 NVIDIA Merlin深度推薦系統應用框架的優化方法
NVIDIA Merlin深度推薦系統應用框架的優化方法
推薦系統驅動你在網上采取的每一個行動,從你現在正在閱讀的網頁的選擇到更明顯的例子,如網上購物。它們在推動用戶參與在線平臺、從成倍增長的可用選項中選擇一些相關商品或服務方面發揮著關鍵作用。在一些最大的商業平臺上,推薦占據了高達 30% 的收入。推薦質量提高 1% 就可以帶來數十億美元的收入。
隨著行業數據集規模的快速增長,深度學習( Deep Learning , DL )推薦模型利用了大量的訓練數據,與傳統的基于內容、鄰域和潛在因素的推薦方法相比,具有越來越大的優勢。 DL 推薦模型是建立在現有技術的基礎上的,例如 embeddings 用來處理分類變量,以及 factorization 用來建模變量之間的相互作用。然而,他們也利用大量快速增長的關于新型網絡架構和優化算法的文獻來構建和訓練更具表現力的模型。
因此,更復雜的模型和快速數據增長的結合提高了培訓所需計算資源的門檻,同時也給生產系統帶來了新的負擔。為了滿足大規模 DL 推薦系統訓練和推理的計算需求, NVIDIA 引入了 Merlin 。
Merlin 是一個基于 – GPU 框架的端到端推薦程序,旨在提供快速功能工程和高訓練吞吐量,以實現 DL 推薦程序模型的快速實驗和生產再訓練。 Merlin 還支持低延遲、高吞吐量和生產推斷。
在深入研究 Merlin 之前,我們將進一步討論大規模推薦系統目前面臨的挑戰。
推薦系統概述
圖 1 顯示了一個端到端推薦系統體系結構示例。
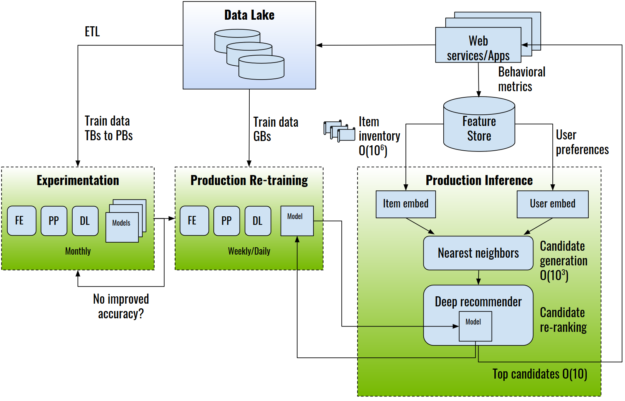
圖 1 。端到端推薦系統架構。 FE :特征工程; PP :預處理; ETL :提取轉換負載。
推薦系統是使用收集到的關于用戶、項目及其交互(包括印象、點擊、喜歡、提及等等)的數據來訓練的。這些信息通常存儲在數據湖或數據倉庫中。
在實驗階段,提取 – 轉換 – 加載( ETL )操作準備并導出用于培訓的數據集,通常以表格數據的形式,可以達到 TB 或 PB 級別。這種類型的一個示例公共數據集是 Criteo-Terabyte 點擊日志 dataset ,它包含 24 天內 40 億次交互的點擊日志。行業數據集可以大幾個數量級,包含多年的數據。
在實驗過程中,數據科學家和機器學習工程師使用特征工程,通過轉換現有特征來創建新的特征;以及預處理,為模型使用工程特征做準備。然后使用 DL 框架(如 TensorFlow 、 PyTorch 或 NVIDIA 推薦者特定的訓練框架 HugeCTR )執行訓練。
模型經過離線培訓和評估后,可以進入生產環境進行在線評估,通常是通過 A / B 測試。推薦系統的推理過程包括根據用戶與候選項交互的預測概率對候選項進行選擇和排序。
對于大型商業數據庫來說,選擇一個項目子集是必要的,因為有數百萬個項目可供選擇。選擇方法通常是一種高效的算法,例如近似最近鄰、隨機林或基于用戶偏好和業務規則的過濾。 DL 推薦模型對候選對象進行重新排序,并將預測概率最高的候選對象呈現給用戶。
推薦系統面臨的挑戰
培訓大規模推薦系統時面臨許多挑戰:
龐大的數據集: 商業推薦系統通常是在大數據集(通常是 TB 或更多)上訓練的。在這種規模下,數據 ETL 和預處理步驟通常比訓練 DL 模型花費更多的時間。
復雜的數據預處理和特征工程管線: 需要對數據集進行預處理,并將其轉換為與 DL 模型和框架一起使用的適當形式。同時,特征工程試驗從現有特征中創建了許多新特征集,然后對這些特征集進行有效性測試。此外,列車時刻的數據加載可能成為輸入瓶頸,導致 GPU 未充分利用。
大量重復實驗: 整個數據 ETL 、工程、培訓和評估過程可能必須在許多模型體系結構上重復多次,這需要大量的計算資源和時間。然而,在部署之后,推薦系統還需要定期進行再培訓,以了解新用戶、項目和最新趨勢,以便隨著時間的推移保持較高的準確性。
巨大的嵌入表: 嵌入是當今處理分類變量的一種普遍使用的技術,尤其是用戶和項目 ID 。在大型商業平臺上,用戶和項目庫很容易達到數億甚至數十億的數量,與其他類型的 DL 層相比,需要大量的內存。同時,與其他 DL 操作不同,嵌入查找是內存帶寬受限的。雖然 CPU 通常提供更大的內存池,但與 GPU 相比,它的內存帶寬要低得多。
分布式培訓: 正如 MLPerf benchmark 所反映的那樣,分布式訓練在視覺和自然語言領域的 DL 模型訓練中不斷創造新的記錄,但由于與其他領域和大型模型相比,大數據的獨特組合,分布式訓練對于推薦系統來說仍然是一個相對較新的領域。它要求模型并行和數據并行,因此很難實現高的擴展效率。
在生產中部署大規模推薦系統的一些顯著挑戰包括:
實時推斷: 對于每個查詢用戶,即使在候選縮減階段之后,要評分的用戶項對的數量也可能多達幾千個。這給 DL 推薦系統推理服務器帶來了極大的負擔,它必須處理高吞吐量以同時為許多用戶提供服務,同時還必須處理低延遲以滿足在線商務引擎嚴格的延遲閾值。
監測和再培訓: 推薦系統在不斷變化的環境中運行:新用戶注冊、新項目可用以及熱點趨勢出現。因此,推薦系統需要不斷的監測和再培訓,以確保高效率。推理服務器還必須能夠同時部署不同版本的模型,并動態加載/卸載模型,以便于 a / B 測試。
NVIDIA Merlin :在 NVIDIA GPU 上的端到端推薦系統
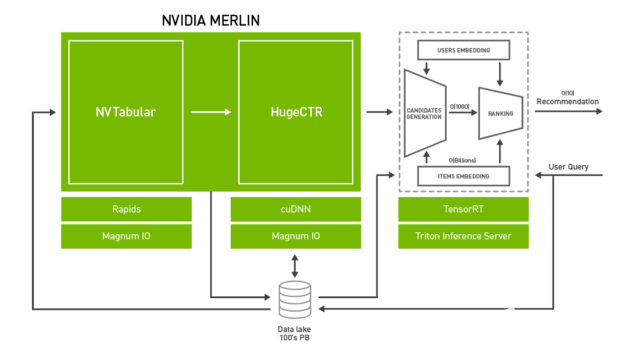
圖 2 。 Merlin 架構。
為了系統地解決上述挑戰,NVIDIA 引入了 Merlin。 NVIDIA Merlin 是一個應用程序框架和生態系統,旨在促進推薦系統開發的所有階段,從實驗到生產,并在 NVIDIA GPU 上加速。圖 2 顯示了 Merlin 的架構圖,包含三個主要組件:
Merlin ETL 公司: 一組用于在 GPU 上進行快速推薦系統功能工程和預處理的工具。 NVTabular 提供高速的、在 GPU 上的數據預處理和轉換功能,以處理 TB 級的表格數據集。 NVTabular 的輸出可以通過 NVTabular 數據加載器擴展以高吞吐量提供給訓練框架,例如 NVTabular 、 PyTorch 或 TensorFlow ,從而消除輸入瓶頸。
Merlin 培訓: DL 推薦系統模型和培訓工具的集合:
HugeCTR 是一種高效的 C ++推薦系統專用培訓框架。它具有多點 GPU 和多節點訓練,并支持模型并行和數據并行擴展。 HugeCTR 涵蓋了常見和最新的推薦系統架構,如 寬而深 ( W & D )、 深交叉網絡 和 DeepFM ,深度學習推薦模型( DLRM )支持即將推出。
DLRM 、 寬深( W & D ) 、 神經協同濾波 和 可變自動編碼器( VAE ) 構成了 NVIDIA GPU – 加速 DL 模型組合 的一部分,它涵蓋了除推薦系統之外的許多不同領域的廣泛網絡體系結構和應用,包括圖像、文本和語音分析。這些模型是為訓練而設計和優化的 TensorFlow 和 PyTorch 。
Merlin 推論: NVIDIA TensorRT 和 NVIDIA Triton ?聲波風廓線儀推斷服務器 (以前的 TensorRT 推理服務器)。
NVIDIA TensorRT 是一個用于高性能 DL 推理的 SDK 。它包括一個 DL 推理優化器和運行時,為 DL 推理應用程序提供低延遲和高吞吐量。
Triton Server 提供了一個全面的 GPU 優化推斷解決方案,允許使用各種后端的模型,包括 PyTorch 、 TensorFlow 、 TensorRT 和開放式神經網絡交換( ONNX )運行時。 Triton Server 自動管理和利用所有可用的 GPU ,并提供為模型的多個版本提供服務和報告各種性能指標的能力,從而實現有效的模型監控和 a / B 測試。
在接下來的部分中,我們將依次探討這些組件中的每一個。
NVTabular :快速表格數據轉換和加載
對推薦系統數據集執行特征工程和預處理所花費的時間常常超過訓練模型本身所花費的時間。作為一個具體的例子,使用開源提供的腳本處理 Criteo-Terabyte 點擊日志 dataset 需要 5 。 5 天才能完成,而在單個 V100 GPU 上對已處理數據集上的 DLRM 進行培訓則需要不到一個小時的時間。
NVTabular 是一個功能工程和預處理庫,旨在快速方便地操作 TB 級數據集。它特別適用于推薦系統,推薦系統需要一種可伸縮的方式來處理附加信息,例如用戶和項目元數據以及上下文信息。它提供了一個高級抽象,以簡化代碼并使用 cuDF cuDF 庫加速 GPU 上的計算。使用 NVTabular ,只需 10-20 行高級 API 代碼,就可以建立一個數據工程管道,與優化的基于 CPU 的方法相比,可以實現高達 10 倍的加速,同時不受數據集大小的限制,而不管 GPU / CPU 內存容量如何。
執行 ETL 所用的總時間是運行代碼所用時間和編寫代碼所用時間的混合。 RAPIDS 團隊在 GPU 上加速了 Python 數據科學生態系統,并通過 cuDF 、 Apache Spark 3 。 0 和 Dask- cuDF 提供了加速。
NVTabular 使用了這些加速,但提供了一個更高級別的 API ,重點放在推薦系統上,這大大簡化了代碼復雜性,同時仍然提供相同級別的性能。圖 3 顯示了 NVTabular 相對于其他數據幀庫的位置。
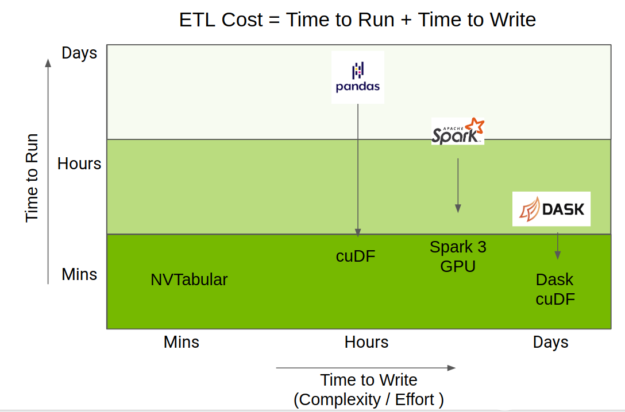
圖 3 。 NVTabular 與其他流行數據幀庫的定位比較。
下面的代碼示例顯示了轉換 1-TB Criteo Ads 數據集所需的實際預處理工作流,使用 NVTabular 只需十幾行代碼即可實現。簡單地說,指定了數字列和分類列。接下來,我們定義一個 NVTabular 工作流,并提供一組訓練和驗證文件。然后,將預處理操作添加到工作流中,并將數據持久化到磁盤。相比之下,定制的處理代碼,比如 Facebook 的 DLRM 實現中基于 NumPy 的 有用數據 ,在同一管道中可以有 500-1000 行代碼。
import nvtabular as nvt
import glob
cont_names = ["I"+str(x) for x in range(1, 14)] # specify continuous feature names
cat_names = ["C"+str(x) for x in range(1, 27)] # specify categorical feature names
label_names = ["label"] # specify target feature
columns = label_names + cat_names + cont_names # all feature names
# initialize Workflow
proc = nvt.Worfklow(cat_names=cat_names, cont_names=cont_names, label_name=label_names)
# create datsets from input files
train_files = glob.glob("./dataset/train/*.parquet")
valid_files = glob.glob("./dataset/valid/*.parquet")
train_dataset = nvt.dataset(train_files, gpu_memory_frac=0.1)
valid_dataset = nvt.dataset(valid_files, gpu_memory_frac=0.1)
# add feature engineering and preprocessing ops to Workflow
proc.add_cont_feature([nvt.ops.ZeroFill(), nvt.ops.LogOp()])
proc.add_cont_preprocess(nvt.ops.Normalize())
proc.add_cat_preprocess(nvt.ops.Categorify(use_frequency=True, freq_threshold=15))
# compute statistics, transform data, export to disk
proc.apply(train_dataset, shuffle=True, output_path="./processed_data/train", num_out_files=len(train_files))
proc.apply(valid_dataset, shuffle=False, output_path="./processed_data/valid", num_out_files=len(valid_files))
圖 5 顯示了 NVTabular 相對于原始 DLRM 預處理腳本的相對性能,以及在單節點集群上運行的 Spark 優化的 ETL 進程。值得注意的是培訓占用的時間與 ETL 占用的時間的百分比。在基線情況下, ETL 與訓練的比率幾乎完全符合數據科學家花費 75% 時間處理數據的普遍說法。在 NVTabular 中,這種關系被翻轉了。
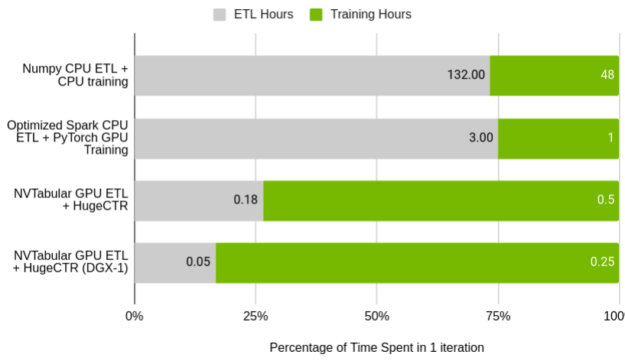
圖 5 。 NVTabular 準則比較。
GPU ( Tesla V100 32 GB )與 CPU ( AWS r5d 。 24xl , 96 核, 768 GB RAM )
使用原始腳本在 CPU 上處理數據集和訓練模型所花費的總時間超過一周。通過大量的努力,使用 Spark 進行 ETL 和 GPU 上的培訓可以減少到四個小時。使用本文后面將介紹的 NVTabular 和 HugeCTR ,您可以將單個 GPU 的迭代時間縮短到 40 分鐘,將 DGX-1 集群的迭代時間縮短到 18 分鐘。在后一種情況下, 40 億個交互數據集只需 3 分鐘即可處理完畢。
HugeCTR : GPU ——大型 CTR 機型加速訓練
HugeCTR 是一個高效的 GPU 框架,設計用于推薦模型訓練,目標是高性能和易用性。它既支持簡單的深層車型,也支持最先進的混合動力車型,如 W&D 、 深交叉網絡 和 DeepFM 。我們還致力于使用 HugeCTR 啟用 DLRM 。模型細節和超參數可以用 JSON 格式輕松指定,允許從一系列常見模型中快速選擇。
與 PyTorch 和 TensorFlow 等其他通用 DL 框架相比, HugeCTR 專門設計用于加速大規模 CTR 模型的端到端訓練性能。為了防止數據加載成為訓練中的主要瓶頸,它實現了一個專用的數據讀取器,該讀取器本質上是異步的和多線程的,因此數據傳輸時間與 GPU 計算重疊。
HugeCTR 中的嵌入表是模型并行的,分布在一個由多個節點和多個 GPU 組成的集群中的所有 GPU 上。這些模型的密集組件是數據并行的,每個模型上有一個副本 GPU (圖 6 )。
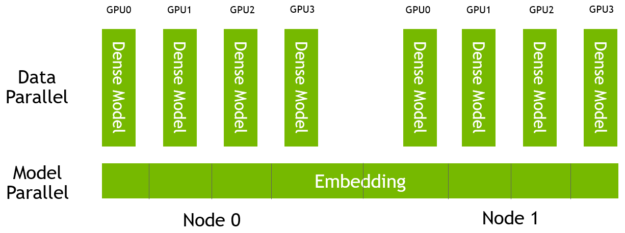
圖 6 。 HugeCTR 模型和數據并行架構。
對于高速可擴展的節點間和節點內通信, HugeCTR 使用 NCCL 。對于有許多輸入特征的情況, HugeCTR 嵌入表可以分割成多個槽。將屬于同一時隙的特征獨立地轉換為相應的嵌入向量,然后將其降為單個嵌入向量。它允許您有效地將每個插槽中有效功能的數量減少到可管理的程度。
圖 7a 顯示了 W & D 網絡的訓練性能, HugeCTR 在 Kaggle 數據集 上的單個 V100 GPU 上,與相同 GPU 上的 TensorFlow 和雙 20 核 Intel Xeon CPU E5-2698 v4 上的 HugeCTR 相比, HugeCTR 的加速比 TensorFlow CPU 高達 54 倍,是 TensorFlow GPU 的 4 倍。為了重現結果, HugeCTR repo 中提供了 寬深樣品 ,包括指令和 JSON 模型配置文件。
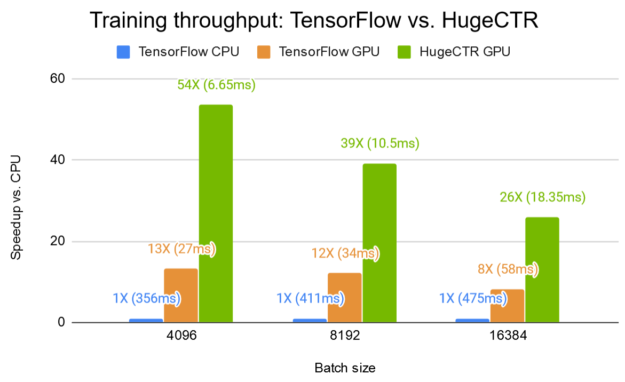
圖 7a 。 TensorFlow v2 。 0 CPU 和 GPU 與 HugeCTR v2 。 1 在單個 V100 16-GB GPU 上的性能比較。 CPU :雙 20 核 Intel ( R ) Xeon ( R ) CPU E5-2698 v4 @ 2 。 20GHz ( 80 線程)。型號: W & D , 2 × 1024 FC 層。條形圖表示加速系數 vs 。 TensorFlow CPU 。越高越好。括號中的數字表示一次迭代所用的平均時間。
圖 7b 顯示了 HugeCTR 在 DGX-1 上對全精度模式( FP32 )和混合精度模式( FP16 )采用更深入的 W & D 模型的強縮放結果。
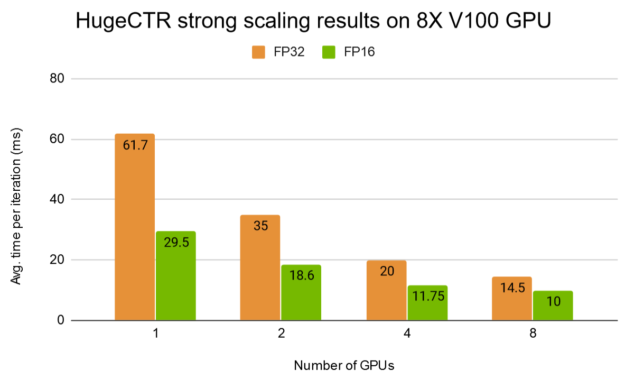
圖 7b 。 HugeCTR 8X V100 16-GB GPU 上的強縮放結果。批量: 16384 。型號: W & D , 7 × 1024 FC 層。
NVIDIA 推薦系統模型組合
DLRM 、 寬而深 、 NCF 和 VAE 構成較大的 NVIDIA GPU – 加速 DL 模型組合 的一部分。在本節中,我們將展示 DLRM 的參考實現。
與其他基于 DL 的方法一樣, DLRM 被設計成同時使用分類和數字輸入,這通常存在于推薦系統的訓練數據中。模型架構如圖 8 所示。
為了處理分類數據,嵌入層將每個分類映射到一個密集的表示,然后再將其輸入多層感知器( MLP )。數字特征可以直接輸入 MLP 。在下一級,通過計算所有嵌入向量對和處理后的密集特征之間的點積,顯式地計算不同特征的二階交互作用。這些成對交互被輸入到頂級 MLP 中,以計算用戶和項目對之間交互的可能性。
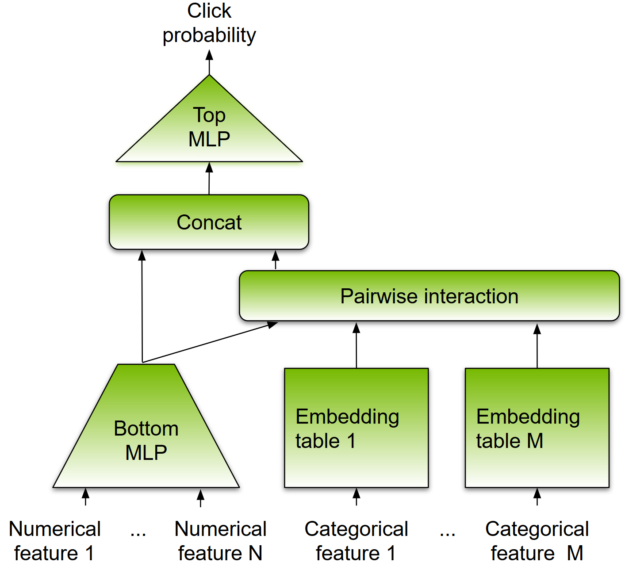
圖 8 。 DLRM 體系結構。
與其他基于 DL 的推薦方法相比, DLRM 在兩個方面有所不同。首先,它顯式計算特征交互,同時將交互順序限制為成對交互。其次, DLRM 將每個嵌入的特征向量(對應于分類特征)視為一個單元,而其他方法(如 Deep 和 Cross )將特征向量中的每個元素視為一個新單元,該單元應產生不同的交叉項。這些設計選擇有助于降低計算和內存成本,同時保持具有競爭力的準確性。
圖 9 顯示了 TB 數據集 上的 DLRM 訓練結果。在采用第三代張量核技術的 NVIDIA A100 GPU 上,采用混合精度訓練,與 CPU 上的訓練相比,訓練時間縮短了 67 倍。
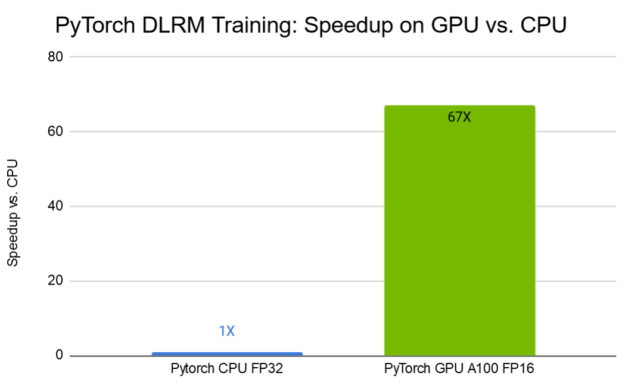
圖 9 。 DLRM 訓練性能。條形圖表示 GPU 與 CPU 。 CPU :雙 Intel ( R ) Xeon ( R ) Platinum 8168 @ 2 。 7 GHz ( 96 線程)。 GPU : Tesla A100 40 GB 。越高越好。
TensorRT 和 Triton Server 進行推斷
NVIDIA TensorRT 是一個用于高性能 DL 推理的 SDK 。它包括一個 DL 推理優化器和運行時,為推理應用程序提供低延遲和高吞吐量。 TensorRT 可以使用一個公共接口,即開放式神經網絡交換格式( ONNX ),從所有 DL 框架接受經過訓練的神經網絡。
TensorRT 可以使用垂直和水平層融合等操作,并使用降低的精度( FP16 , INT8 )利用了 NVIDIA GPU s 上張量核的高混合精度算術吞吐量。 TensorRT 還根據手頭的任務和目標 GPU 體系結構自動選擇最佳內核。對于進一步的特定于模型的優化, TensorRT 是高度可編程和可擴展的,允許您插入自己的插件層。
NVIDIA Triton 推斷服務器提供了一個針對 NVIDIA GPU s 優化的云推斷解決方案。服務器通過 HTTP 或 gRPC 端點提供推斷服務,允許遠程客戶端請求對服務器管理的任何模型進行推斷。 Triton Server 可以使用多種后端為 DL 推薦程序模型提供服務,包括 TensorFlow 、 PyTorch ( TorchScript )、 ONNX 運行時和 TensorRT 運行時。使用 DLRM ,我們展示了如何使用 Triton ?聲波風廓線儀部署預訓練的 PyTorch 模型,與 CPU 相比, A100 GPU 的延遲減少了 9 倍,如圖 10 所示。
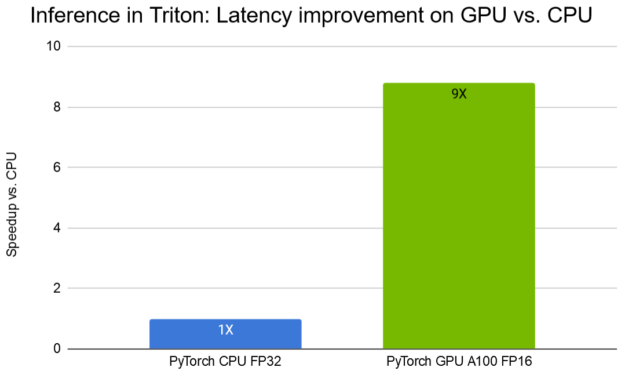
圖 10 。 DLRM 使用 Triton 推理服務器進行推理。條形圖表示 GPU 與 CPU 的加速系數。批量大小 2048 。 CPU :雙 Intel ( R ) Xeon ( R ) Platinum 8168 @ 2 。 7 GHz ( 96 線程)。 GPU : Tesla A100 40 GB 。越高越好。
在最近發表在 在 GPU s 上加速 Wide & Deep 推薦推理 上的文章中,作者詳細介紹了優化方法,使用 TensorFlow 估算器 API 訓練的 W & D 模型適合大規模生產部署。通過實現融合嵌入查找內核來利用 GPU 高內存帶寬,運行在 Triton Server 自定義后端, GPU W & D TensorRT 推理管道與同等的 CPU 推理管道相比,延遲減少了 18 倍,吞吐量提高了 17 。 6 倍。所有這些都是使用 Triton Server 部署的,以提供生產質量指標并確保生產健壯性。
結論
NVIDIA Merlin 的組件已作為開源項目提供:
NVTabular
HugeCTR
DLRM and other DL 推薦系統模型
TensorRT
Triton 推斷服務器
關于作者
Vinh Nguyen 是一位深度學習的工程師和數據科學家,發表了 50 多篇科學文章,引文超過 2500 篇。在 NVIDIA ,他的工作涉及廣泛的深度學習和人工智能應用,包括語音、語言和視覺處理以及推薦系統。
Even Oldridge 是 NVIDIA 的高級應用研究科學家,并領導開發 NVTabular 的團隊。他擁有計算機視覺博士學位,但在過去的五年里,他一直在推薦系統領域工作,專注于基于深度學習的推薦系統。
About Minseok Lee
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5267瀏覽量
105881 -
gpu
+關注
關注
28文章
4918瀏覽量
130766
發布評論請先 登錄
NVIDIA Isaac Sim與NVIDIA Isaac Lab的更新
NVIDIA NVLink 深度解析
利用NVIDIA DPF引領DPU加速云計算的未來
NVIDIA宣布NVIDIA Isaac重要更新
簡述NVIDIA Isaac的重要更新

Triton編譯器在機器學習中的應用
【AIBOX應用】通過 NVIDIA TensorRT 實現實時快速的語義分割

SSM框架的性能優化技巧 SSM框架中RESTful API的實現
NVIDIA RTX AI套件簡化AI驅動的應用開發
NVIDIA推出全新深度學習框架fVDB
SOK在手機行業的應用案例





 工商網監
工商網監
評論