 如何使用NVIDIA Merlin推薦系統框架實現嵌入優化
如何使用NVIDIA Merlin推薦系統框架實現嵌入優化
推薦系統是互聯網的經濟引擎。很難想象任何其他類型的應用程序會對我們的日常數字生活產生更直接的影響:數以萬億計的項目被推薦給數十億人。推薦系統會在大量選項中過濾產品和服務,從而緩解大多數用戶面臨的選擇悖論。
隨著數據量的增加,深度學習( DL )推薦系統開始顯示與傳統的基于機器學習的方法相比的優勢,例如梯度增強樹。為了給出一個具體的數據點, NVIDIA RAPIDS 。 AI 團隊與 DL 贏得了三場推薦比賽最近:
ACM RecSys2021 挑戰
SIGIR 和日期挑戰
ACM WSDM2021 Booking 。 com 挑戰賽
甚至在一年前 NVIDIA 數據科學家詢問為什么深度學習模型還沒有在推薦系統競賽中持續獲勝?時,這種情況也沒有持續發生。
嵌入在現代基于 DL 的推薦體系結構中起著關鍵作用,為數十億實體(用戶、產品及其特征)編碼單個信息。隨著數據量的增加,嵌入表的大小也隨之增加,現在這些表跨越多個 GB 到 TB 。在訓練這種類型的 DL 系統時存在著獨特的挑戰,其龐大的嵌入表和稀疏的訪問模式可能跨越多個 GPU 節點(如果不是節點的話)。
本文重點介紹 NVIDIA Merlin 推薦系統框架如何應對這些挑戰,并介紹了一種優化的嵌入實現,其性能比其他框架的嵌入層高出 8 倍。這個優化的實現也可以作為一個 TensorFlow 插件提供,它可以與 TensorFlow 無縫地工作,并作為 TensorFlow 本機嵌入層的方便替代品。
Embeddings
Embeddings 是一種機器學習技術,它將每個感興趣的對象(用戶、產品、類別等)表示為密集的數字向量。因此,嵌入表只是一種特定類型的鍵值存儲,鍵值是用于唯一標識對象的 ID ,值是實數向量。
Embeddings 是現代 DL 推薦系統中的一個關鍵構建塊,通常位于輸入層之后、“特征交互”和密集層之前。嵌入層是從數據和端到端訓練中學習的,就像深層神經網絡的其他層一樣。正是嵌入層將 DL recommender 模型與其他類型的 DL 工作負載區分開來:它們為模型提供了大量的參數,但幾乎不需要計算,而計算密集型密集層的參數數量要少得多。
舉一個具體的例子:原始博大精深模型有幾個密集的層,大小為[1024 、 512 、 256],因此只有幾百萬個參數,而其嵌入層可以有數十億個條目和數十億個參數。例如,這與 NLP 領域流行的 BERT 模型體系結構形成對比,其中嵌入層只有數萬個條目,總計數百萬個參數,但密集的前饋和注意層由數億個參數組成。這種差異還導致了另一個觀察:與其他類型的 DL 模型相比, DL recommender 網絡每字節輸入數據的計算量通常要小得多。
為什么優化嵌入對推薦者工作流很重要
為了理解為什么優化嵌入層和相關操作很重要,以下是培訓嵌入的挑戰:大小和訪問速度。
Size
隨著在線平臺和服務獲得數億甚至數十億用戶,以及提供的獨特產品數量達到數十億,嵌入表的規模不斷擴大也就不足為奇了。
據報道 Instagram 已被正在開發大小達到 10 TB 的推薦機型刪除。同樣,百度報告了廣告排名模型也達到了 10TB 的境界。在整個行業中,數百 GB 到 TB 的型號越來越流行,例如Pinterest 的 4-TB 模型和谷歌的 1 。 2 TB 模型。
很自然,在單個計算節點上擬合 TB 規模的模型是一個重大挑戰,更不用說在單個計算加速器上了。作為參考,最大的 NVIDIA A100 GPU 目前配備了 80 GB 的 HBM 。
訪問速度
訓練推薦系統本質上是一項內存帶寬密集型任務。這是因為每個訓練樣本或批通常在嵌入表中涉及少量實體。必須檢索這些條目以計算向前傳遞,然后在向后傳遞中更新。
CPU 主存儲器具有高容量,但帶寬有限,高端型號通常在幾十 GB / s 的范圍內。另一方面, GPU 的內存容量有限,但帶寬很高。 NVIDIA A100 80-GB GPU 提供 2 TB / s 的內存帶寬。
解決方案
這些挑戰以不同的方式得到解決。例如,將整個嵌入表保留在主存上可以解決大小問題。然而,它通常會導致極低的訓練吞吐量,這往往與新數據的數量和速度相形見絀,從而使系統無法及時重新訓練。
或者,嵌入可以被仔細地分散在多個 GPU S 和多個節點上,僅被通信瓶頸所困擾,導致持續嚴重的 GPU – 在使用和訓練性能下的計算與純 CPU 訓練正好一致。
嵌入層是推薦系統的主要瓶頸之一。優化嵌入層是解鎖 GPU 高計算吞吐量的關鍵。
在下一節中,我們將討論 NVIDIA Merlin HugeCTR 推薦框架如何通過使用 NVIDIA 技術,如 GPU 直接遠程直接內存訪問( RDMA )、 NVIDIA 集體通信圖書館( NCCL )、 NVLink 和 NVSwitch ,解決大規模嵌入式的挑戰。它解鎖了 GPU 的高計算和高帶寬容量,同時解決了開箱即用、多 GPU 、多節點支持和模型并行性的內存容量問題。
NVIDIA Merlin HugeCTR 嵌入概述
NVIDIA Merlin 解決了培訓大規模推薦系統的挑戰。它是一個端到端的推薦框架,可以加速推薦系統開發的所有階段,從數據預處理到培訓和推理。 NVIDIA Merlin HugeCTR 是一個開源的推薦系統,專用 DL 框架。在這篇文章中,我們關注 HugeCTR 的一個特定方面:嵌入優化。
有兩種方法可以利用 HugeCTR 中的嵌入優化工作:
將本機 NVIDIA Merlin HugeCTR 框架用于培訓和推理工作負載
使用 NVIDIA Merlin HugeCTR TensorFlow 插件,該插件旨在與 TensorFlow 無縫協作
原生 HugeCTR 嵌入優化
為了克服嵌入挑戰并實現更快的訓練, HugeCTR 實現了自己的嵌入層,其中包括 GPU 加速哈希表、以節省內存的方式實現的高效稀疏優化器以及各種嵌入分布策略。它利用NCCL作為其內部 GPU 通信原語。
哈希表實現基于 RAPIDS cuDF ,它是 GPU 數據幀庫,構成 NVIDIA 的 RAPIDS 數據科學平臺的一部分。 cuDF GPU 哈希表可以實現比 CPU 實現高達 35 倍的加速,例如來自線程構造塊( TBB )的并發_ hash _映射。有關更多信息,請參閱介紹 NVIDIA Merlin HugeCTR :一個專門用于推薦系統的培訓框架。
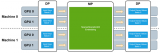
考慮到可伸縮性, HugeCTR 默認支持嵌入層的模型并行性。嵌入表分布在可用的 GPU 和節點上。另一方面,密集層采用數據并行(圖 1 )。
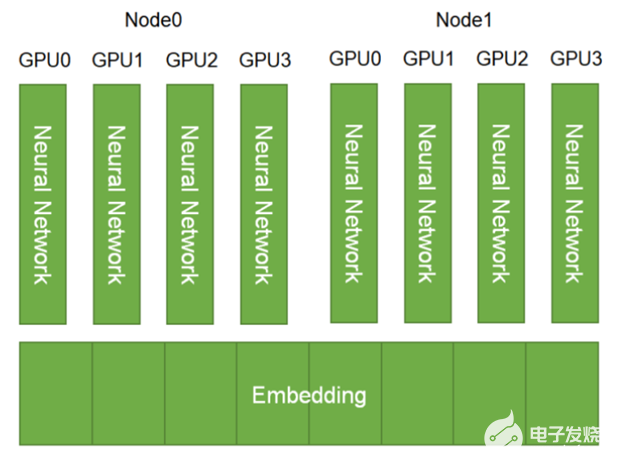
圖 1 。 HugeCTR 中的嵌入層并行性
騰訊推薦團隊是原生 HugeCTR 框架的首批采用者之一,大量使用了原生嵌入層。騰訊廣告與深度學習平臺負責人孔祥亭在最近的一次interview中表示,“ HugeCTR 作為一個推薦培訓框架,被整合到[騰訊]廣告推薦培訓系統中,以加快模型培訓的更新頻率,并可以培訓更多樣本以提高在線效果。”
HugeCTR TensorFlow 插件
NVIDIA Merlin 框架的所有組件都是開源的,旨在與更大的深度學習和數據科學生態系統進行互操作。我們的長期愿景是加速 GPU 上的推薦工作負載,而不管您喜歡哪種框架。 HugeCTR TensorFlow 嵌入插件是為了實現這一目標而創建的。
在高層次上, TensorFlow 嵌入插件是通過利用許多與本機 HugeCTR 嵌入層相同的嵌入優化技術來設計的。特別是,這將是 GPU 哈希表和 NCCL ,位于引擎蓋下,用于 GPU 之間的通信。
HugeCTR 嵌入插件設計為方便無縫地與 TensorFlow 配合使用,作為 TensorFlow 本機嵌入層(如tf.nn.embedding_lookup和tf.nn.embedding_lookup_sparse)的替代品。它還提供了開箱即用的高級功能,例如在多個 GPU 上分布嵌入表的模型并行性。
NVIDIA Merlin HugeCTR TensorFlow 插件演練
下面是如何使用 TensorFlow 嵌入插件。完整示例可在 HugeCTR repository上找到,我們還提供了完整的基準測試筆記本用于再現性能數據。
訪問 HugeCTR 嵌入插件最方便的方式是使用 NGC NVIDIA Merlin TensorFlow 培訓碼頭工人形象,在該插件中預編譯和安裝 NVIDIA Merlin 框架的其他組件以及 TensorFlow 。最新的版本可以直接從 HugeCTR 存儲庫中提取,實時編譯和安裝。更新 TensorFlow 時,還必須為新安裝的 TensorFlow 版本重新編譯插件。
為了進行比較,這里介紹了如何使用本機 TensorFlow 嵌入層。首先,初始化 2D 數組變量以保存嵌入的值。然后,使用 tf 。 nn 。 embedding _ lookup 查找 ID 列表對應的嵌入值。
保存嵌入的值。然后,使用 tf . nn . embedding _ lookup 查找 ID 列表對應的嵌入值。
embedding_var = tf.Variable(initial_value=initial_value, dtype=tf.float32, name='embedding_variables') @tf.function def _train_step(inputs, labels): emb_vectors = tf.nn.embedding_lookup([self.embedding_var], inputs) ... for i, (inputs, labels) in enumerate(dataset): _train_step(inputs)
同樣,也可以使用 HugeCTR 嵌入插件。首先,初始化嵌入層。接下來,該嵌入層用于查找 ID 列表的相應嵌入值。
import sparse_operation_kit as sok
emb_layer = sok.All2AllDenseEmbedding(max_vocabulary_size_per_gpu,
embedding_vec_size,
slot_num, nnz_per_slot)
@tf.function
def _train_step(inputs, labels):
emb_vectors = emb_layer(inputs)
...
for i, (inputs, labels) in enumerate(dataset):
_train_step(inputs)
HugeCTR 嵌入插件旨在與 TensorFlow 無縫協作,包括 Adam 和 sgd 等其他層和優化器。在 TensorFlow v2 。 5 之前, Adam 優化器是基于 CPU 的實現。
為了充分發揮 HugeCTR 嵌入插件的潛力,我們還在 sok 。 optimizers 。 adam 中提供了一個基于 GPU 的插件版本。從 TensorFlow v2 。 5 開始,標準 Adam 優化器 tf 。 keras 。 optimizers 。 Adam (現在帶有 GPU 實現)可以以類似的精度和性能使用。
績效基準
在本節中,我們通過合成和實際用例展示 HugeCTR TensorFlow 嵌入插件的性能。
合成數據
在本例中,我們使用具有 100 個特征字段的合成數據集,每個都有 10 個查找,詞匯表大小為 8192 。推薦模型是一個具有六層的 MLP ,每層大小為 1024 。使用 TensorFlow 中的精確模型架構、優化器和數據加載器,我們觀察到在 1x A100 GPU 上, HugeCTR 嵌入插件比本機 TensorFlow 嵌入層的平均迭代時間提高了 7 。 9 倍(圖 2 )。
當從 1 到 4 個 A100 HugeCTR s 進行強縮放時,我們觀察到總加速比為 23 。 6 倍。默認情況下, GPU 嵌入插件提供了多重 GPU 縮放的好處。在引擎蓋下,嵌入插件以模型并行方式自動將與功能字段對應的表格分發到可用的 GPU 上。這與本機 TensorFlow 嵌入層形成對比,在本機嵌入層中,分布式模型并行多 GPU 訓練需要大量額外工作。 TensorFlow 分布策略 Mirrored 策略和 MultiWorkerMirrored 策略都是為進行數據并行同步訓練而設計的。
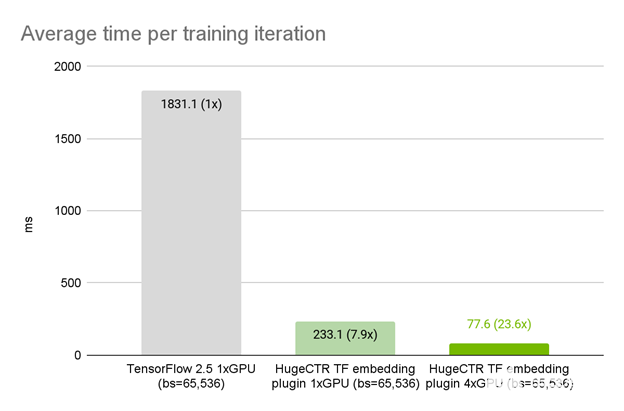
圖 2 。 HugeCTR TensorFlow 在合成數據集上 NVIDIA DGX A100 80GB 上嵌入插件的性能
真實用例:美團推薦系統
美團推薦系統團隊是首批成功采用 HugeCTR TensorFlow 插件的團隊之一。起初,團隊基于 CPU 優化了他們的培訓框架,但隨著他們的模型變得越來越復雜,很難對培訓框架進行更深入的優化。現在,美團正致力于將 NVIDIA HugeCTR 集成到基于 A100 GPU 的培訓系統中。
美團高級技術專家黃軍( Jun Huang )表示:“一臺配備 8x A100 GPU s 的服務器可以替代基于 CPU 的培訓系統中的數百名員工。成本也大大降低。這是初步的優化結果,未來仍有很大的優化空間。”。
美團使用DIEN作為推薦模型。嵌入參數的總數是數百億,每個樣本中有數千個特征字段。由于輸入特征的范圍事先不是固定的和未知的,團隊使用哈希表在輸入嵌入層之前唯一地標識每個輸入特征。
使用 TensorFlow 中的精確模型架構、優化器和數據加載器,我們觀察到在單個 A100 GPU 上, HugeCTR 嵌入插件實現了比原始 TensorFlow 嵌入 11 。 5 倍的加速。在弱縮放情況下, 8x A100 GPU s 上的迭代時間僅略微增加到 1x A100 GPU 的 1 。 17 倍(圖 3 )。
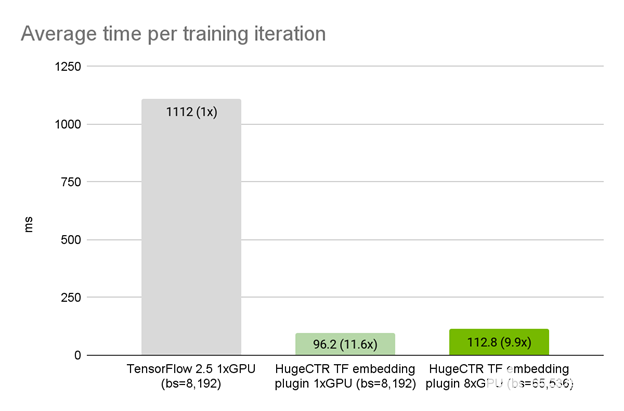
圖 3 。美團數據上 NVIDIA DGX A100 80GB 上的 HugeCTR TensorFlow 嵌入插件性能
結論
HugeCTR TensorFlow 嵌入插件今天可以從 HugeCTR GitHub 存儲庫以及 NGC NVIDIA Merlin TensorFlow 容器獲得。如果您是 TensorFlow 用戶,希望構建和部署具有大型嵌入表的大規模推薦系統, HugeCTR TensorFlow 插件可以輕松替換 TensorFlow 嵌入查找層。
關于作者
Vinh Nguyen 是一位深度學習的工程師和數據科學家,發表了 50 多篇科學文章,引文超過 2500 篇。在 NVIDIA ,他的工作涉及廣泛的深度學習和人工智能應用,包括語音、語言和視覺處理以及推薦系統。
Ann Spencer 是 Merlin 的高級產品營銷經理。在加入 NVIDIA 之前,她曾在多家數據公司擔任產品和研究職務。 2012-2014 年,她還是 O ‘ Reilly Media 的數據編輯,專注于數據工程和數據科學。
Joey Wang 是 NVIDIA Merlin HugeCTR 和 RnnEngine 的作者和開發經理,也是 NVIDIA 亞太地區發展技術解決方案團隊的經理。他在 NVIDIA 工作了七年。自 2014 年以來, Joey 主要從事深度學習 GPU 加速工作。在此之前,喬伊在 HPC 從事智能視頻分析和粒子模擬。
Jianbing Dong 是 DevTech 工程師, HugeCTR 嵌入插件的作者。在 NVIDIA ,他的工作重點是 TensorFlow 相關的優化。
審核編輯:郭婷
-
NVIDIA
+關注
關注
14文章
5238瀏覽量
105764 -
互聯網
+關注
關注
54文章
11229瀏覽量
105578
發布評論請先 登錄
NVIDIA Isaac Sim與NVIDIA Isaac Lab的更新
NVIDIA將為每家AI工廠提供網絡安全

NVIDIA Halos自動駕駛汽車安全系統發布
嵌入式系統存儲的軟件優化策略
嵌入式系統中的代碼優化與壓縮技術
利用NVIDIA DPF引領DPU加速云計算的未來
簡述NVIDIA Isaac的重要更新

【AIBOX應用】通過 NVIDIA TensorRT 實現實時快速的語義分割

SSM框架的性能優化技巧 SSM框架中RESTful API的實現
NVIDIA DOCA 2.9版本的亮點解析

Orin芯片的嵌入式系統
NVIDIA RTX AI套件簡化AI驅動的應用開發
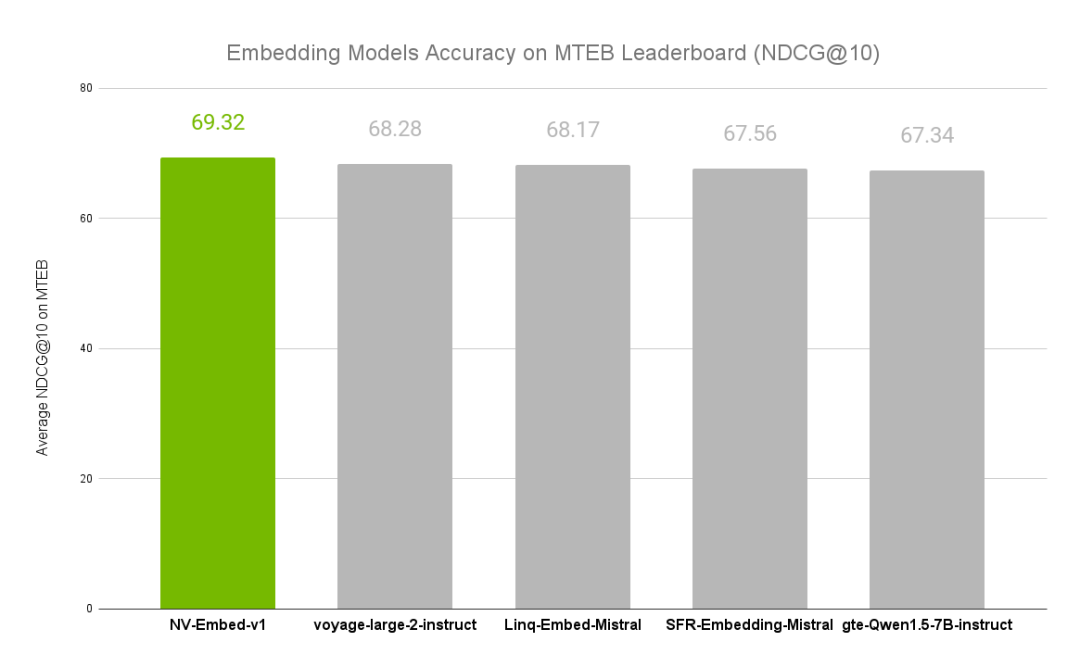
NVIDIA文本嵌入模型NV-Embed的精度基準
SOK在手機行業的應用案例





 工商網監
工商網監
評論