") 阿里云震旦異構(gòu)計(jì)算加速平臺基于NVIDIA Tensor Core GPU
阿里云震旦異構(gòu)計(jì)算加速平臺基于NVIDIA Tensor Core GPU
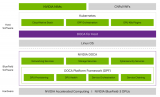
阿里云震旦異構(gòu)計(jì)算加速平臺基于NVIDIA Tensor Core GPU,通過機(jī)器學(xué)習(xí)模型的自動優(yōu)化技術(shù),大幅提升了算子的執(zhí)行效率,刷新了NVIDIA A100、A10、T4的GPU單卡性能。并基于8張NVIDIA A100 GPU和開放規(guī)則,以離線場景下每秒處理107.8萬張圖片的成績,打破MLPerf 1.0推理性能測試紀(jì)錄。
阿里云自研震旦異構(gòu)計(jì)算加速平臺,適配GPU、ASIC等多種異構(gòu)AI芯片,優(yōu)化編譯代碼,深挖和釋放異構(gòu)芯片算力,支持TensorFlow、Caffe、PAI等多種深度學(xué)習(xí)框架,可實(shí)現(xiàn)AI框架及算法的無縫遷移適配,支持云變端多場景快速部署,大幅提升AI應(yīng)用開發(fā)效率。
在MLPerf推理性能測試結(jié)果1.0版中,震旦異構(gòu)計(jì)算加速平臺,基于8卡NVIDIA A100 GPU配置上性能奪魁,在開放規(guī)則的離線場景下取得每秒處理107.8萬張圖片的成績。
首先在頂層算法模型上,使用基于自動機(jī)器學(xué)習(xí)(AutoML)的模型設(shè)計(jì)方式,這種方式可以獲得比人工設(shè)計(jì)更高效的模型。震旦基于MIT的先進(jìn)的神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索算法Once-For-All。
使用了基于強(qiáng)化學(xué)習(xí)的自研搜索算法獲得了高性能子網(wǎng)絡(luò);之后通過INT8量化獲得硬件加速繼續(xù)提高性能,并在量化前進(jìn)行深度重訓(xùn)練,以保證量化后的精度能夠達(dá)到測試的精度要求。
IRB即反轉(zhuǎn)殘差塊(Inverted Residual Block),是用于網(wǎng)絡(luò)架構(gòu)搜索的基本模塊。每個反轉(zhuǎn)殘差塊包括三層卷積算子,圖上反轉(zhuǎn)殘差塊的長度代表了該塊的輸出channel數(shù)量。
一般機(jī)器學(xué)習(xí)框架的算子實(shí)現(xiàn)專注于優(yōu)化主流的神經(jīng)網(wǎng)絡(luò)架構(gòu),而對于NAS的反轉(zhuǎn)殘差塊則效率不佳,震旦使用了基于自動調(diào)優(yōu)的大規(guī)模算子融合技術(shù),大幅提高了推理時算子對GPU的利用率,并且可根據(jù)不同的架構(gòu)自動調(diào)優(yōu)到最佳算子實(shí)現(xiàn)。
因此能快速發(fā)掘全新GPU架構(gòu)的潛力,例如對于A100上通過MIG(多實(shí)例GPU)技術(shù)產(chǎn)生的具有不同計(jì)算資源的GPU實(shí)例,震旦算子優(yōu)化技術(shù)可以通過自動調(diào)優(yōu)來進(jìn)一步提升計(jì)算資源利用率。
打破紀(jì)錄的背后,在硬件平臺上也得益于NVIDIA A100 GPU 強(qiáng)大的算力支持,近5倍于上一代的INT8性能使得超越百萬級性能成為可能。另外,NVIDIA GPU的通用性,即通過CUDA直接對硬件編程,使得用戶可以針對其特有的神經(jīng)網(wǎng)絡(luò)模型進(jìn)行定制優(yōu)化,這讓震旦基于GPU的自動算子調(diào)優(yōu)技術(shù)成為了現(xiàn)實(shí)。
最終獲得的調(diào)優(yōu)算子可以更高效地利用A100最新的Tensor Core硬件指令以及更大的共享內(nèi)存,從而交出了軟硬件協(xié)同優(yōu)化的滿意答卷。
在MLPerf推理性能測試結(jié)果1.0版本圖像分類性能測試中,阿里云震旦異構(gòu)計(jì)算加速平臺,基于NVIDIA A100 GPU平臺和開放規(guī)則,在離線場景下以每秒處理107.8萬張圖片的成績,打破了此前谷歌保持的絕對性能榜單的世界紀(jì)錄。這也是阿里在通用GPU平臺第一次取得100萬+這樣的成績。
此次阿里云震旦異構(gòu)計(jì)算加速平臺基于NVIDIA通用GPU硬件,通過機(jī)器學(xué)習(xí)模型的自動優(yōu)化技術(shù),大幅提升了算子的執(zhí)行效率,刷新了NVIDIA GPU單卡性能。無論是新推出的A100和A10,還是已面市3年的T4,都帶來了單卡性能的大幅提升。
編輯:jq
-
asic
+關(guān)注
關(guān)注
34文章
1242瀏覽量
121984 -
gpu
+關(guān)注
關(guān)注
28文章
4910瀏覽量
130653 -
AI芯片
+關(guān)注
關(guān)注
17文章
1968瀏覽量
35689
原文標(biāo)題:NVIDIA A100 GPU助力阿里云打破MLPerf推理性能測試紀(jì)錄
文章出處:【微信號:murata-eetrend,微信公眾號:murata-eetrend】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
能效提升3倍!異構(gòu)計(jì)算架構(gòu)讓AI跑得更快更省電
GPU加速計(jì)算平臺的優(yōu)勢
RK3399處理器:高性能多核異構(gòu)計(jì)算平臺
利用NVIDIA DPF引領(lǐng)DPU加速云計(jì)算的未來
異構(gòu)計(jì)算的概念、核心、優(yōu)勢、挑戰(zhàn)及考慮因素
《CST Studio Suite 2024 GPU加速計(jì)算指南》
【一文看懂】什么是異構(gòu)計(jì)算?

詳解Arm計(jì)算平臺的優(yōu)勢
《算力芯片 高性能 CPUGPUNPU 微架構(gòu)分析》第3篇閱讀心得:GPU革命:從圖形引擎到AI加速器的蛻變
NVIDIA加速計(jì)算如何推動醫(yī)療健康
打造異構(gòu)計(jì)算新標(biāo)桿!國數(shù)集聯(lián)發(fā)布首款CXL混合資源池參考設(shè)計(jì)

AvaotaA1全志T527開發(fā)板AMP異構(gòu)計(jì)算簡介
異構(gòu)計(jì)算:解鎖算力潛能的新途徑





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論