 cosFormer:重新思考注意力機制中的Softmax
cosFormer:重新思考注意力機制中的Softmax
導讀:Transformer在自然語言處理、計算機視覺和音頻處理方面取得了巨大成功。作為其核心組成部分之一,Softmax Attention模塊能夠捕捉長距離的依賴關系,但由于Softmax算子關于序列長度的二次空間和時間復雜性,使其很難擴展。
針對這點,研究者提出利用核方法以及稀疏注意力機制的方法來近似Softmax算子,從而降低時間空間復雜度。但是,由于誤差的存在,效果往往不盡如人意。
商湯多模態研究組認為,近似操作本身存在的誤差使得其效果很難超越Softmax Attention。我們的觀點是,與其近似Softmax,不如設計一種方式代替Softmax,并且同時降低時間空間復雜度。
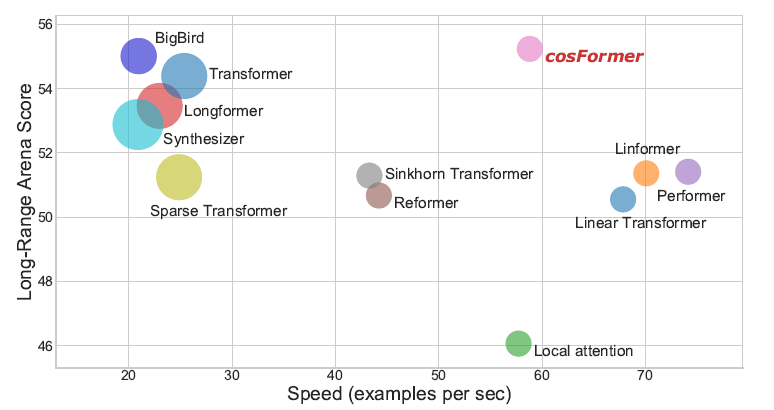
因此,本文提出了名為cosFormer的方法,在時間空間復雜度關于序列長度為線性復雜度的同時,其性能接近或者超越Softmax Attention,并在LRA benchmark上取得SOTA結果。我們的設計核心理念基于兩點,首先是注意力矩陣的非負性,其次是對局部注意力的放大(非極大值抑制)。
本文主要介紹已收錄于ICLR 2022的一篇文章 cosFormer : Rethinking Softmax in Attention。

Part 1
背景

1. Softmax Attention
為了引出我們的方法,對Softmax Attention的計算方式進行一定的推廣:
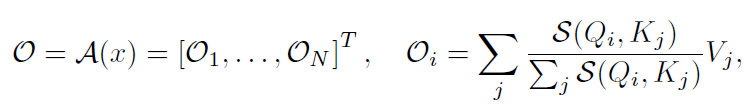
其中表示相似度計算函數,如果,上式即變為Softmax Attention(不考慮除以的縮放操作)。注意到計算的時間復雜度為,的時間復雜度為,所以總時間復雜度為,即關于序列長度是二次的。
2. 線性 Attention
通過分析我們發現,性能瓶頸的主要原因是操作,如果相似度函數可以表示為:
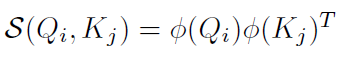
那么:
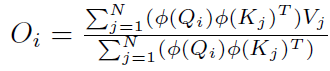
根據矩陣運算的結合律:
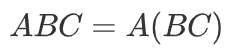
上式可以變換為(編者修正:下方公式未變換,請參照論文):
經過計算后可以得到該方法的時間復雜度為,即關于序列長度是一次的。
Softmax Attention和線性Attention的計算方式可以用下圖概括:
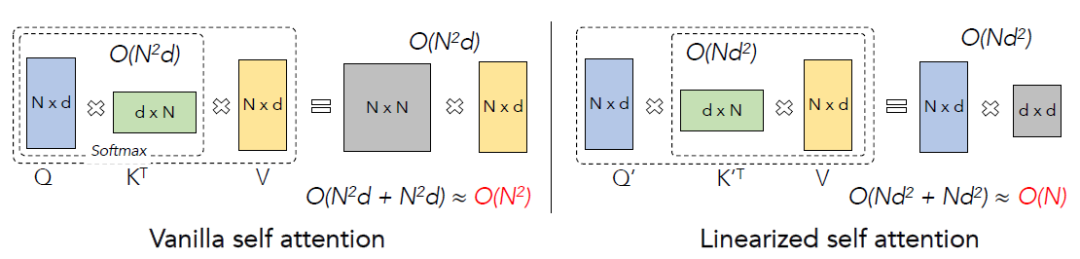
所以接下來將介紹的選擇,以及核心的reweighting操作。
3. Softmax 的兩大性質
我們經過分析以及實驗,歸納出Softmax Attention中比較重要的性質,這兩個性質可以指導我們的模型設計:
1. 注意力矩陣的非負性
2. 局部注意力的放大(非極大值抑制)
對于第一點,我們有如下實驗進行驗證(模型結構為RoBERTa):
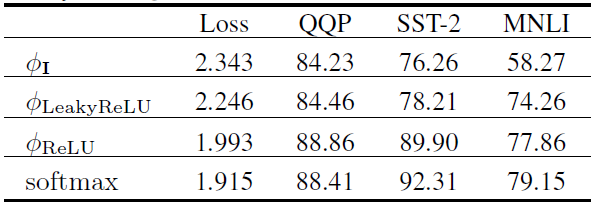
這里Loss表示驗證集損失(越低越好),其余指標均為準確率(越高越好)。可以看到,當保證了注意力矩陣的非負性之后,可以達到較好的效果。基于該實驗,我們選擇為ReLU函數。
對于第二點,我們的方式是在注意力矩陣中引入先驗locality信息,觀察Softmax注意力矩陣,如下圖所示,我們發現其注意力矩陣的權重在對角線附近很集中:
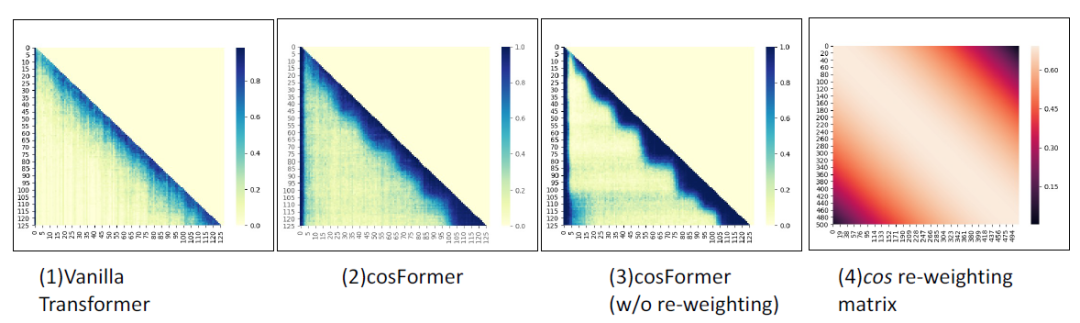
所以我們的方法需要在加了reweighting操作后也更加集中在對角線附近。注意并非所有的有類似權重的函數均適用,這個reweighting的函數需要跟前面的QK一樣可以拆分成兩個矩陣的乘法的形式。
至此,就可以引入我們的cosFormer了。
Part 2
cosFormer
1. 方法
我們的方法基于線性Attention,首先給出符號定義:
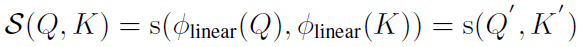
根據之前的分析,我們選擇了:
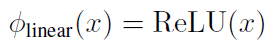
可得:
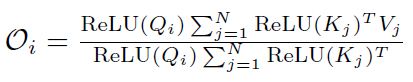
為了進行reweighting操作,并且同時保證線性Attention的計算方式依然成立,我們選擇了cos函數:
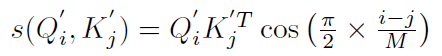
展開可得:
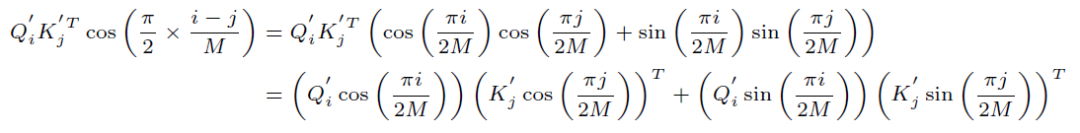
為了便于展示,我們把它記作:
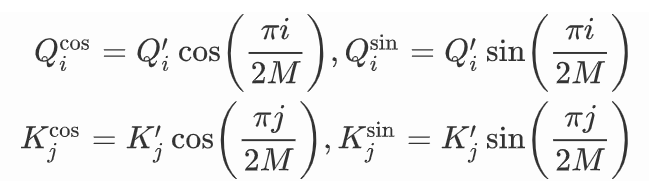
最終得到:
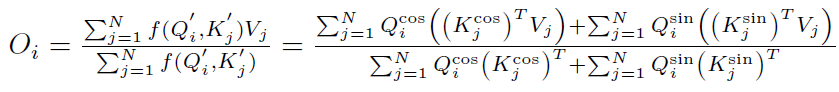
上式和線性Attention的計算方式一致,經過分析不難得出時間復雜度依然是。
2. 實驗結果
我們在單向模型、雙向模型以及LRA benchmark上測試了我們的方法,均取得了非常不錯的效果。
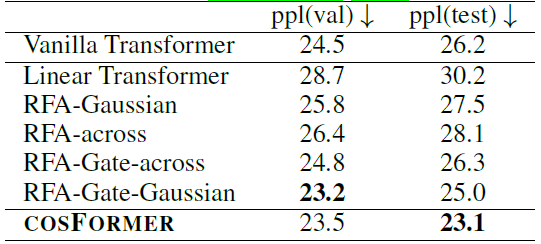
單向語言模型,指標表示困惑度(越低越好):
雙向語言模型,指標表示準確率(越高越好):

LRA benchmark:
1)性能實驗,指標表示準確率(越高越好):
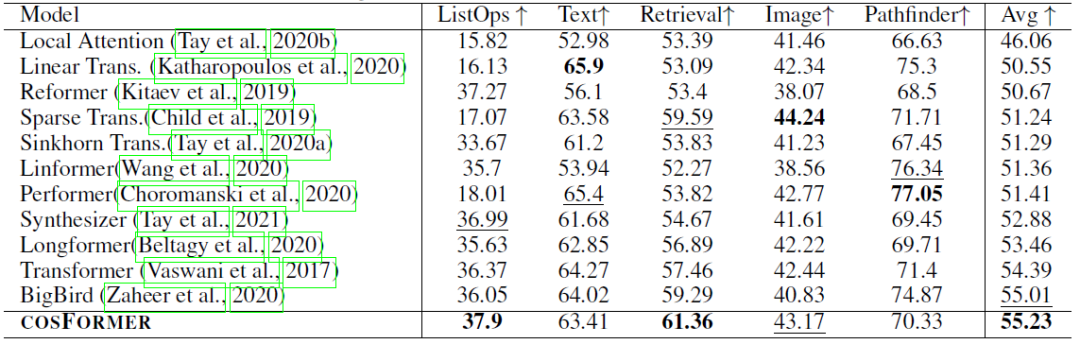
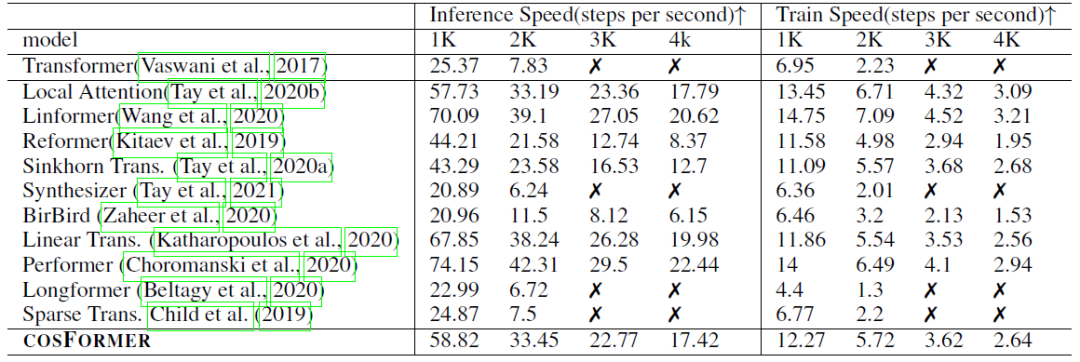
2)內存速度實驗,指標表示速度(越高越好,如果內存溢出,則標記為叉):
審核編輯 :李倩
-
函數
+關注
關注
3文章
4371瀏覽量
64229 -
計算機視覺
+關注
關注
9文章
1706瀏覽量
46580 -
Softmax
+關注
關注
0文章
9瀏覽量
2676
原文標題:ICLR'22 | cosFormer:重新思考注意力機制中的Softmax
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
經顱電刺激適應癥之tDCS治療注意力缺陷ADHD

變頻器重新設置參數應注意什么?

DeepSeek推出NSA機制,加速長上下文訓練與推理
如何使用MATLAB構建Transformer模型

ADS1299S是否推薦有與DEMO匹配的傳感器頭?
什么是LLM?LLM在自然語言處理中的應用
一種基于因果路徑的層次圖卷積注意力網絡

一種創新的動態軌跡預測方法
Llama 3 模型與其他AI工具對比
N型接口在維修過程中需要注意哪些問題

LDO穩壓器的過流保護機制
2024 年 19 種最佳大型語言模型







 工商網監
工商網監
評論