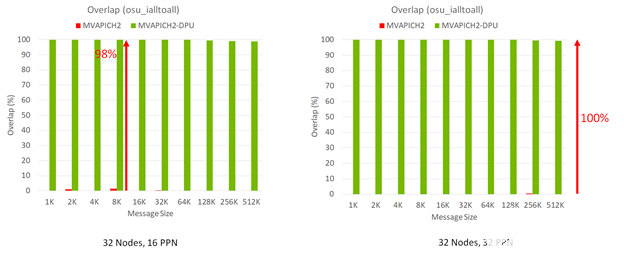
圖 2 MVAPICH2- DPU 庫提取主機和服務器上發(fā)生的計算之間的峰值重疊的能力 MPI_Ialltoall 通信
當 MPI 應用程序中的計算步驟以重疊方式與 MPI Ialltoall 非阻塞集合操作一起使用時, MVAPICH2- DPU MPI 庫在整個程序執(zhí)行時間內(nèi)提供了顯著的性能優(yōu)勢。這是可能的,因為 DPU 中的 Arm 內(nèi)核可以實現(xiàn)非阻塞的 all-to-all 操作,而主機上的 Xeon 內(nèi)核正在執(zhí)行峰值重疊的計算(圖 2 )。
圖 3 顯示,與基本的 MVAPICH2 MPI 庫相比, MVAPICH2- DPU MPI 庫可以提供高達 23% 的性能優(yōu)勢。這是在 32 節(jié)點的 OMB-MPI-Iall 基準測試中跨消息大小和 ppn 的測試。
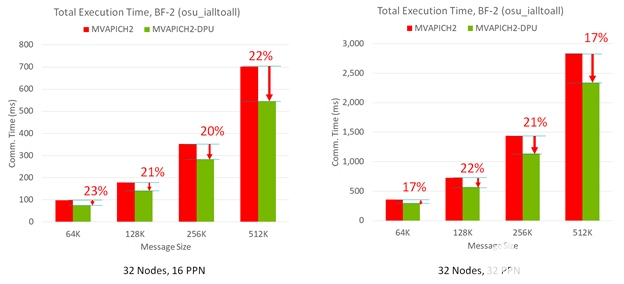
圖 3 當計算步驟與 MPI_Ialltoall 以重疊方式進行非阻塞集體操作
加速 P3DFFT 應用程序內(nèi)核
P3DFFT 是一種常見的 MPI 內(nèi)核,用于許多使用快速傅立葉變換( FFT )的終端應用程序。這個 MPI 內(nèi)核的一個版本是由 P3DFFT 開發(fā)人員設計的,它使用非阻塞的 all-to-all 集合操作和計算步驟來利用最大的重疊。
P3DFFT MPI 內(nèi)核的增強版本在 32 節(jié)點 HPC-AI 集群上使用 MVAPICH2- DPU MPI 庫進行了評估。圖 4 顯示了 MVAPICH2- DPU MPI 庫將 P3DFFT 應用程序內(nèi)核的總體執(zhí)行時間減少了 21% ,適用于各種網(wǎng)格大小和 ppn 。
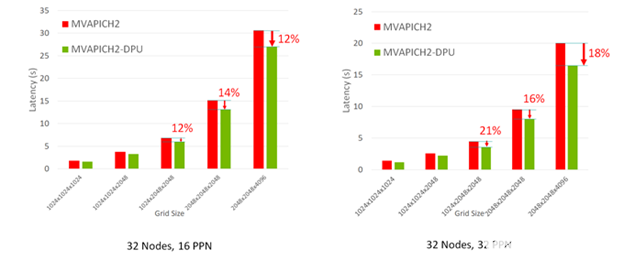
圖 4 MVAPICH2- DPU 庫減少 P3DFFT 應用程序總執(zhí)行時間的能力。
概括
NVIDIA DPU 體系結(jié)構(gòu)提供了新的功能,可以將任何中間件的功能卸載到 DPU 上的可編程 Arm 內(nèi)核。必須重新設計 MPI 庫,以利用這些功能加速科學應用。
MVAPICH2- DPU MPI 庫是利用這種 DPU 功能的領先庫。 MVAPICH2- DPU 庫的初始版本提供了對 MPI \ u ialtoall nonblocking collectives 的卸載支持,顯示了計算和非阻塞 alltoall collective 之間 100% 的重疊。在 1024mpi 進程運行時,它可以將 P3DFFT 應用程序內(nèi)核執(zhí)行時間縮短 21% 。
這項研究證明了使用 MVAPICH2- DPU MPI 庫的 DPU 體系結(jié)構(gòu)具有很強的 ROI 。隨著 DPU 體系結(jié)構(gòu)的進步,即將發(fā)布的其他 MPI 功能的附加卸載功能將顯著加快云本地超級計算系統(tǒng)上的科學應用。
關(guān)于作者
Gilad Shainer 擔任 NVIDIA Mellanox networking 的營銷高級副總裁,專注于高性能計算、人工智能和 InfiniBand 技術(shù)。
Dhabaleswar K (DK) Panda 是 X-SaleSalOffice 的創(chuàng)始人和 CEO ,也是俄亥俄州立大學計算機科學教授和杰出學者。
Nick Sarkauskas 是俄亥俄州立大學計算機科學與工程系博士學位的軟件工程師。他目前在 X-ScaleSolutions 的工作是設計和開發(fā) MVAPICH2- DPU 軟件堆棧。他的研究興趣包括高性能計算、高性能互連和并行算法。 Nick Sarkauskas 于 2020 年從 OSU 獲得計算機科學與工程學士學位。
審核編輯:郭婷
-
NVIDIA
+關(guān)注
關(guān)注
14文章
5242瀏覽量
105769 -
人工智能
+關(guān)注
關(guān)注
1804文章
48708瀏覽量
246492 -
應用程序
+關(guān)注
關(guān)注
38文章
3322瀏覽量
58727
發(fā)布評論請先 登錄
NVIDIA攜手微軟加速代理式AI發(fā)展
第三屆NVIDIA DPU黑客松開啟報名
使用NVIDIA CUDA-X庫加速科學和工程發(fā)展
Cadence 利用 NVIDIA Grace Blackwell 加速AI驅(qū)動的工程設計和科學應用
英偉達GTC2025亮點:Oracle與NVIDIA合作助力企業(yè)加速代理式AI推理

Oracle 與 NVIDIA 合作助力企業(yè)加速代理式 AI 推理

利用NVIDIA DPF引領DPU加速云計算的未來
在NVIDIA BlueField-3 DPU上運行WEKA客戶端的實際優(yōu)勢






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論