") 英特爾BigDL深挖大數(shù)據(jù)價值 助力分布式人工智能廣泛落地
英特爾BigDL深挖大數(shù)據(jù)價值 助力分布式人工智能廣泛落地
“沒說就是零卡。”近日,網(wǎng)絡(luò)健身博主@禿頂吳彥祖的金句意外走紅,揭開了無數(shù)擼鐵干飯王的最強自我欺騙套路——只要食物包裝上沒有注明卡路里,吃了它我就不會發(fā)胖!除此之外,“冰可樂沒有熱量”、“卡路里正正得負”等高頻彈幕也常常令人忍俊不禁。實際上,它們并不僅僅是幾句戲言,通過Transformer Cross Transformer (TxT)人工智能推薦系統(tǒng),漢堡王發(fā)現(xiàn),當(dāng)人們把高熱量食物而非低熱量食物加入購物車時,他們更愿意再點一份甜點。也就是說,高熱量食物和高熱量食物更配哦!另外,TxT還發(fā)現(xiàn),即使天氣很冷,漢堡王的顧客都會點上一份奶昔——而此前人們一般認為,低溫天氣會使冷飲銷量降低。
其實,想要在客戶服務(wù)中使用人工智能,尤其是快餐推薦,線下快餐門店面臨著自己獨特的挑戰(zhàn)。相比電子商務(wù)、搜索引擎等能夠在較為充裕的時間內(nèi)通過大量推理與訓(xùn)練,掌握用戶偏好的行業(yè),對于快餐品牌而言,目前仍然沒有什么簡單的方法可以在瞬間識別客戶并檢索到他們的檔案,因為所有食物推薦都是在線下完成的。此外,在把位置、上下文特征加載到模型之前,還必須對此類數(shù)據(jù)進行預(yù)處理,對于要求快速響應(yīng)的線下快餐門店來說,這著實是一個不小的難題。
為了應(yīng)對這些挑戰(zhàn),漢堡王的Transformer Cross Transformer (TxT)人工智能推薦系統(tǒng)應(yīng)運而生。該系統(tǒng)采用了所謂的“雙”Transformer架構(gòu),既能夠?qū)W習(xí)實時訂單序列數(shù)據(jù),也能夠?qū)W習(xí)位置、天氣和訂單行為等特征。TxT可以利用餐館中所有可用的數(shù)據(jù)點,而無需在接單流程開始之前識別顧客。例如,如果顧客在其購物車內(nèi)加入的第一款商品是奶昔,那么這將影響TxT的推薦,這些推薦基于顧客過去購買的商品、當(dāng)下購買的商品以及商店售賣的商品。這是從模型方面的創(chuàng)新。
另一方面的創(chuàng)新則是統(tǒng)一的大數(shù)據(jù)處理和模型訓(xùn)練的流水線。目前,大多數(shù)企業(yè)的做法是建立兩個模型,一個模型做大數(shù)據(jù)處理,一個模型做深度學(xué)習(xí),但這一方式效率低下,拷貝文件就占了整個訓(xùn)練20%以上的時間。而英特爾和漢堡王合作創(chuàng)建的端到端推薦流水線將整個端到端的數(shù)據(jù)處理和模型訓(xùn)練遷移到基于BigDL的統(tǒng)一的平臺上,其中包括分布式Apache Spark數(shù)據(jù)處理和在英特爾至強集群上進行的Apache MXNet訓(xùn)練,能夠讓企業(yè)直接在現(xiàn)有集群上運行程序,從而大大提高了人工智能的工作效率。
說到這里,你會發(fā)現(xiàn),想要將AI部署于現(xiàn)實的應(yīng)用,其中所面臨的一個重大挑戰(zhàn)就是針對生產(chǎn)數(shù)據(jù)集進行數(shù)據(jù)分析、機器學(xué)習(xí)和深度學(xué)習(xí)。生產(chǎn)數(shù)據(jù)集來源于龐大的分布式數(shù)據(jù)倉庫,而按照傳統(tǒng)方法,企業(yè)需要設(shè)立兩個單獨的集群,一個用于大數(shù)據(jù),導(dǎo)出數(shù)據(jù)并轉(zhuǎn)移到另外一個深度學(xué)習(xí)集群進行建模,該集群運行TensorFlow、PyTorch等。在這種架構(gòu)下,首先會產(chǎn)生大量與數(shù)據(jù)移動相關(guān)的開銷,其次,它會產(chǎn)生隔離的工作流,從而大大降低開發(fā)效率。
而針對上述難題,英特爾BigDL 2.0有著清晰的解決思路——提供一個統(tǒng)一的大數(shù)據(jù)架構(gòu),為分布式AI提供統(tǒng)一的端到端管道。如此一來,企業(yè)就可以在同一個集群、同一個應(yīng)用內(nèi)使用Spark等處理數(shù)據(jù)倉庫中的數(shù)據(jù)。在此基礎(chǔ)上,人們可以針對內(nèi)存Spark Dataframes直接使用TensorFlow、PyTorch、OpenVINO等深度學(xué)習(xí)AI模型。Spark Dataframes是駐留在內(nèi)存中的數(shù)據(jù)集,分布在整個集群上,客戶可以透明地在分布式數(shù)據(jù)集上使用這些AI模型、AI算法——都在一個集群內(nèi),更重要的是,一個程序,只需一個工作流。
通過這種方法,英特爾的一些客戶,如中國最大的軟硬件廠商之一的浪潮,已經(jīng)成功將研發(fā)周期從幾個季度縮短到幾個月。毋庸置疑,這一顯著的進步極大推動了人工智能現(xiàn)實應(yīng)用的進一步發(fā)展。
而在這一成就的背后,是英特爾BigDL 2.0所凝結(jié)的大量創(chuàng)新。分布式模式運行本地筆記本上的代碼。實際上,這一直是很多數(shù)據(jù)科學(xué)家的痛點,他們沒法簡單地獲取一個單節(jié)點PythonNotebook,并在集群上以分布式模式運行,因此,他們通常需要重寫代碼。
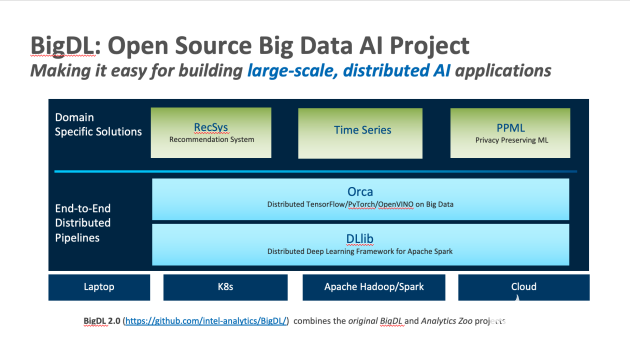
在Orca中,英特爾BigDL嘗試讓用戶可以把筆記本電腦上運行的Notebook部署到分布式集群,云中托管的Kubernetes集群、或者Hadoop集群。在Notebook的一開始,只需調(diào)用Orca下文中的一個方法,它會告訴程序用戶希望運行哪個環(huán)境,可以是在本地筆記本電腦上,也可以是本地集群或者Kubernetes集群等。只需改變一行代碼,這個Notebook就可以在本地筆記本電腦上運行,模擬分布式集群規(guī)模,在分布式環(huán)境中處理大型數(shù)據(jù)集。
而在更高層級的運用,即基于這些管道開發(fā)更垂直的行業(yè)解決方案中,用戶可以通過BigDL PPML,在云上創(chuàng)建一個支持大數(shù)據(jù)和AI的可信平臺環(huán)境。在把數(shù)據(jù)或者模型轉(zhuǎn)移到云上之前,用戶可以使用加密技術(shù)保護內(nèi)容,然后通過BigDL PPML直接在加密數(shù)據(jù)上運行應(yīng)用軟件、模型、Spark數(shù)據(jù)分析等,PPML會在可信環(huán)境中讀取加密數(shù)據(jù),解密并運行相應(yīng)的應(yīng)用,同時確保數(shù)據(jù)的安全性和應(yīng)用的完整性。在此基礎(chǔ)下,BigDL PPML還可以提供可信的聯(lián)邦學(xué)習(xí)(也被稱為聯(lián)合學(xué)習(xí))——每一方只擁有一部分信息和功能,但他們可以聯(lián)合訓(xùn)練一個模型,而不需要向另一方披露數(shù)據(jù)。通過SGX提供的硬件級的安全環(huán)境,聯(lián)邦學(xué)習(xí)場景中的性能和安全性能夠得到有效保證。
此外,BigDL之上構(gòu)建的其他垂直行業(yè)解決方案還包括Chronos項目——一個利用AutoML技術(shù)構(gòu)建大規(guī)模、分布式時間序列分析的應(yīng)用框架,可用于時序數(shù)據(jù)的處理,滑動窗口取樣、縮放、重采樣、補全,以及自動的特征提取。同時,其中內(nèi)置了大量時序預(yù)測和異常檢測模型,用戶可以直接使用TSDataset構(gòu)建時序應(yīng)用進行數(shù)據(jù)處理,使用對應(yīng)的模型進行預(yù)測或者異常檢測。AutoML技術(shù)幫助用戶搜索最佳的模型參數(shù)以提高模型預(yù)測的準(zhǔn)確性。 Chronos同時內(nèi)置了Intel的分類加速工具可以幫助用戶取得更好的訓(xùn)練與推理速度;以及Friesian項目——用于構(gòu)建大規(guī)模端到端推薦解決方案的應(yīng)用框架,提供了豐富的內(nèi)置特征工程操作、推薦算法和參考樣例,幫助用戶快速構(gòu)建一個完整的推薦系統(tǒng)來應(yīng)對離線或者在線的推薦場景。
總而言之,作為一個開源項目,BigDL能夠提供端到端大數(shù)據(jù)人工智能管道,讓用戶、科學(xué)家和數(shù)據(jù)工程師更容易構(gòu)建大規(guī)模分布式人工智能解決方案,并使其變得更加容易。它還提供各種垂直框架,如推薦、時間序列分析、隱私保護機制,以幫助用戶快速整合他們的AI解決方案。或許在并不遙遠的未來,伴隨著人工智能在人類生活中更加深度的滲透,BigDL與大數(shù)據(jù)的結(jié)合將為我們揭示更多意想不到的神奇真相。
-
英特爾
+關(guān)注
關(guān)注
61文章
10183瀏覽量
174153 -
人工智能
+關(guān)注
關(guān)注
1805文章
48843瀏覽量
247405 -
機器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8497瀏覽量
134222 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8953瀏覽量
139683
發(fā)布評論請先 登錄
英特爾? 具身智能大小腦融合方案發(fā)布:構(gòu)建具身智能落地新范式

2025英特爾人工智能創(chuàng)新應(yīng)用大賽正式啟動
HarmonyOS Next 應(yīng)用元服務(wù)開發(fā)-分布式數(shù)據(jù)對象遷移數(shù)據(jù)權(quán)限與基礎(chǔ)數(shù)據(jù)
【「具身智能機器人系統(tǒng)」閱讀體驗】+數(shù)據(jù)在具身人工智能中的價值
英特爾推出全新英特爾銳炫B系列顯卡

IC China 2024北京開幕:英特爾分享洞察,促智能計算應(yīng)用落地

嵌入式和人工智能究竟是什么關(guān)系?
WDS分布式存儲系統(tǒng)軟件助力電信工程海量數(shù)據(jù)存儲項目

人工智能云計算大數(shù)據(jù)三者關(guān)系
《AI for Science:人工智能驅(qū)動科學(xué)創(chuàng)新》第一章人工智能驅(qū)動的科學(xué)創(chuàng)新學(xué)習(xí)心得
英特爾攜手騰訊以技術(shù)創(chuàng)新,共馭智算未來新機

人工智能技術(shù)躍進:英特爾引領(lǐng)AI無處不在新紀元
AI軟件開發(fā)商Anaconda起訴英特爾侵權(quán)
探秘IO分布式模塊設(shè)計:讓大數(shù)據(jù)處理更高效

基于英特爾至強6能效核處理器優(yōu)化原生分布式數(shù)據(jù)庫OceanBase





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論