 一個更直觀的角度對當前經典流行的GNN網絡
一個更直觀的角度對當前經典流行的GNN網絡
近年來,深度學習領域關于圖神經網絡(Graph Neural Networks,GNN)的研究熱情日益高漲,圖神經網絡已經成為各大深度學習頂會的研究熱點。GNN處理非結構化數據時的出色能力使其在網絡數據分析、推薦系統、物理建模、自然語言處理和圖上的組合優化問題方面都取得了新的突破。圖神經網絡有很多比較好的綜述[1][2][3]可以參考,更多的論文可以參考清華大學整理的GNN paper list[4] 。本篇文章將從一個更直觀的角度對當前經典流行的GNN網絡,包括GCN、GraphSAGE、GAT、GAE以及graph pooling策略DiffPool等等做一個簡單的小結。
筆者注:行文如有錯誤或者表述不當之處,還望批評指正!
一、為什么需要圖神經網絡?
隨著機器學習、深度學習的發展,語音、圖像、自然語言處理逐漸取得了很大的突破,然而語音、圖像、文本都是很簡單的序列或者網格數據,是很結構化的數據,深度學習很善于處理該種類型的數據(圖1)。
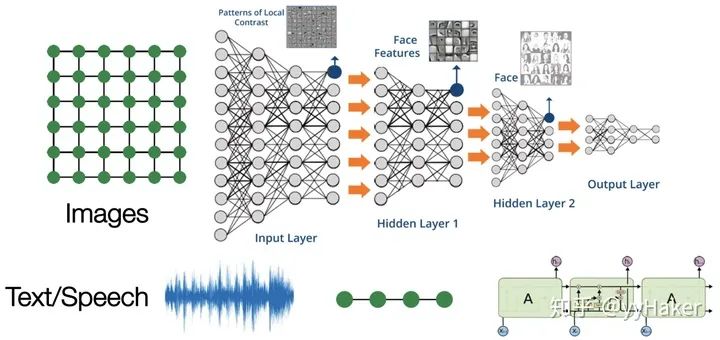
圖1然而現實世界中并不是所有的事物都可以表示成一個序列或者一個網格,例如社交網絡、知識圖譜、復雜的文件系統等(圖2),也就是說很多事物都是非結構化的。
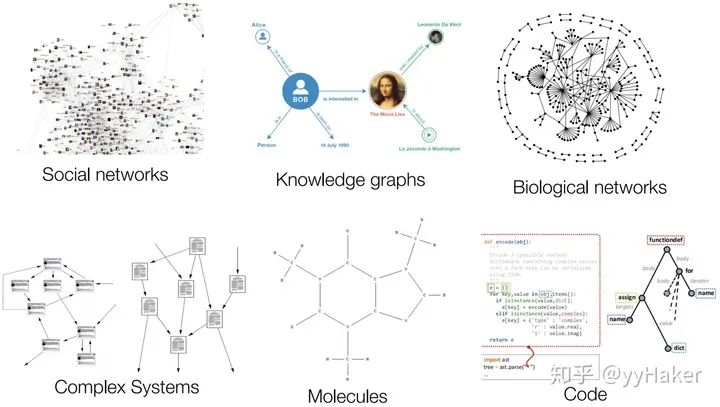
圖2相比于簡單的文本和圖像,這種網絡類型的非結構化的數據非常復雜,處理它的難點包括:
圖的大小是任意的,圖的拓撲結構復雜,沒有像圖像一樣的空間局部性
圖沒有固定的節點順序,或者說沒有一個參考節點
圖經常是動態圖,而且包含多模態的特征
那么對于這類數據我們該如何建模呢?能否將深度學習進行擴展使得能夠建模該類數據呢?這些問題促使了圖神經網絡的出現與發展。
二. 圖神經網絡是什么樣子的?
相比較于神經網絡最基本的網絡結構全連接層(MLP),特征矩陣乘以權重矩陣,圖神經網絡多了一個鄰接矩陣。計算形式很簡單,三個矩陣相乘再加上一個非線性變換(圖3)。
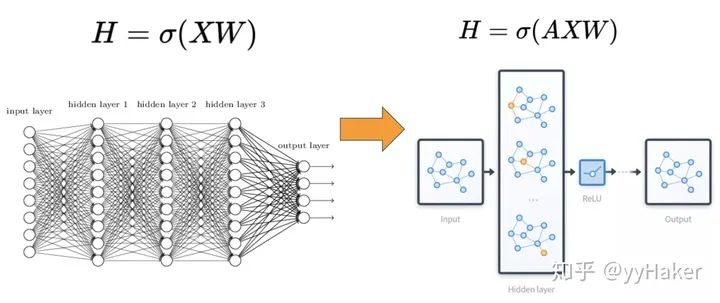
圖3因此一個比較常見的圖神經網絡的應用模式如下圖(圖4),輸入是一個圖,經過多層圖卷積等各種操作以及激活函數,最終得到各個節點的表示,以便于進行節點分類、鏈接預測、圖與子圖的生成等等任務。
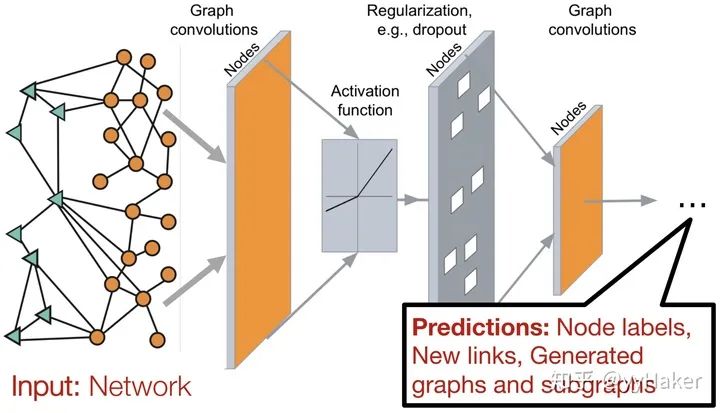
圖4上面是一個對圖神經網絡比較簡單直觀的感受與理解,實際其背后的原理邏輯還是比較復雜的,這個后面再慢慢細說,接下來將以幾個經典的GNN models為線來介紹圖神經網絡的發展歷程
三、圖神經網絡的幾個經典模型與發展
1 . Graph Convolution Networks(GCN)[5]GCN可謂是圖神經網絡的“開山之作”,它首次將圖像處理中的卷積操作簡單的用到圖結構數據處理中來,并且給出了具體的推導,這里面涉及到復雜的譜圖理論,具體推到可以參考[6][7]。推導過程還是比較復雜的,然而最后的結果卻非常簡單( 圖5)。
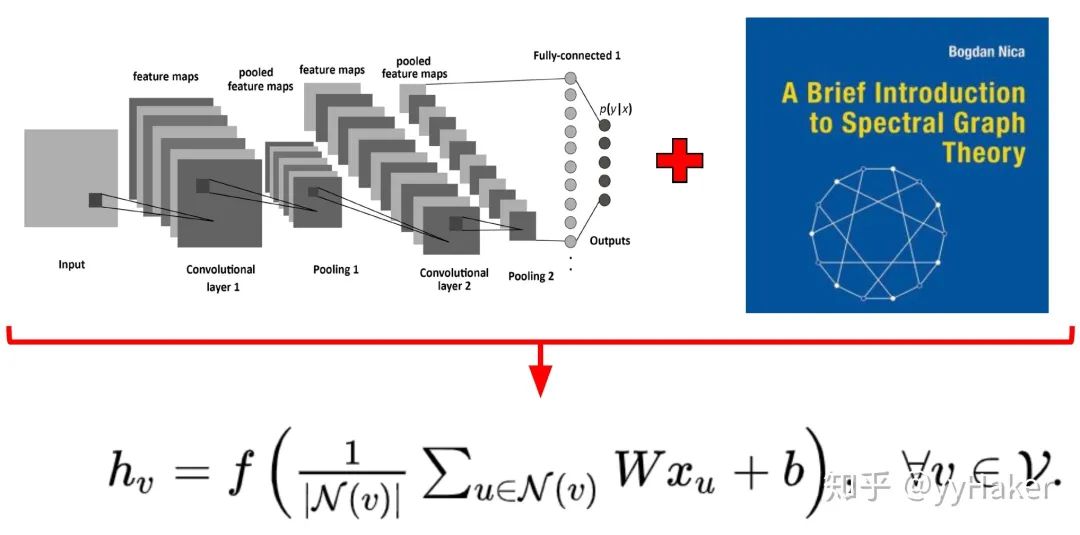
圖5我們來看一下這個式子,天吶,這不就是聚合鄰居節點的特征然后做一個線性變換嗎?沒錯,確實是這樣,同時為了使得GCN能夠捕捉到K-hop的鄰居節點的信息,作者還堆疊多層GCN layers,如堆疊K層有:
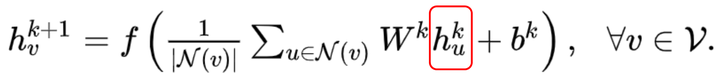
上述式子還可以使用矩陣形式表示如下,
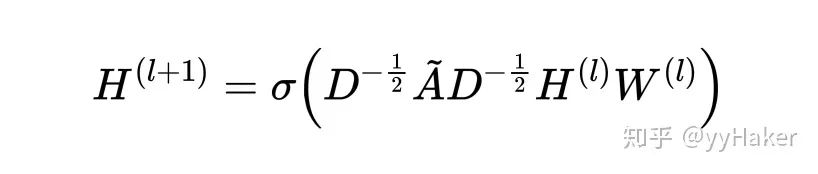
其中是歸一化之后的鄰接矩陣,相當于給層的所有節點的embedding做了一次線性變換,左乘以鄰接矩陣表示對每個節點來說,該節點的特征表示為鄰居節點特征相加之后的結果。(注意將換成矩陣就是圖3所說的三矩陣相乘)那么GCN的效果如何呢?作者將GCN放到節點分類任務上,分別在Citeseer、Cora、Pubmed、NELL等數據集上進行實驗,相比于傳統方法提升還是很顯著的,這很有可能是得益于GCN善于編碼圖的結構信息,能夠學習到更好的節點表示。
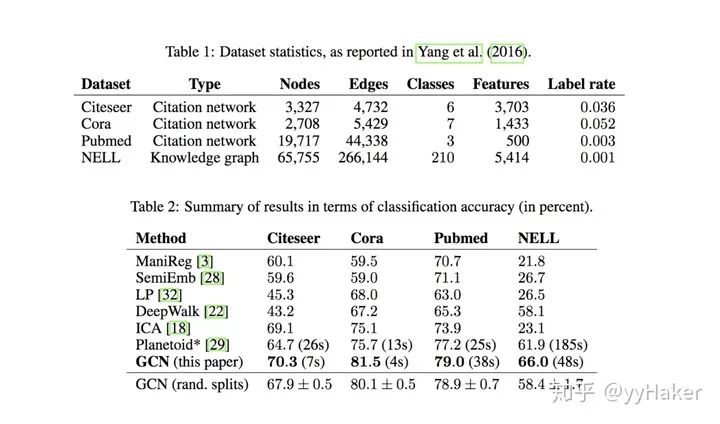
圖6當然,其實GCN的缺點也是很顯然易見的,第一,GCN需要將整個圖放到內存和顯存,這將非常耗內存和顯存,處理不了大圖;第二,GCN在訓練時需要知道整個圖的結構信息(包括待預測的節點), 這在現實某些任務中也不能實現(比如用今天訓練的圖模型預測明天的數據,那么明天的節點是拿不到的)。2. Graph Sample and Aggregate(GraphSAGE)[8]為了解決GCN的兩個缺點問題,GraphSAGE被提了出來。在介紹GraphSAGE之前,先介紹一下Inductive learning和Transductive learning。注意到圖數據和其他類型數據的不同,圖數據中的每一個節點可以通過邊的關系利用其他節點的信息。這就導致一個問題,GCN輸入了整個圖,訓練節點收集鄰居節點信息的時候,用到了測試和驗證集的樣本,我們把這個稱為Transductive learning。然而,我們所處理的大多數的機器學習問題都是Inductive learning,因為我們刻意的將樣本集分為訓練/驗證/測試,并且訓練的時候只用訓練樣本。這樣對圖來說有個好處,可以處理圖中新來的節點,可以利用已知節點的信息為未知節點生成embedding,GraphSAGE就是這么干的。GraphSAGE是一個Inductive Learning框架,具體實現中,訓練時它僅僅保留訓練樣本到訓練樣本的邊,然后包含Sample和Aggregate兩大步驟,Sample是指如何對鄰居的個數進行采樣,Aggregate是指拿到鄰居節點的embedding之后如何匯聚這些embedding以更新自己的embedding信息。下圖展示了GraphSAGE學習的一個過程,
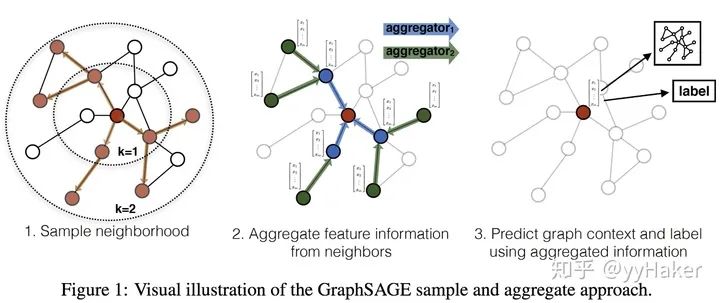
圖7第一步,對鄰居采樣第二步,采樣后的鄰居embedding傳到節點上來,并使用一個聚合函數聚合這些鄰居信息以更新節點的embedding第三步,根據更新后的embedding預測節點的標簽接下來,我們詳細的說明一個訓練好的GrpahSAGE是如何給一個新的節點生成embedding的(即一個前向傳播的過程),如下算法圖:

首先,(line1)算法首先初始化輸入的圖中所有節點的特征向量,(line3)對于每個節點,拿到它采樣后的鄰居節點后,(line4)利用聚合函數聚合鄰居節點的信息,(line5)并結合自身embedding通過一個非線性變換更新自身的embedding表示。注意到算法里面的,它是指聚合器的數量,也是指權重矩陣的數量,還是網絡的層數,這是因為每一層網絡中聚合器和權重矩陣是共享的。網絡的層數可以理解為需要最大訪問的鄰居的跳數(hops),比如在圖7中,紅色節點的更新拿到了它一、二跳鄰居的信息,那么網絡層數就是2。為了更新紅色節點,首先在第一層(k=1),我們會將藍色節點的信息聚合到紅色解節點上,將綠色節點的信息聚合到藍色節點上。在第二層(k=2)紅色節點的embedding被再次更新,不過這次用到的是更新后的藍色節點embedding,這樣就保證了紅色節點更新后的embedding包括藍色和綠色節點的信息,也就是兩跳信息。為了看的更清晰,我們將更新某個節點的過程展開來看,如圖8分別為更新節點A和更新節點B的過程,可以看到更新不同的節點過程每一層網絡中聚合器和權重矩陣都是共享的。
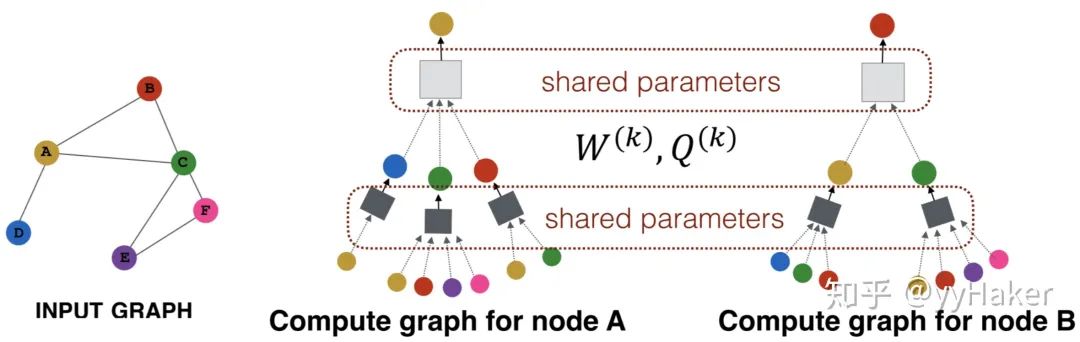
圖8那么GraphSAGESample是怎么做的呢?GraphSAGE是采用定長抽樣的方法,具體來說,定義需要的鄰居個數,然后采用有放回的重采樣/負采樣方法達到。保證每個節點(采樣后的)鄰居個數一致,這樣是為了把多個節點以及它們的鄰居拼接成Tensor送到GPU中進行批訓練。那么GraphSAGE 有哪些聚合器呢?主要有三個,

這里說明的一點是Mean Aggregator和GCN的做法基本是一致的(GCN實際上是求和)。到此為止,整個模型的架構就講完了,那么GraphSAGE是如何學習聚合器的參數以及權重矩陣呢?如果是有監督的情況下,可以使用每個節點的預測lable和真實lable的交叉熵作為損失函數。如果是在無監督的情況下,可以假設相鄰的節點的embedding表示盡可能相近,因此可以設計出如下的損失函數,

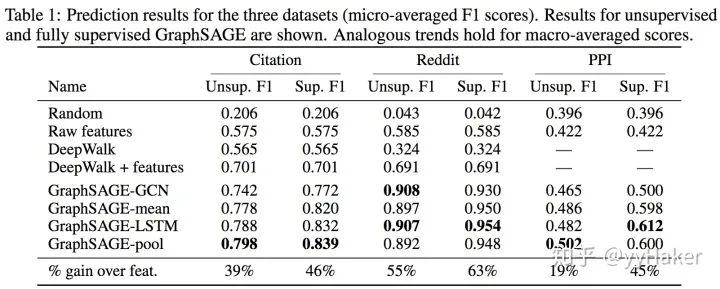
那么GrpahSAGE的實際實驗效果如何呢?作者在Citation、Reddit、PPI數據集上分別給出了無監督和完全有監督的結果,相比于傳統方法提升還是很明顯。
至此,GraphSAGE介紹完畢。我們來總結一下,GraphSAGE的一些優點,(1)利用采樣機制,很好的解決了GCN必須要知道全部圖的信息問題,克服了GCN訓練時內存和顯存的限制,即使對于未知的新節點,也能得到其表示(2)聚合器和權重矩陣的參數對于所有的節點是共享的(3)模型的參數的數量與圖的節點個數無關,這使得GraphSAGE能夠處理更大的圖(4)既能處理有監督任務也能處理無監督任務(就喜歡這樣解決了問題,方法又簡潔,效果還好的idea!!!)當然,GraphSAGE也有一些缺點,每個節點那么多鄰居,GraphSAGE的采樣沒有考慮到不同鄰居節點的重要性不同,而且聚合計算的時候鄰居節點的重要性和當前節點也是不同的。3. Graph Attention Networks(GAT)[9]為了解決GNN聚合鄰居節點的時候沒有考慮到不同的鄰居節點重要性不同的問題,GAT借鑒了Transformer的idea,引入masked self-attention機制,在計算圖中的每個節點的表示的時候,會根據鄰居節點特征的不同來為其分配不同的權值。具體的,對于輸入的圖,一個graph attention layer如圖9所示,
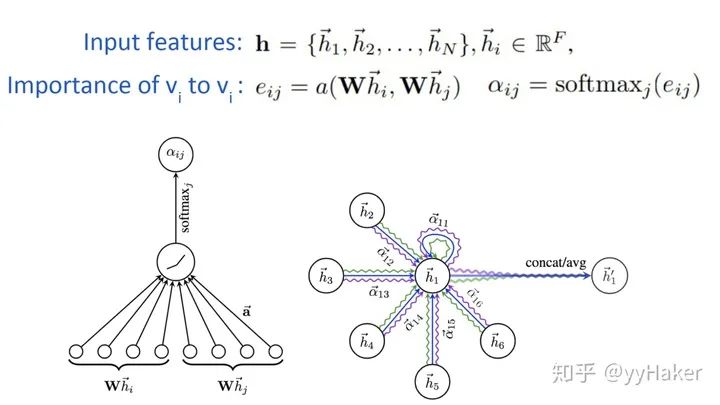
圖9其中采用了單層的前饋神經網絡實現,計算過程如下(注意權重矩陣對于所有的節點是共享的):
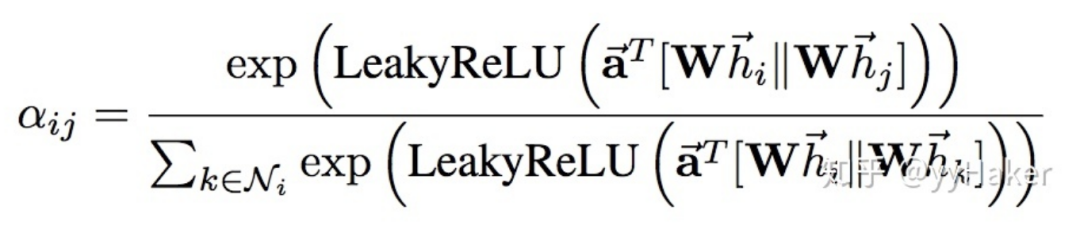
計算完attention之后,就可以得到某個節點聚合其鄰居節點信息的新的表示,計算過程如下:
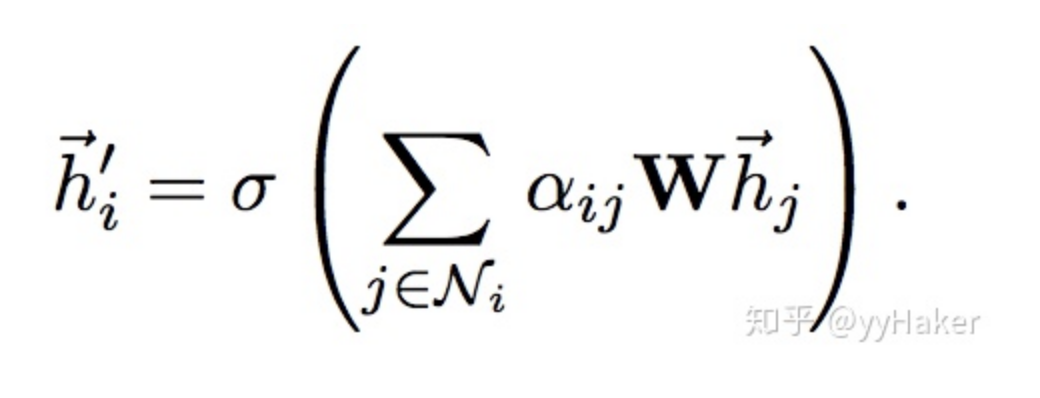
為了提高模型的擬合能力,還引入了多頭的self-attention機制,即同時使用多個計算self-attention,然后將計算的結果合并(連接或者求和):
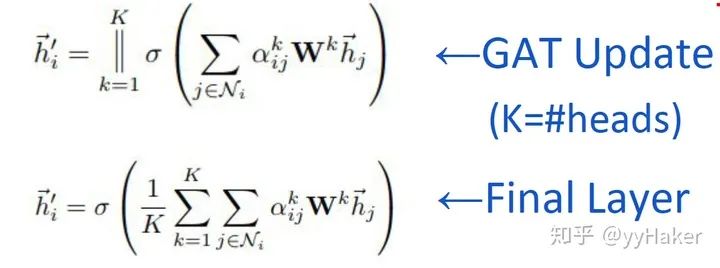
此外,由于GAT結構的特性,GAT無需使用預先構建好的圖,因此GAT既適用于Transductive Learning,又適用于Inductive Learning。那么GAT的具體效果如何呢?作者分別在三個Transductive Learning和一個Inductive Learning任務上進行實驗,實驗結果如下:
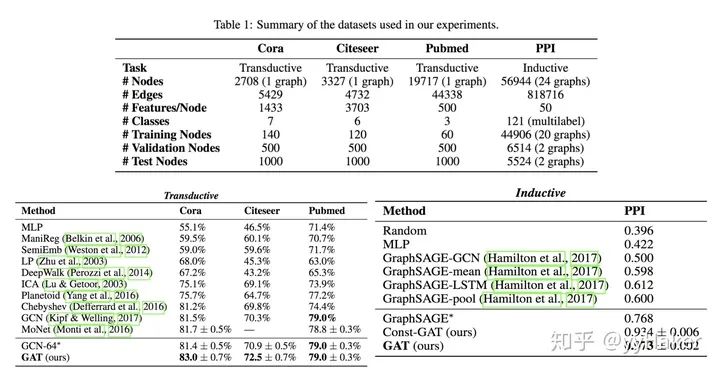
無論是在Transductive Learning還是在Inductive Learning的任務上,GAT的效果都要優于傳統方法的結果。至此,GAT的介紹完畢,我們來總結一下,GAT的一些優點,(1)訓練GCN無需了解整個圖結構,只需知道每個節點的鄰居節點即可(2)計算速度快,可以在不同的節點上進行并行計算(3)既可以用于Transductive Learning,又可以用于Inductive Learning,可以對未見過的圖結構進行處理(仍然是簡單的idea,解決了問題,效果還好!!!)到此,我們就介紹完了GNN中最經典的幾個模型GCN、GraphSAGE、GAT,接下來我們將針對具體的任務類別來介紹一些流行的GNN模型與方法。四、無監督的節點表示學習(Unsupervised Node Representation)由于標注數據的成本非常高,如果能夠利用無監督的方法很好的學習到節點的表示,將會有巨大的價值和意義,例如找到相同興趣的社區、發現大規模的圖中有趣的結構等等。
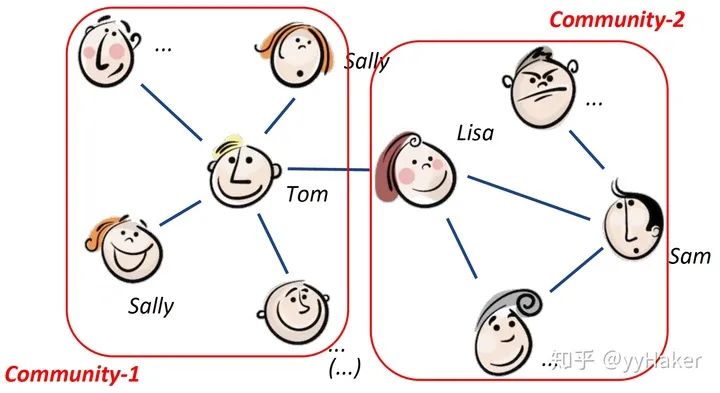
圖10這其中比較經典的模型有GraphSAGE、Graph Auto-Encoder(GAE)等,GraphSAGE就是一種很好的無監督表示學習的方法,前面已經介紹了,這里就不贅述,接下來將詳細講解后面兩個。
Graph Auto-Encoder(GAE)[10]
在介紹Graph Auto-Encoder之前,需要先了解自編碼器(Auto-Encoder)、變分自編碼器(Variational Auto-Encoder),具體可以參考[11],這里就不贅述。理解了自編碼器之后,再來理解變分圖的自編碼器就容易多了。如圖11輸入圖的鄰接矩陣和節點的特征矩陣,通過編碼器(圖卷積網絡)學習節點低維向量表示的均值和方差,然后用解碼器(鏈路預測)生成圖。
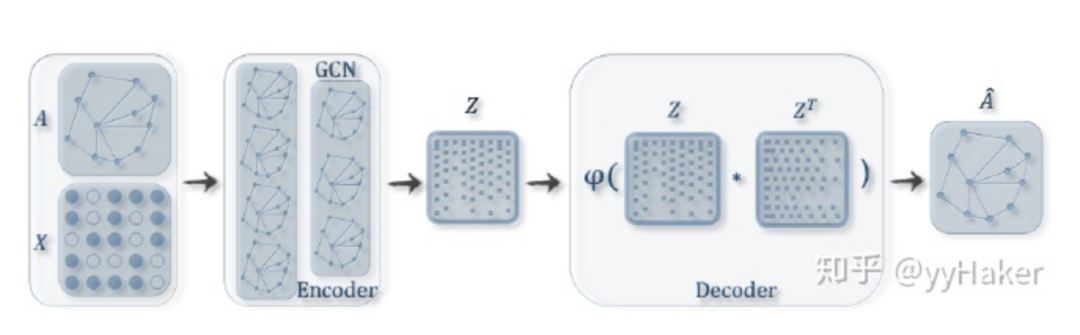
圖11編碼器(Encoder)采用簡單的兩層GCN網絡,解碼器(Encoder)計算兩點之間存在邊的概率來重構圖,損失函數包括生成圖和原始圖之間的距離度量,以及節點表示向量分布和正態分布的KL-散度兩部分。具體公式如圖12所示:

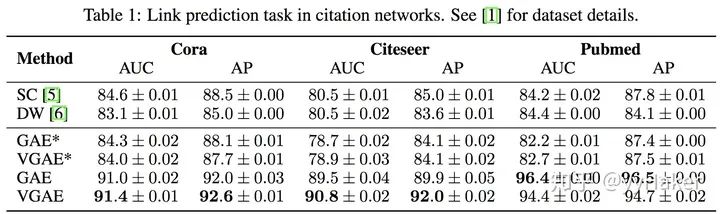
圖12另外為了做比較,作者還提出了圖自編碼器(Graph Auto-Encoder),相比于變分圖的自編碼器,圖自編碼器就簡單多了,Encoder是兩層GCN,Loss只包含Reconstruction Loss。那么兩種圖自編碼器的效果如何呢?作者分別在Cora、Citeseer、Pubmed數據集上做Link prediction任務,實驗結果如下表,圖自編碼器(GAE)和變分圖自編碼器(VGAE)效果普遍優于傳統方法,而且變分圖自編碼器的效果更好;當然,Pumed上GAE得到了最佳結果。可能是因為Pumed網絡較大,在VGAE比GAE模型復雜,所以更難調參。
五、Graph PoolingGraph pooling是GNN中很流行的一種操作,目的是為了獲取一整個圖的表示,主要用于處理圖級別的分類任務,例如在有監督的圖分類、文檔分類等等。
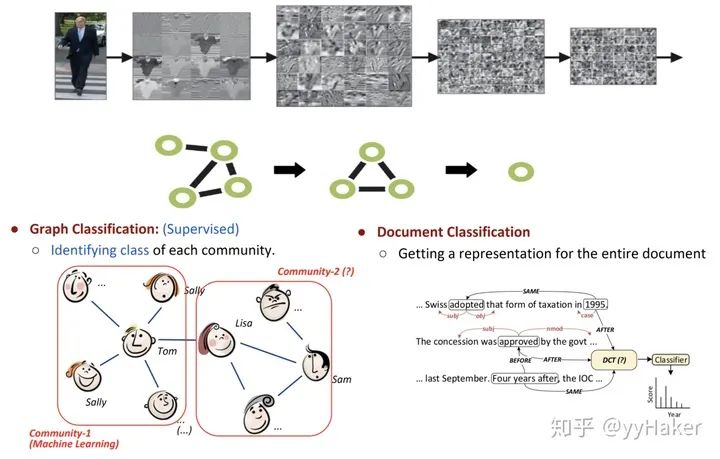
圖13Graph pooling的方法有很多,如簡單的max pooling和mean pooling,然而這兩種pooling不高效而且忽視了節點的順序信息;這里介紹一種方法:Differentiable Pooling (DiffPool)。1.DiffPool[12]在圖級別的任務當中,當前的很多方法是將所有的節點嵌入進行全局池化,忽略了圖中可能存在的任何層級結構,這對于圖的分類任務來說尤其成問題,因為其目標是預測整個圖的標簽。針對這個問題,斯坦福大學團隊提出了一個用于圖分類的可微池化操作模塊——DiffPool,可以生成圖的層級表示,并且可以以端到端的方式被各種圖神經網絡整合。DiffPool的核心思想是通過一個可微池化操作模塊去分層的聚合圖節點,具體的,這個可微池化操作模塊基于GNN上一層生成的節點嵌入以及分配矩陣,以端到端的方式分配給下一層的簇,然后將這些簇輸入到GNN下一層,進而實現用分層的方式堆疊多個GNN層的想法。(圖14)
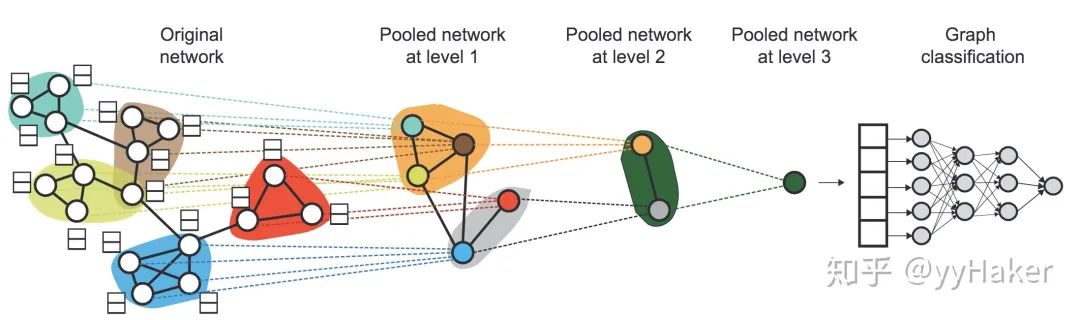
圖14那么這個節點嵌入和分配矩陣是怎么算的?計算完之后又是怎么分配給下一層的?這里就涉及到兩部分內容,一個是分配矩陣的學習,一個是池化分配矩陣。
分配矩陣的學習
這里使用兩個分開的GNN來生成分配矩陣和每一個簇節點新的嵌入,這兩個GNN都是用簇節點特征矩陣和粗化鄰接矩陣作為輸入,
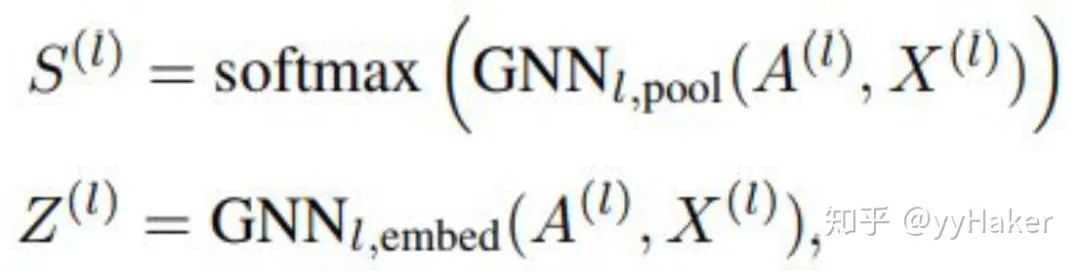
池化分配矩陣
計算得到分配矩陣和每一個簇節點新的嵌入之后,DiffPool層根據分配矩陣,對于圖中的每個節點/簇生成一個新的粗化的鄰接矩陣與新的嵌入矩陣,
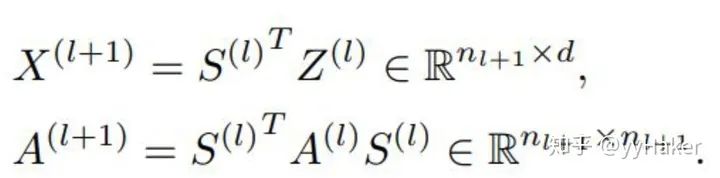
總的來看,每層的DiffPool其實就是更新每一個簇節點的嵌入和簇節點的特征矩陣,如下公式:
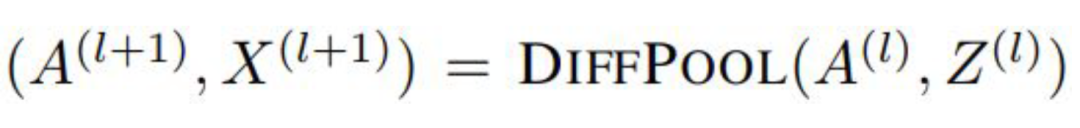
至此,DiffPool的基本思想就講完了。那么效果如何呢?作者在多種圖分類的基準數據集上進行實驗,如蛋白質數據集(ENZYMES,PROTEINS,D&D),社交網絡數據集(REDDIT-MULTI-12K),科研合作數據集(COLLAB),實驗結果如下:
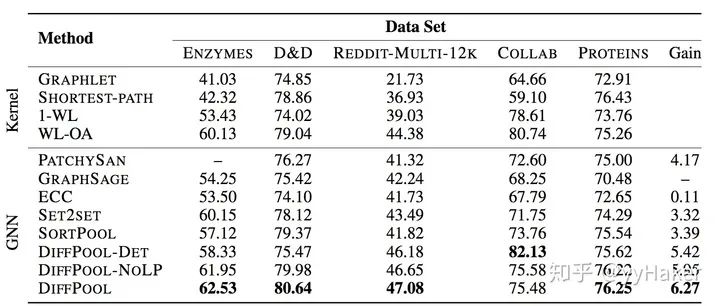
其中,GraphSAGE是采用全局平均池化;DiffPool-DET是一種DiffPool變體,使用確定性圖聚類算法生成分配矩陣;DiffPool-NOLP是DiffPool的變體,取消了鏈接預測目標部分。總的來說,DiffPool方法在GNN的所有池化方法中獲得最高的平均性能。為了更好的證明DiffPool對于圖分類十分有效,論文還使用了其他GNN體系結構(Structure2Vec(s2v)),并且構造兩個變體,進行對比實驗,如下表:
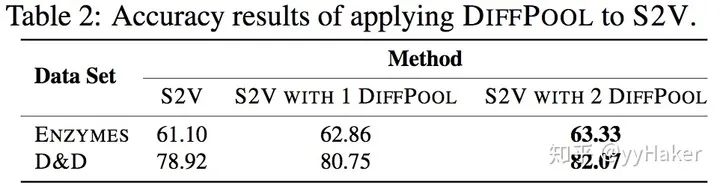
可以看到DiffPool的顯著改善了S2V在ENZYMES和D&D數據集上的性能。
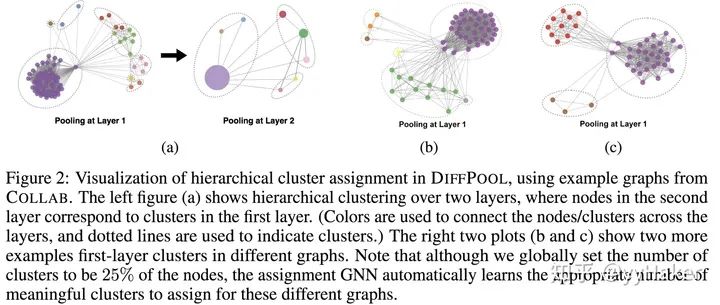
而且DiffPool可以自動的學習到恰當的簇的數量。至此,我們來總結一下DiffPool的優點,(1)可以學習層次化的pooling策略(2)可以學習到圖的層次化表示(3)可以以端到端的方式被各種圖神經網絡整合然而,注意到,DiffPool也有其局限性,分配矩陣需要很大的空間去存儲,空間復雜度為,為池化層的層數,所以無法處理很大的圖。
責任編輯:lq
-
神經網絡
+關注
關注
42文章
4810瀏覽量
102929 -
深度學習
+關注
關注
73文章
5555瀏覽量
122537 -
GNN
+關注
關注
1文章
31瀏覽量
6509
原文標題:圖神經網絡入門必讀: 一文帶你梳理GCN, GraphSAGE, GAT, GAE, Pooling, DiffPool
文章出處:【微信號:vision263com,微信公眾號:新機器視覺】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
20個經典模擬電路及詳細分析答案
兩個EMC抗干擾的經典案例

20個經典電路分享
SOLIDWORKS 2025直觀的用戶界面
經典圖神經網絡(GNNs)的基準分析研究

一文看懂刻蝕角度與ICP-RIE射頻功率的關系
光纖的折彎角度限制是多少
電子產品方案開發公司常用的15個單片機經典電路分享!
如何控制普通電機的轉動角度
使用SOLIDWORKS的直觀體驗






 工商網監
工商網監
評論